
一、Hive简介
(一)什么是Hive
Hive是基于Hadoop的一个**数据仓库工具**,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。Hive十分适合对数据仓库进行统计分析。
本质:将 HQL 转化成 MapReduce 程序
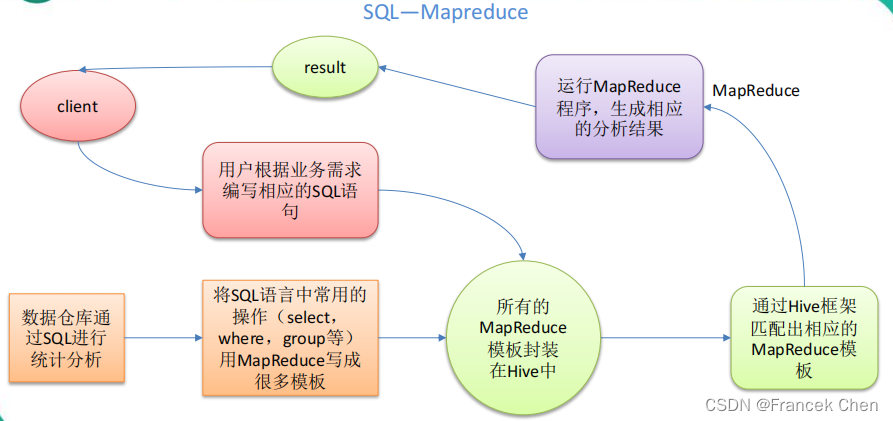
(1)Hive 处理的数据存储在 HDFS
(2)Hive 分析数据底层的实现是 MapReduce
(3)执行程序运行在 Yarn 上
(二)优缺点
1、优点
(1)操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写 MapReduce,减少开发人员的学习成本。
(3)Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
(4)Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
(5)Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
2、缺点
(1)Hive 的 HQL 表达能力有限:
迭代式算法无法表达;
数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却无法实现。(2)Hive 的效率比较低:
Hive 自动生成的 MapReduce 作业,通常情况下不够智能化;
Hive 调优比较困难,粒度较粗。
(三)Hive架构原理

1、用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2、元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore。
3、Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4、驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
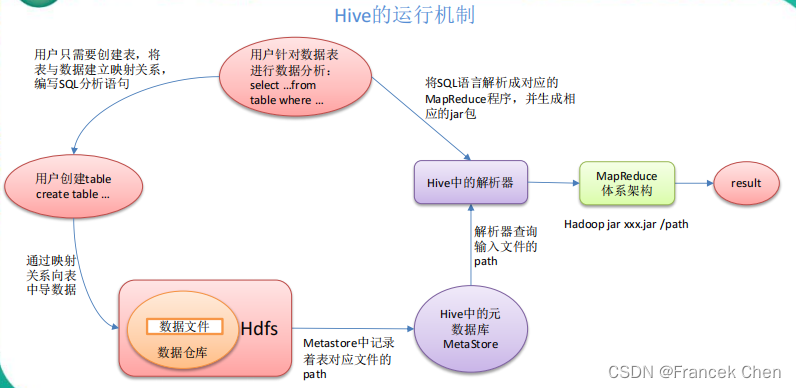
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
(四)Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
1、查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2、数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3、数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据 , 使用 UPDATE … SET 修改数据。
4、执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
5、执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
6、可扩展性
由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
7、数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
二、MySQL的安装配置
MySQL的安装配置可以参考我之前的博客:
在Linux系统中安装MySQL数据库-CSDN博客https://blog.csdn.net/Morse_Chen/article/details/135154114
三、Hive的安装配置
1、下载安装包
下载地址:http://archive.apache.org/dist/hive/
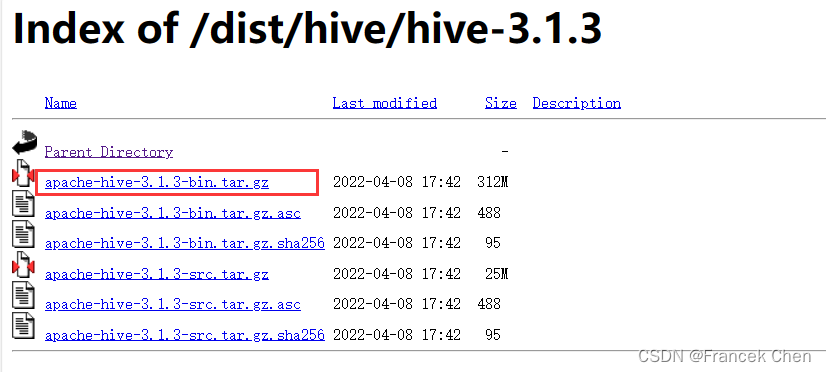
将安装包apache-hive-3.1.3-bin.tar.gz上传到虚拟机“/usr/local/uploads”目录下。
2、解压并改名
[root@bigdata zhc]# cd /usr/local/uploads
[root@bigdata uploads]# tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /usr/local
[root@bigdata uploads]# cd /usr/local
[root@bigdata local]# mv apache-hive-3.1.3-bin hive
3、配置环境变量
[root@bigdata local]# vi /etc/profile
在文件最后加入以下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
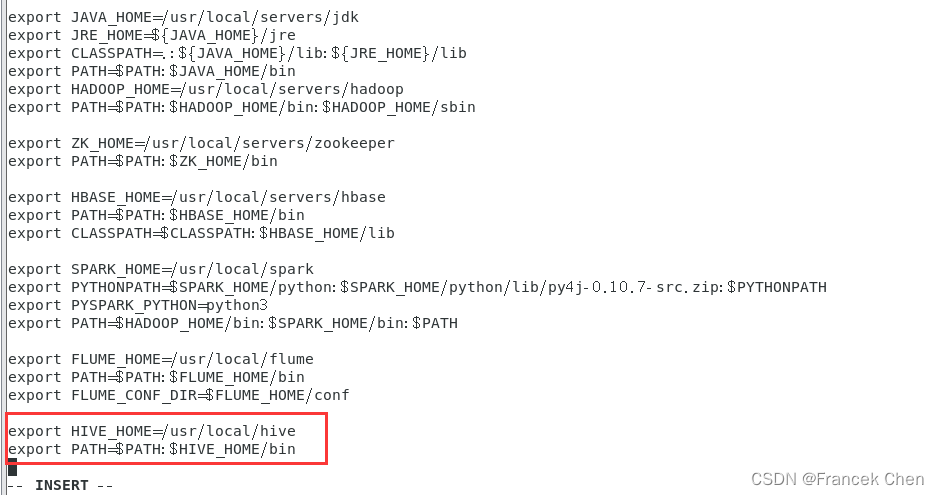
使环境变量生效:
[root@bigdata local]# source /etc/profile
4、修改hive-env.sh文件
[root@bigdata local]# cd /usr/local/hive/conf
[root@bigdata conf]# cp hive-env.sh.template hive-env.sh

在文件中加入以下内容:
export JAVA_HOME=/usr/local/servers/jdk
export HADOOP_HOME=/usr/local/servers/hadoop
export HIVE_HOME=/usr/local/hive

四、Hive的使用
(一)Hive的数据类型
1、基本数据类型
序号
数据类型
Java 数据类型
长度
范围
例子
1
TINYINT
byte
1Byte
-128~127
10
2
SMALLINT
short
2Byte
-32,768~2,767
10
3
INT
int
4Byte
10
4
BIGINT
long
8Byte
-9,223,372,036,854,775,808~9,223,372,036,854,775,807
10
5
BOOLEAN
boolean
布尔类型
TRUE
6
FLOAT
float
单精度浮点数
1.23456
7
DOUBLE
double
双精度浮点数
1.23456
8
STRING
string
字符序列
可指定字符集。可使用单引号和双引号
'hello hive'
"hello hadoop"
9
TIMESTAM
时间戳,纳米精度
整数、浮点数或字符串
1232321232
12312341.21234421
'2017-04-07 15:05:56.1231352'
10
BINARY
字节数组
2、复杂数据类型
序号
数据类型
描述
示例
1
STRUCT
STRUCT封装一组有名字的字段,其类型可以是任意的基本类型,可以通过“点”号来访问元素的内容。
names('Zoro','Jame')
2
MAP
MAP是一组键—值对元组集合,使用数组表示法可以访问元素。其中key只能是基本类型,值可以是任意类型。
money('Zoro',1000,
'Jame',800)
3
ARRAY
ARRAY类型是由一系列相同数据类型元素组成的,每个数组元素都有一个编号,从零开始。例如,fruits['apple','orange','mango'],可通过fruits[1]来访问orange
fruits('apple','orange','mango')
4
UNION
UNION类似于C语言中的UNION结构,在给定的任何一个时间点,UNION类型可以保存指定数据类型中的任意一种,类型声明语法为UNIONTYPE<data_type,data_type……>,每个UNION类型的值都通过一个整数来表示其类型,这个整数位声明时的索引从0开始。
(二)Hive的基本操作
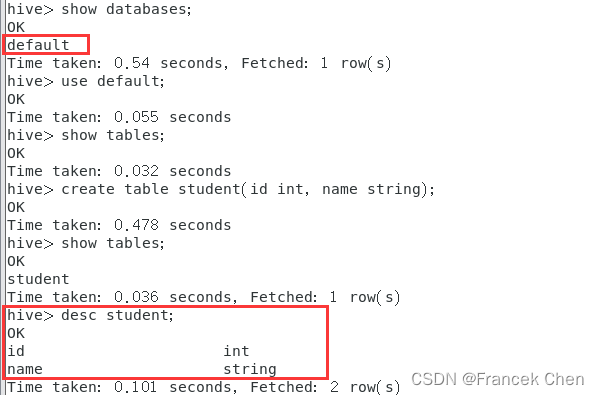
1、创建数据库和表
hive> show databases;
hive> use default;
hive> show tables;
hive> create table student(id int, name string);
hive> show tables;
hive> desc student;
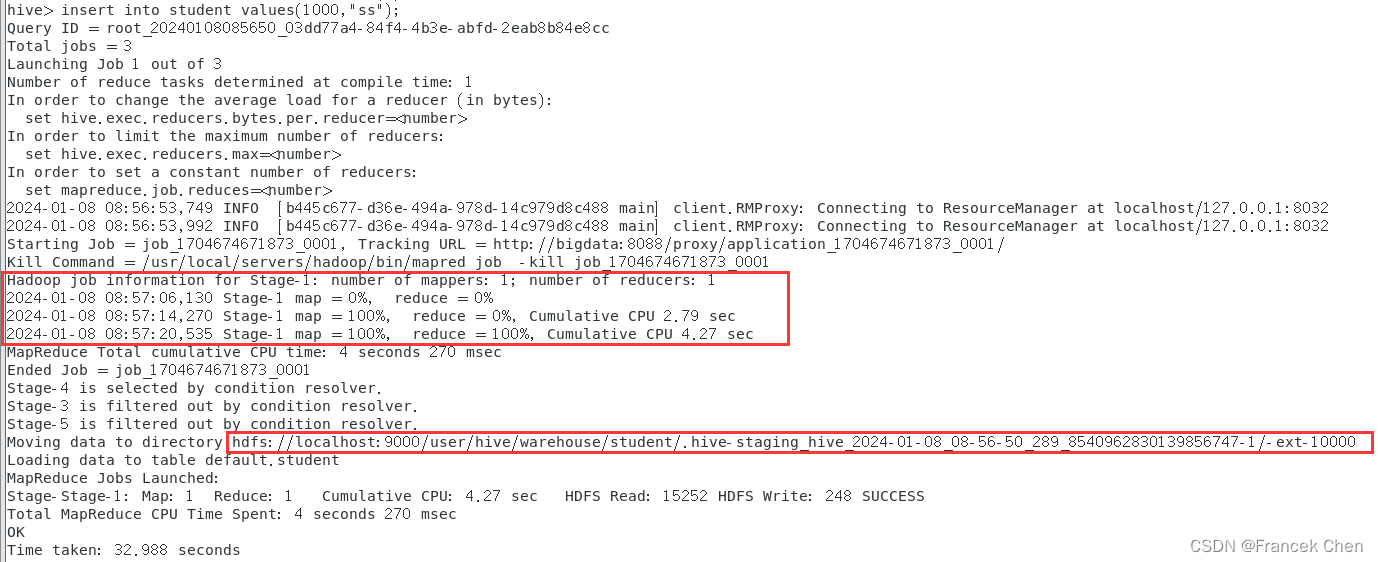
2、向表中插入数据
hive> insert into student values(1000,"ss");
在HDFS中也能查看Hive数据库信息:
[root@bigdata zhc]# hdfs dfs -ls /user/hive/warehouse/student/

3、查看表中数据
hive> select * from student;

4、查看HDFS中的信息
hive> dfs -ls /;

5、加载本地文件到数据库表中
[root@bigdata zhc]# cd /home/zhc/mycode/
[root@bigdata mycode]# mkdir hive
[root@bigdata mycode]# cd hive
[root@bigdata hive]# vi student.txt
1001 zhangshan
1002 lishi
1003 zhaoliu
然后我们就会发现加入的数据都是NULL,这样更改:

hive> drop table if exists student;
hive> CREATE TABLE student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
hive> load data local inpath '/home/zhc/mycode/hive/student.txt' into table student;
hive> select * from student;
就可以发现数据能够正常查看:

五、配置Hive元数据存储到MySQL
1、修改hive-site.xml文件
如果没有这个文件,在conf目录新建。
[root@bigdata conf]# vi hive-site.xml
在文件中加入以下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.191.200:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>MYsql123!</value>
<description>password to use against metastore database</description>
</property>
</configuration>
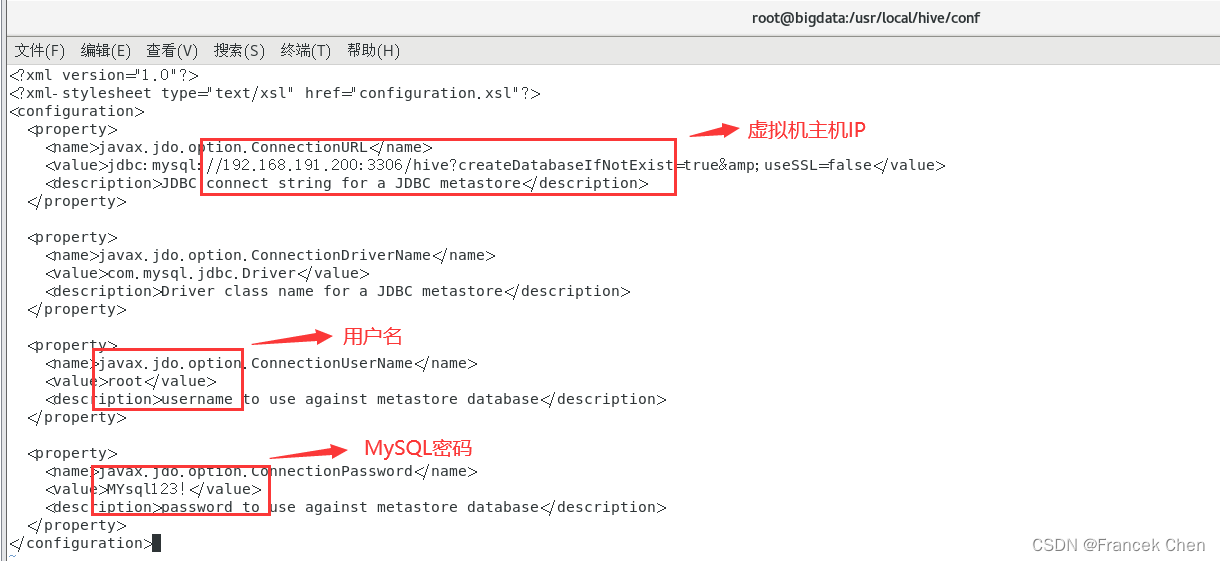
此文件是为了配置Hive元数据存储到MySQL,希望将Hive元数据写入到MySQL的metastore数据库。
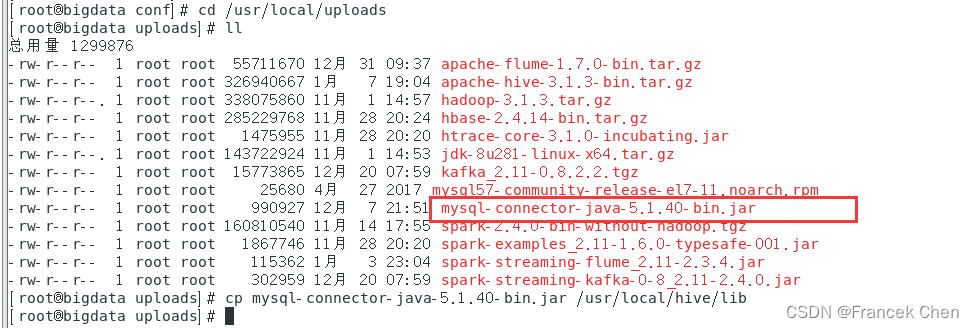
2、上传MySQL连接驱动
将mysql-connector-java-5.1.40-bin.jar复制到“/usr/local/hive/lib”目录下。
[root@bigdata conf]# cd /usr/local/uploads
[root@bigdata uploads]# cp mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
3、初始化Hive元数据库
修改为采用MySQL存储元数据。(默认的是derby数据库)
[root@bigdata conf]# schematool -initSchema -dbType mysql
报如下错误:

原因是hadoop和hive的两个guava.jar版本不一致,两个jar位置分别位于下面两个目录:
/usr/local/hive/lib/guava-19.0.jar
/usr/local/servers/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar
解决办法是删除低版本的那个,将高版本的复制到低版本目录下。
[root@bigdata lib]# cd /usr/local/hive/lib
[root@bigdata lib]# rm -f guava-19.0.jar
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar .
若再次运行初始化命令,还有下面类似的报错:

这个是mysql中权限不够,添加权限如下:
(1)进入mysql数据库命令行
(2)设置root账号密码为MYsql123!可以访问用任何ip访问mysql服务器
mysql> grant all privileges on *.* to root@"%" identified by "MYsql123!";
这相当于是给IP-xxx.xxx.xxx.xxx赋予了所有的权限,包括远程访问权限,%百分号表示允许任何IP访问数据库。
(3)然后再输入 flush privileges;
(4)在Linux服务器上重启MySQL

再次运行初始化命令,出现如下结果则表示成功。

4、验证元数据
(1)启动Hadoop和MySQL服务
这里注意:启动hive之前,必须启动hdfs和yarn!
[root@bigdata zhc]# start-all.sh
[root@bigdata zhc]# systemctl start mysqld.service
[root@bigdata zhc]# systemctl status mysqld.service
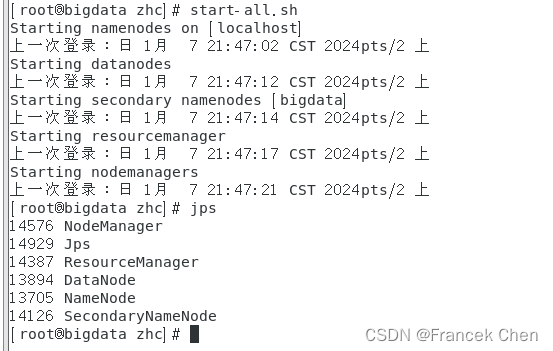

(2)启动Hive
[root@bigdata zhc]# cd /usr/local/hive
[root@bigdata hive]# bin/hive
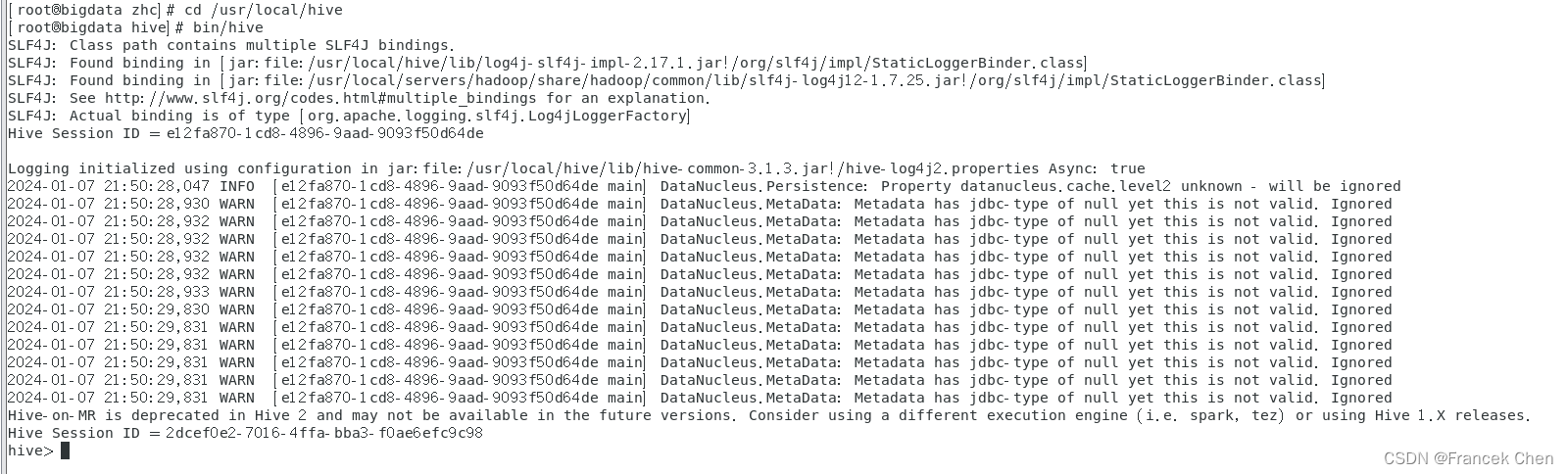
(3)进入MySQL
[root@bigdata zhc]# mysql -u root -p
mysql> show databases;
这里看到多出了一个hive数据库:
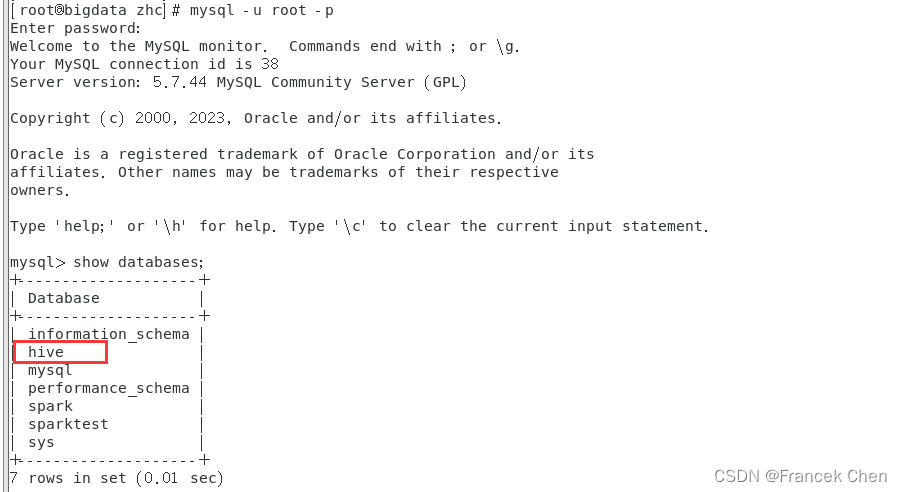
(4)查看元数据库hive
mysql> use hive;
mysql> show tables;


查看到hive元数据库中的表格。
至此,配置Hive元数据存储到MySQL就成功了!
版权归原作者 Francek Chen 所有, 如有侵权,请联系我们删除。