
Hadoop高可靠集群搭建步骤(手把手教学)
【超级详细】文章目录
1 HA集群基础配置
基于VMware Workstation 17 Pro
1.1 创建系统为Centos7(Linux)的虚拟机
一、用管理员身份运行虚拟机
二、创建新的虚拟机:
选择自定义→选择硬件兼容性:Workstation 15.x→选择稍后安装→选Linux(L)(选CentOS 7 64位)→编辑虚拟机名字并选择文件位置→处理器数量和内核数量均选1→选择虚拟机内存(若运行内存是8G,则选择1G,若16G则选择2G,以此类推)→选择网络NAT模式(NAT模式就是电脑能上网虚拟机就能上网)→控制器类型选择推荐→磁盘类型也选择推荐→选择创建新虚拟磁盘→最大磁盘大小选择10G,并选择将虚拟磁盘存储为单个文件(若电脑为256或512G的就选择10G,1t的可选择20G)→在自定义硬件中可以把打印机和声卡移除
三、安装系统:
点击CD/DVD,选择使用ISO映像文件,找到已下载好的光盘iso文件CentOS-7-x86_64-Minimal-1908.iso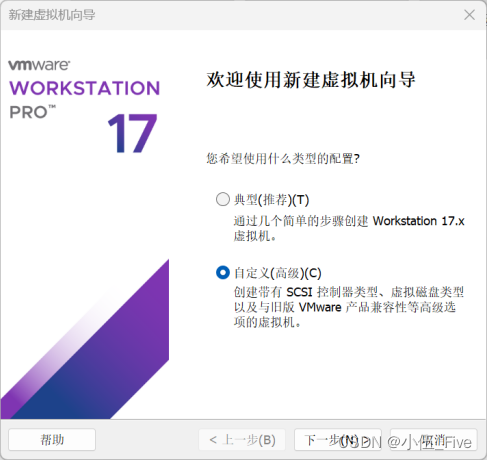
图 3-1虚拟机创建
四、开启虚拟机,选择第一个安装虚拟机(即直接按回车)
五、文字选英文版→选系统选→点击Done→安装的同时可设置密码
1.2 基本网络配置
一、修改主机名
1、配置hostname文件:
vi /etc/hostname
输入master
2、配置network文件:
vi /etc/sysconfig/network
输入NETWORKING=yes
HOSTNAME=master
(修改名字后要reboot重启虚拟机)
二、NET网络设置
首先以管理员身份进入,在页面左上角寻找“编辑”,点击进入后选择“虚拟网络编辑器”,点击“添加网络”,选择”VMnet8”,将”仅主机模式”改为“NAT模式”,
1、子网设置:
子网IP:192.168.222.0 #子网的最后一位一定是0
子网掩码:255.255.255.0
2、DHCP设置:
起始IP地址:192.168.222.128
结束IP地址:192.168.222.254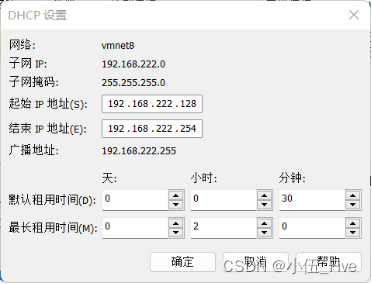
图 3-4 DHCP设置
3、NAT设置:
网关IP:192.168.222.2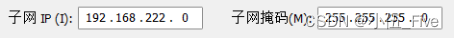
图 3-5 NAT设置
以上三步做完点击“应用”,再点击“确定”
三、虚拟机网络配置
1、配置ifcfg-ens33文件:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=dhcp 改为BOOTPROTO=static #静态的意思ONBOOT=no 改为ONBOOT=yes
再添加5条记录
IPADDR=192.168.222.171 #IPADDR 互联网协议地址GATEWAY=192.168.222.2 #GATEWAY 网关NETMASK=255.255.255.0 #NETWORK子网掩码DNS1=192.168.222.2 #DNS1域名解析服务器1DNS2=8.8.8.8 #DNS2 域名解析服务器2
2、网络服务重启并关闭防火墙:
service network restart
systemctl stop firewalld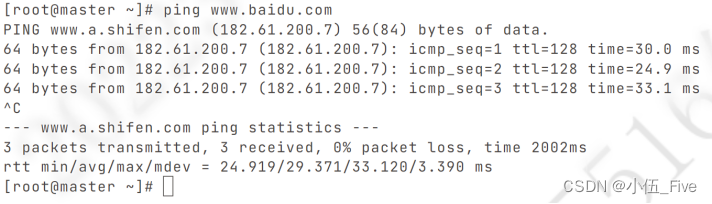
四、克隆四台虚拟机:虚拟机–管理–克隆–选完整克隆
图 3-7虚拟机克隆界面
五、修改克隆的虚拟机IP、机器名、网络名:
vi /etc/hostname
vi /etc/sysconfig/network
vi /etc/sysconfig/network-scripts/ifcfg-ens33
1.3 连接FinalShell
打开finalshell,页面左上角有一个文件夹图标,点击之后在弹出的页面上再点击左上角的文件夹图标,然后点击新建一个连接,点击“SSH连接”(免密安全登录)
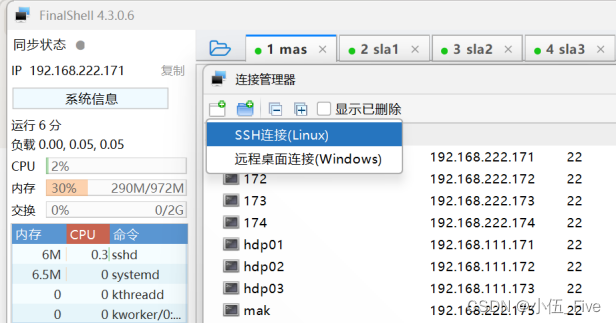
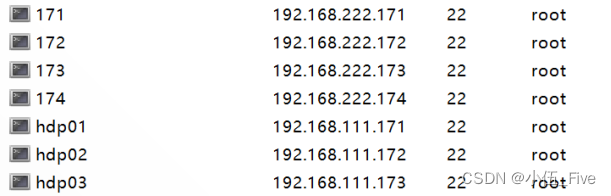
将ip 地址和名字做连接
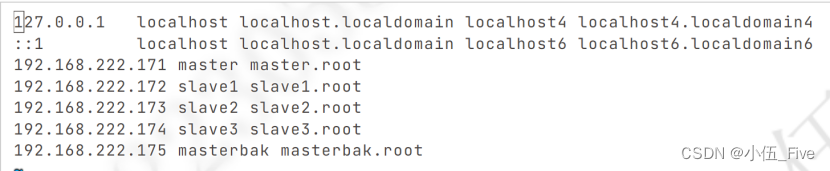
vi /etc/hosts键入:
192.168.222.171 master master.root
192.168.222.172 slave1 slave1.root
192.168.222.173 slave2 slave2.root
192.168.222.174 masterback masterbak.root
2 NTP时间同步和免密登录
2.1 NTP时间同步
安装NTP软件,并以master为时间服务器做时间同步
一、安装NTP:yum install -y ntp
二、修改ntp配置文件:
vi /etc/ntp.conf
末尾追加:server 127.127.1.0
Fudge 127.127.1.0 stratum 10
图 3-11配置conf文件
三、重启时间服务
/bin/systemctl restart ntpd.service
可以在slave1、slave2、slave3、masterbak上去更新时间(以master为标准进行时间的校对):
ntpdate master 结果:如下图
代码如下(示例):
2.2 集群免密登录
操作发现两个服务器之间通信(例如传数据)需要密码才可以。
当集群运行起来后,频繁交换数据,每次输入密码是不可能的。不输入密码如何保证安全呢?那就是进行加密
明文—加密—密文—解密—明文
具体实现步骤如下:
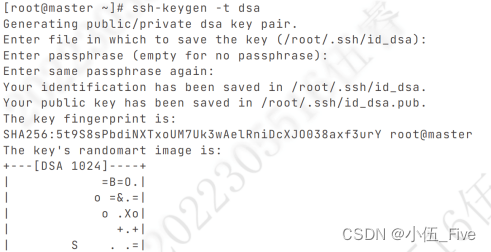
一、四台机器上生成公钥-密钥
ssh-keygen -t dsa(以master为例)
二、传递公钥(以slave1为例)
1.进入slave1中的 .ssh 文件夹:cd/root/.ssh
2.将slave1的公钥传递到master中
scp id_dsa.pub root@master:/root/.ssh/s1.pub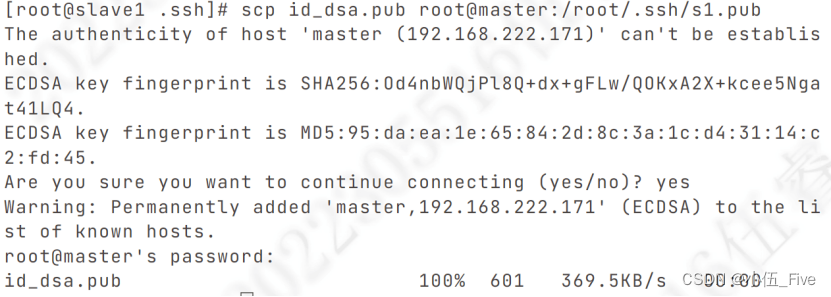
三、slave2,slave3和masterbak操作同上
四、在master中将五个公钥合并成一个公钥包
1.先切换到/root/.ssh目录下面:
cd /root/.ssh
2.将五个公钥合并成一个公钥包:
cat id_dsa.pub s1.pub s2.pub s3.pub mb.pub >> authorized_keys
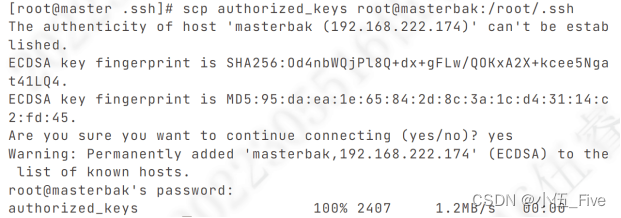
五、将master中合成的公钥包分发至集群内其他机器:
scp authorized_keys root@slave1:/root/.ssh
scp authorized_keys root@slave2:/root/.ssh
scp authorized_keys root@slave3:/root/.ssh
scp authorized_keys root@masterbak:/root/.ssh
六、验证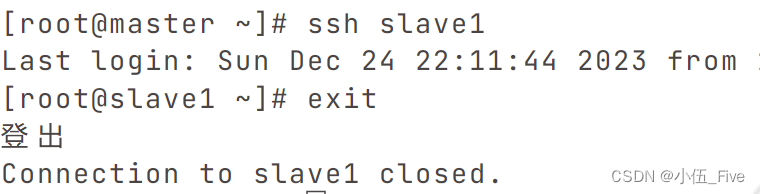
3 JDK的安装与配置
一、创建/opt/soft 文件夹:
mkdir -p /opt/soft
二、切换到这个目录下面:
cd /opt/soft
三、点击页面上的上传按钮,将JDK文件(jdk-8u171-linux-x64.tar.gz)上传到该目录下面
四、创建一个目录用来安装jdk
mkdir -p /usr/java
五、将JDK安装到特定的目录下:
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/java
六、修改环境变量
vi /etc/profile
exportJAVA_HOME=/usr/java/jdk1.8.0_171
exportCLASSPATH=.:$JAVA_HOME/lib
exportPATH=$PATH:$JAVA_HOME/bin
七、让环境变量生效:source /etc/profile
八、测试JDk安装配置成功:
1、java -version
九、分发至集群内其他机器
4 Zookeeper的安装与配置
一、切换到这个目录下面(master机器中):
cd /opt/soft
二、点击上传按钮,将zookeeper文件(zookeeper-3.4.10.tar.gz)上传到soft文件夹内部
三、创建一个目录用来安装zookeeper:
mkdir -p /usr/zookeeper
四、安装zookeeper
tar-zxvf zookeeper-3.4.10.tar.gz -C /usr/zookeeper
五、配置zookeeper
(1)配置zoo.cfg
/usr/zookeeper/zookeeper-3.4.10/conf下的zoo_sample.cfg 复制一份为zoo.cfg
进入该目录下,cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
编辑添加:
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog server.1=192.168.222.171:2888:3888
server.2=192.168.222.172:2888:3888
server.3=192.168.222.173:2888:3888
server.4=192.168.222.174:2888:3888
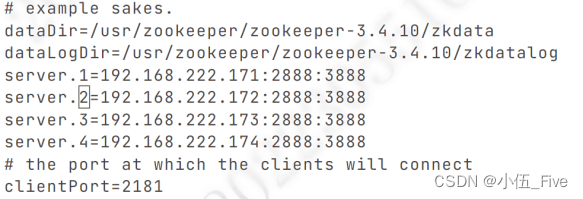
(2)创建zoo.cfg里配置的目录:
mkdir zkdata/mkdir zkdatalog
在 zkdata中:vi myid 并编辑内容为1

六、对另外四台机器进行分发
scp-r /usr/zookeeper root@slave1:/usr
scp-r /usr/zookeeper root@slave2:/usr
scp-r /usr/zookeeper root@slave3:/usr
scp-r /usr/zookeeper root@masterbak:/usr
七、修改slave1,slave2,slave3和masterbak的myid,分别为 2,3,4和5(注意:这里的数字2、3、4、5要与zoo.cfg中的server.数字 一一对应)
八、配置环境变量:
vi /etc/profile
添加:
exportZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10/
exportPATH=$PATH:$ZOOKEEPER_HOME
使环境变量生效:source /etc/profile
九、分发至集群内其他机器
十、启动四台虚拟机的zookeeper服务:
bin/zkServer.sh start
查看四台虚拟机的zookeeper状态(以master为例):
bin/zkServer.sh status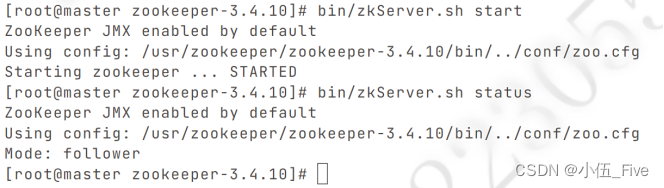
5 高可靠的Hadoop集群的安装与配置【核心】
一、在master上创建:
mkdir -p /usr/hadoop
二、解压安装:
cd /opt/soft上传已下好的hadoop-2.7.3
tar -zxvf hadoop-2.7.3.tar.gz -C /usr/hadoop
三、在五台机器上配置环境变量:
vi /etc/profile
exportHADOOP_HOME=/usr/hadoop/hadoop-2.7.3
exportCLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
exportPATH=$PATH:$HADOOP_HOME/bin
让环境变量生效:source /etc/profile

四、在master中cd /usr/hadoop/hadoop-2.7.3/etc/hadoop进入到hadoop配置文件
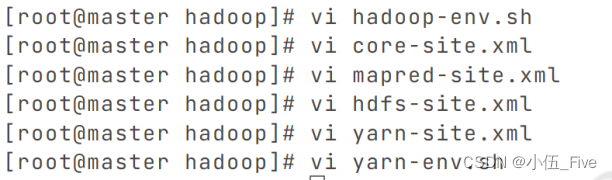
1、vi hadoop-env.sh修改java的安装目录:
export JAVA_HOME=/usr/java/jdk1.8.0_171
2、vi yarn-env.sh修改java的安装目录:
export JAVA_HOME=/usr/java/jdk1.8.0_171
3、配置vi core-site.xml,放在,中间)
<configuration><!-- 指定hdfs的nameservice为cluster --><property><name>fs.defaultFS</name><value>hdfs://cluster</value></property><!-- 指定zookeeper地址--><property><name>ha.zookeeper.quorum</name><value>192.168.222.171:2181,192.168.222.172:2181,192.168.222.173:2181,192.168.222.174:2181,192.168.222.175:2181</value></property><property><name>ha.zookeeper.session-timeout.ms</name><value>60000</value></property><!-- 故障检查时间 --><property><name>ha.failover-controller.cli-check.rpc-timeout.ms</name><value>60000</value></property><!-- ipc通讯超时时间 --><property><name>ipc.client.connect.timeout</name><value>20000</value></property><!-- 指定hadoop临时目录 --><property><name>hadoop.tmp.dir</name><value>file:/usr/hadoop/tmp</value></property></configuration>
4、配置vi mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
5、配置vi hdfs-site.xml
vi hdfs-site.xml
<configuration><!--指定hdfs的nameservice为cluster,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>cluster</value></property><!-- cluster下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.cluster</name><value>nn1,nn2</value></property><!-- nn1、nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.cluster.nn1</name><value>192.168.222.171:8020</value></property><property><name>dfs.namenode.rpc-address.cluster.nn2</name><value>192.168.222.175:8020</value></property><!-- nn1、nn2的http通信地址 --><property><name>dfs.namenode.http-address.cluster.nn1</name><value>192.168.222.171:50070</value></property><property><name>dfs.namenode.http-address.cluster.nn2</name><value>192.168.222.175:50070</value></property><property><name>dfs.namenode.servicerpc-address.cluster.nn1</name><value>192.168.222.171:53310</value></property><!-- 指定NameNode的元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://192.168.222.172:8485;192.168.222.173:8485;192.168.222.174:8485/cluster</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/usr/hadoop/hdfs/journal/data</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 配置失败自动切换实现方式 --><property><name>dfs.client.failover.proxy.provider.cluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value></property><!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 --><property><name>dfs.ha.fencing.methods</name><value>
sshfence
shell(/bin/true)
</value></property><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.permissions.enable</name><value>false</value></property><property><name>dfs.image.transfer.bandwidthPerSec</name><value>1048576</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/hadoop/hdfs/name</value></property><property><name>dfs.datanode.name.dir</name><value>file:/usr/hadoop/hdfs/data</value></property><property><name>dfs.namenode.checkpoint.dir</name><value>file:/usr/hadoop/hdfs/namesecondary</value></property></configuration>
6、配置 vi yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>192.168.222.171</value></property></configuration>
7、配置slaves
vi slaves
删去localhost
输入
192.168.222.172
192.168.222.173
192.168.222.174
五、将配置好的hadoop分发到其他服务器上:
scp -r /usr/hadoop root@slave1:/usr
scp -r /usr/hadoop root@slave2:/usr
scp -r /usr/hadoop root@slave3:/usr
scp -r /usr/hadoop root@masterbak:/usr
六、在四台机器上启动zookeeper:
cd $ZOOKEEPER_HOME
bin/zkServer.sh start
七、启动journalNode集群(在slave1,slave2,slave3)
$HADOOP_HOME/sbin/hadoop-daemons.sh start journalnode
图 3-23 启动journalNode集群
八、格式化HDFS(namenode)第一次要格式化
(在master,masterbak中任意一台,我选择master)
hdfs namenode –format
九、在master上格式化zkfc,使zookeeper中生成HA节点:
bin/hdfs zkfc -formatZK
在master上格式化hdfs
格式成功后,查看zookeeper中可以看到
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[cluster]
十、启动zkfc来监控NN状态(在master,masterbak)
sbin/hadoop-daemon.sh start zkfc
十一、启动HDFS(namenode)(在master即可)
sbin/start-dfs.sh
十二、把NameNode的数据同步到masterbak上(在masterbak上执行)
hdfs namenode –bootstrapStandby
十三、启动masterbak上的namenode作为standby
sbin/hadoop-daemon.sh start namenode
十四、启动YARN
在master上执行如下命令
sbin/start-yarn.sh
启动YARN(MR)(在192.168.222.171即可)
图 3-24启动Hadoop集群
在五台机器上jps查看进程,如下图。
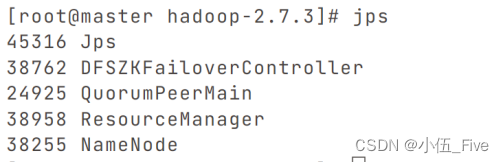
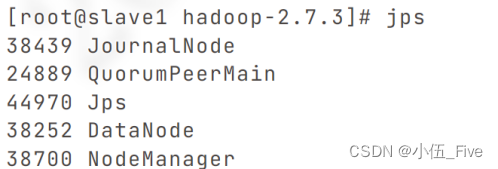
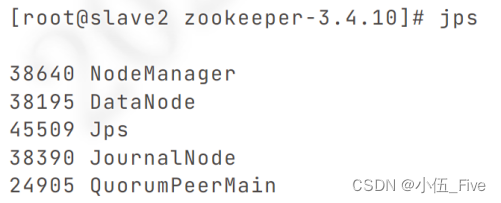


6.功能验证
在浏览器上:http://192.168.222.171:50070。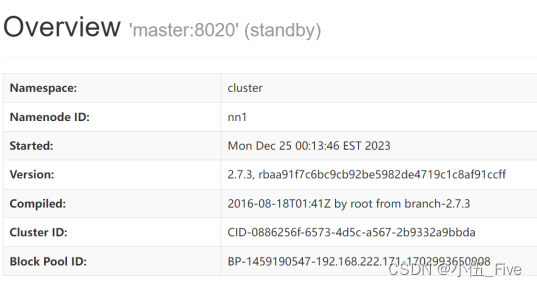
在浏览器上:http://192.168.222.175:50070。
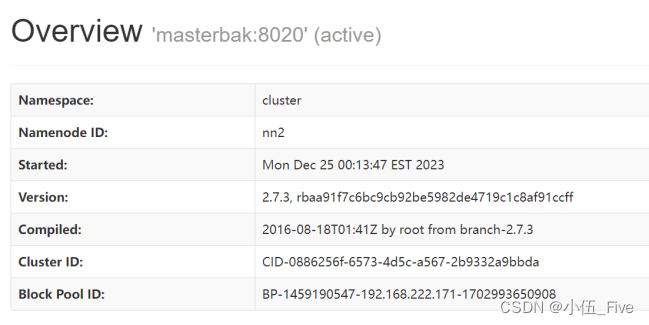
此时master节点处于standby状态,masterback节点处于active状态,当主节点namenode失效时,备用节点会自动替代上去,因此我们模拟主节点失灵,在masterbak上关闭namenode再去查看master的namenode状态。
执行命令: sbin/hadoop-daemon.sh stop namenode
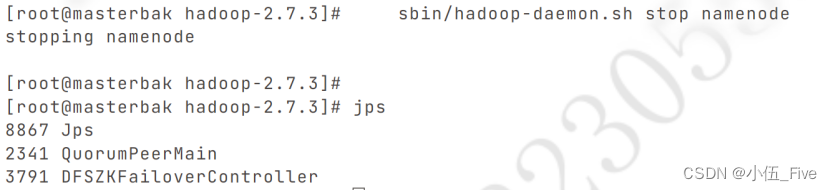
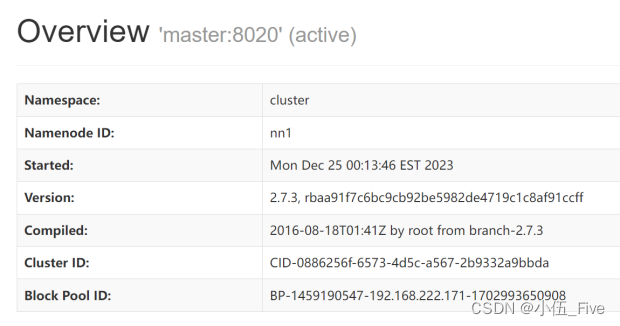
因为masterbak关闭了namenode,所以会拒绝连接而无法查看状态。
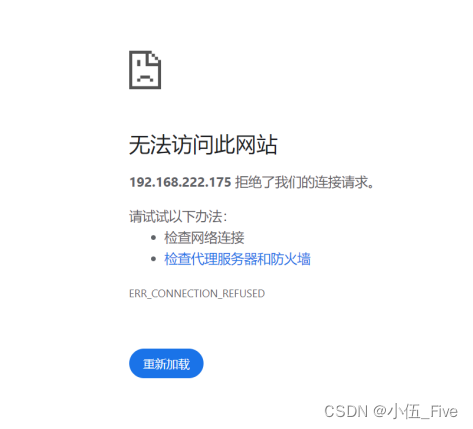
注意
保证master和masterbak均有name文件,没有的话通过scp传输过去
创作不易,关注一波呗
版权归原作者 小伍_Five 所有, 如有侵权,请联系我们删除。