
📢📢📢📣📣📣
哈喽!大家好,我是【一心同学】,一位上进心十足的【Java领域博主】!😜😜😜
✨【一心同学】的写作风格:喜欢用【通俗易懂】的文笔去讲解每一个知识点,而不喜欢用【高大上】的官方陈述。
✨【一心同学】博客的领域是【面向后端技术】的学习,未来会持续更新更多的【后端技术】以及【学习心得】。
✨如果有对【后端技术】感兴趣的【小可爱】,欢迎关注【一心同学】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
一、Elasticsearch介绍
1.1 概述
Elasticsearch简称ES,是一个高扩展、开源、分布式的全文检索和分析引擎,它可以准实时地快速存储、搜索、分析海量的数据。而且ES本身扩展性很好,既可以扩展到上百台服务器,处理PB级别(大数据时代)的数据,服务大公司,也可以运行在单机上,服务小公司。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,Elasticsearch已超过Solr等,成为排名第一的搜索引擎类应用。

1.2 搜索引擎是什么?
** 所谓搜索引擎,就是根据用户需求与一定算法,运用特定策略从互联网检索出制定信息反馈给用户的一门检索技术。例如我们在淘宝进行购物时,当我们输入关键字“衣服”,那么淘宝就会给我们返回各种类型的衣服(男装/女装),实现这个功能的背后就是搜索引擎的功劳。**

1.3 全文检索是什么?
** 全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。**
全文检索的方式主要有两种:
(1)按字检索:指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。
(2)按词检索:指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。
二、ES特点
(1)分布式:横向扩展非常灵活
(2)高度的可伸缩性 :可以搭建大型的分布式集群,处理PB级的数据服务于大公司,也可以运行在单机上,服务于小公司
(3)高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据
(4)全文检索:基于lucene的强大的全文检索能力
(5)模式自由:ES的动态mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索
(6)开箱即用:对用户而言开箱即用,非常简单,作为中小型的应用,直接三分钟部署ES,就可以作为生产环境系统来使用了。
三、ES概念
3.1 基本概念
ES中有几个基本概念:索引(index)、类型(type)、文档(document)、映射(mapping)等。我们将这几个概念与传统的关系型数据库中的库、表、行、列等概念进行对比,如下表:
RDBS
ES
数据库(database)索引(index)表(table)类型(type)(ES6.0之后被废弃,es7中完全删除)表结构(schema)映射(mapping)行(row)文档(document)列(column)字段(field)索引反向索引SQL查询DSLSELECT * FROM tableGET http://.....UPDATE table SETPUT http://......DELETEDELETE http://......
3.1.1 索引(index)
索引是ES的一个逻辑存储,对应关系型数据库中的库,ES可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。
3.1.2 类型(type)
ES中,一个索引可以存储多个用于不同用途的对象,可以通过类型来区分索引中的不同对象,对应关系型数据库中表的概念。
3.1.3 文档(document)
存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成。区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。
由于Elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档, ES中,文档有几个重要属性:
(1)自我包含: 一篇文档同时包含字段和对应的值,也就是同时包含key:value !
(2)层次型:,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一 个json对象! fastjson进行自动转换!}
(3)灵活的结构:文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
3.1.4 映射(mapping)
mapping是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的mapping,这就像是关系型数据中的,无需定义表机构,更不用指定字段的数据类型。同时我们也可以手动指定mapping类型。
3.1.5 倒排索引
倒排索引也叫反向索引,有反向索引必有正向索引。通俗来讲,正向索引是通过key找value,反向索引则是通过value找key。
倒排索引操作步骤:
(1)先将文档中包含的关键字全部提取出来
(2)然后再将关键字与文档的对应关系保存起来
(3)最后对关键字本身做索引排序。
这样在用户检索关键字时, 可以先查找关键字索引,在通过关键字与文档的对应关系查找到所在的文档。
如下面的两个文档:
文档1: I love elasticsearch
文档2: I love logstash
他们对应的倒排索引为:
("√" 表示文档中包含这个关键字)
序号关键字文档1文档21I
√
√
2love
√
√
3elasticsearch
√
4logstash
√
现在,我们试图搜索 love elasticsearch,只需要查看包含每个词条的文档
关键字文档1文档2love√√elasticsearch√xtotal21
** 两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。**
3.2 ES集群核心概念
3.2.1 集群(cluster)
集群由许多结点Node组成,其中一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。ES的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看ES集群,在逻辑上是个整体,你与任何一个节点的通信和与整个ES集群通信是等价的。
3.2.2 节点(node)
一个es实例即为一个节点,一台机器可以有多个节点,正常使用下每个实例都会部署在不同的机器上。
ES的配置文件中可以通过node.master、 node.data 来设置节点类型:
node.master: true/false 表示节点是否具有成为主节点的资格
node.data: true/false 表示节点是否为存储数据
node节点的组合方式:
主节点+数据节点: 默认方式,节点既可以作为主节点,又存储数据
数据节点: 节点只存储数据,不参与主节点选举
客户端节点: 不会成为主节点,也不存储数据,主要针对海量请求时进行负载均衡
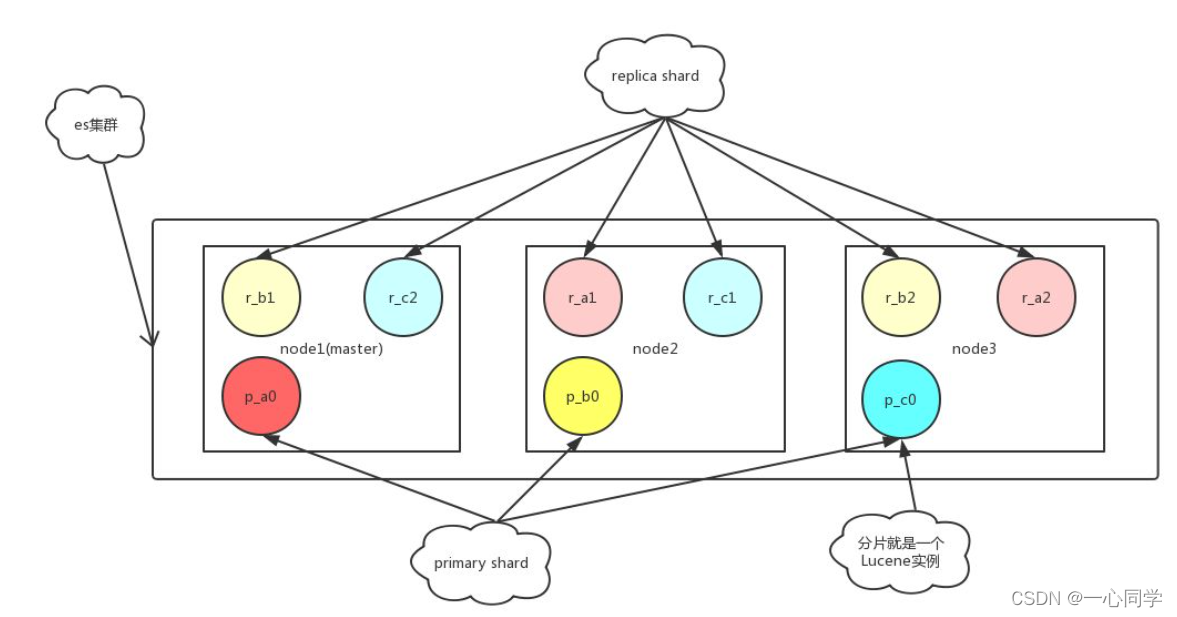
3.2.3 分片(shard)
概述:
代表索引分片,如果我们的索引数据量很大,超过硬件存放单个文件的限制,就会影响查询请求的速度,ES引入了分片技术,可以把一个完整的索引分成多个分片,一个分片本身就是一个完成的搜索引擎,文档存储在分片中,而分片会被分配到集群中的各个节点中,随着集群的扩大和缩小,ES会自动的将分片在节点之间进行迁移,以保证集群能保持一种平衡。
这样的好处是可以把一个大索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
特点:
(1)ES的一个索引可以包含多个分片(shard);
(2)每一个分片(shard)都是一个最小的工作单元,承载部分数据;
(3)每个shard都是一个lucene实例,有完整的简历索引和处理请求的能力;
(4)增减节点时,shard会自动在nodes中负载均衡;
(5)一个文档只能完整的存放在一个shard上
(6)分片的数量只能在索引创建前指定,并且索引创建后不能更改。如一个索引中含有shard的数量,默认值为5,在索引创建后这个值是不能被更改的。
(7)每一个shard关联的副本分片(replica shard)的数量,默认值为1,这个设置在任何时候都可以修改。
优点:
(1)水平分割和扩展我们存放的内容索引;
(2)分发和并行跨碎片操作提高性能/吞吐量;
3.2.4 副本(replica)
代表索引副本,ES可以设置多个索引的副本,副本的作用如下:
(1)提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
(2)提高ES的查询效率,ES会自动对搜索请求进行负载均衡。
四、应用场景
🌴 场景一:搜索服务
🌵 典型场景
- 仪表盘搜索
- 电子商务
- 手机应用搜索
- 地理位置搜索
🔥 主要特性
- 高性能:高并发、低延迟的搜索体验
- 强相关:自定义打分、排序机制
- 高可用:机房、机架感知,异地容灾
🚀 相关公司
腾讯健康码、腾讯文档全文检索、携程、拼多多、蘑菇街、滴滴、今日头条、贝壳找房…….
🌴 场景二:日志实时分析
🌵 典型场景
- 业务日志:用户行为日志、应用日志
- 状态日志:慢查询、异常探测
- 系统日志:debug、info、warn、error、fatal
🔥 主要特性
- 实时性:从日志产生到可访问,秒级
- 全文搜索:基于倒排索引,支持灵活的搜索分析
- 交互式分析:万亿级日志,搜索秒级响应
🚀 相关公司
日志易
🌴 场景三:商业智能BI
🌵 典型场景
电子商务、移动应用、广告媒体等业务都需要借助数据分析和数据挖掘来辅助商业决策,而规模庞大的业务数据对数据的统计分析造成了很大的挑战。
🔥 主要特性
- ES 拥有结构化查询的能力,支持复杂的过滤和聚合统计功能。
- 帮助客户对海量数据进行高效地个性化统计分析、发现问题与机会、辅助商业决策,让数据产生真正的价值。
🚀 相关公司
睿思BI
小结
以上就是【一心同学】对【Elasticsearch】的介绍,也带大家去理解了ES中的各种【基本概念】和ES在我们生活中的【应用场景】,相信大家现在对ES已经不再陌生了,而在接下来的博客中,【一心同学】将会向为大家继续讲解【ES的操作】。
如果这篇【文章】有帮助到你,希望可以给【一心同学】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点,如果有对【后端技术】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【一心同学】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!
版权归原作者 一心同学 所有, 如有侵权,请联系我们删除。