
一、单聚合函数搜索
AggregationBuilders.terms 相当于sql中的group by
1. 搜索province(省份)字段每个省份的数量有多少
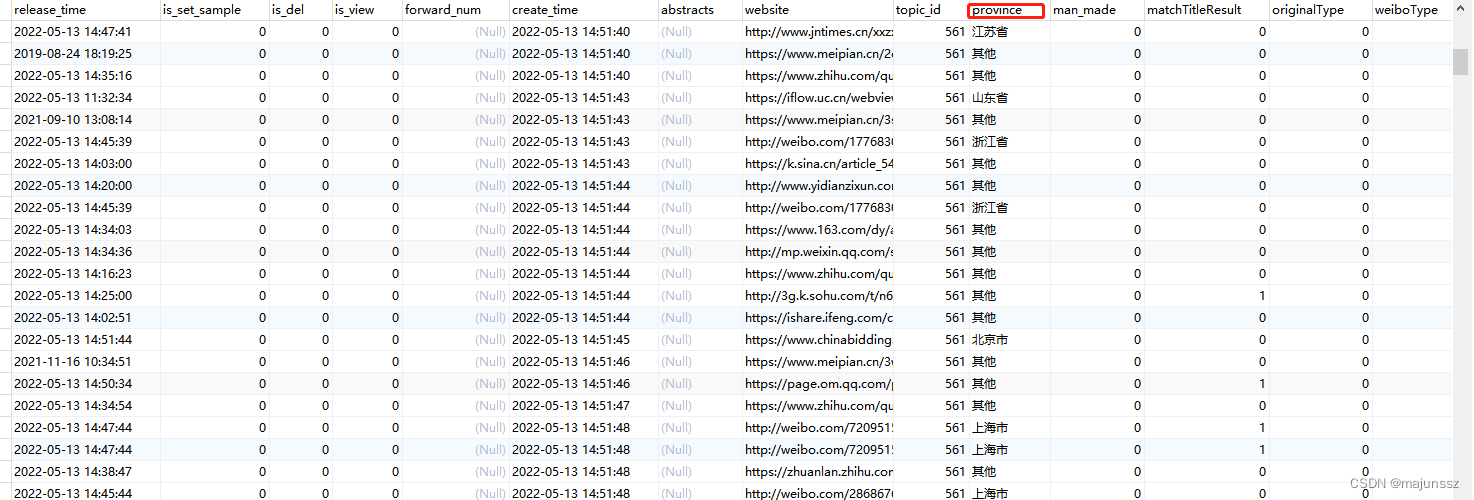
如下图数据库表1(我们es和数据库表是同步的,且结构一样,所以拿数据库表字段举例)。
** 需求**:现es中有字段province(省份),该字段内容为全国各省名字,现在需要求出每个省份有多少条数据。
代码如下:
@Autowired
RestHighLevelClient client;
//MediaHeatBean 为我的实体类,需要换成你自己的实体类
public List<MediaHeatBean> selectMediaHeatES(MediaHeatBean infoPushData) {
SearchRequest searchRequest = new SearchRequest();
// 设置索引库的名称
searchRequest.indices("topicanalysismsg");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (Objects.nonNull(infoPushData.getTopicId())) {//topicId
searchSourceBuilder.query(boolQueryBuilder.must(QueryBuilders.matchBoolPrefixQuery("topicId", infoPushData.getTopicId())));
}
if (Objects.nonNull(infoPushData.getMediaLink())) {//mediaLink 环节
searchSourceBuilder.query(boolQueryBuilder.must(QueryBuilders.matchBoolPrefixQuery("mediaLink", infoPushData.getMediaLink())));
}
searchSourceBuilder.query(boolQueryBuilder.must(QueryBuilders.matchBoolPrefixQuery("isDel", 0)));
//分组
searchSourceBuilder.size(0);
//对province字段进行分组搜索
TermsAggregationBuilder aggregation = AggregationBuilders
//别名
.terms("province")
//聚合字段名
.field("province")
//聚合结果数据量,默认只返回前十条
.size(100);
searchSourceBuilder.trackTotalHits(true);
searchSourceBuilder.aggregation(aggregation);
searchRequest.source(searchSourceBuilder);
List<MediaHeatBean> result = new ArrayList<>();
SearchResponse response;
try {
response = client.search(searchRequest, RequestOptions.DEFAULT);
log.info("response is {}", response);
//从桶中取出该字段分组后的内容
Terms byAgeAggregation = response.getAggregations().get("province");
for (Terms.Bucket buck : byAgeAggregation.getBuckets()) {
MediaHeatBean aggregationForOne = new MediaHeatBean();
//获取当前省份的数量
aggregationForOne.setProvinceSum((int) buck.getDocCount());
//获取当前省份的名称
aggregationForOne.setMediaLink(buck.getKeyAsString());
result.add(aggregationForOne);
}
} catch (IOException e) {
log.error("[EsClientConfig.groupByField][error][fail to query]", e);
}
return result;
}
搜索后的数据如下图:(实体类中省份的字段给错了,应该为province),provinceSum为该省份再es索引库中共有多少条数据。

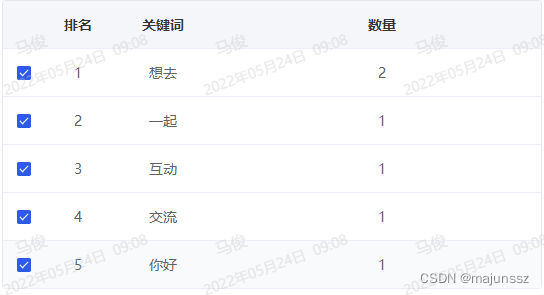
2.查询“content”字段中词语出现频率最高的五个词语(词频统计)
需求:es索引库中content为内容字段,现需要得出所有数据中内容中词语出现频率最高的五个词语(也可以叫词频统计)
@Autowired
RestHighLevelClient client;
public List<CommentCurve> selectTopfiveEs(Integer topicId) {
ArrayList<String> indexes = new ArrayList<>();
// 1.1 构建查询请求对象,指定查询的索引名称
SearchRequest searchRequest = new SearchRequest("topicprecisecomment");
//5 创建查询条件构建器 SearchSourceBuilder
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
sourceBuilder.size(0);
//3.3 构建agg查询,获取当前路径
sourceBuilder.query(boolQueryBuilder.must(QueryBuilders.matchQuery("topicId", topicId)));
TermsAggregationBuilder aggregationBuilder = AggregationBuilders.terms("content").field("content").size(100);
sourceBuilder.aggregation(aggregationBuilder);
//4 添加查询条件构建器SearchSourceBuilder
searchRequest.source(sourceBuilder);
//6 准确计数
sourceBuilder.trackTotalHits(true);
// 查询,获取查询结果
SearchResponse search = null;
//将桶中的age数据获取到
List<CommentCurve> list = new ArrayList<>();
try {
search = client.search(searchRequest, RequestOptions.DEFAULT);
// 7 获取聚会结果
Aggregations aggregations = search.getAggregations();
// 8 将结果转为map
Map<String, Aggregation> aggregationMap = aggregations.asMap();
// 9 获取结果中上面定义的ages里面的数据,并将结果转为Term类型
Terms ages = (Terms) aggregationMap.get("content");
//获取桶里面的数据
List<? extends Terms.Bucket> buckets = ages.getBuckets();
//获取当前所有的全部请求数量
int num = 0;
for (Terms.Bucket bucket : buckets) {
CommentCurve commentCurve = new CommentCurve();
Object key = bucket.getKey();
long docCount = bucket.getDocCount();
//因为一个字不算词语,所有进行比较,词语的字数必须大于1
if(key.toString().length()>1){
num ++;
commentCurve.setMainkeyword(key.toString());
commentCurve.setAmount((int)docCount);
list.add(commentCurve);
if(num == 5){
break;
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
搜出来如下图 ,关键字就是所有内容中出现频率最高的词语,数量则是该词语在所有内容中出现的次数。
二、双重聚合函数搜索
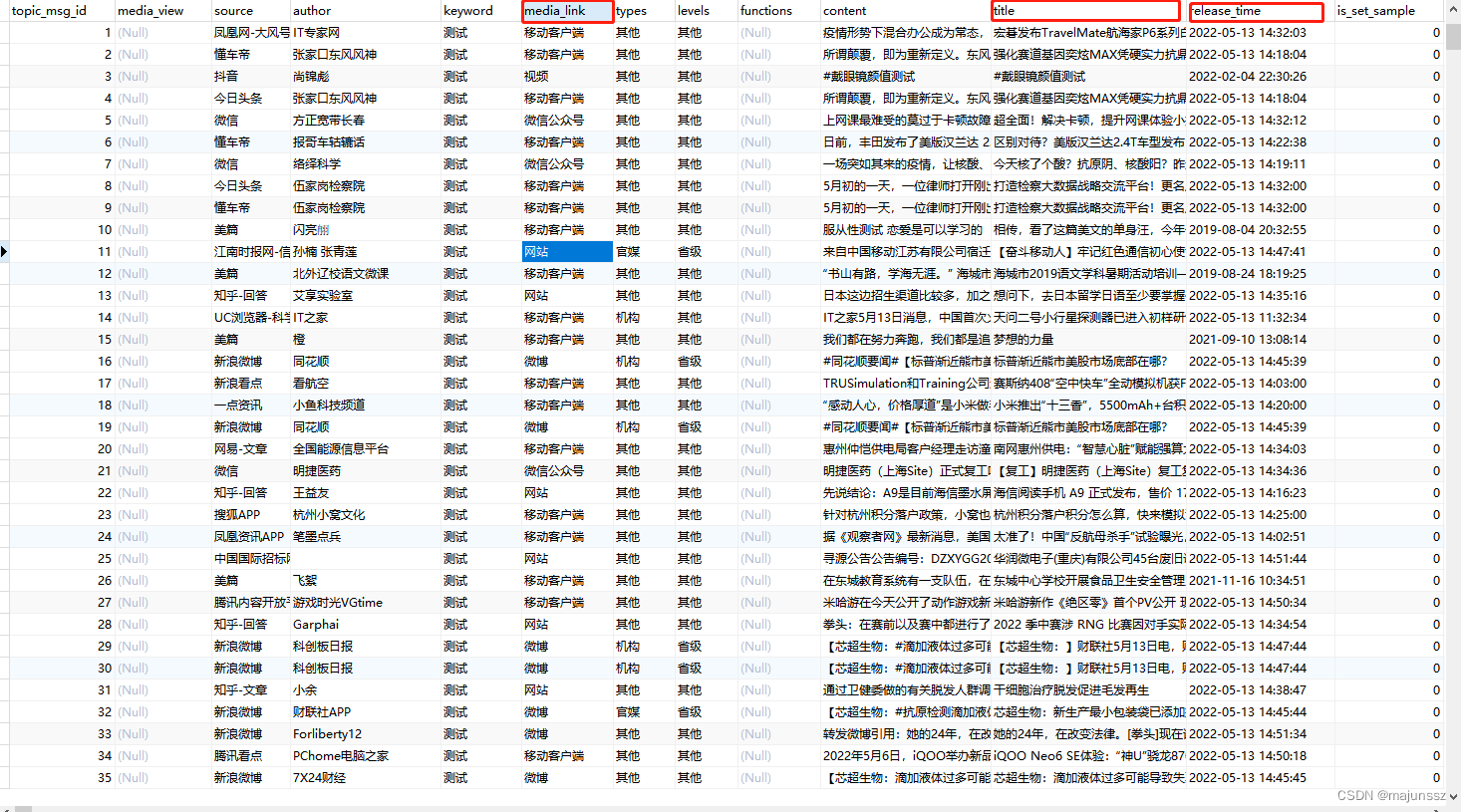
如下图数据库表1(我们es和数据库表是同步的,且结构一样,所以拿数据库表字段举例),其中有个字段media_link代表媒体类型,该字段有移动客户端、视频、微信公众号、网站等几类数据。
需求:现需要求出移动客户端、视频、微信公众号、网站等媒体环节第一次出现的时间、标题(title)、作者(author)等信息。也可以称为首发媒体(环节)(通俗讲就是:移动客户端第一次出现的时间、视频第一次出现的时间、微信公众号第一次出现的时间等)。现在就需要用到双重聚合函数。
代码如下:
@Autowired
RestHighLevelClient client;
public List<StartMediaBean> startMediaes(Integer topicId) {
SearchRequest searchRequest = new SearchRequest();
// 设置索引库的名称
searchRequest.indices("topicanalysismsg");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if (topicId != null) {//topicId
//下面俩行为我的条件搜索,你可以根据自己的需求进行修改
searchSourceBuilder.query(boolQueryBuilder.must(QueryBuilders.matchBoolPrefixQuery("topicId", topicId)));
}
searchSourceBuilder.query(boolQueryBuilder.must(QueryBuilders.matchBoolPrefixQuery("isDel", 0)));
//将es索引库按media_link字段进行分组(第一次使用聚合函数分组)
searchSourceBuilder.size(0);
TermsAggregationBuilder aggregation = AggregationBuilders
//别名
.terms("showname")
//聚合字段名
.field("mediaLink")
//聚合结果数据量,默认只返回前十条
.size(100);
searchSourceBuilder.trackTotalHits(true);
//media_link分组后 ,再按时间字段进行分组并进行排序(升序),然后取第一条数据,第二次使用聚合函数分组
TopHitsAggregationBuilder topHitsAggregationBuilder = AggregationBuilders.topHits("top_detail").size(1).sort("releaseTime", SortOrder.ASC);
aggregation.subAggregation(topHitsAggregationBuilder);
searchSourceBuilder.aggregation(aggregation);
searchRequest.source(searchSourceBuilder);
List<StartMediaBean> list = new ArrayList<>();
SearchResponse response;
try {
response = client.search(searchRequest, RequestOptions.DEFAULT);
log.info("response is {}", response);
Terms byAgeAggregation = response.getAggregations().get("showname");
for (Terms.Bucket buck : byAgeAggregation.getBuckets()) {
ParsedTopHits topDetail = buck.getAggregations().get("top_detail");
SearchHit[] hits = topDetail.getHits().getHits();
for (SearchHit hit : hits) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
StartMediaBean o = JSONArray.parseObject(JSONArray.toJSONBytes(sourceAsMap), StartMediaBean.class);
list.add(o);
}
}
} catch (IOException e) {
log.error("[EsClientConfig.groupByField][error][fail to query]", e);
}
return list;
}
搜索完毕后如下图: es索引库中media_link(环节)字段总共有微博、移动客户端、微信公众号、网站、视频等几类数据,时间就是该环节第一次出现的时间。我们称为首发媒体(环节)。

标签:
elasticsearch
本文转载自: https://blog.csdn.net/majunssz/article/details/124381726
版权归原作者 majunssz 所有, 如有侵权,请联系我们删除。
版权归原作者 majunssz 所有, 如有侵权,请联系我们删除。