
通过前面小节的学习,相信大家已经理解了什么是消息队列,消息队列是做什么的。kafka作为消息队列的一种,具有高可靠性、高吞吐量的特点,从而而得到广泛的应用。
本节为大家介绍一下kafka的一些基础概念,这些概念将在后续的学习中不断的被提到,所以有必要清晰明了。本节内容是应用kafka消息队列最核心的理论知识内容,初学者请务必研读揣摩。 第一遍读不懂往后学一学,再回来都这一篇文章,总之反复揣摩,这篇是kafka的理论知识核心。
kafka主题、分区、消费者有哪些门门道道?
kafka分区副本与高可用
文章目录
一、代理商Broker
在之前我们已经为大家介绍了生产者向消息队列中投递消息,消费者从消息队列中拉取数据。
在kafka消息队列中有一个非常重要的概念就是代理Broker,大家可以想象生活中的商品代理商是做什么的?进货、存货、销货。 kafka的代理Broker也承担着同样的作用:接收消息、保存消息、为消费者提供消息。

具体到kafka架构层面,我们可以认为一个Broker代理就是一个kafka的服务实例。kafka可以启动多个服务实例,组成一个具有多个Broker代理的服务集群。通常一个集群内的Broker越多,kafka集群的整体吞吐能力就越强。这个也好理解,现实生活中一个产品的代理商越多,销售能力就越强,是一个道理。
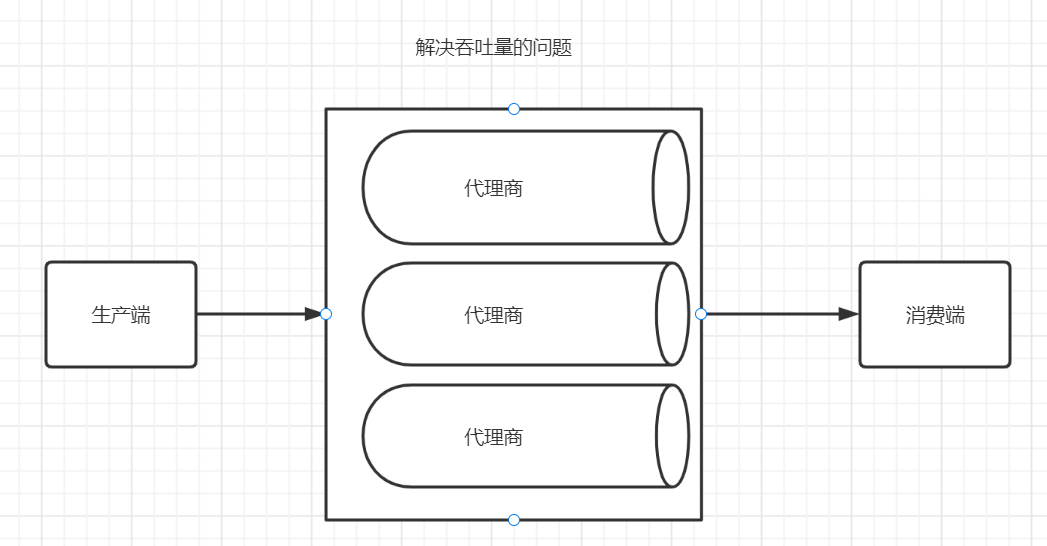
因为kafka通常时进行分布式部署,所以一个物理服务器(一个操作系统)通常只部署启动一个kafka实例,所以在这种场景下Broker代理就可以理解是一台服务器。
可不可以一个服务器部署多个kafka实例?可以,通过修改端口避免端口冲突是可以实现的,但是这样不好。因为kafka之所以分布式部署是考虑到高可用,即:一台服务器宕机,kafka集群仍然可用。如果一个服务器部署多个kafka实例,一旦该服务器宕机,那么影响面就很大了,很可能直接将kafka集群拖垮。
二、主题与主题分区
代理商Broker可以帮助上产厂家对商品进行“进销存”,但是有一个问题,商品没有进行分类。显然茅台酒和乳制品、猪肉等不同产品的销售周期、销售频率是不一样的,为了有效的安排商品进销存需要对商品进行分类。同理,kafka接收到的消息有些是需要快速处理数据,有些是高频但时效性要求低的数据。所以要对消息数据进行分类,每一个分类被称为一个Topic(主题)。笔者觉得Topic这个词在这里翻译成"渠道"会更好,但是更多的人已经认可“主题”这种翻译方式了,所以先入为主。
下图中中间实线部分是一个单kafka实例的Broker,包含三个Topic。也就是该代理商代理酒类、乳制品、零食三种商品。Topic主题是一个逻辑概念,用来对消息进行分类。
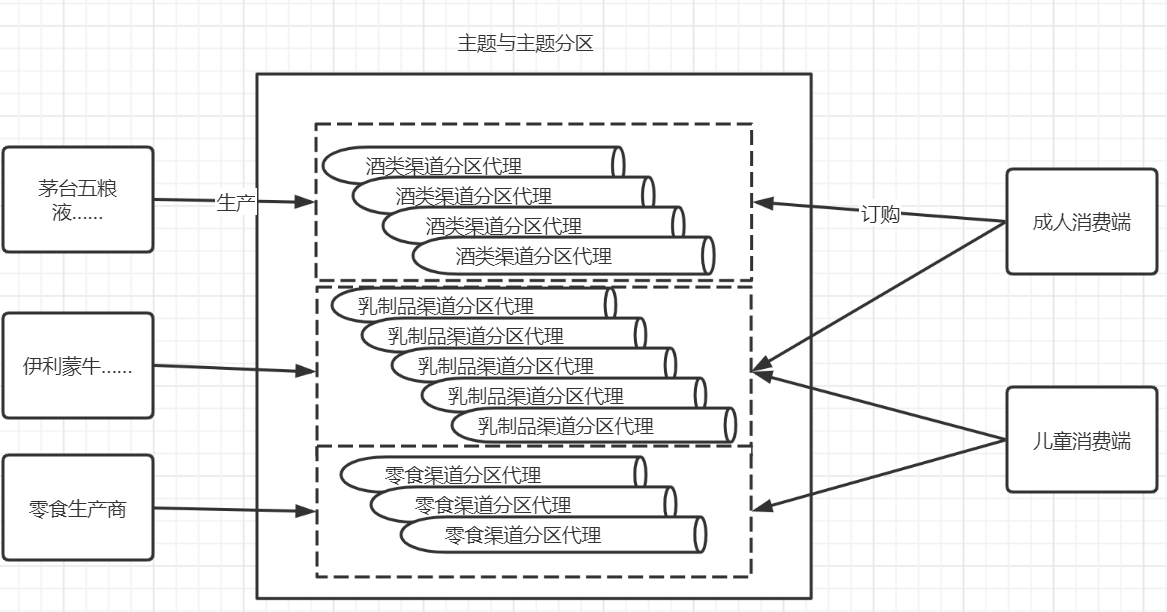
上图中虚线范围代表主题Topic,管道状图形代表主题的分区partition。
代理商将商品按照主题Topic进行分类,那么还有一个问题,如果一个代理商的工作是单线程的,处理高并发的工作时就捉襟见肘了。所以,我们为Topic主题引入分区的概念,分区是一个实实在在的物理存在的队列数据结构用于存放数据,占用系统内存以及磁盘数据存储等资源。
- 分区是一个主题Topic的分区,所以主题Topic包含一个或多个分区。一个Topic包含多少个分区取决于该主题下的商品处理的吞吐量能力需求。
- 因为Topic是一个逻辑概念,所以分区也可以被叫做"分区代理",一个代理Broker包含多个分区。就像一个省级代理可以包含多个地市级代理。
三、分区与消费者组
kafka代理有了主题Topic与分区partition之后,消息数据的代理能力增强了,也就是消息可以分类了,吞吐量能力也提升了。生产者可以大量的生产消息数据交给kafka消息队列。但是注意这里:和现实生活中一个分区代理面向多个消费者不同,kafka的一个分区只能面向一个消费者线程。

所以有了下面的概念
- 多个消费同一主题Topic数据的消费者线程,可以组成一个消费者组。如上图:成人消费者组,儿童消费者组。
- 一个消费者组可以订阅多个主题,消费多个主题下的数据。如上图:成人消费者组可以在酒类、乳制品两个主题下进行消费。
假如一个topic有2个分区,订阅该topic的消费者组有5个消费线程,那么就会有3个消费线程消费不到该主题的数据(空转)。
四、分区副本与高可用
解决完吞吐量的问题,下面就是如何保证kafka集群高可用的问题。上文已经介绍:一个kafka集群包含多个Broker实例,通常每个Broker实例部署在不同的服务器上独立运行。这就是分布式架构内保证高可用的常用方法之一:服务多实例。一个服务实例挂掉,还有其他实例可以提供服务,从而保证高可用。
那么保证分布式集群高可用的第二种方法:数据多副本,一个副本的数据丢失,还有其他的数据副本可以使用。kafka的数据存在哪?分区,所以对于kafka来说保证数据不丢的高可用方式就是分区多副本。
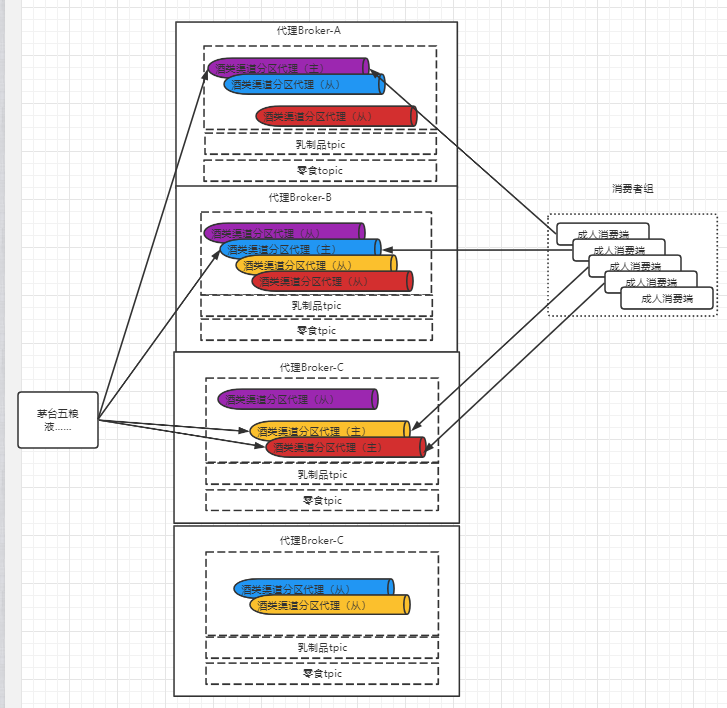
Broker服务多实例、分区多副本结合到一起就是上面的这一张图,解释一下这张图:
- 1个酒类主题包含4个分区,每个分区有三个副本(一主二从、同一颜色)
- 三个分区副本分布式四个Broker服务实例上
- 生产者只向主分区副本发送消息数据
- 消费者也只从主分区副本拉取消息数据
另外,上图中的一个主题分区的三个分区副本之间的主从关系不是固定不变的,是根据分区副本所在的Broker服务实例的状态选举出来的。举例说明,分区副本A、B、C,目前状态是A是主分区副本。如果分区副本A所在的Broker挂掉了,那么分区副本A就失去了“主副本资质”,在分区副本B和C之间重新选举一个主分区副本。
所以以上图所示的集群为例,分区副本分散存在于多个Broker服务实例上,所以即使其中1个或2个服务实例挂掉了,也不会使消息服务整体不可用。因为还剩一个分区副本,生产者和消费者只和主分区副本(Leader)进行数据通信,从分区副本(Follower)只起到数据备份的作用。
五、分区副本的数据同步
上文我们介绍到,生产者和消费者只和主分区副本进行数据通信,那么从分区副本的数据从哪里来的?从分区副本( Follower )的数据是从主分区副本(Leader)那里同步过来的。
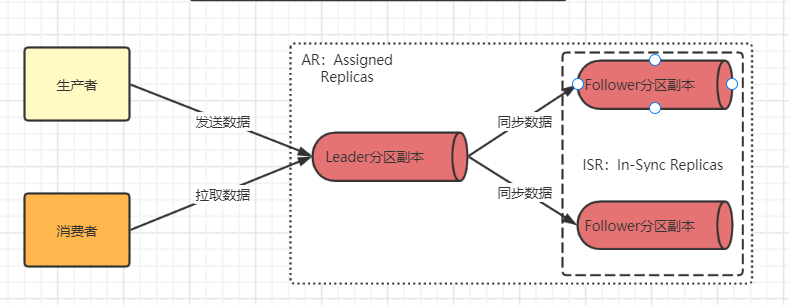
这里有几个名词,可能需要大家记一下,都是技术人,聊天装逼用用挺好。
- AR(Assigned Replicas):代表一个分区的所有副本的集合,包括主(leader)、从(Follower)。
- ISR(In Sync Replicas):与主分区副本处于同步状态的从分区副本的集合。也可能存在少量的数据延时差异,因为数据同步嘛难免耗时。
- OSR(Out Sync Replicas):,数据同步状态已经跟不上主分区副本的从分区副本的集合。可能是网络等问题导致。
什么样的分区副本会被判断为OSR?
答:判断一个 Follower 分区副本与主分区是否同步,是通过判断从分区副本数据落后主分区副本的数据的时间跨度来实现的,如果这个时间跨度大于replica.lag.time.max.ms配置的参数值(默认值是10秒),则认为从分区副本与主分区副本不同步。
不同步的分区副本将被踢出ISR集合,放入OSR集合。如果后续该Follower分区副本逐渐赶上Leader副本的数据进度,还会自动回到ISR集合中。
版权归原作者 字母哥哥 所有, 如有侵权,请联系我们删除。