
本文内容翻译自《数据密集型应用系统设计》,豆瓣评分高达 9.7 分。

什么是「数据密集型应用系统」?
当数据(数据量、数据复杂度、数据变化速度)是一个应用的主要挑战,那么可以把这个应用称为数据密集型的。与之相对的是计算密集型——处理器速度是主要瓶颈。
其实我们平时遇到的大部分系统都是数据密集型的——应用代码访问内存、硬盘、数据库、消息队列中的数据,经过业务逻辑处理,再返回给用户。
这本书并不是针对某个具体的数据库,而是自顶向下展开各项技术的共性和区别,把所有跟「数据」有关的知识点做了剖析、整理、总结。

查询类型
Online analytical processing和Online analytical processing。
查询类型主要分为两大类:
引擎类型
请求数量
数据量
瓶颈
存储格式
用户
场景举例
产品举例
OLTP
相对频繁,侧重在线交易
总体和单次查询都相对较小
Disk Seek
多用行存
比较普遍,一般应用用的比较多
银行交易
MySQL
OLAP
相对较少,侧重离线分析
总体和单次查询都相对巨大
Disk Bandwidth
列存逐渐流行
多为商业用户
商业分析
ClickHouse
其中,OLTP 侧,常用的存储引擎又有两种流派:
流派
主要特点
基本思想
代表
log-structured 流
只允许追加,所有修改都表现为文件的追加和文件整体增删
变随机写为顺序写
Bitcask、LevelDB、RocksDB、Cassandra、Lucene
update-in-place 流
以页(page)为粒度对磁盘数据进行修改
面向页、查找树
B 族树,所有主流关系型数据库和一些非关系型数据库
此外,针对 OLTP, 还探索了常见的建索引的方法,以及一种特殊的数据库 —— 全内存数据库。
对于数据仓库,本章分析了它与 OLTP 的主要不同之处。数据仓库主要侧重于聚合查询,需要扫描很大量的数据,此时,索引就相对不太有用。需要考虑的是存储成本、带宽优化等,由此引出列式存储。
驱动数据库的底层数据结构
本节由一个 shell 脚本出发,到一个相当简单但可用的存储引擎 Bitcask,然后引出 LSM-tree,他们都属于日志流范畴。之后转向存储引擎另一流派 ——B 族树,之后对其做了简单对比。最后探讨了存储中离不开的结构 —— 索引。
首先来看,世界上 “最简单” 的数据库,由两个 Bash 函数构成:
1
2
3
4
5
6
7
8
#!/bin/bash
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
这两个函数实现了一个基于字符串的 KV 存储(只支持 get/set,不支持 delete):
1
2
3
4
$ db_set 123456 '{"name":"London","attractions":["Big Ben","London Eye"]}'
$ db_set 42 '{"name":"San Francisco","attractions":["Golden Gate Bridge"]}'
$ db_get 42
{"name":"San Francisco","attractions":["Golden Gate Bridge"]}
来分析下它为什么 work,也反映了日志结构存储的最基本原理:
- set:在文件末尾追加一个 KV 对。
- get:匹配所有 Key,返回最后(也即最新)一条 KV 对中的 Value。
可以看出:写很快,但是读需要全文逐行扫描,会慢很多。典型的以读换写。为了加快读,我们需要构建索引:一种允许基于某些字段查找的额外数据结构。
索引从原数据中构建,只为加快查找。因此索引会耗费一定额外空间,和插入时间(每次插入要更新索引),即,重新以空间和写换读取。
这便是数据库存储引擎设计和选择时最常见的权衡(trade off):
- 恰当的存储格式能加快写(日志结构),但是会让读取很慢;也可以加快读(查找树、B 族树),但会让写入较慢。
- 为了弥补读性能,可以构建索引。但是会牺牲写入性能和耗费额外空间。
存储格式一般不好动,但是索引构建与否,一般交予用户选择。
哈希索引
本节主要基于最基础的 KV 索引。
依上小节的例子,所有数据顺序追加到磁盘上。为了加快查询,我们在内存中构建一个哈希索引:
- Key 是查询 Key
- Value 是 KV 条目的起始位置和
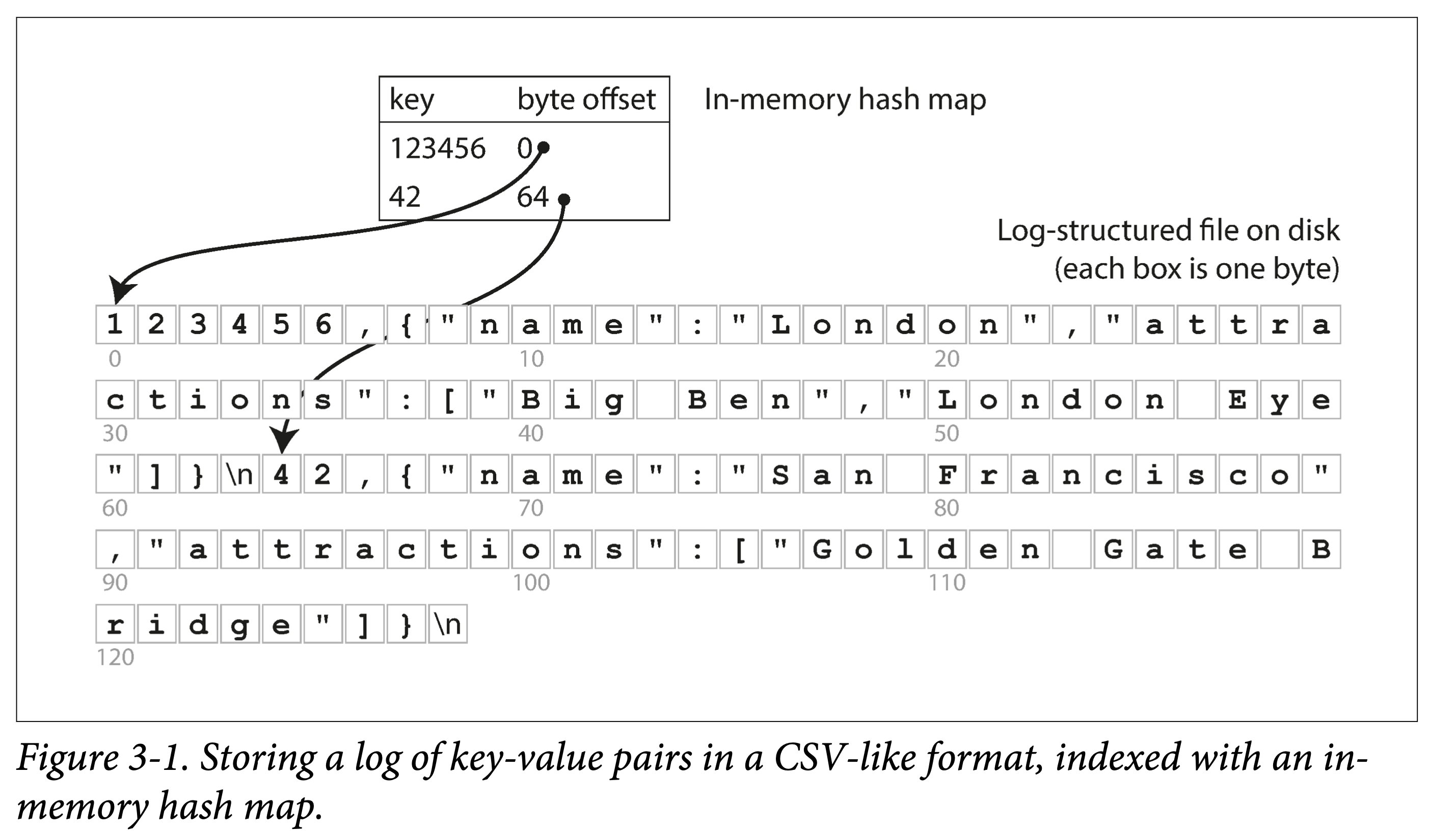
看来很简单,但这正是 Bitcask 的基本设计,但关键是,他 Work(在小数据量时,即所有 key 都能存到内存中时):能提供很高的读写性能:
- 写:文件追加写。
- 读:一次内存查询,一次磁盘 seek;如果数据已经被缓存,则 seek 也可以省掉。
如果你的 key 集合很小(意味着能全放内存),但是每个 key 更新很频繁,那么 Bitcask 便是你的菜。举个栗子:频繁更新的视频播放量,key 是视频 url,value 是视频播放量。
但有个很重要问题,单个文件越来越大,磁盘空间不够怎么办?
在文件到达一定尺寸后,就新建一个文件,将原文件变为只读。同时为了回收多个 key 多次写入的造成的空间浪费,可以将只读文件进行紧缩( compact ),将旧文件进行重写,挤出 “水分”(被覆写的数据)以进行垃圾回收。

当然,如果我们想让其工业可用,还有很多问题需要解决:
- 文件格式。对于日志来说,CSV 不是一种紧凑的数据格式,有很多空间浪费。比如,可以用 length + record bytes 。
- 记录删除。之前只支持 put\get,但实际还需要支持 delete。但日志结构又不支持更新,怎么办呢?一般是写一个特殊标记(比如墓碑记录,tombstone)以表示该记录已删除。之后 compact 时真正删除即可。
- 宕机恢复。在机器重启时,内存中的哈希索引将会丢失。当然,可以全盘扫描以重建,但通常一个小优化是,对于每个 segment file, 将其索引条目和数据文件一块持久化,重启时只需加载索引条目即可。
- 记录写坏、少写。系统任何时候都有可能宕机,由此会造成记录写坏、少写。为了识别错误记录,我们需要增加一些校验字段,以识别并跳过这种数据。为了跳过写了部分的数据,还要用一些特殊字符来标识记录间的边界。
- 并发控制。由于只有一个活动(追加)文件,因此写只有一个天然并发度。但其他的文件都是不可变的(compact 时会读取然后生成新的),因此读取和紧缩可以并发执行。
乍一看,基于日志的存储结构存在折不少浪费:需要以追加进行更新和删除。但日志结构有几个原地更新结构无法做的优点:
- 以顺序写代替随机写。对于磁盘和 SSD,顺序写都要比随机写快几个数量级。
- 简易的并发控制。由于大部分的文件都是不可变(immutable)的,因此更容易做并发读取和紧缩。也不用担心原地更新会造成新老数据交替。
- 更少的内部碎片。每次紧缩会将垃圾完全挤出。但是原地更新就会在 page 中留下一些不可用空间。
当然,基于内存的哈希索引也有其局限:
- 所有 Key 必须放内存。一旦 Key 的数据量超过内存大小,这种方案便不再 work。当然你可以设计基于磁盘的哈希表,但那又会带来大量的随机写。
- 不支持范围查询。由于 key 是无序的,要进行范围查询必须全表扫描。
后面讲的 LSM-Tree 和 B+ 树,都能部分规避上述问题。
- 想想,会如何进行规避?
SSTables 和 LSM-Trees
这一节层层递进,步步做引,从 SSTables 格式出发,牵出 LSM-Trees 全貌。
对于 KV 数据,前面的 BitCask 存储结构是:
- 外存上日志片段
- 内存中的哈希表
其中外存上的数据是简单追加写而形成的,并没有按照某个字段有序。
假设加一个限制,让这些文件按 key 有序。我们称这种格式为:SSTable(Sorted String Table)。
这种文件格式有什么优点呢?
高效的数据文件合并。即有序文件的归并外排,顺序读,顺序写。不同文件出现相同 Key 怎么办?
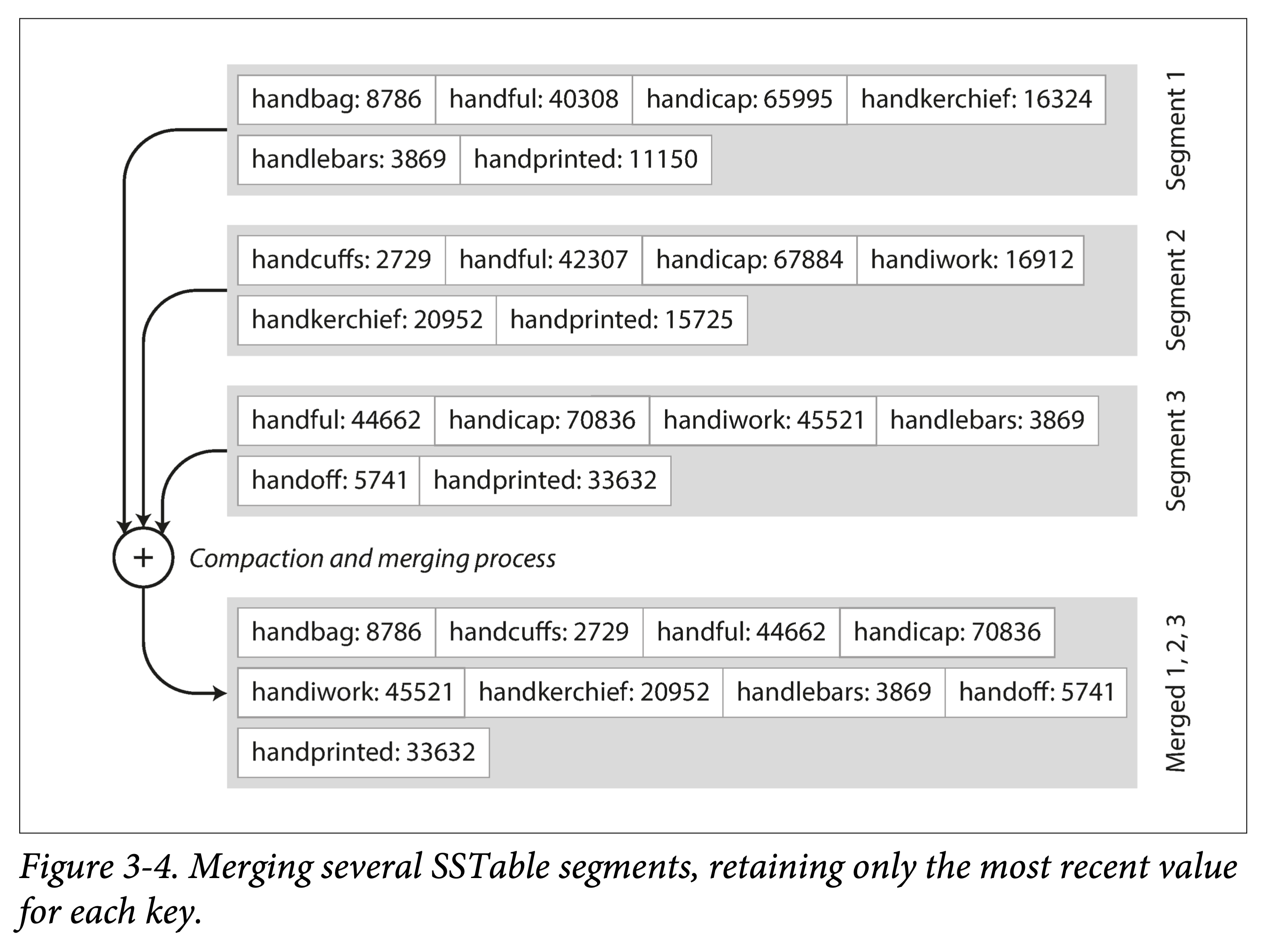
不需要在内存中保存所有数据的索引。仅需要记录下每个文件界限(以区间表示:[startKey, endKey],当然实际会记录的更细)即可。查找某个 Key 时,去所有包含该 Key 的区间对应的文件二分查找即可。
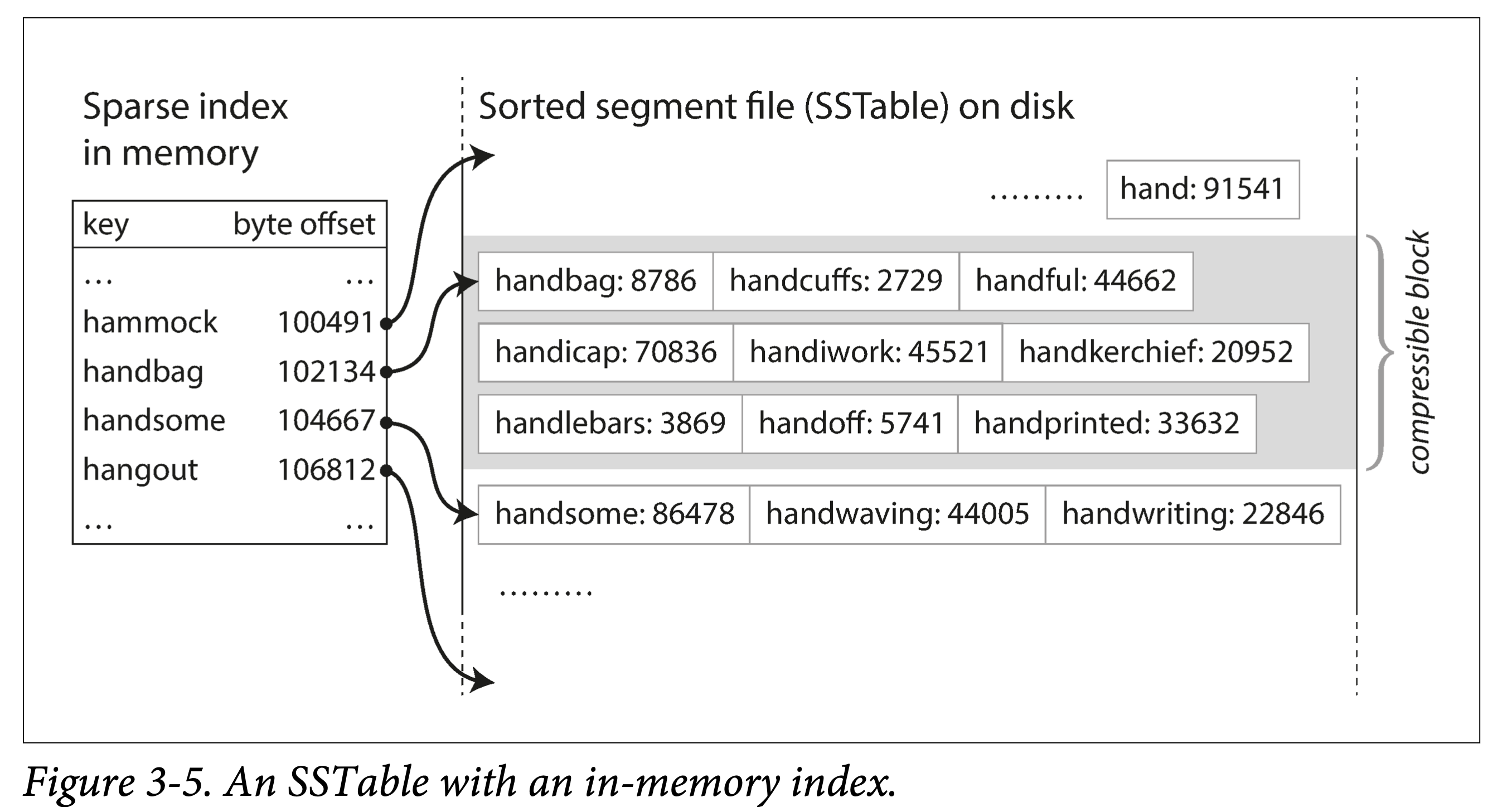
分块压缩,节省空间,减少 IO。相邻 Key 共享前缀,既然每次都要批量取,那正好一组 key batch 到一块,称为 block,且只记录 block 的索引。
构建和维护 SSTables
SSTables 格式听起来很美好,但须知数据是乱序的来的,我们如何得到有序的数据文件呢?
这可以拆解为两个小问题:
- 如何构建。
- 如何维护。
构建 SSTable 文件。将乱序数据在外存(磁盘 or SSD)中上整理为有序文件,是比较难的。但是在内存就方便的多。于是一个大胆的想法就形成了:
- 在内存中维护一个有序结构(称为 MemTable)。红黑树、AVL 树、条表。
- 到达一定阈值之后全量 dump 到外存。
维护 SSTable 文件。为什么需要维护呢?首先要问,对于上述复合结构,我们怎么进行查询:
- 先去 MemTable 中查找,如果命中则返回。
- 再去 SSTable 按时间顺序由新到旧逐一查找。
如果 SSTable 文件越来越多,则查找代价会越来越大。因此需要将多个 SSTable 文件合并,以减少文件数量,同时进行 GC,我们称之为紧缩( Compaction)。
该方案的问题:如果出现宕机,内存中的数据结构将会消失。 解决方法也很经典:WAL。
从 SSTables 到 LSM-Tree
将前面几节的一些碎片有机的组织起来,便是时下流行的存储引擎 LevelDB 和 RocksDB 后面的存储结构:LSM-Tree:
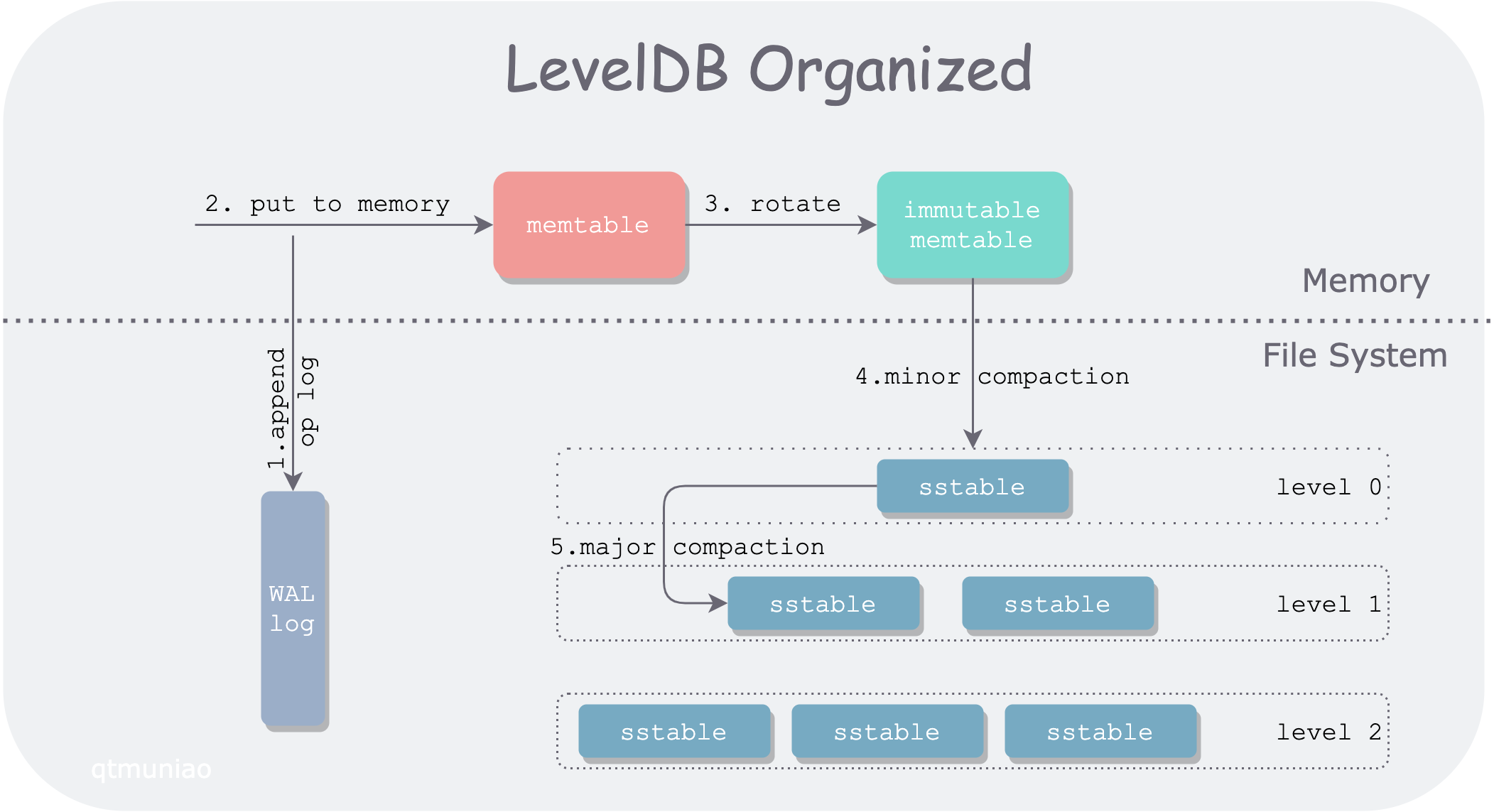
这种数据结构是 Patrick O’Neil 等人,在 1996 年提出的:The Log-Structured Merge-Tree。
Elasticsearch 和 Solr 的索引引擎 Lucene,也使用类似 LSM-Tree 存储结构。但其数据模型不是 KV,但类似:word → document list。
性能优化
如果想让一个引擎工程上可用,还会做大量的性能优化。对于 LSM-Tree 来说,包括:
优化 SSTable 的查找。常用 Bloom Filter。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用。
层级化组织 SSTable。以控制 Compaction 的顺序和时间。常见的有 size-tiered 和 leveled compaction。LevelDB 便是支持后者而得名。前者比较简单粗暴,后者性能更好,也因此更为常见。

对于 RocksDB 来说,工程上的优化和使用上的优化就更多了。在其 Wiki 上随便摘录几点:
- Column Family
- 前缀压缩和过滤
- 键值分离,BlobDB
但无论有多少变种和优化,LSM-Tree 的核心思想 —— 保存一组合理组织、后台合并的 SSTables —— 简约而强大。可以方便的进行范围遍历,可以变大量随机为少量顺序。
B 族树
虽然先讲的 LSM-Tree,但是它要比 B+ 树新的多。
B 树于 1970 年被 R. Bayer and E. McCreight 提出后,便迅速流行了起来。现在几乎所有的关系型数据中,它都是数据索引标准一般的实现。
与 LSM-Tree 一样,它也支持高效的点查和范围查。但却使用了完全不同的组织方式。
其特点有:
- 以页(在磁盘上叫 page,在内存中叫 block,通常为 4k)为单位进行组织。
- 页之间以页 ID 来进行逻辑引用,从而组织成一颗磁盘上的树。

查找。从根节点出发,进行二分查找,然后加载新的页到内存中,继续二分,直到命中或者到叶子节点。 查找复杂度,树的高度 —— O (lgn),影响树高度的因素:分支因子(分叉数,通常是几百个)。

插入 or 更新。和查找过程一样,定位到原 Key 所在页,插入或者更新后,将页完整写回。如果页剩余空间不够,则分裂后写入。
分裂 or 合并。级联分裂和合并。
一个记录大于一个 page 怎么办?
- 树的节点是逻辑概念,page or block 是物理概念。一个逻辑节点可以对应多个物理 page。
让 B 树更可靠
B 树不像 LSM-Tree ,会在原地修改数据文件。
在树结构调整时,可能会级联修改很多 Page。比如叶子节点分裂后,就需要写入两个新的叶子节点,和一个父节点(更新叶子指针)。
- 增加预写日志(WAL),将所有修改操作记录下来,预防宕机时中断树结构调整而产生的混乱现场。
- 使用 latch 对树结构进行并发控制。
B 树的优化
B 树出来了这么久,因此有很多优化:
- 不使用 WAL,而在写入时利用 Copy On Write 技术。同时,也方便了并发控制。如 LMDB、BoltDB。
- 对中间节点的 Key 做压缩,保留足够的路由信息即可。以此,可以节省空间,增大分支因子。
- 为了优化范围查询,有的 B 族树将叶子节点存储时物理连续。但当数据不断插入时,维护此有序性的代价非常大。
- 为叶子节点增加兄弟指针,以避免顺序遍历时的回溯。即 B+ 树的做法,但远不局限于 B+ 树。
- B 树的变种,分形树,从 LSM-tree 借鉴了一些思想以优化 seek。
B-Trees 和 LSM-Trees 对比
存储引擎
B-Tree
LSM-Tree
备注
优势
读取更快
写入更快
写放大
数据和 WAL
更改数据时多次覆盖整个 Page
数据和 WAL
Compaction
SSD 不能过多擦除。因此 SSD 内部的固件中也多用日志结构来减少随机小写。
写吞吐
相对较低:
- 大量随机写。
相对较高:
较低的写放大(取决于数据和配置)
顺序写入。
更为紧凑。
压缩率
存在较多内部碎片。
更加紧凑,没有内部碎片。
压缩潜力更大(共享前缀)。
但紧缩不及时会造成 LSM-Tree 存在很多垃圾
后台流量
更稳定可预测,不会受后台 compaction 突发流量影响。
写吞吐过高,compaction 跟不上,会进一步加重读放大。
由于外存总带宽有限,compaction 会影响读写吞吐。
随着数据越来越多,compaction 对正常写影响越来越大。
RocksDB 写入太过快会引起 write stall,即限制写入,以期尽快 compaction 将数据下沉。
存储放大
有些 Page 没有用满
同一个 Key 存多遍
并发控制
同一个 Key 只存在一个地方
树结构容易加范围锁。
同一个 Key 会存多遍,一般使用 MVCC 进行控制。
版权归原作者 Leread 所有, 如有侵权,请联系我们删除。