
应用层告一段落,我们在前面学习到了
- 序列化和反序列化
- 守护进程
- 正确的读取和写入
- 怎么定制协议
- 协议和序列化的区别
- 加密
- ...
国庆后写个小结(。・∀・)
这篇文章我们就开始 传输层 的讲解啦
思维导图如下:
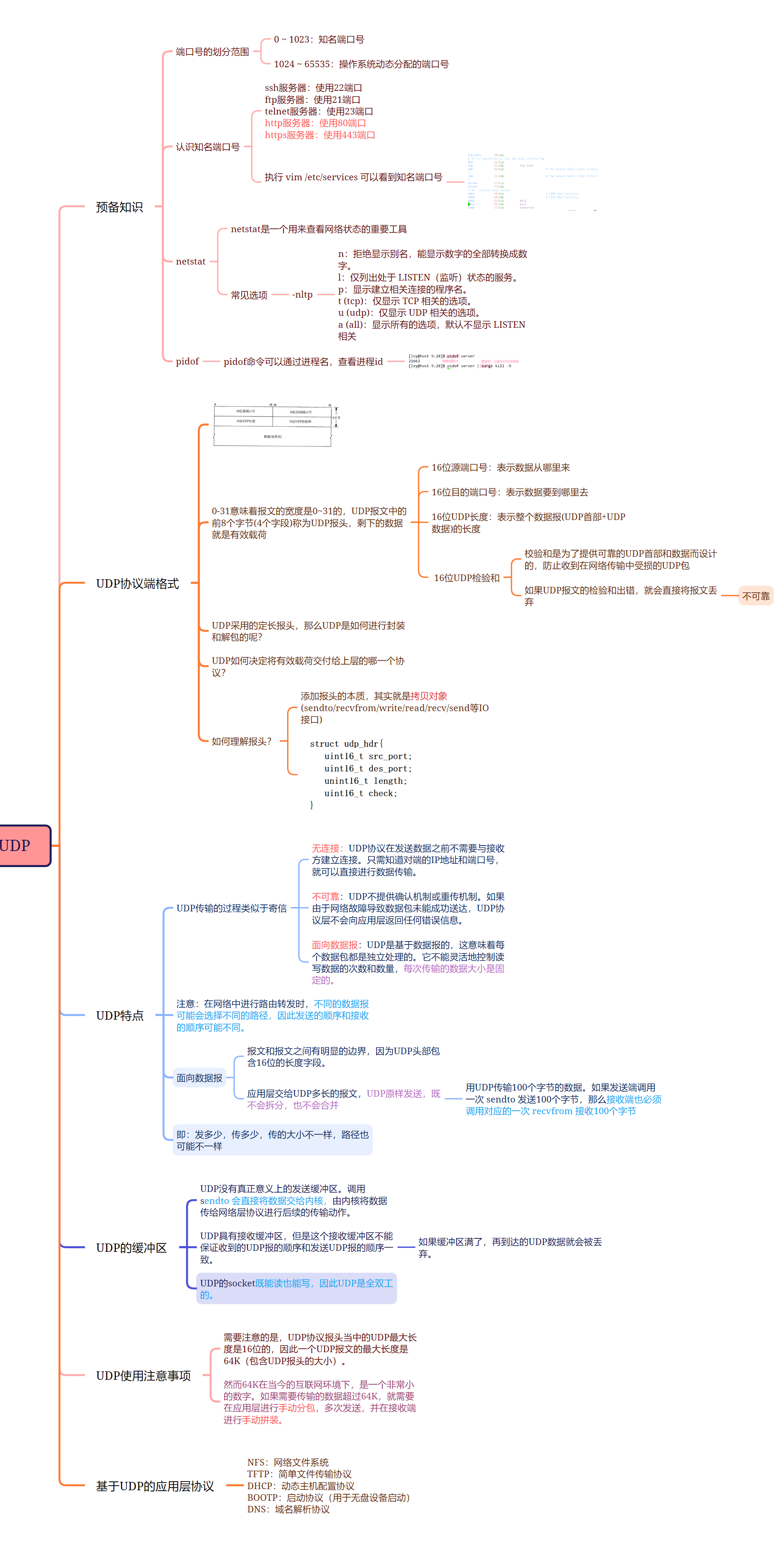
0. 预备知识
1. 端口号的划分范围
端口号(Port)标识了一个主机上进行通信的不同的应用程序。
- 在TCP/IP协议中,用 “源IP”,“源端口号”,“目的IP”, “目的端口号”, “协议号” 这样一个五元组来标识一个通信(可以通过netstat -n查看);
- 这里协议号就相当于具体一个协议的名称,也就是标识客户端和服务器用什么协在通信。其实目的端口号就已经确定了用那个协议,如:22 ssh协议。

实际上不管是用同一个客户端上不同的请求或者不同的客户端去请求同一个服务器,都能够准确区分清楚这个请求时从哪来的。全都是得益于完整的报文。
TCP解决通信双方端口问题,IP解决通信双方IP地址问题,所以TCP/IP解决网络通信的问题。
端口号长度为16位,因此范围是 0 ~ 65535。
- 0 ~ 1023:知名端口号
- 例如:HTTP、FTP、SSH等广泛使用的应用层协议,其端口号是固定的。
- 1024 ~ 65535:操作系统动态分配的端口号
- 客户端程序的端口号由操作系统在这个范围内动态分配。
2. 认识知名端口号
常用的服务器端口号有固定分配,为了使用方便,常见服务器通常使用以下固定端口号:
- SSH 服务器:22 端口
- FTP 服务器:21 端口
- Telnet 服务器:23 端口
- HTTP 服务器:80 端口
- HTTPS 服务器:443 端口
通过执行
vim /etc/services
可以查看知名端口号的详细信息。

注意:
- 有可能是由于某种原因(如误删除或系统配置问题),该文件确实不在你的系统中。你可以通过重新安装相关的软件包来恢复这个文件。对于基于Debian的系统(如Ubuntu),可以使用如下命令:
sudo apt-get install --reinstall netbase
- 对于基于RHEL的系统(如CentOS),可以尝试:
sudo yum reinstall initscripts
- 一个进程是否可以bind多个端口号? ✔️
- 一个端口号是否可以被多个进程bind? ✖️
数据一定是自底向上交付的,一定是从端口号唯一交付给进程,所以我们要保持从端口号到进程的唯一关系。因此2错。
一个进程绑定多个端口号并不破坏端口号到进程的唯一性,从任何端口号到进程都是唯一的,如一个进程绑定两个端口号一个端口号用来发数据,一个端口号用来发指令,因此1对。
3.
netstat
命令
netstat
是用于查看网络状态的重要工具,常见选项如下:
n:显示数字格式,不转换为别名。l:仅列出处于监听(LISTEN)状态的服务。p:显示建立相关链接的程序名。t:仅显示 TCP 相关选项。u:仅显示 UDP 相关选项。a:显示所有选项,默认不显示 LISTEN 相关。

4.
pidof
命令
pidof命令可以通过进程名查看对应的进程 ID。xargs把管道上一个进程输入的管道的内容,以命令行参数的方式拼接在后接命令的后面

二.UDP
0.协议的学习思路
我们未来学习协议都要带着这两个问题去学习
- 学习所有的协议,都有它的报头和有效载荷
- 如何解包(如何将报头和有效载荷进行分离),如何分用

- 报头和有效载荷如何分离
- 有效载荷应该交付给哪一个上层协议(对应的协议字段,方案)
- 认识报头
- 学习该协议周边的问题
之后学习 tcp 协议格式也是这个思路~
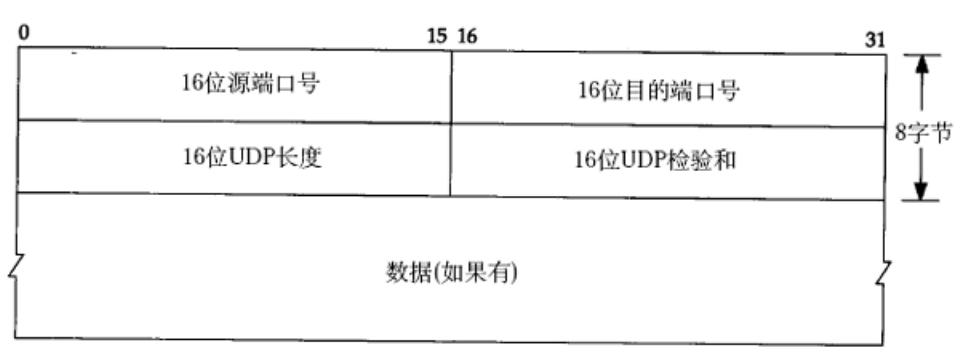
1. UDP 协议报文格式
UDP 报文的宽度为 0-31,前 8 个字节(4 个字段)为 UDP 报头,剩余部分为有效载荷。报文包含以下信息:
- 16 位源端口号:表示数据的来源端口。
- 16 位目的端口号:表示数据的目的端口。
- 1****6 位 UDP 长度:表示整个数据报的长度(UDP 首部 + UDP 数据)。
- **16 位 UDP **校验和:用于检测 UDP 报文是否在传输中损坏,校验失败时报文会被丢弃。
⭕UDP 报头的封装与解包:
- 发送数据时,传输层为数据前面添加 8 字节的 UDP 报头。
- 接收数据时,从报文中提取前 8 个字节作为报头,其余为有效载荷。
所以所谓的报头其实就是一种结构化数据对象
一般在定协议的时候采用的是结构体或者位端的方式。
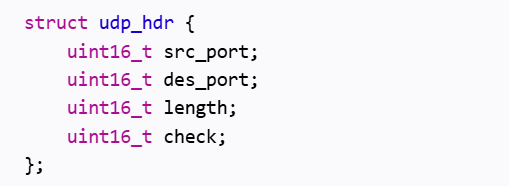
所谓的添加报头,当程序员在应用层调用sendto发送数据,这个sendto其实并没有把数据直接发送到网络里,而是把数据拷贝UDP这个协议中。

在看到UDP报文这张图,脑海中要立即想到协议就是一个结构化的数据,添加报头就是把数据放在缓冲区里然后在缓冲区前面把报头相关字段拿过来,这个报文就构建好了,继续向下交付就好了!
报头与端口映射:
- 每个应用层进程绑定一个端口号,服务端进程显式绑定,客户端由系统动态分配。
- 内核通过哈希表维护端口号与进程 ID 之间的映射,传输层通过端口号找到对应的应用层进程。
2. UDP 的特点
UDP 传输类似于寄信,具有以下特点:
- 无连接:不需要建立连接,直接通过 IP 和端口号传输数据。
- 不可靠:没有确认和重传机制,传输失败不会反馈给应用层。
- 面向数据报:报文有明确边界,数据不会被拆分或合并。
面向数据报:
- 报文有 16 位长度标识,UDP 按原样发送报文,接收端必须按相同方式接收。
- 对方调sendto发送10次报文,对方必须调用recvfrom接收10次报文,次数是1:1的。
例:用UDP传输100个字节的数据
- 如果发送端调用一次sendto,发送100个字节,那么接收端也必须调用对应的一次recvfrom,接收100个字节
- 而不能循环调用10次recvfrom每次接收10个字节
3. UDP 的缓冲区
- 发送缓冲区:UDP 没有真正的发送缓冲区,
sendto直接将数据交给内核处理。 - 接收缓冲区:UDP 有接收缓冲区,但不能保证接收顺序与发送顺序一致,缓冲区满时会丢弃数据。
- 全双工:UDP 的 socket 既能读,也能写,支持全双工通信。
实际上我们用的网络IO接口,其实并不直接是发送和接收窗口,是****拷贝窗口!
关于上面这句话我们通过 TCP 来理解

- 网络IO接口与缓冲区
- 实际使用的网络IO接口,并非直接操作发送和接收窗口,而是拷贝窗口。- 客户端和服务器通过TCP协议通信时,在各自的传输层维护着发送和接收缓冲区。
- 数据发送过程
- 应用层使用
send/write接口并不是直接将数据发送到网络中,而是先拷贝到操作系统(OS)管理的发送缓冲区。- OS决定何时及如何从发送缓冲区向网络发送数据,以及发送多少数据。- 发送的数据经过网络后到达对方的接收缓冲区。
- 应用层使用
- 数据接收过程
- 接收方使用
recv/read接口读取数据时,实际上是将接收到的数据从接收缓冲区拷贝到应用层定义的缓冲区。- 这一过程也是由OS控制,而非直接从网络读取。
- 接收方使用
- 接口的本质
read,write,sendto,recvfrom,send,recv等接口本质上执行的是内存拷贝操作。
- 全双工通信
- 客户端到服务器:客户端的发送缓冲区至服务器的接收缓冲区。- 服务器到客户端:服务器的发送缓冲区至客户端的接收缓冲区。- 双方都拥有独立的发送和接收缓冲区对,使得同时双向通信成为可能。
- 缓冲区的作用
- 提供全双工通信支持。- 增强发送效率,允许应用层在数据拷贝完成后立即返回并继续执行其他任务。- 缓冲区处理包括数据发送时机、数量及丢包情况等,这些都由TCP协议自动管理。
- 生产者-消费者模式
- 数据的产生和消费类似于生产者-消费者模式,其中一方放入数据(生产),另一方负责将数据刷新到网络或取出(消费)。- 此模式支持了系统中的解耦合,能够应对不同时间段内产生的负载不均问题。- 在正常发送情况下,通过拷贝行为代替实际发送,减少了客户端等待时间,提高了整体性能。
什么是以TCP来讲的,那UDP呢?
- UDP没有真正意义上的 发送缓冲区. 调用sendto会直接交给内核, 由内核将数据传给网络层协议进行后续的传输动作;
- UDP没有真正意义上的 发送缓冲区,这是因为它不需要,因为UDP把报头一加直接交给下层,它没有可靠性机制,也不需要把数据暂存下来。
- UDP具有接收缓冲区. 但是这个接收缓冲区不能保证收到的UDP报文的顺序和发送UDP报文的顺序一致; 如果缓冲区满了, 再到达的UDP数据就会被丢弃
- UDP的socket既能读, 也能写, 这个概念叫做 全双工
理解 UDP 先描述再组织的管理:

下三层:传输,网络,数据链路,都在内核中,用 C语言写的,都是先描述再组织的管理
4. UDP 使用注意事项
- UDP 报头中的长度字段为 16 位,因此单个 UDP 报文的最大长度为 64KB(包含 UDP 报头)。

- 传输超过 64KB 的数据时,需在应用层手动分包传输,并在接收端拼装数据。
5. 基于 UDP 的应用层协议
- NFS:网络文件系统
- TFTP:简单文件传输协议
- DHCP:动态主机配置协议
- BOOTP:启动协议(用于无盘设备启动)
- DNS:域名解析协议
当然, 也包括你自己写UDP程序时自定义的应用层协议
下篇文章讲对 TCP 协议进行讲解~
一些方向的了解:
STM32是由STMicroelectronics(意法半导体)生产的基于ARM Cortex-M内核的32位微控制器系列。而ARM本身是一个架构,它提供了多种处理器设计,从低功耗的Cortex-M系列到高性能的Cortex-A系列,广泛应用于嵌入式系统、移动设备和服务器等领域。
下面将分别简要介绍STM32和ARM在嵌入式软件方向的应用:
STM32 微控制器
特点:
- 基于ARM Cortex-M内核。
- 提供了广泛的性能选项,包括不同的处理速度、内存大小以及外设集。
- 支持多种开发工具链和IDE,如Keil, IAR, 以及开源的GCC工具链。
- 拥有丰富的生态系统,包括官方的STM32CubeMX配置工具、HAL库(硬件抽象层)、LL库(底层库)等。
软件开发方向:
- 固件开发:使用C/C++语言编写控制微控制器及其外设的代码。
- RTOS集成:可以与实时操作系统(例如FreeRTOS, RT-Thread)结合,以实现多任务管理。
- 驱动程序开发:为各种传感器和其他外部设备编写驱动程序。
- 中间件开发:开发或集成网络协议栈、文件系统、图形用户界面等中间件。
- 安全应用:利用STM32的安全特性来实现加密算法、安全启动等功能。
- 物联网(IoT)应用:通过Wi-Fi, Bluetooth, LoRa等无线技术连接互联网。
ARM 架构
特点:
- 广泛应用于从智能手机到服务器的各种计算平台。
- ARM提供不同级别的处理器设计,适用于不同的应用场景。
- 强调低功耗设计,适合电池供电的便携式设备。
- 开放性架构,允许第三方厂商根据ARM架构设计自己的处理器。
软件开发方向:
- 裸机编程:直接针对特定的ARM处理器进行编程,不依赖任何操作系统。
- 嵌入式Linux/Android开发:对于更高性能需求的嵌入式系统,可以运行完整的操作系统,比如Linux或者Android。
- **实时操作系统(RTOS)**:用于需要确定响应时间的应用场景,例如工业自动化。
- 安全关键系统:在汽车电子、医疗设备等对安全性要求极高的领域中应用。
- 高级应用程序开发:如果是在带有操作系统的ARM平台上工作,则涉及到应用程序层面的开发,这可能包括GUI开发、多媒体处理等。
无论是在STM32还是更广泛的ARM平台上,嵌入式软件工程师都需要具备良好的编程技能、理解硬件原理,并且熟悉相关的开发工具和技术文档。随着技术的发展,对于网络安全、云服务集成等方面的知识也越来越重要。
版权归原作者 lvy- 所有, 如有侵权,请联系我们删除。