
文章目录
在之前的博客中我通过
MySQL数据库实现了积分和积分排行榜功能,在数据量大和并发量高的情况下会有以下缺点:
- SQL编写复杂;
- 数据量大,执行统计SQL慢;
- 高并发下会拖累其他业务表的操作,导致系统变慢;
使用 Sorted Sets 保存用户的积分总数,因为 Sorted Sets 有 score 属性,能够方便保存与读取,使用指令:
# 添加元素的分数,如果member不存在就会自动创建
ZINCRBY key increment member
# 按分数从大到小进行读取
zrevrange key
# 根据分数从大到小获取member排名
zrevrank key member
修改添加积分方法
当将用户积分记录插入数据库后,同时利用
ZINCRBY
指令,将数据存入Redis中,这里不使用
ZADD
的原因是当用户不存在记录要插入,而且存在时需要将分数累加。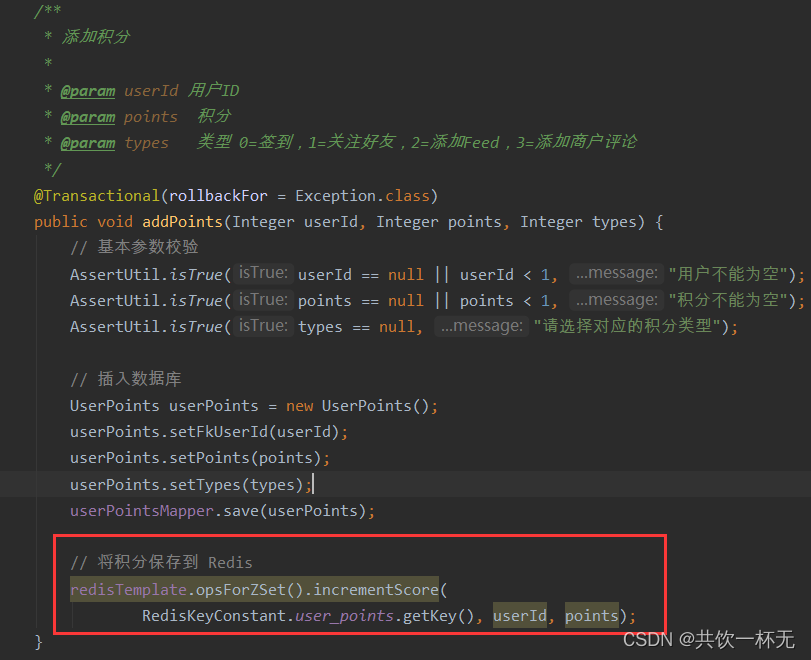
积分排行控制层redis实现
/**
* 查询前 20 积分排行榜,同时显示用户排名 -- Redis
*
* @param access_token
* @return
*/@GetMapping("redis")publicResultInfofindDinerPointsRankFromRedis(String access_token){List<UserPointsRankVO> ranks = userPointsService.findUserPointRankFromRedis(access_token);returnResultInfoUtil.buildSuccess(request.getServletPath(), ranks);}
积分排行业务逻辑层
- 排行榜:从Redis中根据user:points的key按照score的排序进行读取,这里使用Redis的
ZREVRANGE指令,但在ZREVRANGE指令只返回member,不返回score,在RedisTemplate的ZSetOperations中有一个一个API方法叫reverseRangeWithScores(key, start, end)其中start从0开始,返回的是member和score,底层是将ZREVRANGE与ZSCORE指令进行组装。 - 个人排名:使用
REVRANK和ZSCORE操作进行读取;
/**
* 查询前 20 积分排行榜,并显示个人排名 -- Redis
*
* @param accessToken
* @return
*/publicList<UserPointsRankVO>findUserPointRankFromRedis(String accessToken){// 获取登录用户信息SignInUserInfo signInUserInfo =loadSignInUserInfo(accessToken);// 统计积分排行榜Set<ZSetOperations.TypedTuple<Integer>> rangeWithScores = redisTemplate.opsForZSet().reverseRangeWithScores(RedisKeyConstant.user_points.getKey(),0,19);if(rangeWithScores ==null|| rangeWithScores.isEmpty()){returnLists.newArrayList();}// 初始化用户 ID 集合List<Integer> rankuserIds =Lists.newArrayList();// 根据 key:用户 ID value:积分信息 构建一个 MapMap<Integer,UserPointsRankVO> ranksMap =newLinkedHashMap<>();// 初始化排名int rank =1;// 循环处理排行榜,添加排名信息for(ZSetOperations.TypedTuple<Integer> rangeWithScore : rangeWithScores){// 用户IDInteger userId = rangeWithScore.getValue();// 积分int points = rangeWithScore.getScore().intValue();// 将用户 ID 添加至用户 ID 集合
rankuserIds.add(userId);UserPointsRankVO userPointsRankVO =newUserPointsRankVO();
userPointsRankVO.setId(userId);
userPointsRankVO.setRanks(rank);
userPointsRankVO.setTotal(points);// 将 VO 对象添加至 Map 中
ranksMap.put(userId, userPointsRankVO);// 排名 +1
rank++;}// 获取 users 用户信息ResultInfo resultInfo = restTemplate.getForObject(usersServerName +"findByIds?access_token=${accessToken}&ids={ids}",ResultInfo.class, accessToken,StrUtil.join(",", rankuserIds));if(resultInfo.getCode()!=ApiConstant.SUCCESS_CODE){thrownewParameterException(resultInfo.getCode(), resultInfo.getMessage());}List<LinkedHashMap> dinerInfoMaps =(List<LinkedHashMap>) resultInfo.getData();// 完善用户昵称和头像for(LinkedHashMap dinerInfoMap : dinerInfoMaps){ShortUserInfo shortDinerInfo =BeanUtil.fillBeanWithMap(dinerInfoMap,newShortUserInfo(),false);UserPointsRankVO rankVO = ranksMap.get(shortDinerInfo.getId());
rankVO.setNickname(shortDinerInfo.getNickname());
rankVO.setAvatarUrl(shortDinerInfo.getAvatarUrl());}// 判断个人是否在 ranks 中,如果在,添加标记直接返回if(ranksMap.containsKey(signInUserInfo.getId())){UserPointsRankVO rankVO = ranksMap.get(signInUserInfo.getId());
rankVO.setIsMe(1);returnLists.newArrayList(ranksMap.values());}// 如果不在 ranks 中,获取个人排名追加在最后// 获取排名Long myRank = redisTemplate.opsForZSet().reverseRank(RedisKeyConstant.user_points.getKey(), signInUserInfo.getId());if(myRank !=null){UserPointsRankVO me =newUserPointsRankVO();BeanUtils.copyProperties(signInUserInfo, me);
me.setRanks(myRank.intValue()+1);// 排名从 0 开始
me.setIsMe(1);// 获取积分Double points = redisTemplate.opsForZSet().score(RedisKeyConstant.user_points.getKey(),
signInUserInfo.getId());
me.setTotal(points.intValue());
ranksMap.put(signInUserInfo.getId(), me);}returnLists.newArrayList(ranksMap.values());}
Redis排行榜测试
查询结果如下: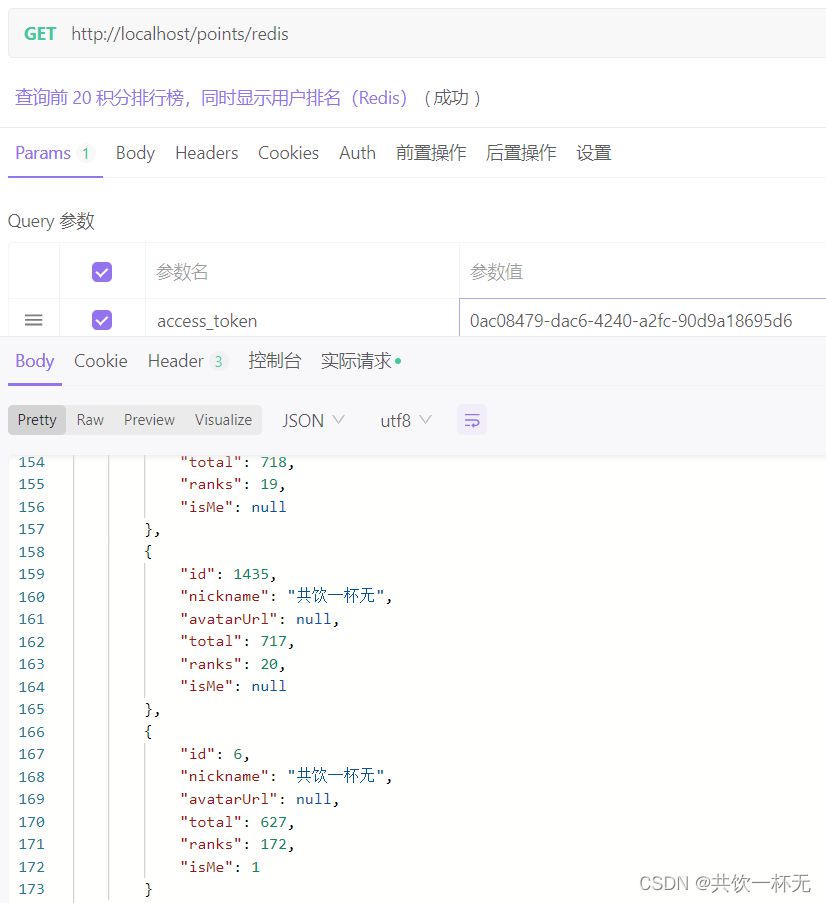
{"code":1,"message":"Successful.","path":"/redis","data":[{"id":1171,"nickname":"共饮一杯无","avatarUrl":null,"total":773,"ranks":1,"isMe":null},{"id":482,"nickname":"共饮一杯无","avatarUrl":null,"total":772,"ranks":2,"isMe":null},{"id":161,"nickname":"共饮一杯无","avatarUrl":null,"total":762,"ranks":3,"isMe":null},{"id":740,"nickname":"共饮一杯无","avatarUrl":null,"total":757,"ranks":4,"isMe":null},{"id":1629,"nickname":"共饮一杯无","avatarUrl":null,"total":754,"ranks":5,"isMe":null},{"id":912,"nickname":"共饮一杯无","avatarUrl":null,"total":747,"ranks":6,"isMe":null},{"id":213,"nickname":"共饮一杯无","avatarUrl":null,"total":744,"ranks":7,"isMe":null},{"id":1477,"nickname":"共饮一杯无","avatarUrl":null,"total":742,"ranks":8,"isMe":null},{"id":771,"nickname":"共饮一杯无","avatarUrl":null,"total":737,"ranks":9,"isMe":null},{"id":791,"nickname":"共饮一杯无","avatarUrl":null,"total":736,"ranks":10,"isMe":null},{"id":1989,"nickname":"共饮一杯无","avatarUrl":null,"total":735,"ranks":11,"isMe":null},{"id":1027,"nickname":"共饮一杯无","avatarUrl":null,"total":735,"ranks":12,"isMe":null},{"id":492,"nickname":"共饮一杯无","avatarUrl":null,"total":734,"ranks":13,"isMe":null},{"id":1743,"nickname":"共饮一杯无","avatarUrl":null,"total":733,"ranks":14,"isMe":null},{"id":1529,"nickname":"共饮一杯无","avatarUrl":null,"total":729,"ranks":15,"isMe":null},{"id":242,"nickname":"共饮一杯无","avatarUrl":null,"total":727,"ranks":16,"isMe":null},{"id":1126,"nickname":"共饮一杯无","avatarUrl":null,"total":725,"ranks":17,"isMe":null},{"id":796,"nickname":"共饮一杯无","avatarUrl":null,"total":719,"ranks":18,"isMe":null},{"id":418,"nickname":"共饮一杯无","avatarUrl":null,"total":718,"ranks":19,"isMe":null},{"id":1435,"nickname":"共饮一杯无","avatarUrl":null,"total":717,"ranks":20,"isMe":null},{"id":6,"nickname":"共饮一杯无","avatarUrl":null,"total":627,"ranks":172,"isMe":1}]}
可以看到id为6的用户排名172,同时展示排名前20名的数据。
使用 JMeter 压测对比
通过JMeter分别对数据库和Redis两种方式实现的积分排行榜进行压力测试(5000并发),可以发现Redis在响应速度,吞吐量上面都提升明显,同时异常率更低。
使用Sorted Sets优势:
- Redis本身内存数据库,读取性能高;
- Sorted Sets底层是SkipList + ZipList既能保证有序又能对数据进行压缩存储;
- Sorted Sets操作简单,几个命令搞定;
Redis Sorted Sets是类似Redis Sets数据结构,不允许重复项的String集合。不同的是Sorted Sets中的每个成员都分配了一个分数值(score),它用于在Sorted Sets中进行成员排序,从最小值到最大值。Sorted Sets中所有的成员都是唯一的,其分数(score)是可以重复的,即是说一个分数可能会对应多个值。
用Sorted Sets可以非常快的进行添加、删除、或更新成员,其复杂度是
O(m*log(n))
,m是添加或查询的成员数量。因为成员是按照顺序添加的,所以可以非常快的通过score或者索引进行范围查询。访问Sorted Sets中间的元素也是非常快的,因此可以用sort sets作为一个不重复的小型有序列表。 通过Sorted Sets可以快速操作任何你想做的事情:排序成员,判断成员是否在集合中,快速访问集合中间的成员。
总的来说,在其他数据库比较难完成的任务,用Sorted Sets可以更快更优性能的完成。
更多Sorted Sets的用法可以查看官方文档。
本文内容到此结束了,
如有收获欢迎点赞👍收藏💖关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问💬欢迎各位指出。
主页:共饮一杯无的博客汇总👨💻保持热爱,奔赴下一场山海。🏃🏃🏃
版权归原作者 共饮一杯无 所有, 如有侵权,请联系我们删除。