
HTTP 简介
HTTP协议(超文本传输协议HyperText Transfer Protocol),它是基于TCP协议的应用层传输协议,简单来说就是客户端和服务端进行数据传输的一种规则。
但是就这样就可以了吗?当面试官问我们什么是HTTP协议时上面这个我们肯定能够说的出来但是这可能不是面试官想要的结果.面试官可能会在问什么是超文本控制协议?
我们可以将超文本传输协议拆分为三部分:
- 超文本
- 传输
- 协议
他们之间的关系如下:
1.什么是超文本?
在互联网早期的时候,我们输入的信息只能保存在本地,无法和其他电脑进行交互。我们保存的信息通常都以文本即简单字符的形式存在,文本是一种能够被计算机解析的有意义的二进制数据包。而随着互联网的高速发展,两台电脑之间能够进行数据的传输后,人们不满足只能在两台电脑之间传输文字,还想要传输图片、音频、视频,甚至点击文字或图片能够进行超链接的跳转,那么文本的语义就被扩大了,这种语义扩大后的文本就被称为超文本(Hypertext)。
2.什么是传输?
传输其实非常好理解就是把⼀堆东⻄从 A 点搬到 B 点,或者从 B 点 搬到 A 点。
通常我们把传输数据包的一方称为
请求方,把接到数据包的一方称为
应答方。请求方和应答方可以进行互换,请求方也可以作为应答方接受数据,应答方也可以作为请求方请求数据。
3.什么是协议
1.什么是协议?协议其实就是一种约定。比如:假设你有女朋友当你约女朋友在那个地方吃饭,这个约定也叫做协议。那么你和你的女朋友都要遵守如果双方都不遵守那么你们是吃不成饭的。那么网络协议是什么呢?
网络协议就是网络中(包括互联网)传递、管理信息的一些规范。就如果我们上课的时候需要遵守一定的规矩,计算机之间的相互通信需要共同遵守一定的规则,这些规则就称为网络协议。
2.没有规则不成方圆,没有协议的互联网是混乱的。就像人类社会一样我们并不是想干啥就干啥我们的行为是要受到法律的限制的。那么互联网中的主机也不能自己想发什么发什么,也是需要受到通信协议约束的。
URL
URL 即统一资源定位符,它是用来表示互联网上的某个资源地址,互联网上的每个文件都有一个唯一的 URL。也就是我们常说的网址。
一个URL的构成如下:
1.协议方案名:
其中http://表示的是协议名称,表示请求的时需要使用的协议通常是HTTP协议和HTTPS协议 。
2.登录信息:
user:pass表示的是登录的认证信息包括了我们的用户名和密码但是通常会被省略,因为登录信息可以通过其他方案交付给服务器。
3.服务器地址
4.端口号
80表示的服务器的端口号.HTTP协议是位于引用层的协议在进行套接字编程的适合我们需要给服务器绑定对于的IP和端口号。常见的端口号有:
- HTTP:80
- HTTPS:443
- SSH:22
urlencode&urldecode
在URL中有一些符号具有特殊的含义如果我们搜索的关键字出现了这些关键字时URL会对这些关键字进行转义。转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY 格式
比如说我们搜索C++关键字时由于+号在URL当中是特殊符号而+号转换之后对于的16进制的值为:0x2B

注意:当我们输入中文时中文也没被URL编码
既然URL能对这些特殊字符进行编码那么服务器拿到这些字符的时候肯定要进行解码,这样服务器才能收到你传递的参数。也就是说urdecode是urlencode的一个逆过程。
HTTP请求协议格式
1.http的请求格式如下:
HTTP请求由四部分组成:
- 请求行:请求方法+[URL]+[HTTP版本]
- 请求报头:请求的属性,这些属性都是以key:value的形式按行呈列的。
- 空行:用来分隔报头和请求正文
- 请求正文:请求正文可以为空,如果有请求正文那么请求报头中会有一个Content-Length属性该属性是用来标识请求正文的长度。
下面我们以请求行为列解释一下:
注意请求方法后面有一个空格最后有一个\n请求属性的每一行的末尾都有一个\n.
如何将HTTP请求的报头和有效载荷分离?
当应用层收到一个HTTP请求时必须将报头和有效载荷分离。我们可以根据HTTP请求的\n进行分离,我们可以按行读取读到\n时我们就知道HTTP的报头读取完了。
2.获取HTTP请求
在网络协议中应用层的下一层叫做传输层而HTTP协议的底层通常用的是TCP协议所以了我们可以自己编写一个简单的TCP服务器然后用浏览器访问我们编写的这个服务器。我们实现的这个服务器非常的简单直接将浏览器发过来的HTTP请求进行输出打印即可。这样我们就可以看到HTTP的基本构成了。
对于代码:
1 #include<fstream> 2 #include<cstdlib> 3 #include<sys/wait.h> 4 #include<iostream> 5 #include<sys/types.h> 6 #include<sys/socket.h> 7 #include<netinet/in.h> 8 #include<arpa/inet.h> 9 #include<unistd.h> 10 using namespace std; 11 int main() 12 { 13 14 int lsock=socket(AF_INET,SOCK_STREAM,0); 15 if(lsock<0) 16 { 17 cerr<<"socket error"<<endl; 18 return 1; 19 } 20 struct sockaddr_in local; 21 local.sin_family=AF_INET; 22 local.sin_port=htons(8080); 23 local.sin_addr.s_addr=INADDR_ANY; 24 if(bind(lsock,(struct sockaddr*)&local,sizeof(local))<0) 25 { 26 cerr<<"bind error"<<endl; 27 return 2; 28 } 29 30 if(listen(lsock,5)<0){ 31 cerr<<"listen error"<<endl; return 3; 32 } 33 struct sockaddr_in peer; 34 for(;;) 35 { 36 socklen_t len=sizeof(peer); 37 int sock=accept(lsock,(struct sockaddr*)&peer,&len); 38 if(sock<0) 39 { 40 std::cout<<"accept error"<<endl; 41 } if(listen(lsock,5)<0){ 31 cerr<<"listen error"<<endl; 32 } 33 struct sockaddr_in peer; 34 for(;;) 35 { 36 socklen_t len=sizeof(peer); 37 int sock=accept(lsock,(struct sockaddr*)&peer,&len); 38 if(sock<0) 39 { 40 std::cout<<"accept error"<<endl; 41 } 42 if(fork()==0) 43 { 44 if(fork()>0) 45 { 46 exit(0); 47 } 48 close(lsock); 49 //read http request 50 char buffer[1024]; 51 recv(sock,buffer,sizeof(buffer),0); 52 cout<<"###################################http request begin##################################################"<<endl;; 53 54 cout<<buffer<<endl; 55 cout<<"###################################http request end##################################################"<<endl; 75 close(sock); 76 77 } 78 exit(0); 79 } 80 close(sock); 81 waitpid(-1,nullptr,0); 82 } 83 84 85 return 0; 86 }
下面我们将服务器跑起来然后使用浏览器对我们编写的服务器进行访问:

注意:
1.浏览器向我们的服务器发起请求之后,因为我们的服务器并没有对其进行响应此时浏览器可能就认为服务器没有收到请求所以不断的向我们的服务器发起请求所以了我们虽然只使用浏览器访问服务器一次但是确收到了很多次HTTP请求。
2.URL当中的/我们不能认为就是我们云服务器上的根目录这个/代表的是web根目录这个目录可以自己指定不一定就是Linux当中的根目录。
通过服务器打印出来的结果我们可以发现请求行当中的URL一般是不携带域名和端口号的这是因为在请求报头的Host字段中已经携带了。请求行中的URL代表你要访问对于服务器上的那个路径下的资源。而请求报头也正如我们上面所说的一样是以key:value的形式进行呈列的。
HTTP响应格式
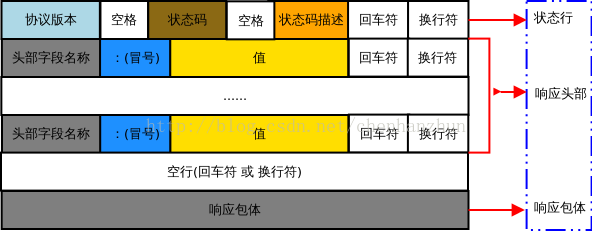
http的响应由以下四部分构成:
- 状态行:http版本+状态码+状态码描述
- 响应报头:响应的属性,这些属性都是按行进行呈列的都是key:value的形式。
- 空行:空行用来标识响应报头结束
- 响应正文 :响应正文允许有空字符串,但是如果有响应正文的话那么响应报头的属性里面会有一个Content-Length来标识响应正文的长度。
同样的如何将响应的报头和有效载荷进行分离?和请求一样按行读取读到换行就说明报头读取完毕。
下面我们用我们的服务器给浏览器一个响应:
当服务器收到客户端的请求时会对HTTP请求报文进行一系列分析然后再给客户端进行响应。在这里为了简单我们的服务器只给客户端响应一些简单的html:

当服务器收到请求时不官浏览器发来的是什么请求我们都把这个网页响应给浏览器其实也就是把这个html里面的内容放到响应正文里面。
对于代码:
#include<fstream> #include<cstdlib> #include<sys/wait.h> #include<iostream> #include<sys/types.h> #include<sys/socket.h> #include<netinet/in.h> #include<arpa/inet.h> #include<unistd.h> using namespace std; int main() { int lsock=socket(AF_INET,SOCK_STREAM,0); if(lsock<0) { cerr<<"socket error"<<endl; return 1; } struct sockaddr_in local; local.sin_family=AF_INET; local.sin_port=htons(8080); local.sin_addr.s_addr=INADDR_ANY; if(bind(lsock,(struct sockaddr*)&local,sizeof(local))<0) { cerr<<"bind error"<<endl; return 2; } if(listen(lsock,5)<0){ cerr<<"listen error"<<endl; } struct sockaddr_in peer; for(;;) { socklen_t len=sizeof(peer); int sock=accept(lsock,(struct sockaddr*)&peer,&len); if(sock<0) { std::cout<<"accept error"<<endl; } if(fork()==0) { if(fork()>0) { exit(0); } close(lsock); //read http request char buffer[1024]; recv(sock,buffer,sizeof(buffer),0); cout<<"###################################http request begin##################################################"<<endl;; cout<<buffer<<endl; cout<<"###################################http request end##################################################"<<endl; #define PAGE "index.html" ifstream t(PAGE); if(t.is_open()){ t.seekg(0,std::ios::end); size_t len=t.tellg(); t.seekg(0,std::ios::beg); char*file=new char[len]; t.read(file,len); t.close(); std::cout<<file<<endl; string status_line="http/1.0 200 OK\n";//状态行 string respond_header="Conten-Length:"+std::to_string(len);//响应报头 respond_header+="\n"; std::string blank="\n"; send(sock,status_line.c_str(),status_line.size(),0); send(sock,respond_header.c_str(),respond_header.size(),0); send(sock,blank.c_str(),blank.size(),0); send(sock,file,len,0);//响应正文 close(sock); delete []file; } exit(0); } close(sock); waitpid(-1,nullptr,0); } return 0; }
当浏览器收到我们的响应时会对响应正文里面的内容进行解析,解析之后就是我们看到的内容:

同样的我们可以使用telnet指令向我们的服务器发起请求,这样也是可以得到响应的:

HTTP的常见方法

其中最常见的就是GET方法和POST方法:
1.GET方法
Get ⽅法的含义是请求从服务器获取资源,这个资源可以是静态的⽂本、⻚⾯、图⽚视频等。 ⽐如,你打开我的⽂章,浏览器就会发送 GET 请求给服务器,服务器就会返回⽂章的所有⽂字及资源。
GET方法和POST方法都可以传参:
- GET方法是通过url传参
- POST方法是通过正文传参
从这里我们就可以知道POST方法比GET传递的参数要更多这是因为url的长度是有限的,POST可以通过正文传递更多的参数,还有就是POST方法比GET方法更私密。POST方法不会把你的参数回显到URL中所以了POST方法比GET方法更私密。
下面我们通过PostMan这个软件来演示POST和GET的区别


下面我们使用POST方法通过PostMan

对应结果

我们发现确实和上面说的一样其中了这个Content-Lenght就是正文的长度标识响应正文的长度
总结:
- 使用GET方法我们提交的参数会显示到url当中所以一般GET方法一般处理不是很敏感的数据
- POST方法更私密因为POST方法通过正文传参不会把参数显示出来所以相对url来说更加私密。
HTTP状态码
http常见的状态码如下:

我们重点来看3 xx(重定向状态码)
重定向是将网络请求重新定了一个方向转到其他的位置,此时服务器就只起到了引路的作用。重定向分为:临时重定向和永久重定向其他状态码
301(永久重定向)而状态码302和307表示临时重定向。临时重定向和永久重定向的区别:
永久重定向和临时重定向的本质是影响客户端的标签,决定客户端是否需要更新目标地址。如果一个网站是永久重定向那么第一次访问它时浏览器帮你重定向但是以后访问给网站时你直接访问的是重定向后的网站了如果是临时的话每次都需要进行浏览器帮我们进行重定向。
下面我们进行重定向演示:
进行重定向时我们需要使用Location字段。Location字段表示你要重定向的目标网站我们在这里演示临时重定向将HTTP状态行的状态码改为307
然后再将对于的状态码描述改为对于的描述而后面的这个Location后面跟上你要重定向的网址比如我们设置为www.baidu.com
对于代码:
#include<fstream> #include<cstdlib> #include<sys/wait.h> #include<iostream> #include<sys/types.h> #include<sys/socket.h> #include<netinet/in.h> #include<arpa/inet.h> #include<unistd.h> using namespace std; int main() { int lsock=socket(AF_INET,SOCK_STREAM,0); if(lsock<0) { cerr<<"socket error"<<endl; return 1; } struct sockaddr_in local; local.sin_family=AF_INET; local.sin_port=htons(8080); local.sin_addr.s_addr=INADDR_ANY; if(bind(lsock,(struct sockaddr*)&local,sizeof(local))<0) { cerr<<"bind error"<<endl; return 2; } if(listen(lsock,5)<0){ cerr<<"listen error"<<endl; } struct sockaddr_in peer; for(;;) { socklen_t len=sizeof(peer); int sock=accept(lsock,(struct sockaddr*)&peer,&len); if(sock<0) { std::cout<<"accept error"<<endl; } if(fork()==0) { if(fork()>0) { exit(0); } close(lsock); //read http request char buffer[1024]; recv(sock,buffer,sizeof(buffer),0); cout<<"###################################http request begin##################################################"<<endl;; cout<<buffer<<endl; cout<<"###################################http request end##################################################"<<endl; #define PAGE "index.html" ifstream t(PAGE); if(t.is_open()){ t.seekg(0,std::ios::end); size_t len=t.tellg(); t.seekg(0,std::ios::beg); char*file=new char[len]; t.read(file,len); t.close(); std::cout<<file<<endl; string status_line="http/1.0 307 Temporary Redirect\n";//状态行 string respond_header="Location://www.baidu.com\n";//响应报头 std::string blank="\n"; send(sock,status_line.c_str(),status_line.size(),0); send(sock,respond_header.c_str(),respond_header.size(),0); send(sock,blank.c_str(),blank.size(),0); send(sock,file,len,0);//响应正文 close(sock); delete []file; } exit(0); } close(sock); waitpid(-1,nullptr,0); } return 0; }
我们运行服务器我们使用telnet命令访问我们都服务器时并发送HTTP请求时:

HTTP常见的Header
User-Agent (浏览器名称)
User-Agent:是客户浏览器的名称,以后会详细讲。Cookie (Cookie)
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能。Referer (页面跳转处)
Referer:表明产生请求的网页来自于哪个URL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面, 是从什么网站来的等。
有时候遇到下载某网站图片,需要对应的referer,否则无法下载图片,那是因为人家做了防盗链,原理就是根据referer去判断是否是本网站的地址 ,如果不是,则拒绝,如果是,就可以下载;Content-Type (POST数据类型)
Content-Type:POST请求里用来表示的内容类型。
举例:Content-Type = Text/XML; charset=gb2312:
指明该请求的消息体中包含的是纯文本的XML类型的数据,字符编码采用“gb2312”。
- Host (主机和端口号)
- Host:对应网址URL中的Web名称和端口号,用于指定被请求资源的Internet主机和端口号,通常属于URL的一部分。
6.X-Requested-With: XMLHttpRequest(表示是一个Ajax异步请求)
Connection (链接类型) Connection:表示客户端与服务连接类型
Accept (传输文件类型)
9.Content-Length:正文长度
10.Cookie:用于在客户端存储少量信息通常用来实现seesion功能
版权归原作者 一个山里的少年 所有, 如有侵权,请联系我们删除。