
上一篇我们已经写到了对索引库的操作,现在我们要更进一步,对文档document及后面的操作:
- 我们现在添加文档到索引库(相当于MySQL添加一条记录到table当中)- 我们新建立了一个HotelDocumentTest测试类-
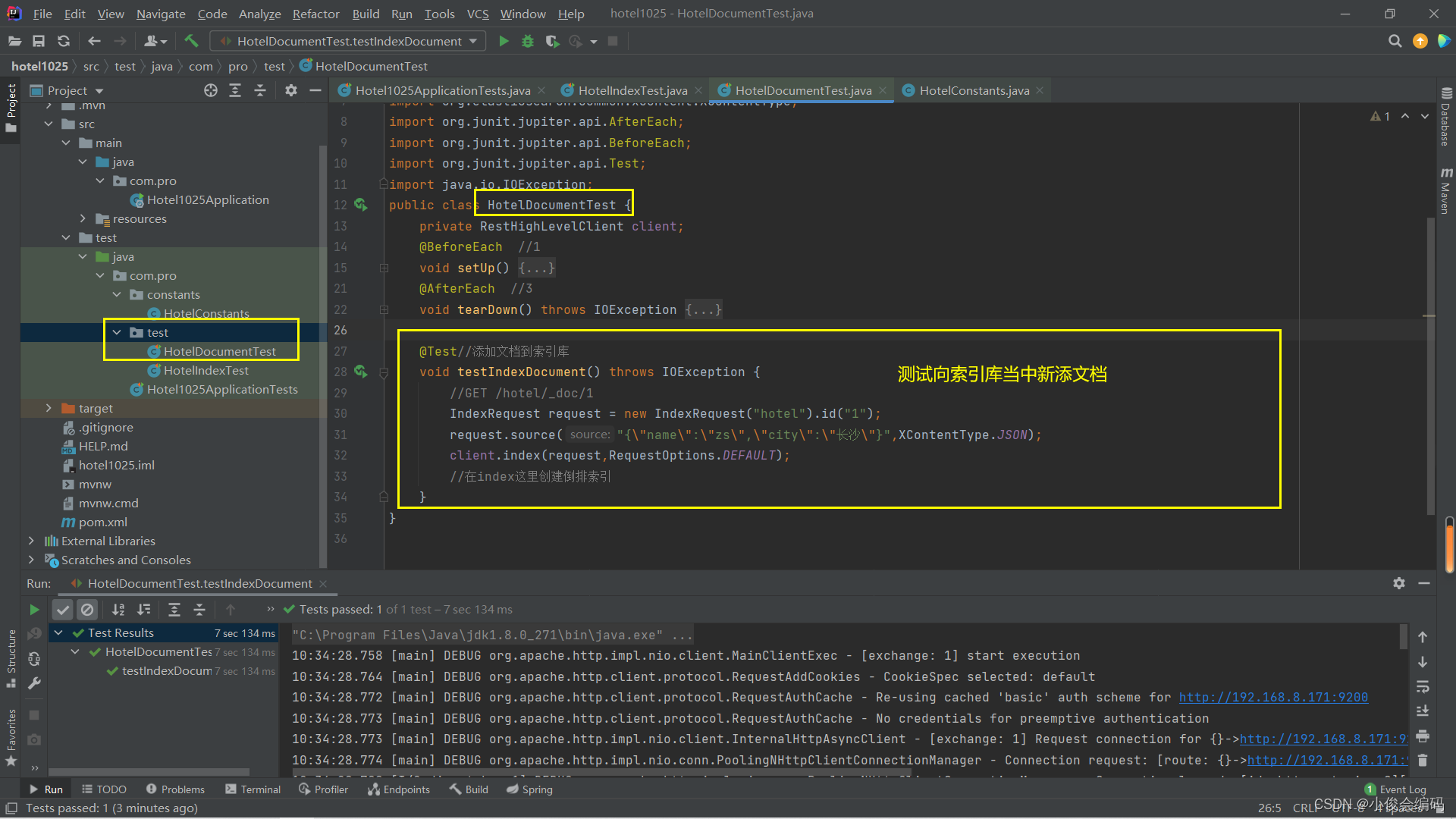 -
- @Test//添加文档到索引库 void testIndexDocument() throws IOException { //GET /hotel/_doc/1 IndexRequest request = new IndexRequest("hotel").id("1"); request.source("{\"name\":\"zs\",\"city\":\"长沙\"}",XContentType.JSON); client.index(request,RequestOptions.DEFAULT); //在index这里创建倒排索引 } - 刚刚我们测试了添加一条记录。但是我们现在需要将MySQL当中的hotel表的所有记录导入hotel索引库,那么我们需要建两个实体类,一个对应MySQL,一个对应es索引库,然后将两个实体类进行关联,从而将MySQL的hotel表和es的索引库进行关联
- 首先我们创建对应MySQL的实体类
@TableName("tb_hotel")public class Hotel { @TableId(type = IdType.AUTO) private Long id; private String name; private String address; private Integer price; private Integer score; private String brand; private String city; private String starName; private String business; private String latitude; private String longitude; private String pic;}- 然后我们需要用到mybatis-plus来操作MySQL数据库,所以需要导入这两个依赖
<!--整合mybatis-plus--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.49</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.0.5</version> </dependency>- 然后建一个对应hotel索引库的实体类:(构造函数location那里不一样)
- 思路:我们是是将MySQL对应的hotel实体类的对象作为参数,传进索引库的构造方法里面来对索引库对象对应的属性进行初始化
public class HotelDoc { private Long id; private String name; private String address; private Integer price; private Integer score; private String brand; private String city; private String starName; private String business; /*经纬度换成location*/ private String location; private String pic; public HotelDoc() { } /*构造函数*/ public HotelDoc(Hotel hotel) { this.id = hotel.getId(); this.name = hotel.getName(); this.address = hotel.getAddress(); this.price = hotel.getPrice(); this.score = hotel.getScore(); this.brand = hotel.getBrand(); this.city = hotel.getCity(); this.starName = hotel.getStarName(); this.business = hotel.getBusiness(); /*纬度和经度*/ this.location = hotel.getLatitude()+","+hotel.getLongitude(); this.pic = hotel.getPic(); }}- 然后写hotelMapper,继承BaseMapper
- 再写hotelService,继承苞米豆的IService-

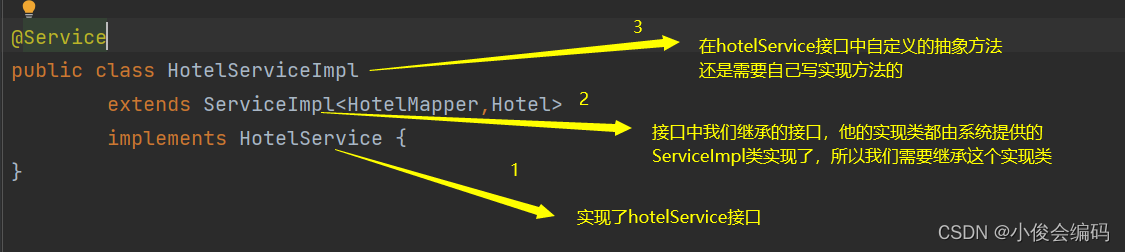
- 然后写他的实现类,我们是继承了mybatis-plus提供的ServiceImpl-
- 紧接着我们写service的测试类 -
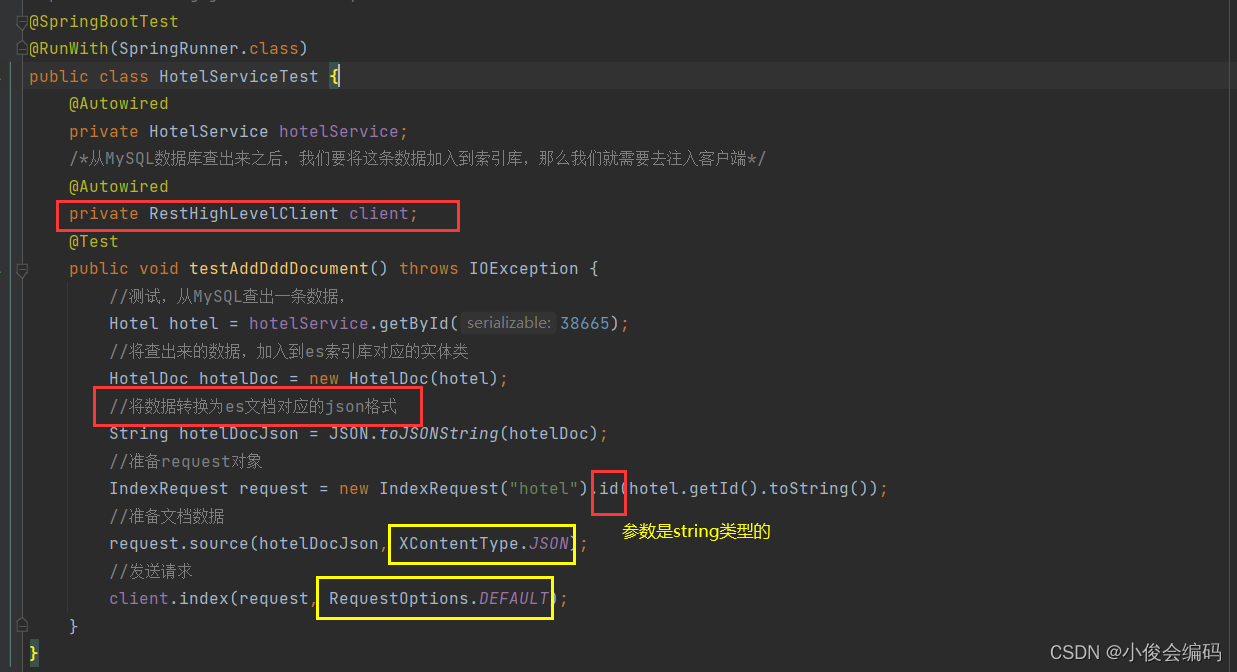 - 我们既然要注入es客户端,那么我们容器当中就需要有这个es客户端,所以我们去启动类配置,并且将启动类配置好扫描器:- 扫描器:**@MapperScan("com.pro.mapper")**-
- 我们既然要注入es客户端,那么我们容器当中就需要有这个es客户端,所以我们去启动类配置,并且将启动类配置好扫描器:- 扫描器:**@MapperScan("com.pro.mapper")**- @Bean public RestHighLevelClient client(){ return new RestHighLevelClient( RestClient.builder(HttpHost.create("http://192.168.8.171:9200")) ); } - 既然要连接MySQL数据库,那么我们需要去核心配置文件写上我们的配置- 数据库连接四大金刚- mybatis.xml文件扫描包的配置- mapper别名配置- 开启驼峰命名
#mysqlspring.datasource.driver-class-name=com.mysql.jdbc.Driverspring.datasource.url=jdbc:mysql://192.168.8.171:3306/hotelspring.datasource.username=rootspring.datasource.password=root#扫描包mybatis-plus.mapper-locations=classpath:mapper/*.xml#别名mybatis-plus.type-aliases-package=com.pro.domain#驼峰mybatis-plus.configuration.map-underscore-to-camel-case=true- 执行测试类之后,我们去查一下是否有这个文档记录,
- source里面就是我们加进来的内容
- get /hotel/_doc/38665-
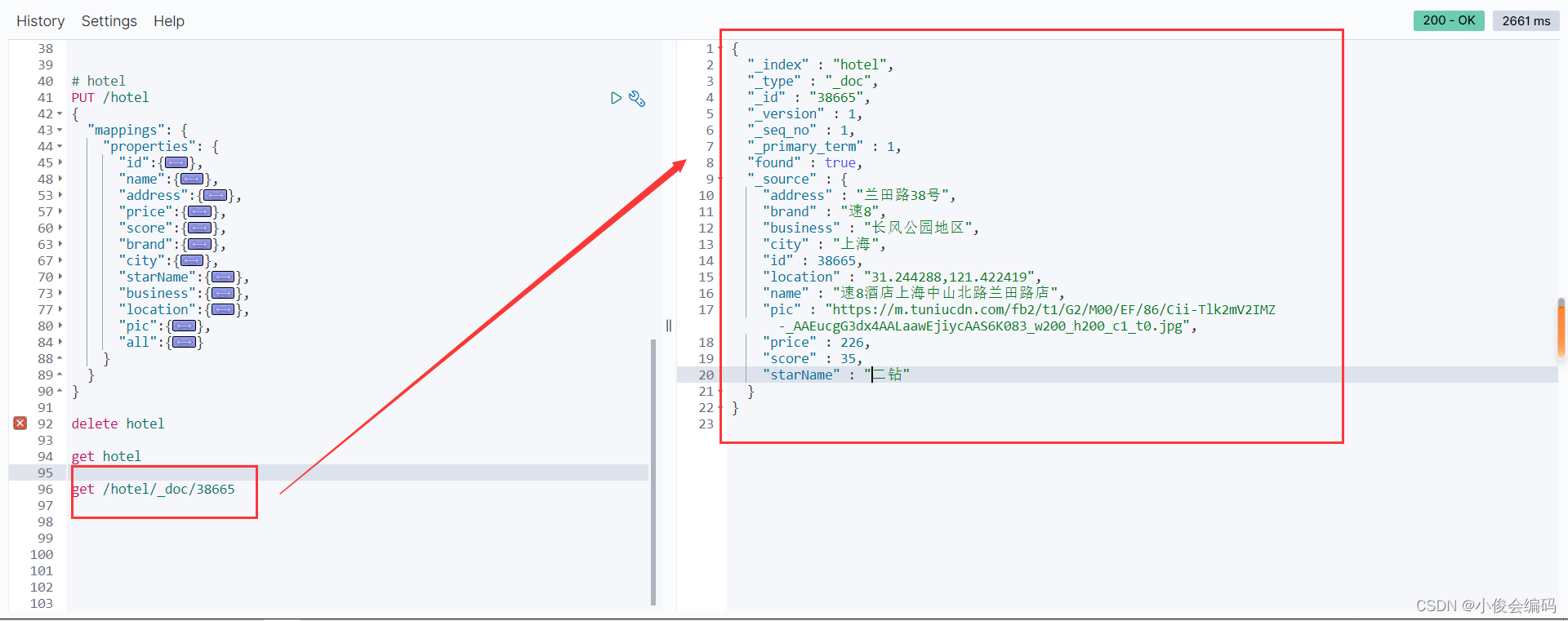
那么我们查询MySQL记录并将其加入索引库成功了!
有了增加,我们再来写修改,删除,查看以及批量增加
- 查单个
/*根据id查出索引库的文档,强转为对象输出*/ @Test public void testGetDocumentById() throws IOException { GetRequest request = new GetRequest("hotel", "38665"); //发请求,得到响应 GetResponse response = client.get(request, RequestOptions.DEFAULT); String json = response.getSourceAsString(); HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class); System.out.println(hotelDoc); }- 修改
/*根据id修改索引库对应的文档*/ @Test public void testUpdateDocument(){ //1.request UpdateRequest request = new UpdateRequest("hotel", "38665"); //修改 request.doc( "price","262", "starName","三钻" ); }- 删除
/*根据id删除索引库对应的文档*/ @Test public void TestDeleteDocumentById() throws IOException { //创建request对象 DeleteRequest request = new DeleteRequest("hotel", "38665"); //删除文档 client.delete(request,RequestOptions.DEFAULT); }- 批量增加
/*将MySQL查出来的所有记录加到索引库 * 批量操作 * */ @Test public void testBulkRequest() throws IOException { QueryWrapper queryWrapper = new QueryWrapper(); List<Hotel> hotelList = hotelService.list(queryWrapper); BulkRequest request = new BulkRequest(); for (Hotel hotel : hotelList) { HotelDoc hotelDoc = new HotelDoc(hotel); //将数据对象,一个个转为json,加入到批量操作的对象request中 request.add(new IndexRequest("hotel") .id(hotelDoc.getId().toString()) .source(JSON.toJSONString(hotelDoc),XContentType.JSON)); } //发送请求 client.bulk(request,RequestOptions.DEFAULT); }es官方提供了基于json的DSL来查询
- 地址:Query DSL | Elasticsearch Guide [8.4] | Elastic -
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html - 译文地址 -
https://www.kancloud.cn/apachecn/elasticsearch-doc-zh/1945172 - es提供了基于json的DSL来查询
- ES的DSL类似于MySQL的SQL,我们可以进行一个对比
select * from class;select * from stu;select * from stu where classid = 1;-- in 条件可以是一个或多个--select * from stu where classid in (1);select * from stu where classid in (1,2);select * from stu where classid = (select classid from class where classname='1班');-- 五个聚合函数 --select count(*) from stu;select avg(age) from stu;select sum(age) from stu;select max(age) from stu;select min(age) from stu;-- 分组查询 select 后面只能跟分组的字段,聚合函数--select classid,avg(age) from stu GROUP BY classid;-- 对所有记录筛选 --select * from stu where age < 20;-- 对组进行筛选,使用having,后面只能跟分组的字段,聚合函数 --select classid,avg(age) from stu GROUP BY classid having avg(age) > 21;-- 温哥华 --select classid,avg(age) from stu where gender = '男' GROUP BY classid having avg(age) > 21;select * from stu,class;select * from stu,class where stu.classid=class.classid and stu.stuid=1;-- 内连接 两边协商,没有的去取消,查出5条数据 --select * from stu s inner join class c on s.classid=c.classid;-- 左连接,以左为主,可以查6条数据 --select * from stu s left join class c on s.classid=c.classid;-- 右连接,以右为主,可以查5条数据 --select * from stu s right join class c on s.classid=c.classid;- 常见的查询类型: - 查所有,match_all- 全文检索,可以利用分词器对用户输入进行分词,再去倒排索引库中取匹配 - match_query- multi_match_query- 精确查询,一般是keyword,数值,日期,boolean,id,range,term- 地理(geo)查询,经纬度查询 - geo_distance- geo_bounding_box- 复合(compound)查询,可以将上面的查询组织在一起,合并查询 - bool- function_score- 查询DSL的语法:-
#查询dsl的语法GET /hotel/_search{ "query":{ "查询类型":{ "FIELD":"TEXT" } }}- 查所有: -#查所有GET /hotel/_search{ "query":{ "match_all":{} }}- match查询,会对用户的输入分词,再到索引库检索 -#match查询,会对用户的输入分词,再到索引库检索GET /hotel/_search{ "query":{ "match":{ "all":"深圳如家" } }}#允许多个字段搜 ,字段越多,查询性能越差GET /hotel/_search{ "query":{ "multi_match":{ "query":"深圳如家", "fields": ["brand","name","business"] } }}#上面这两种查询结果是一样的,因为这三个字段我们已经copy_to all里面了,所以第一种显然要好些-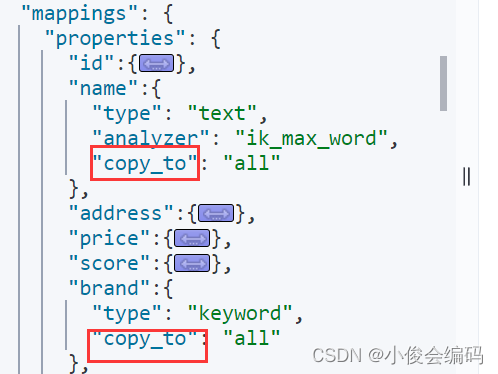 - match,multi_match的区别:后者可以搜多个字段- #精准查,term不分词:例如查品牌-
- match,multi_match的区别:后者可以搜多个字段- #精准查,term不分词:例如查品牌- #精准查询 term 特点:不分词GET /hotel/_search{ "query":{ "term":{ "city":{ "value": "上海" } } }}- #范围内精准查询 range 特点:不分词 - **gte:>=, lte:<=**#范围内精准查询 range 特点:不分词GET /hotel/_search{ "query": { "range": { "price": { "gte": 100, "lte": 300 } } }}- t**erm,range这两种查询:前者一般搜keyword,后者一般搜数值(在某个范围内**)- **#地理查询,经纬度查询:geo_distance; geo_bounding_box**- **geo_distance: 圆形范围,根据范围和经纬度查**-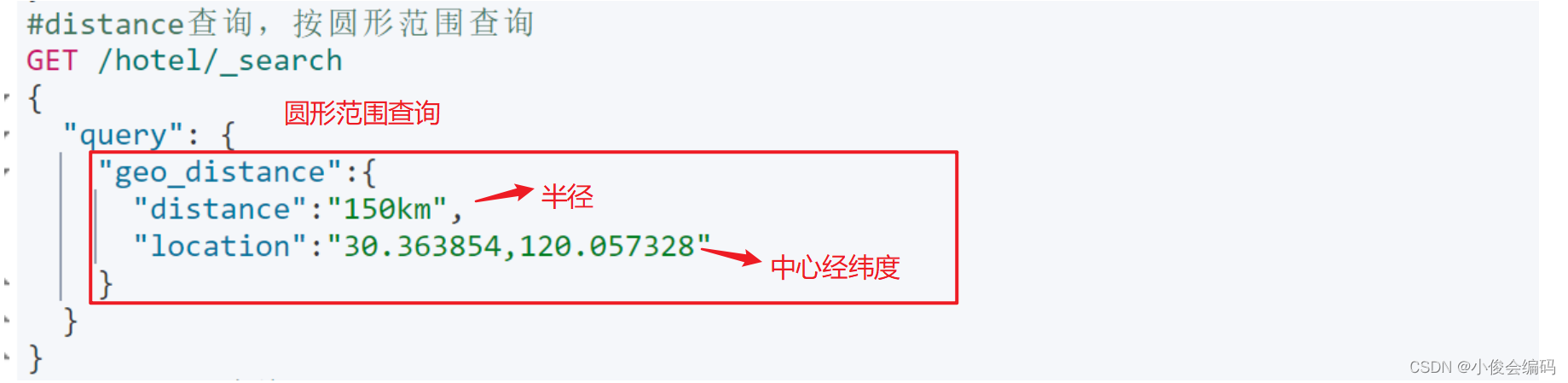 -
- #地理查询,经纬度查询:#geo_distance: 圆形范围GET /hotel/_search{ "query":{ "geo_distance":{ "distance":"150km", "location":"31.174377,121.442875" } }}- **geo_bounding_box矩形范围:lat纬度,lon经度**-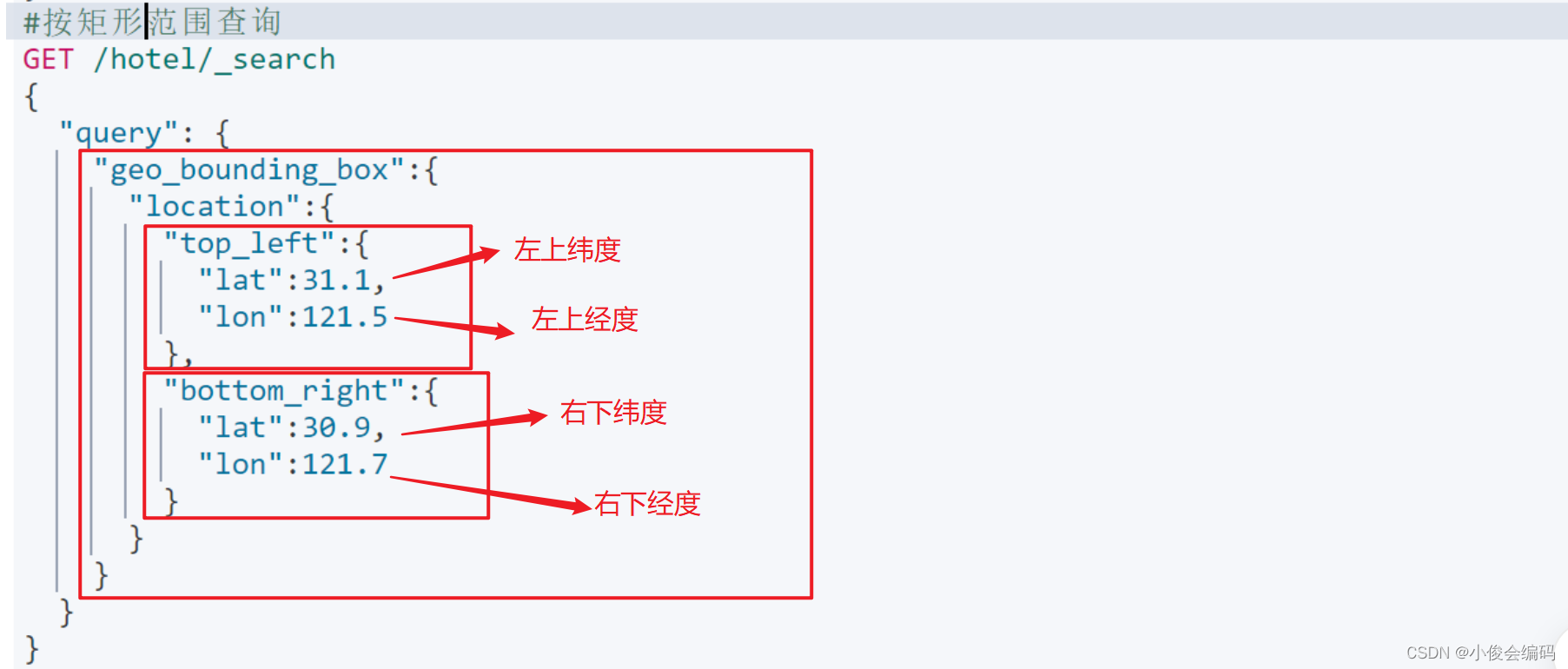
#geo_bounding_box矩形范围:lat纬度,lon经度GET /hotel/_search{ "query":{ "geo_bounding_box":{ "location":{ "top_left":{ "lat":31.1, "lon":121.5 }, "bottom_right":{ "lat":30.9, "lon":121.7 } } } }}- **#复合查询 **- **将简单的查询组合起来**- **算分函数查询,function score ,可以控制文档相关性算分,**- **控制文档排名**- **1)function score**先查所有all里面分词有外滩的文档,然后再过滤出brand为如家的品牌(精准过滤),最后对对应文档的_score进行操作-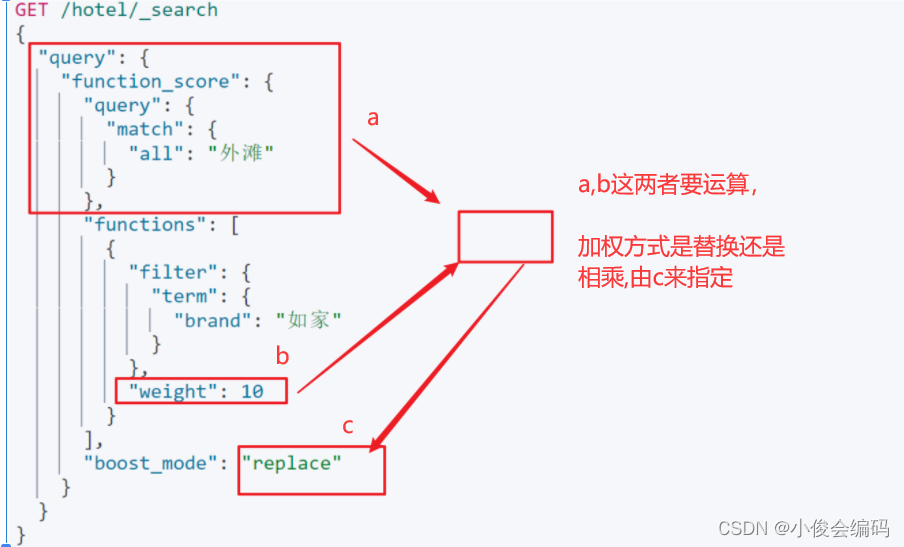 - **filter:term精准过滤出“如家”这个品牌(过滤出哪些文档要加分)**- **算分函数**- weight: 给一个常量值作为函数的结果:- random_score 随机生成一个值,作为函数结果- script_score 自定义计算公式,公式结果作为函数结果- field_score_factor 用文档中的某个字段作为函数的结果- 加权模式(boost_mode):定义function score 和 query score(查出的分值之间的运算方式:**默认相乘**) - multiply: 两者相乘 (默认)- replace: 用算分函数**替换**查询出来的分值- **其它 :sum,avg,max,min**-
- **filter:term精准过滤出“如家”这个品牌(过滤出哪些文档要加分)**- **算分函数**- weight: 给一个常量值作为函数的结果:- random_score 随机生成一个值,作为函数结果- script_score 自定义计算公式,公式结果作为函数结果- field_score_factor 用文档中的某个字段作为函数的结果- 加权模式(boost_mode):定义function score 和 query score(查出的分值之间的运算方式:**默认相乘**) - multiply: 两者相乘 (默认)- replace: 用算分函数**替换**查询出来的分值- **其它 :sum,avg,max,min**- #1)function score先查所有all里面分词有外滩的文档,然后再过滤出brand为如家的品牌(精准过滤),最后对对应文档的_score进行操作GET /hotel/_search{ "query":{ "function_score": { "query": { "match":{ "all":"外滩" } }, "functions": [ { "filter": { "term":{ "brand": "如家" } }, "weight":10 } ], "boost_mode": "replace" } }}- ### 复合查询之布尔查询- 是一个或多个查询子句的组合,子查询的组合方式- must 必须匹配每个子查询 &&- should 选择性的匹配子查询 ||- must_not 必须不匹配 ,不参与算分- filter 必须匹配,不参与算分-#搜索如家,价格小于等于400,坐标在31.2,121.5周围十公里范围内的酒店GET /hotel/_search{ "query":{ "bool": { "must": [ { "match": { "FIELD": "如家" } } ], "must_not": [ { "range": { "FIELD": { "gte": 400 } } } ], "filter": [ { "geo_distance":{ "distance":"10km", "location":{ "lat":31.21, "lon":121.5 } } } ] } } }}- ### **有了搜索结果之后,我们可以对搜索结果进行排序(默认是根据算分来排)**- **可以排序的字段类型:keyword,数值,地理坐标,日期**- **1:**> > - #排序,根据评分降序 GET /hotel/_search { "query":{ "match_all": {} }, "sort":[ { "score":{ "order":"desc" } } ] }- 2: > > - #按坐标排序 GET /hotel/_search { "query":{ "match_all": {} }, "sort":[ { "_geo_distance": { "location": "31.21,121.5", "order": "desc", "unit": "km" } } ] }- 3: > > - #按分值排序,分值一致时,按价格升序 GET /hotel/_search { "query":{ "match_all": {} }, "sort":[ { "score":{ "order": "desc" }, "price": { "order": "asc" } } ] } - 4: > > - #按某坐标,周围的酒店,距离降序排序 #查询的sort的值,是公里数 #注意,如果排序,则打分为null GET /hotel/_search { "query":{ "match_all": {} }, "sort":[ { "_geo_distance": { "location": { "lat": 30, "lon": 120 }, "order": "desc", "unit": "km" } } ] }- ### 分页:默认的返回10条,from,size> > - #分页 #es 默认的返回10条,from,size,我们现在分20条 GET /hotel/_search { "query":{ "match_all": {} }, "from": 0, "size": 20, "sort":[ { "price": { "order": "asc" } } ] }
#如果集群,:每台机器分配一些
#es的查新结果上限为10000条,超一条都会提示large
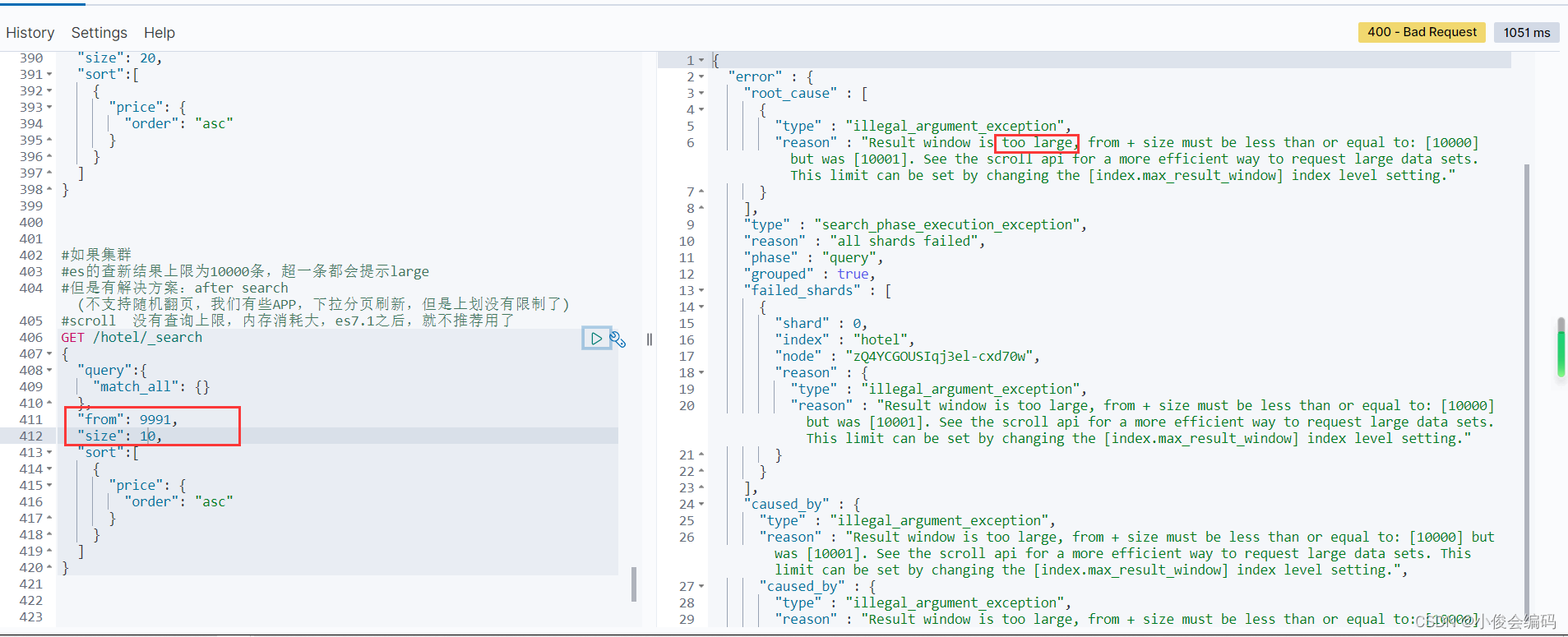
#但是有解决方案:after search (不支持随机翻页,我们有些APP,下拉分页刷新,但是上划没有限制了,回不到上一页
#scroll 没有查询上限,内存消耗大,es7.1之后,就不推荐用了
- 练习:搜索:价格在220以内的酒店- 按从小到大升序排列- 取前五个酒店-
#练习:搜索:价格在220以内的酒店#按从小到大升序排列#取前五个酒店GET /hotel/_search{ "query": { "range": { "price": { "lte": 220 } } }, "from": 0, "size": 5, "sort": [ { "price": { "order": "asc" } } ]} 高亮显示 - ** 高亮,require_field_match表示:是否匹配搜索字段和高亮字段**-
#高亮,require_field_match表示:是否匹配搜索字段和高亮字段GET /hotel/_search{ "query":{ "match":{ "all":"如家" } }, "highlight": { "fields": { "name": {"require_field_match": "false"} } }}- 设定标签,不设定,标签默认是em,搜索字段和高亮字段默认必须匹配-
搜索小结- 结构:- get /hotel/_search- query- from size- sort- field,_geo_distance- hight
本文转载自: https://blog.csdn.net/qq_60555957/article/details/127547447
版权归原作者 小俊会编码 所有, 如有侵权,请联系我们删除。
版权归原作者 小俊会编码 所有, 如有侵权,请联系我们删除。