
一、github克隆项目
特别注意下载的是v0.01版本
二、Python环境
1. Python3.9下载以及Pycharm安装
可以参考这位大佬的文章
https://blog.csdn.net/c_lanxiaofang/article/details/109902269
2. 下载torch:
(一) 打开pycharm控制台查看环境:括号里面的是py3.9,与我们创建的python环境一样
(二) 环境正确后安装torch,命令如下
pip installtorch==1.9.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip installtorchvision==0.10.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
3. 其他必须需要的库:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
4. 安装webrtcvad-wheels:
pip install webrtcvad-wheels -i https://pypi.tuna.tsinghua.edu.cn/simple
5. 安装ffmpeg:
安装过程参考:
https://blog.csdn.net/xiaoxueyaoxuexi/article/details/110451006
三、运行代码
1. 下载预训练模型
链接:https://pan.baidu.com/s/1Scp1pzKJVeSa_ZlOQm-wGA
提取码:2021
2. 将saved_models放入项目中的synthesizer目录中

3. 代码修改
找到项目中的“/synthesizer/utils/symbols.py”文件修改代码如下,直接注释上边的_characters,并把下面的_characters放开就OK啦,如下图
4. 终端输入指令
(一)GUI界面:
命令:
python demo_toolbox.py
流程:
- 先“打开本地”或者是录音,上传录音要是.wav格式
- 推荐大家一个m4a转mav的免费网站 https://www.aconvert.com/cn/audio/m4a-to-wav/
- 进行模型选择,按我下面这样就可以,Synthesize选择ceshi,Vocoder选择pretrained
- 再点击右侧的“Synthesize and vocode”
- 左下方点击“Export”可以导出文件 截图:
 (二)web界面: 命令:
(二)web界面: 命令:
python web.py
截图: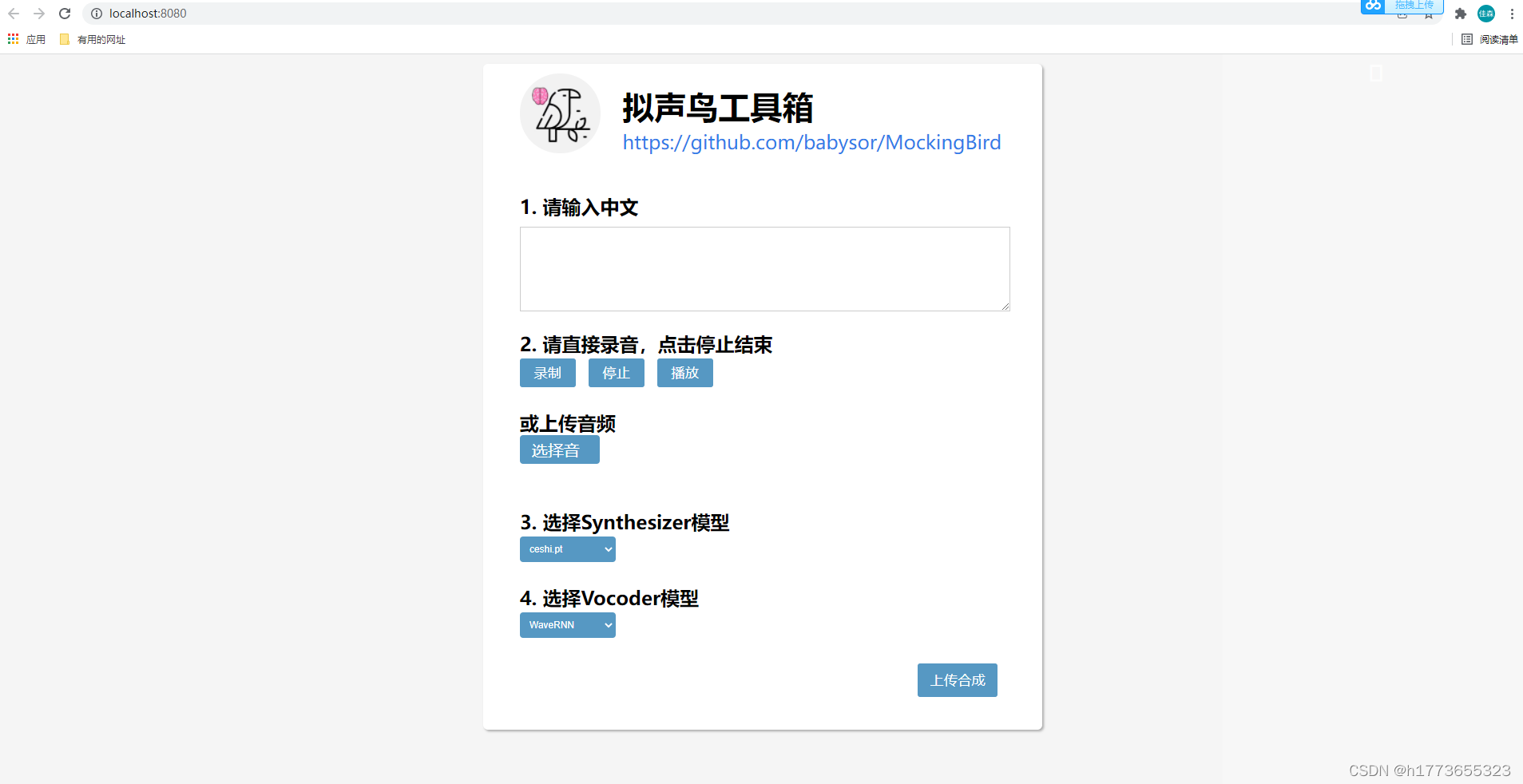
四、音质优化
- 导入模型后将“Enhance vocoder output”勾选好,可以提高清晰度。
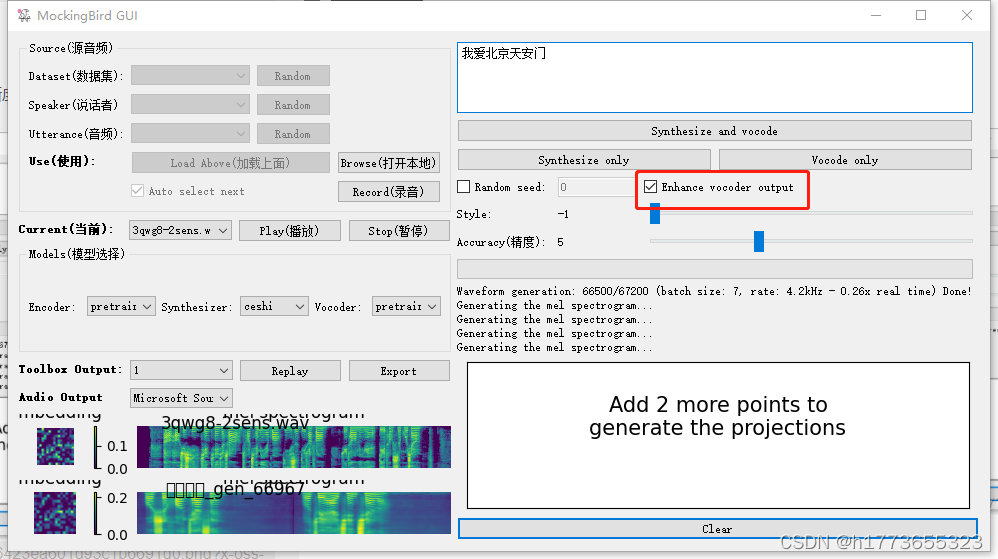
- 可以尝试调整style和accuracy,然后点击“synthesize only”,调节至左下角的图像出现分段,可以看出来是一个一个的吐字,及吐字清晰即可点击“vocode only”,如下图
 效果好的语音如下图的效果:
效果好的语音如下图的效果:
问题反馈
大家有什么问题,可以评论区提问,我了解的话会帮大家解答!
本文转载自: https://blog.csdn.net/h1773655323/article/details/121771643
版权归原作者 h1773655323 所有, 如有侵权,请联系我们删除。
版权归原作者 h1773655323 所有, 如有侵权,请联系我们删除。