
1、什么是爬虫?
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据 。
解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息。
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息。
2、网络爬虫步骤
网络爬虫是一种自动化程序,用于浏览互联网并收集相关数据。它通过发送HTTP请求,下载网页内容,然后解析和提取有用的信息。网络爬虫的主要目的是获取特定网站或多个网站的数据,并将其用于分析、存储或其他应用程序。
网络爬虫的工作原理通常包括以下几个步骤:
- 确定起始点:爬虫需要指定一个或多个起始URL作为开始点。这些URL可以是特定的网页、网站的首页或其他包含感兴趣信息的页面。
- 发送请求:爬虫使用HTTP协议向目标网站发送请求,获取网页的HTML源代码。请求可以包含一些额外的信息,如用户代理、Cookie等。
- 解析网页:爬虫使用HTML解析器解析网页的结构,识别出网页中的各种元素,如链接、文本、图像等。
- 提取数据:爬虫从解析后的网页中提取出感兴趣的数据。这可以通过正则表达式、XPath、CSS选择器等方式进行。
- 遍历链接:爬虫会从当前页面中提取出的链接中找到新的URL,并将其添加到待访问的URL队列中。这样可以实现对其他页面的访问和数据提取。
- 存储数据:爬虫将提取到的数据进行清洗、处理和存储,以备后续使用。数据可以保存到文件、数据库或其他存储介质中。
- 反爬处理:为了防止被网站封禁或限制访问,爬虫需要处理反爬虫机制,如限制访问频率、验证码识别等。
网络爬虫在实际应用中有着广泛的用途,例如搜索引擎的索引建立、数据挖掘、舆情监测、价格比较、信息聚合等。但要注意,爬虫的使用需要遵守法律法规和网站的使用条款,尊重网站的隐私和访问限制。
3、爬虫核心
1.爬取网页:爬取整个网页 包含了网页中所有得内容
2.解析数据:将网页中你得到的数据 进行解析
3.难点:爬虫和反爬虫之间的博弈
在后面的文章中我们都会一一去讲解。
4、爬虫的用途
- 数据分析/人工数据集
- 社交软件冷启动(交友平台爬取用户数据然后进行自己平台的机器式注册)
- 舆情监控
- 竞争对手监控(电商平台之间的竞争)
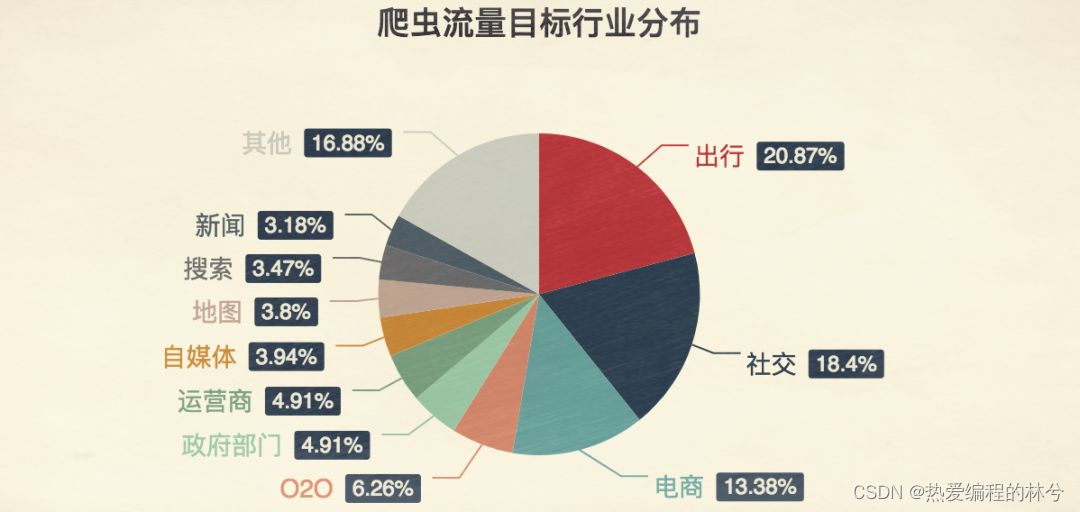
为什么出行是爬虫流量目标第一呢?
我们平时都使用过抢票软件(智行,飞猪等等)去进行买票,但是国内只有12306一家卖票,那他们的票是哪里来的呢?
他们也是从12306中抢票,通过爬虫进行高频次的访问去进行抢票。
其次是社交类,而其中微博又是最大的灾区,微博是其他聊天软件第一目标,为什么?
因为我要把爬取的数据当作自己软件的一些假用户,然后去进行和你聊天,去吸引到你的注意,让你去想进行聊天。
5、爬虫分类
通用爬虫:
实例 百度、360、google、sougou等搜索引擎‐‐‐伯乐在线 功能 访问网页‐>抓取数据‐>数据存储‐>数据处理‐>提供检索服务 robots协议 一个约定俗成的协议,添加robots.txt文件,来说明本网站哪些内容不可以被抓取,起不到限制作用 自己写的爬虫无需遵守 网站排名(SEO) 1. 根据pagerank算法值进行排名(参考个网站流量、点击率等指标) 2. 百度竞价排名 缺点 1. 抓取的数据大多是无用的 2.不能根据用户的需求来精准获取数据
因此上面的通用爬虫不是我们学习的目标,我们的学习目标是下面的聚焦爬虫。
聚焦爬虫
功能 根据需求,实现爬虫程序,抓取需要的数据 设计思路 1.确定要爬取的url 如何获取Url 2.模拟浏览器通过http协议访问url,获取服务器返回的html代码(所有的数据) 如何访问 3.解析html字符串(根据一定规则提取需要的数据)
6、反爬手段

为了保护网站的数据和资源,防止被恶意爬虫滥用或过度访问,网站常常采用一些反爬手段。以下是一些常见的反爬手段:
- 验证码:网站可能要求用户输入验证码,以确认其为真实用户而不是爬虫。验证码可以是图形验证码、短信验证码等形式。
- IP限制:网站可以根据IP地址限制访问频率或连接数,当同一个IP地址请求过于频繁时,可能会被暂时或永久禁止访问。
- User-Agent检测:网站可以通过检查请求中的User-Agent字段来判断请求是否来自爬虫。如果User-Agent与正常浏览器的标识不匹配,可能会被拒绝访问。
- Cookie验证:网站可能使用Cookie来验证用户身份,如果请求中没有有效的Cookie或Cookie不符合预期,可能会被拒绝访问。
- 动态页面:网站可以使用动态生成的页面内容, ers实现爬虫难以解析和提取数据。
- 页面渲染:有些网站使用JavaScript动态生成页面内容,爬虫需要使用浏览器引擎来解析和执行JavaScript代码,以获取完整的页面数据。
- 请求频率限制:网站可能设置了请求频率限制,当请求频率超过一定阈值时,可能会被判定为爬虫并拒绝访问。
为了规避这些反爬手段,爬虫开发者可以采取一些策略,如设置合理的请求频率、使用代理IP、处理验证码、处理动态页面等。然而,请注意,遵守网站的规则和使用条款是非常重要的,爬虫应该尊重网站的隐私和访问限制,避免对网站造成过度负荷或滥用。
版权归原作者 热爱编程的林兮 所有, 如有侵权,请联系我们删除。