
1. SparkSQL的运行流程
1.1 SparkRDD的执行流程回顾
1.2 SparkSQL的自动优化
RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响。而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。这是因为:
RDD:内含数据类型不限格式和结构。
DataFrame:100% 是二维表结构,可以被针对SparkSQL的自动优化,依赖于Catalyst优化器。
1.3 Catalyst优化器
为了解决过多依赖Hive的问题,SparkSQL使用了一个新的SQL优化器替代Hive中的优化器,这个优化器就叫Catalyst,整个SparkSQL架构大致如下:
- API层简单的说就是Spark会通过一些API接受SQL语句。
- 收到SQL语句以后。将其交给Catalyst,Catalyst负责解析SQL,生成执行计划。
- Catalyst的输出应该是RDD的执行计划。
- 最终交给集群运行。
具体流程如下:
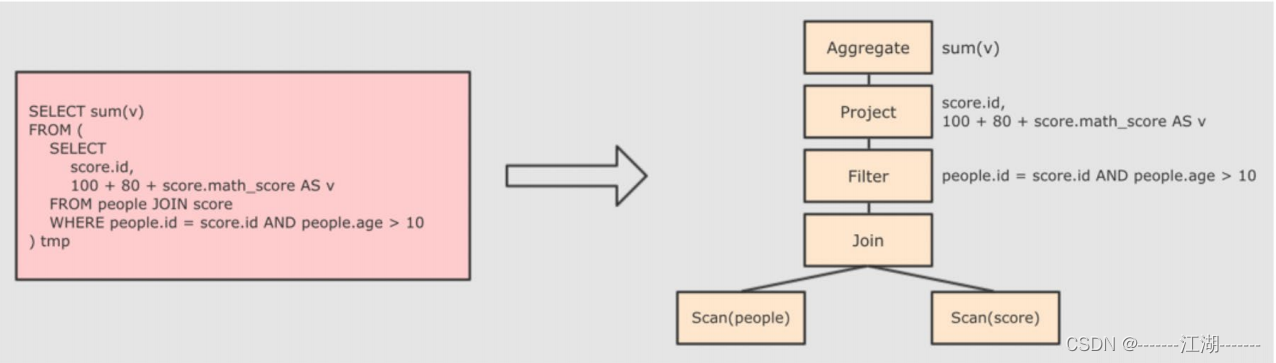
第一步:解析sql,并生成AST(抽象语法树)
第二步:在AST中加入元数据信息
主要为了优化,例如col=col这样的条件,下面是一个简略图: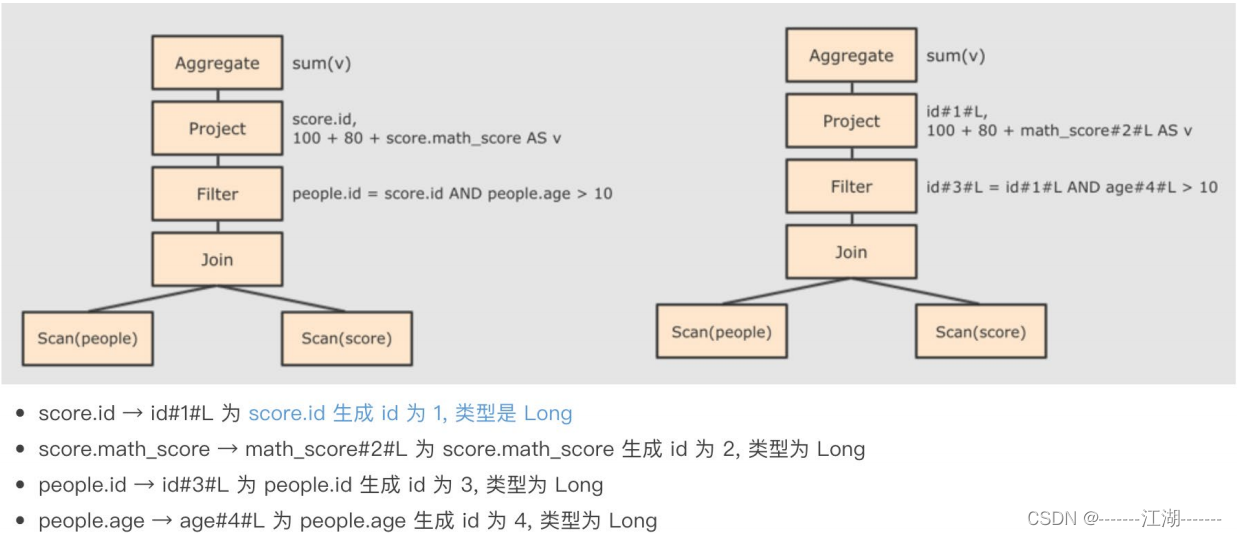
第三步:对已经加入元数据的AST,输出优化器,进行优化
从两种常见的优化开始,简单介绍: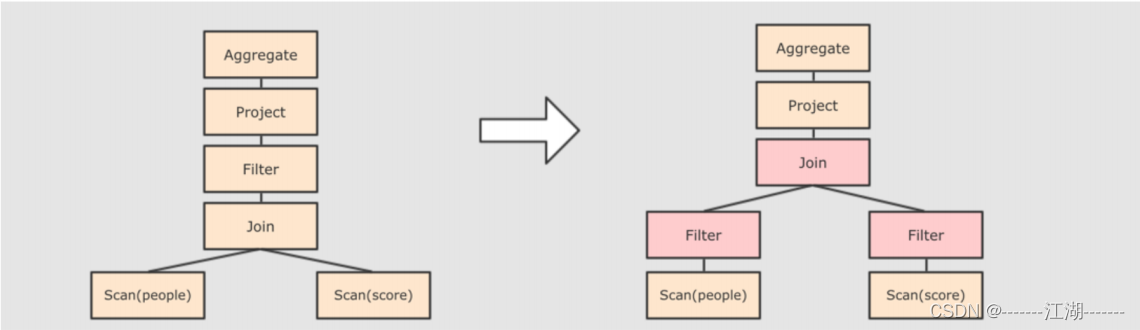
断言下推
将Filter这种可以减少数据集的操作下推,放在Scan的位置,这样可以减少操作时候的数据量。比如第一步中的sql,正常流程是先做JOIN再做WHERE。断言下推后,会先过滤age,然后再join,减少join的数据量提高性能。
列值裁剪
在断言下推后执行裁剪,由于people表之上的操作只用到了id列,所以可以将其他的列裁减掉,这样可以减少处理的数据量,从而优化处理速度,如下图: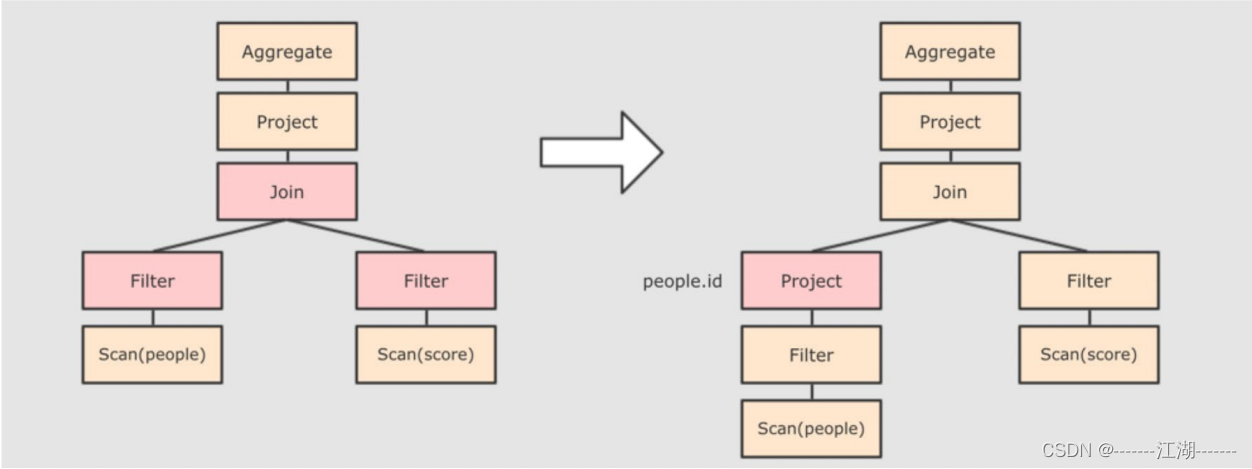
第四步:AST生成物理计划,然后再生成RDD
上面的过程生成的AST其实最终没有办法直接运行,AST叫做逻辑计划,结束后需要生成物理计划,从而生成RDD来运行。
在生成物理计划的时候,会经过成本模型对整棵树再次执行优化,选择一个更好的计划。在生成物理计划后,因为会考虑到性能问题,所以会使用代码生成,在机器运行。
可以使用queryExecution方法查看逻辑执行计划,使用explain方法查看物理执行计划。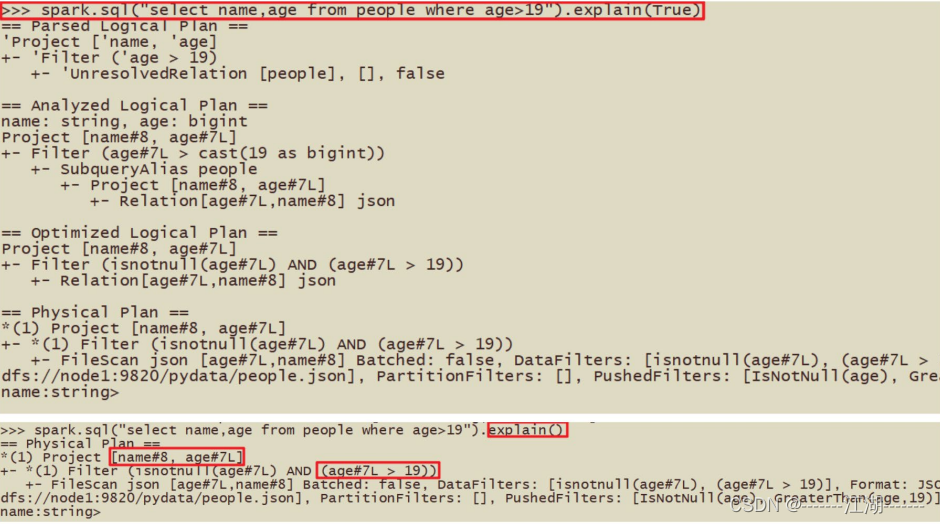
总结
Catalyst的优化大致分为两点:
- 谓词下推\断言下推:将逻辑判断提到前面,减少shuffle阶段的数据量,简单地说就是行过滤,提前执行where。
- 列值裁剪:将加载的列进行裁剪,减少被处理的数据宽度,简单地说就是列过滤,提前规划select字段数量。
列值裁剪有一种非常适合的存储系统:parquet。
1.4 SparkSQL的执行流程

- 提交sparkSQL代码
- catalyst优化 - 生成原始AST语法树- 标记AST元数据- 进行断言下推和列值裁剪,以及其他方面的优化作用在AST上- 得到最终的AST,然后生成执行计划- 将执行计划翻译为RDD代码
- Driver执行环境入口构建(SparkSession)
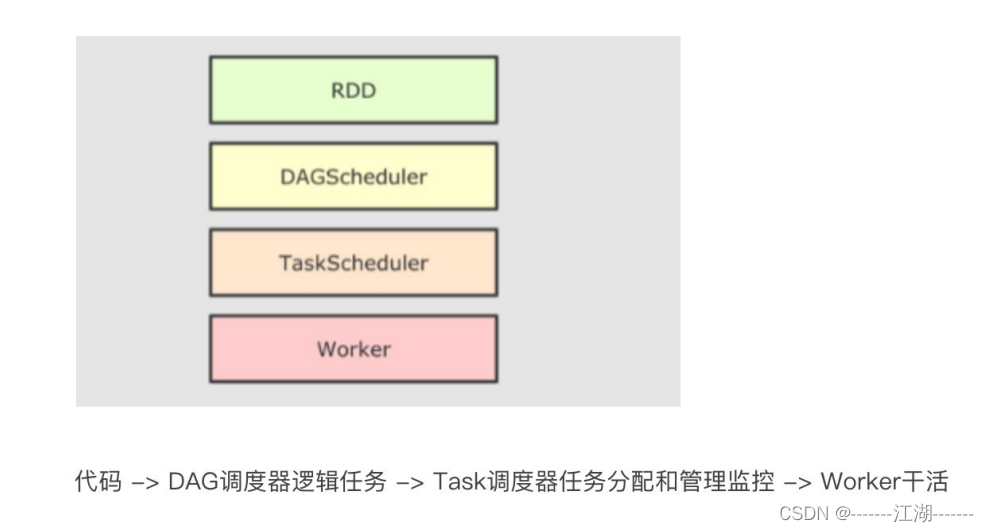
- DAG调度器规划逻辑任务
- TASK调度区分配逻辑任务到具体的Executor上工作并监控管理任务。
- worker干活
2 Spark On Hive
2.1 原理
回顾Hive组件
对于Hive来说,核心的是:
- SQL优化翻译器(执行引擎),翻译SQL到MapReduce,并提交到Yarn执行。
- MetaStore元数据管理中心
Spark On Hive
- 问题 对于Spark来说,自身是一个执行引擎,但是Spark自己没有元数据管理功能,当我们执行sql的时候,spark有能力将其转成RDD提交,但是sql中涉及到的数据在哪里,有什么字段,字段类型,Spark无法知晓。 在SparkSQL代码中,可以写SQL,那是因为表来自DataFrame注册的。DataFrame中有数据,字段,类型,使得Spark可以用来翻译成RDD。
- 解决方案 Spark提供执行引擎能力,Hive的MetaStore提供元数据管理能力,让Spark和MetaStore连接形成Spark On Hive。
2.2 配置
根据原理,就是Spark能够连接上hive的metastore即可。所以首先需要启动metastore,然后Spark需要配置Metastore的IP端口号。
步骤1:在Spark的conf目录中,创建hive-site.xml,内容如下:

步骤2:将mysql的驱动jar放在Spark的jars目录
因为需要连接元数据,会有部分功能连接到mysql。
步骤3:hive配置metastore相关服务
hive配置文件目录内有:hive-site.xml
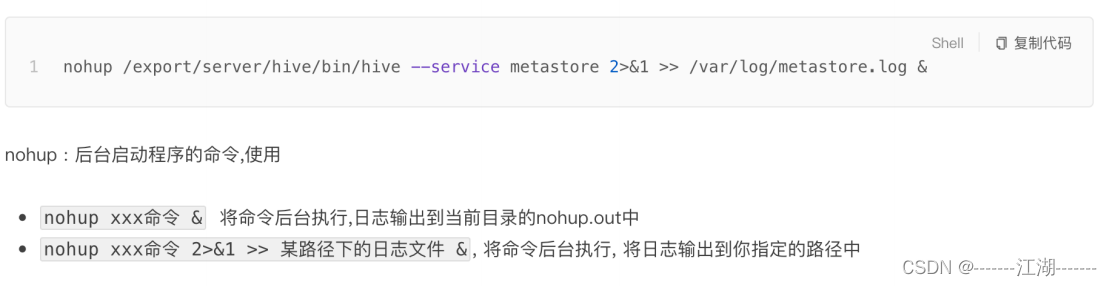
步骤4:启动hive的metastore服务
步骤5:测试

2.3 在代码中集成
前提:确保metastore服务启动好的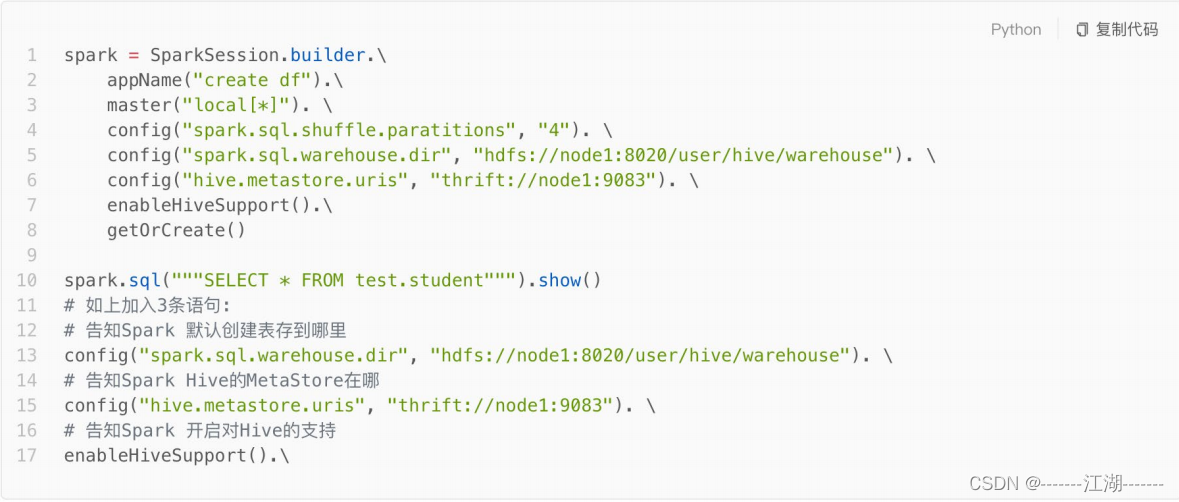
3 分布式SQL执行引擎
3.1 概念
Spark中有一个服务,叫ThriftServer,可以启动并监听10000端口。这个服务对外提供功能,我们可以用数据库工具或者代码连接,直接写sql可以操作Spark。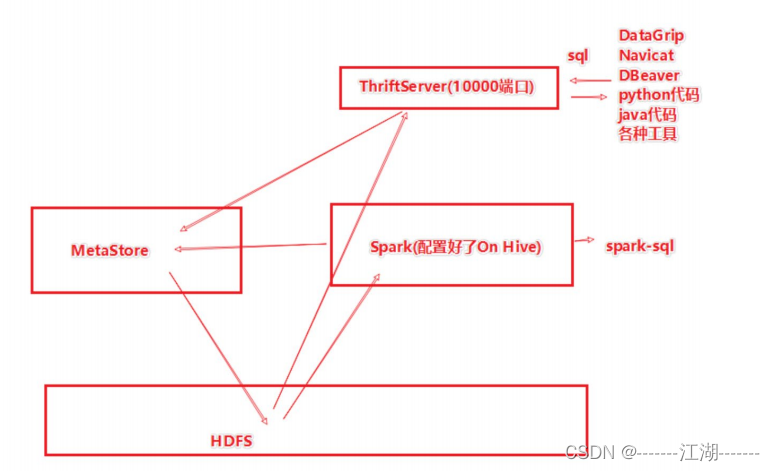
当使用ThriftServer后,相当于是一个持续性的Spark On Hive集成模式,它提供10000端口,持续对外提供服务,外部可以通过这个端口连接上来,写sql,让Spark运行。
3.2 配置
确保:配置好Spark on Hive,启动了ThriftServer。
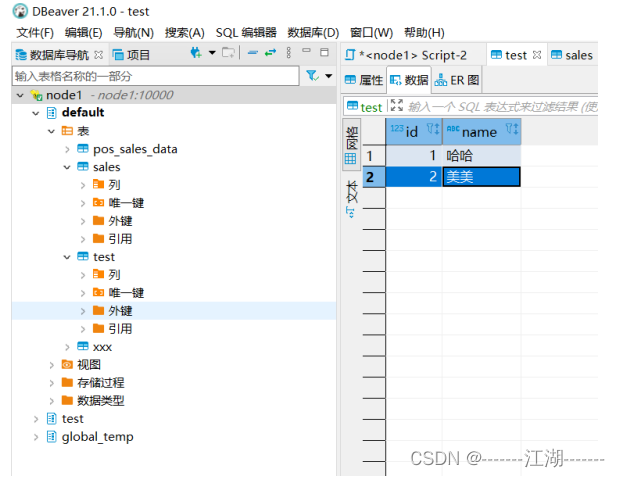
3.3 客户端工具连接
3.4 代码JDBC连接
我使用的是远程Python解释器,同时要使用pyhive的包来操作。
为了安装pyhive包 需要安装一些Linux软件,可以执行如下命令:
安装好前置依赖后,安装pyhive包
代码测试
版权归原作者 技术闲聊DD 所有, 如有侵权,请联系我们删除。