
一.大数据的特征
大数据的特点可以用四个以“V”开头的英文单词来概括,即大数据量(large Volume of data)、类型多样(diversity types)、价值密度(Value density Value)和速度(Velocity)。
如今,“大数据”已成为互联网和信息技术领域的热词。它是指1TB以上、增长率高、类型多样、传统软件工具无法挖掘和处理的数据。大数据的潜在价值是如此巨大,以至于它被定义为“未来的新石油”。
1. 数据量大(Volume)
大数据的显著特征是其庞大的规模。随着信息技术的发展和互联网的不断扩大,每个人的生活都被记录在大数据中,数据本身也出现了爆发式增长。
2. 类型多样(Variety)
大数据受大量互联网用户等因素的影响,来源广泛,因此大数据的类型也多种多样。大数据按因果关系强弱可分为三类,即结构化数据、半结构化数据和非结构化数据,统称为大数据。
3.价值密度(Value)
大数据价值在大数据特征中占有核心地位。大数据的总量与其价值密度成反比。同时,任何有价值的信息都是经过大量基础数据处理后提取出来的。在大数据蓬勃发展的今天,如何提高计算机算法处理海量大数据并提取有价值信息的速度一直是人们探索的问题。
4. 高速(Velocity)
大数据的高速特性主要体现在数据量的快速增长和处理。与传统媒体相比,在大数据时代的今天,信息的生产和传播发生了巨大的变化。在互联网和云计算的影响下,大数据可以快速产生和传播。
二.结构化数据、半结构化数据和非结构化数据
1.结构化数据
结构化数据一般是指可以使用关系型数据库来进行表示和存储,可以用二维表来逻辑表达实现的数据。通俗来讲,带有结构,有序的数据统称为结构化数据,例如我们平常使用的Excel,mysql,数字,符号等等
2.半结构化数据
半结构化数据是结构化数据的一种形式,半结构化数据就是介于完全结构化数据和完全无结构的数据之间的数据。例如HTML文档,JSON,XML和一些NoSQL数据库等就属于半结构化数据。
3.非数据化数据库
非结构化数据顾名思义,就是没有固定结构的数据。包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频、视频信息等等都属于非结构化数据。
三.Hadoop的优势
- 扩容能力强
- 成本低
- 高效率
- 可靠性
- 高容错性
四.Hadoop生态圈
指以Hadoop为基础的生态圈,是一个很庞大的体系,Hadoop只是其中最重要、最基础的一部分;生态圈中的每个子系统只负责解决某一个特定的问题区域,甚至可能更小,它并不是一个全能系统,而是多个小的系统的集成。Hadoop生态圈的构成如下图:

五.Hadoop HDFS架构
HDFS(Hadoop Distribute File System)分布式文件系统
分布式文件系统 distributed file system 是指文件系统管理的物理存储资源不一定直接链接在本地节点上,而是通过计算机网络与节点相连,可让多机器上的多用户分享文件和存储空间。分布式文件系统的设计基于客户机/服务器模式
HDFS架构图如下图所示:
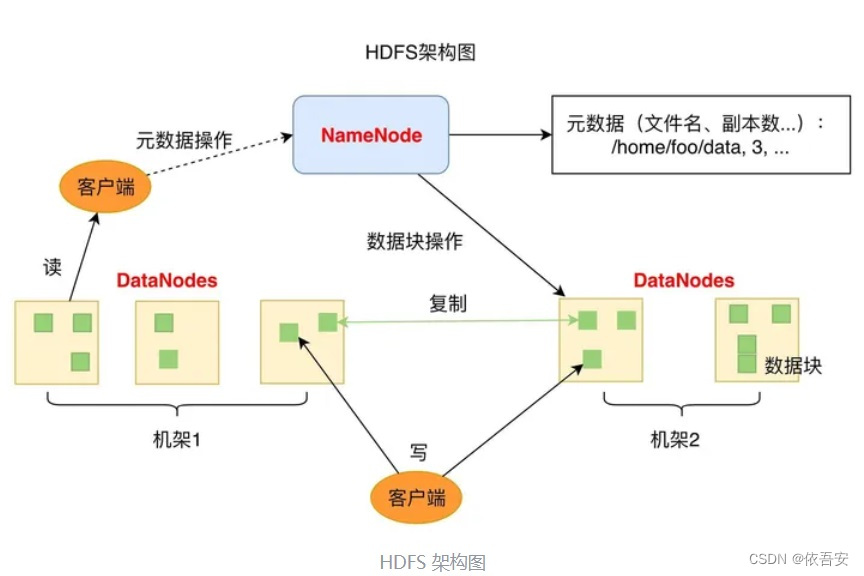
HDFS优势:
1、可构建在廉价机器上,设备成本相对低
2、高容错性
3、适合批处理
4、适合存储大文件
HDFS劣势:
1、由于提高吞吐量,降低实时性
2、如果存储了大量的小文件,会对造成很大的压力
3、不合适小文件处理
4、不适合文件的修改,文件只能追加在文件的末尾,不支持任意位置修改,不支持多个写入者操作
六.HDFS读的流程
先上图:

1.HDFS客户端远程调用Namenode,查询元数据信息,获得这个文件的数据块位置列表,返回封装DFSIntputStream的HdfsDataInputStream输入流对象。
2.客户端选择一台可用Datanode服务器,请求建立输入流。
3.Datanode向输入流中写原始数据和以packet为单位的checksum。
4.客户端接收数据。如遇到异常,跳转至步骤2,直到数据全部读出,而后客户端关闭输入流。当客户端读取时,可能遇到Datanode或Block异常,导致当前读取失败。正由于HDFS的多副本保证,DFSIntputStream将会切换至下一个Datanode进行读取。与HDFS写入类似,通过checksum来保证读取数据的完整性和准确性。
本文转载自: https://blog.csdn.net/2302_76955238/article/details/136395321
版权归原作者 依吾安 所有, 如有侵权,请联系我们删除。
版权归原作者 依吾安 所有, 如有侵权,请联系我们删除。