
find_element可以使用get_attribute来得到某一属性值,但是find_element就只能够得到一个节点
find_elements可以得到多个节点,但是不能够直接使用get-attribute来得到属性值
但是可以通过for i in range()循环来实现得到每一个节点所对应的属性值:
这里用爬取网易云音乐热歌榜为例(没错,又是网易云,网易云:再这样子我就要网抑云了)
代码献上:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser=webdriver.Chrome()
url='https://music.163.com/#/discover/toplist?id=3778678'
browser.get(url)
browser.switch_to.frame('g_iframe')#一个坑,页面使用了框架套框架(就这么理解吧),需要先切换到小框架中
songs =browser.find_elements(By.XPATH,'//table[@class="m-table m-table-rank"]/tbody/tr')#通过Xpath来定位我们所需要的东西,
for song in songs:#进行遍历
hrefs=song.find_elements(By.XPATH,'//span[@class="txt"]/a')
names=song.find_elements(By.XPATH,'//span[@class="txt"]/a/b')
for i in range(0,101):#先设一个i,让他在0-100内step为1的循环
href=hrefs[i].get_attribute('href')#当i=1的时候href便是对应的第二个网址,即孤勇者(爱你孤身走暗巷~),同理循环到100个的时候就会得到第100个网址(别看我我就会唱那一首)
name=names[i].get_attribute('title')#和上面的逻辑一毛一样
print(href,name,sep='\t')#之后进行输出,超链接和名字,sep='\t'是不让他换行
break#这个break一定要有,不然的话就会无限循环下去,0-100之后再来一次,结果就是被网页反爬了
我在爬取的时候遇到了这样的情况,上网查之后看到有人是find_element之后直接遍历,输出name,href
我试了一下子,出来的是这个样子: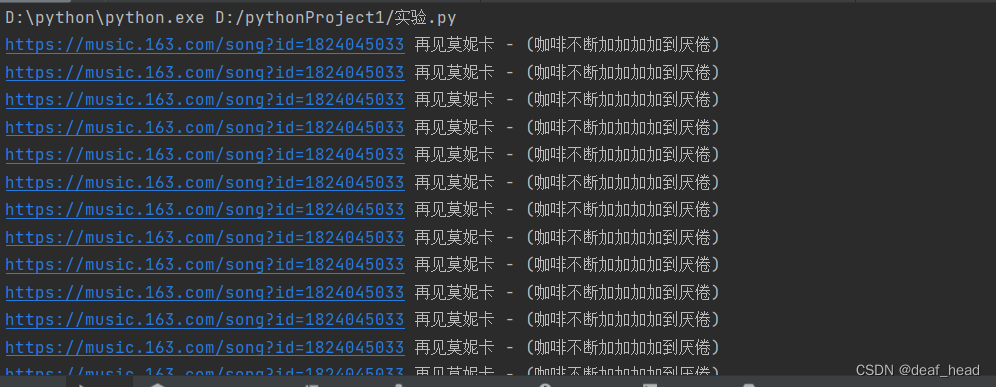
嗯,就很棒,莫妮卡:老娘这辈子再也不想听见再见了
小白第一次写博客,希望各位大佬多多指点,谢谢,
and,热歌榜是200条数据的,但是直接0-201的话,会被反扒,我也加过time.sleep,但是并没有神马用,所以要是有大佬知道肿么办的,欢迎评论区留言
本文转载自: https://blog.csdn.net/deaf_head/article/details/125603508
版权归原作者 歪比巴布的巴尔 所有, 如有侵权,请联系我们删除。
版权归原作者 歪比巴布的巴尔 所有, 如有侵权,请联系我们删除。