
文章目录
01 KafkaSink 版本&导言
Flink版本:
本文主要是基于Flink1.14.4 版本
导言:
Apache Flink 作为流式处理领域的先锋,为实时数据处理提供了强大而灵活的解决方案。其中,KafkaSink 是 Flink 生态系统中的关键组件之一,扮演着将 Flink 处理的数据可靠地发送到 Kafka 主题的角色。本文将深入探讨 KafkaSink 的工作原理、配置和最佳实践,帮助读者全面掌握在 Flink 中使用 KafkaSink 的技巧和方法。
02 KafkaSink 基本概念
KafkaSink 是 Apache Flink 提供的用于将流式数据发送到 Kafka 的连接器。它允许 Flink 应用程序将经过处理的数据以高效和可靠的方式传输到 Kafka 主题,从而实现流处理与消息队列的无缝集成。
特性和优势:
- Exactly-Once 语义: KafkaSink 提供 Exactly-Once 语义,确保数据不会丢失,也不会重复写入 Kafka 主题。这是通过 Flink 提供的端到端一致性保障的一部分。
- 高性能: KafkaSink 被设计为高性能的组件,能够处理大规模的数据流,并以低延迟将数据发送到 Kafka。其底层使用 Kafka 生产者 API,充分利用 Kafka 的并发性和批量处理能力。
- 配置灵活: 用户可以通过配置参数定制 KafkaSink 的行为,包括 Kafka 服务器地址、主题名称、生产者配置等。这种灵活性使得 KafkaSink 可以适应不同场景和需求。
- Exactly-Once Sink Semantics: KafkaSink 通过 Kafka 生产者的事务支持,确保在发生故障时能够保持数据的一致性,即使在 Flink 任务重新启动后也能继续从上次中断的地方进行。
03 KafkaSink 工作原理
KafkaSink是Apache Flink中用于将流式数据写入Apache Kafka的关键组件。其工作原理涉及几个主要步骤,同时我将介绍一些源码片段以解释其内部实现。
1.初始化连接
用户需要配置Kafka连接属性,包括Kafka服务器地址、序列化器等。在Flink中,这通常通过创建Properties对象来完成。
// 创建KafksSink配置
Properties properties = new Properties();
properties.setProperty(ProducerConfig.ACKS_CONFIG, "1");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "0");
properties.setProperty(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, "10000");
2.定义序列化模式
KafkaRecordSerializationSchema
是 Apache Flink 中用于将数据流转换为 Kafka 记录(record)的序列化模式(Serialization Schema)。它允许将 Flink 数据流中的元素转换为 Kafka 生产者记录,并定义了如何序列化元素的逻辑。
在 Flink 中,当你想要将数据发送到 Kafka 主题,需要一个序列化模式来将 Flink 数据流中的元素序列化为 Kafka 记录。而
KafkaRecordSerializationSchema
就是为此目的而设计的。
// 序列化模式
KafkaRecordSerializationSchema<String> recordSerializer = KafkaRecordSerializationSchema.builder()
//设置对哪个主题进行序列化
.setTopic("topic_a")
//设置数据值序列化方式
.setValueSerializationSchema(new SimpleStringSchema())
//设置数据key序列化方式
.setKeySerializationSchema(new SimpleStringSchema())
.build();
3.创建KafkaSink算子
使用Flink提供的
KafkaSink
类创建一个Kafka生产者实例。以下是简化的源码片段,展示了如何创建实例:
注意:如果传递保证选择Exactly Once (精确一次),需要设置 客户端的超时时间 ,否则会报错
Caused by: org.apache.kafka.common.KafkaException: Unexpected error in InitProducerIdResponse; The transaction timeout is larger than the maximum value allowed by the broker (as configured by transaction.max.timeout.ms),需要设置 transaction.timeout.ms 小于15分钟,后续会专门出一篇关于这个传递保证的博客讲述。
// 创建KafkaSink算子
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
//设置kafka各种参数
.setKafkaProducerConfig(properties)
//设置序列化模式
.setRecordSerializer(recordSerializer)
//设置传递保证
//At Most Once (至多一次): 系统保证消息要么被成功传递一次,要么根本不被传递。这种保证意味着消息可能会丢失,但不会被传递多
//At Least Once (至少一次): 系统保证消息至少会被传递一次,但可能会导致消息的重复传递。这种保证确保了消息的不丢失,但应用
//Exactly Once (精确一次): 系统保证消息会被确切地传递一次,而没有任何重复。这是最高级别的传递保证,确保消息不会丢失且不会
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
//设置集群地址
.setBootstrapServers("127.0.0.1:9092")
//设置事务前缀
.setTransactionalIdPrefix("flink_")
.build();
4.创建数据源
创建数据源,每隔1000ms下发一笔数据
// 生成一个数据流
SourceFunction<String> sourceFunction = new SourceFunction<String>() {
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
while (true) {
String id = UUID.randomUUID().toString();
sourceContext.collect( id);
logger.info("正在下发数据:{}",id);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
// 创建数据源
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction).setParallelism(1);
5.将数据流添加到KafkaSink
在Flink应用程序中,通过
addSink()
方法将要写入Kafka主题数据流添加到KafkaSink,以下是一个简化的示例:
// 数据流数据通过KafkaSink算子写入kafka
dataStreamSource.sinkTo(kafkaSink).setParallelism(1);
// 执行任务
env.execute("KafkaSinkStreamJobDemo");
6.内部工作机制
KafkaSink会将接收到的数据流分区为若干个并行的数据流,每个并行数据流由一个Kafka生产者实例负责向Kafka主题写入数据。这样可以提高写入的吞吐量和并行度。
以下是源码中的一部分,展示了KafkaSink是如何将数据发送到Kafka的:
@Override
public void invoke(IN value, Context context) throws Exception {
// 将数据发送到Kafka主题
producer.send(new ProducerRecord<>(topic, value.toString()));
}
KafkaSink的源码相对复杂,涉及到与Kafka的交互、并行处理、容错等方面的实现。
总的来说,KafkaSink通过整合Flink和Kafka的功能,提供了一种高效、可靠的方式将流式数据写入Kafka主题,适用于各种实时数据处理场景。
04 KafkaSink参数配置
需要根据具体的安全需求和环境配置 Kafka 的安全性参数。建议查阅最新版本的 Kafka 文档以获取详细的安全配置指南:https://kafka.apache.org/documentation/#producerconfigs
在 Apache Flink 中,
ProducerConfig
是用于配置 Kafka 生产者的类,它是 Kafka 客户端库中的一部分。下面是一些常见的配置选项及其解释:
bootstrap.servers
集群的地址列表,用于初始化连接。生产者会从这些服务器中选择一个 broker 进行连接。
public static final String BOOTSTRAP_SERVERS_CONFIG = "bootstrap.servers";
metadata.max.age.ms
元数据的最大缓存时间。在此时间内,生产者将重复使用已经获取的元数据,而不会向服务器发送新的元数据请求
public static final String METADATA_MAX_AGE_CONFIG = "metadata.max.age.ms";
batch.size
控制批量发送到 Kafka 的消息大小。当消息积累到一定大小时,生产者会将它们一起发送到 Kafka 以提高效率
public static final String BATCH_SIZE_CONFIG = "batch.size";
acks
消息确认机制,控制生产者收到确认的方式。可以是“all”(所有副本都确认),“1”(至少一个副本确认)或“0”(不需要确认)
public static final String ACKS_CONFIG = "acks";
linger.ms
生产者在发送批量消息前等待的时间,以使更多的消息聚合成一个批次。默认是0,表示立即发送
public static final String LINGER_MS_CONFIG = "linger.ms";
request.timeout.ms
发送请求到 Kafka 服务器的超时时间
public static final String REQUEST_TIMEOUT_MS_CONFIG = "request.timeout.ms";
delivery.timeout.ms
这个参数在 Kafka 生产者的配置中是存在的,它表示生产者在发送消息后等待生产者确认的最大时间。如果在这段时间内没有收到确认,生产者将重试发送消息或者抛出异常,具体取决于 retries 参数的配置
public static final String DELIVERY_TIMEOUT_MS_CONFIG = "delivery.timeout.ms";
client.id
用于区分不同生产者实例的客户端 ID
public static final String CLIENT_ID_CONFIG = "client.id";
send.buffer.bytes
Kafka 消费者用于网络 socket 发送数据的缓冲区大小
public static final String SEND_BUFFER_CONFIG = "send.buffer.bytes";
receive.buffer.bytes
Kafka 消费者用于网络 socket 接收数据的缓冲区大小
public static final String RECEIVE_BUFFER_CONFIG = "receive.buffer.bytes";
max.request.size
单个请求发送的最大字节数
public static final String MAX_REQUEST_SIZE_CONFIG = "max.request.size";
reconnect.backoff.ms
用于控制在与 Kafka 服务器连接断开后重新连接的时间间隔。具体来说,它定义了在发起重新连接尝试之间等待的时间量,以毫秒为单位。如果连接失败,生产者将在此时间间隔之后尝试重新连接到 Kafka 服务器
public static final String RECONNECT_BACKOFF_MS_CONFIG = "reconnect.backoff.ms";
reconnect.backoff.max.ms
用于控制重新连接的最大退避时间。具体来说,它定义了在发起重新连接尝试之间等待的最长时间量,以毫秒为单位。如果连接失败,生产者将在此时间间隔之后尝试重新连接到 Kafka 服务器
public static final String RECONNECT_BACKOFF_MAX_MS_CONFIG = "reconnect.backoff.max.ms";
max.block.ms
当 Kafka 队列已满时,生产者将阻塞的最长时间(毫秒),超时后会抛出异常
public static final String MAX_BLOCK_MS_CONFIG = "max.block.ms";
buffer.memory
生产者用于缓冲等待发送到服务器的消息的内存大小。默认是33554432字节(32MB)
public static final String BUFFER_MEMORY_CONFIG = "buffer.memory";
retries
生产者发送失败后的重试次数。默认是0,表示不重试
public static final String RETRIES_CONFIG = "retries";
key.serializer
用于序列化消息键的序列化器类。通常是指实现了Serializer接口的类的全限定名
public static final String KEY_SERIALIZER_CLASS_CONFIG = "key.serializer";
value.serializer
用于序列化消息值的序列化器类
public static final String VALUE_SERIALIZER_CLASS_CONFIG = "value.serializer";
connections.max.idle.ms
客户端与服务器保持空闲连接的最长时间(毫秒)。默认值为 540000(即 9 分钟)。例如:
"900000"表示客户端与服务器保持空闲连接的最长时间为 15 分钟
public static final String CONNECTIONS_MAX_IDLE_MS_CONFIG = "connections.max.idle.ms";
partitioner.class
用于指定消息将被发送到哪个分区的算法,即分区器的实现类。Kafka 中的主题(topic)通常被划分为多个分区,每个分区都包含有序的消息序列。分区器决定了生产者发送的消息应该被分配到哪个分区中。
通过配置
partitioner.class,用户可以自定义分区算法,以满足特定的业务需求。Kafka 提供了默认的分区器,也允许用户根据自己的逻辑实现自定义的分区器。
例如,以下是配置
partitioner.class的示例:
partitioner.class=com.example.CustomPartitioner在这个示例中,
com.example.CustomPartitioner是用户自定义的分区器类的全限定名。该类必须实现 Kafka 提供的
org.apache.kafka.clients.producer.Partitioner接口,该接口定义了确定消息应该被发送到哪个分区的方法。
自定义分区器可以根据消息的内容、键(如果有)、以及其他上下文信息,灵活地决定消息应该被发送到哪个分区。这样的自定义分区策略可以帮助实现一些特定的业务逻辑,例如确保相关的消息被发送到相同的分区,以提高消费的局部性。
在没有显式配置
partitioner.class的情况下,Kafka 使用默认的分区器,该分区器根据消息的键(如果有)或者采用轮询的方式将消息平均分配到所有分区。
public static final String PARTITIONER_CLASS_CONFIG = "partitioner.class";
interceptor.classes
用于指定一组拦截器类。拦截器类是实现 Kafka 接口
org.apache.kafka.clients.producer.ProducerInterceptor或者
org.apache.kafka.clients.consumer.ConsumerInterceptor的类,用于在生产者或消费者发送或接收消息之前或之后对消息进行处理。
拦截器允许用户对消息进行自定义的预处理或后处理。这些操作可以包括但不限于:
- 对消息进行加工、转换、过滤。
- 在消息发送或接收之前或之后记录日志。
- 对消息的时间戳或键进行修改。
通过配置
interceptor.classes参数,可以指定一组拦截器类,并且它们将按顺序应用于每个消息。这样的拦截器链使得在消息处理过程中可以执行多个不同的操作。
例如,以下是配置
interceptor.classes的示例:
interceptor.classes=com.example.MyProducerInterceptor, com.example.MyConsumerInterceptor在这个示例中,
com.example.MyProducerInterceptor和
com.example.MyConsumerInterceptor是用户定义的拦截器类的全限定名。这两个类必须分别实现 Kafka 提供的
org.apache.kafka.clients.producer.ProducerInterceptor和
org.apache.kafka.clients.consumer.ConsumerInterceptor接口。
需要注意的是,拦截器类的顺序很重要。拦截器将按照它们在
interceptor.classes参数中声明的顺序依次应用于每个消息。如果需要确保拦截器按照特定的顺序应用,可以通过配置参数来指定顺序。
拦截器提供了一种灵活的方式来实现特定的消息处理逻辑,同时也允许用户对消息进行监控和记录。
public static final String INTERCEPTOR_CLASSES_CONFIG = "interceptor.classes";
enable.idempotence
public static final String ENABLE_IDEMPOTENCE_CONFIG = "enable.idempotence";
transaction.timeout.ms
public static final String TRANSACTION_TIMEOUT_CONFIG = "transaction.timeout.ms";
transactional.id
用于启用生产者的幂等性。幂等性是指对于同一个生产者实例,无论消息发送多少次,最终只会产生一条副本(实际上是一个幂等序列)的性质。这可以防止由于网络错误、重试或者生产者重新启动等情况导致的重复消息。
启用生产者的幂等性可以通过设置
enable.idempotence参数为
true来实现。例如:
enable.idempotence=true启用幂等性会自动设置一些与幂等性相关的配置,例如:
acks配置将被设置为 “all”,确保所有的 ISR(In-Sync Replicas)都已经接收到消息。max.in.flight.requests.per.connection将被设置为 1,以确保在一个连接上只有一个未确认的请求。幂等性对于确保消息传递的精确一次语义非常重要。在启用幂等性的情况下,生产者会为每条消息分配一个唯一的序列号,以便在重试发生时 Broker 能够正确地识别并去重重复的消息。
需要注意的是,启用幂等性会对性能产生一些开销,因为它引入了额外的序列号和一些额外的网络开销。在生产环境中,需要仔细评估幂等性对性能的影响,并根据实际需求权衡性能和可靠性。
public static final String TRANSACTIONAL_ID_CONFIG = "transactional.id";
security.providers
参数已经被 Kafka 移除了。在较早的 Kafka 版本中,这个参数可能被用于指定安全性相关的提供者。然而,从 Kafka 2.0 开始,Kafka 已经采用了基于 JAAS(Java Authentication and Authorization Service)的身份验证和授权机制,这个参数不再被使用。
现在,Kafka 的安全性配置主要包括以下几个方面:
- 身份验证机制(Authentication Mechanisms):Kafka 支持多种身份验证机制,如SSL/TLS、SASL(Simple Authentication and Security Layer)、OAuth等。通过配置
security.protocol参数选择所需的身份验证机制。- 授权机制(Authorization Mechanisms):Kafka 使用 ACL(Access Control Lists)来控制对主题和分区的访问权限。可以通过配置
authorizer.class.name参数选择 ACL 的实现类。- 加密通信(Encryption):可以通过配置 SSL/TLS 来对 Kafka 通信进行加密,以保护数据在传输过程中的安全性。
- 客户端配置(Client Configuration):客户端需要根据服务端的安全配置进行相应的配置,如设置 SSL/TLS 的信任证书、SASL 的认证信息等。
需要根据具体的安全需求和环境配置 Kafka 的安全性参数。建议查阅最新版本的 Kafka 文档以获取详细的安全配置指南。
public static final String SECURITY_PROVIDERS_CONFIG = "security.providers";
retry.backoff.ms
用于定义在发生可重试的发送错误后,生产者在进行重试之前等待的时间间隔,以毫秒为单位。
当生产者发送消息到 Kafka 时,可能会遇到一些可重试的错误,例如网络问题、Kafka 服务器繁忙等。retry.backoff.ms 允许在出现这些可重试错误后等待一段时间,然后再次尝试发送消息,以避免频繁的重试。这样的设计有助于在短时间内解决暂时性的问题,而不至于对 Kafka 服务器造成额外的负担。
具体而言,如果发生了可重试的错误,生产者将等待 retry.backoff.ms 指定的时间间隔,然后进行下一次重试。如果重试依然失败,生产者可能会继续进行更多的重试,每次之间间隔逐渐增加,以避免过度压力和频繁的连接尝试。
默认情况下,retry.backoff.ms 的值通常是 100 毫秒,但可以根据实际需求和环境进行调整
public static final String RETRY_BACKOFF_MS_CONFIG = "retry.backoff.ms";
compression.type
控制发送到 Kafka 的消息是否压缩。可以是“none”、“gzip”、“snappy”或“lz4”
public static final String COMPRESSION_TYPE_CONFIG = "compression.type";
metrics.sample.window.ms
用于配置 Kafka Broker 的参数,用于定义度量指标(metrics)的采样窗口的时间跨度,以毫秒为单位。
具体来说,这个参数指定了度量指标的采样窗口的持续时间。在这个时间段内,Kafka Broker 会收集和计算各种指标,比如吞吐量、延迟、请求处理时间等。然后,这些度量指标可以被监控工具或者外部系统使用,以便实时地监控 Kafka Broker 的运行状态和性能指标。
通过调整
metrics.sample.window.ms这个参数,可以改变度量指标采样的时间窗口长度,以适应不同的监控和性能分析需求。较短的采样窗口可以提供更加实时的性能指标,但也会增加系统资源的开销;而较长的采样窗口则可以减少资源开销,但会牺牲一些实时性。
默认情况下,
metrics.sample.window.ms的值通常是 30000 毫秒(30秒),但根据具体的 Kafka 集群配置和监控需求,可以进行调整。
public static final String METRICS_SAMPLE_WINDOW_MS_CONFIG = "metrics.sample.window.ms";
metrics.num.samples
用于配置 Kafka Broker 的参数,用于指定在每个度量指标采样窗口中收集的样本数量。
具体来说,度量指标(metrics)是用于监视 Kafka Broker 运行状态和性能的关键数据,比如吞吐量、延迟、请求处理时间等。而
metrics.num.samples参数则控制了在每个采样窗口内收集多少个样本。这些样本可以用于计算度量指标的平均值、最大值、最小值等统计信息。
通过调整
metrics.num.samples这个参数,可以平衡度量指标的准确性和资源消耗之间的权衡。较大的样本数量可以提供更加准确的度量指标统计信息,但会增加系统资源的开销;而较小的样本数量则可以减少资源消耗,但可能会牺牲一些准确性。
默认情况下,
metrics.num.samples的值通常是 2,但根据具体的 Kafka 集群配置和监控需求,可以进行调整。
public static final String METRICS_NUM_SAMPLES_CONFIG = "metrics.num.samples";
metrics.recording.level
用于配置度量指标(metrics)的记录级别。这个参数决定了哪些度量指标会被记录和汇报。
具体来说,
metrics.recording.level可以设置为以下几个级别之一:
INFO:记录常规的度量指标,如吞吐量、延迟等。DEBUG:记录更详细的度量指标信息,可能包括更多的细节和较低级别的度量指标。TRACE:记录非常详细的度量指标信息,包括所有细节和最低级别的度量指标。通过调整
metrics.recording.level这个参数,可以灵活地控制记录的度量指标的级别,以满足不同场景下的监控和分析需求。例如,在生产环境中,通常会将记录级别设置为
INFO或者
DEBUG,以便实时监控 Kafka 集群的运行状态和性能指标;而在调试或者故障排查时,可以将记录级别设置为
TRACE,以获取更详细的信息。
默认情况下,
metrics.recording.level的值通常是
INFO,但可以根据具体的需求和环境进行调整。
public static final String METRICS_RECORDING_LEVEL_CONFIG = "metrics.recording.level";
metric.reporters
用于指定要使用的度量指标(metrics)报告器。度量指标报告器负责将 Kafka Broker 收集到的度量指标信息发送到指定的位置,以供监控和分析使用。
具体来说,
metric.reporters参数接受一个逗号分隔的报告器类名列表,这些报告器类名必须实现 Kafka 的
org.apache.kafka.common.metrics.MetricsReporter接口。通过配置这个参数,可以启用不同的度量指标报告器,并将度量指标信息发送到不同的目的地,比如日志、JMX、Graphite、InfluxDB 等。
例如,可以使用以下配置启用 JMX 报告器和日志报告器:
metric.reporters=jmx, kafka.metrics.KafkaMetricsReporter这样配置后,Kafka Broker 将同时使用 JMX 报告器和日志报告器,将度量指标信息发送到 JMX 和日志中。
默认情况下,
metric.reporters参数为空,表示不使用任何度量指标报告器。在实际部署中,根据监控和分析需求,可以配置不同的度量指标报告器来收集和报告度量指标信息。
public static final String METRIC_REPORTER_CLASSES_CONFIG = "metric.reporters";
max.in.flight.requests.per.connection
用于控制在任何给定时间内允许向单个 Broker 发送的未确认请求的最大数量。
在 Kafka 中,生产者发送消息到 Broker 时,可以选择等待服务器确认(acknowledgement)消息发送成功后再发送下一条消息,或者继续发送下一条消息而不等待前一条消息的确认。当生产者选择继续发送下一条消息时,这些未确认的消息就会处于 “in-flight” 状态。
max.in.flight.requests.per.connection参数就是用来限制在这种情况下的未确认请求的数量。如果未确认请求的数量达到了这个限制,生产者将会阻塞,直到有一些请求被确认,才会继续发送新的请求。
通过调整
max.in.flight.requests.per.connection参数,可以平衡生产者的吞吐量和消息传递的可靠性之间的权衡。较大的值可以提高生产者的吞吐量,因为它允许更多的消息在未确认状态下发送,而较小的值可以提高消息传递的可靠性,因为它限制了未确认请求的数量,从而减少了消息丢失的风险。
默认情况下,
max.in.flight.requests.per.connection的值是 5。根据应用程序的要求和实际情况,可以适当地调整这个参数的值。
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
05 KafkaSink 应用依赖
<!-- Flink kafka 连接器依赖 start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<!-- Flink kafka 连接器依赖 end -->
06 KafkaSink 快速入门
6.1 包结构

6.2 项目配置
log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmproot
Logger.level=INFO
6.3 pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.aurora</groupId>
<artifactId>aurora_kafka_connector</artifactId>
<version>1.0-SNAPSHOT</version>
<!--属性设置-->
<properties>
<!--java_JDK版本-->
<java.version>1.8</java.version>
<!--maven打包插件-->
<maven.plugin.version>3.8.1</maven.plugin.version>
<!--编译编码UTF-8-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--输出报告编码UTF-8-->
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!--json数据格式处理工具-->
<fastjson.version>1.2.75</fastjson.version>
<!--log4j版本-->
<log4j.version>2.17.1</log4j.version>
<!--flink版本-->
<flink.version>1.14.4</flink.version>
<!--scala版本-->
<scala.binary.version>2.12</scala.binary.version>
</properties>
<!--依赖管理-->
<dependencies>
<!-- fastJson工具类依赖 start -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- fastJson工具类依赖 end -->
<!-- log4j日志框架依赖 start -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<!-- log4j日志框架依赖 end -->
<!-- Flink基础依赖 start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink基础依赖 end -->
<!-- Flink kafka 连接器依赖 start -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink kafka 连接器依赖 end -->
</dependencies>
<!--编译打包-->
<build>
<finalName>${project.name}</finalName>
<!--资源文件打包-->
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>org.google.code.flindbugs:jar305</exclude>
<exclude>org.slf4j:*</exclude>
<excluder>org.apache.logging.log4j:*</excluder>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.aurora.demo,ElasticsearchSinkStreamingJobDemo</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<!--插件统一管理-->
<pluginManagement>
<plugins>
<!--maven打包插件-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<configuration>
<fork>true</fork>
<finalName>${project.build.finalName}</finalName>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<!--编译打包插件-->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.plugin.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
6.4 Flink集成KafkaSink作业
package com.aurora;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Properties;
import java.util.UUID;
/**
* 描述:Flink集成kafkaSink,实现数据流写入Kafka集群
*
* @author 浅夏的猫
* @version 1.0.0
* @date 2024-02-18 20:52:25
*/
public class KafkaSinkStreamJobDemo {
private static final Logger logger = LoggerFactory.getLogger(KafkaSinkStreamJobDemo.class);
public static void main(String[] args) {
try {
logger.info("开始启动作业!!!");
// 创建Flink运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建KafksSink配置
Properties properties = new Properties();
properties.setProperty(ProducerConfig.ACKS_CONFIG, "1");
properties.setProperty(ProducerConfig.LINGER_MS_CONFIG, "0");
properties.setProperty(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, "10000");
// 序列化模式
KafkaRecordSerializationSchema<String> recordSerializer = KafkaRecordSerializationSchema.builder()
//设置对哪个主题进行序列化
.setTopic("topic_a")
//设置数据值序列化方式
.setValueSerializationSchema(new SimpleStringSchema())
//设置数据key序列化方式
.setKeySerializationSchema(new SimpleStringSchema())
.build();
// 创建KafkaSink算子
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
//设置kafka各种参数
.setKafkaProducerConfig(properties)
//设置序列化模式
.setRecordSerializer(recordSerializer)
//设置传递保证
//At Most Once (至多一次): 系统保证消息要么被成功传递一次,要么根本不被传递。这种保证意味着消息可能会丢失,但不会被传递多次。
//At Least Once (至少一次): 系统保证消息至少会被传递一次,但可能会导致消息的重复传递。这种保证确保了消息的不丢失,但应用程序需要能够处理重复消息的情况。
//Exactly Once (精确一次): 系统保证消息会被确切地传递一次,而没有任何重复。这是最高级别的传递保证,确保消息不会丢失且不会被重复
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
//设置集群地址
.setBootstrapServers("127.0.0.1:9092")
//设置事务前缀
.setTransactionalIdPrefix("flink_")
.build();
// 生成一个数据流
SourceFunction<String> sourceFunction = new SourceFunction<String>() {
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
while (true) {
String id = UUID.randomUUID().toString();
sourceContext.collect( id);
logger.info("正在下发数据:{}",id);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
};
// 创建数据源
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction).setParallelism(1);
// 数据流数据通过KafkaSink算子写入kafka
dataStreamSource.sinkTo(kafkaSink).setParallelism(1);
// 执行任务
env.execute("KafkaSinkStreamJobDemo");
} catch (Exception e) {
e.printStackTrace();
}
}
}
6.5 验证
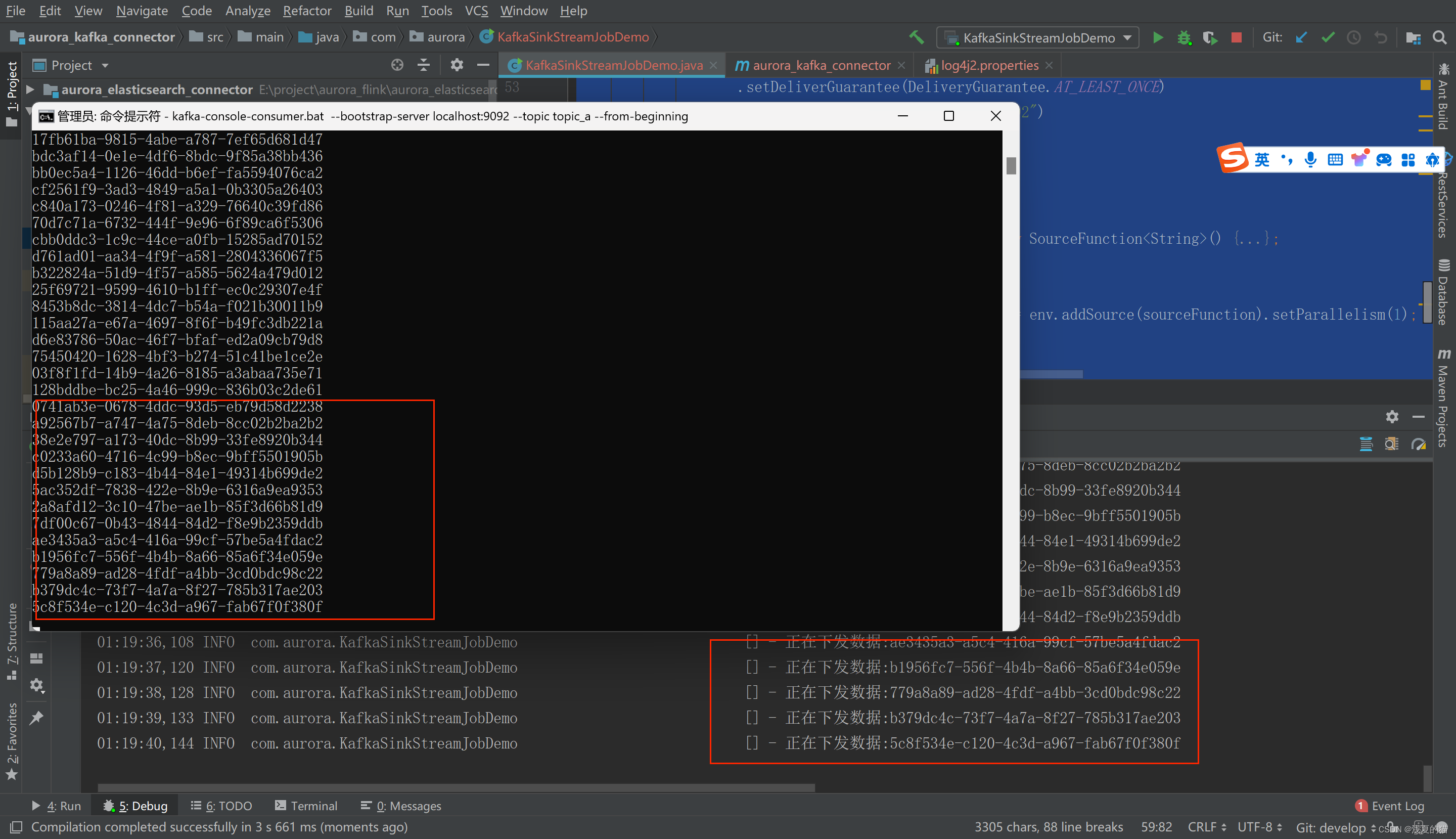
构建并运行 Flink 应用,确保应用能够成功发送数据到 Kafka 主题。你可以通过 Kafka Consumer 来验证是否成功接收到了消息。
这个简单的示例展示了如何使用 Kafka Sink 集成到流处理系统中,并且它是可运行的。在实际应用中,你可以根据需要配置更多参数,例如序列化器、acks 级别、以及其他相关的生产者和 Kafka 配置。
通过kafka命令启动一个消费者,观察是否实时消费到数据
#windows
kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic topic_a
#linux
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic_a
07 总结
Kafka Sink 是实现流处理到 Kafka 集群的关键组件之一。通过上述示例,你可以开始使用 Kafka Sink 将你的流处理数据发送到 Kafka,从而实现可靠的消息传递。在实际应用中,确保根据业务需求和性能要求调整配置参数,以获得最佳的性能和稳定性。
版权归原作者 浅夏的猫 所有, 如有侵权,请联系我们删除。