
章节十:Selenium
目录
Hi,又见面啦,上一关,我们认识了
cookies
和
session
。
分别学习了它们的用法,以及区别。
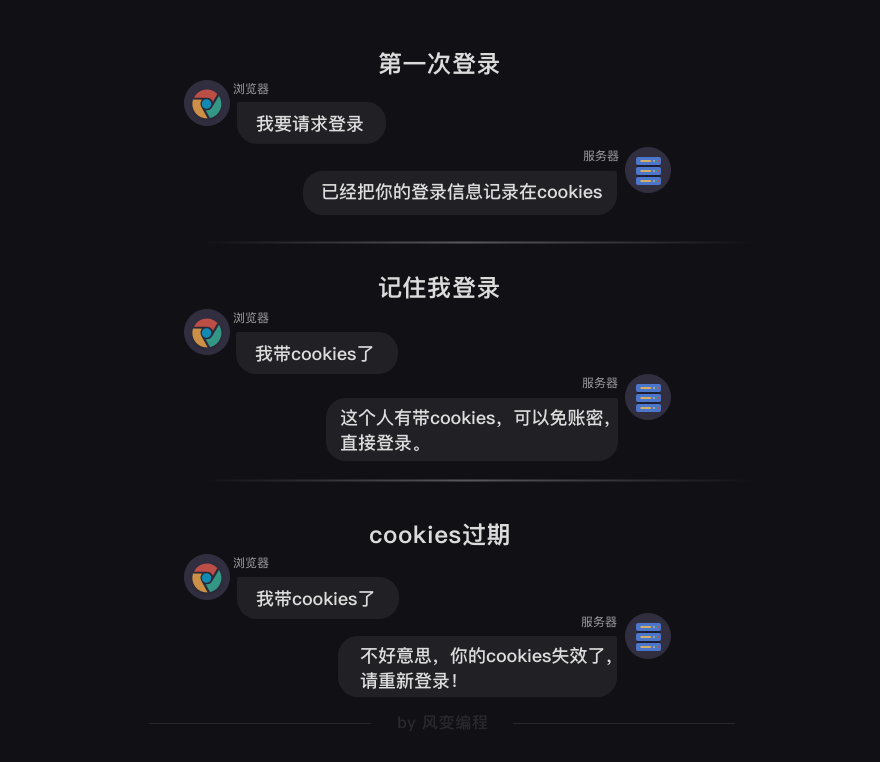

还做了一个项目:带着小饼干登录,然后在博客中发表评论。
除了上一关所讲的登录问题,在爬虫过程中,我们还可能会遇到各种各样棘手的问题——
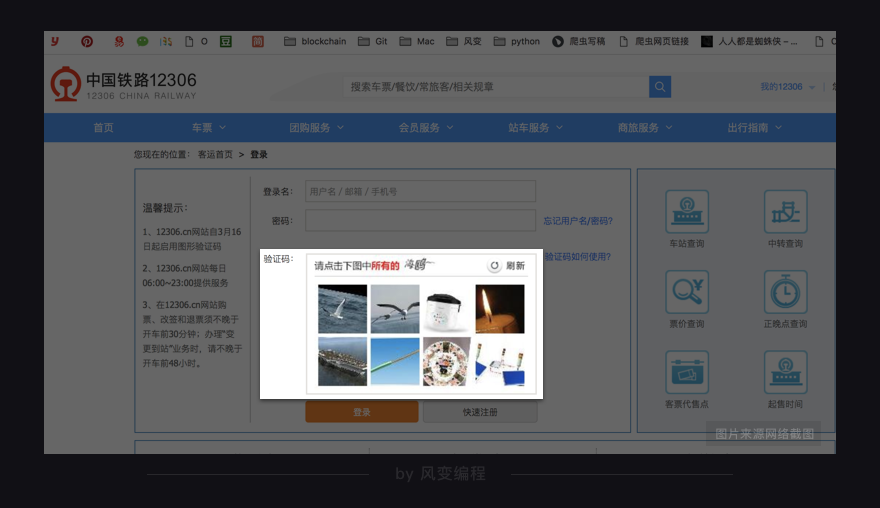
有的网站登录很复杂,验证码难以破解,比如大名鼎鼎的12306。
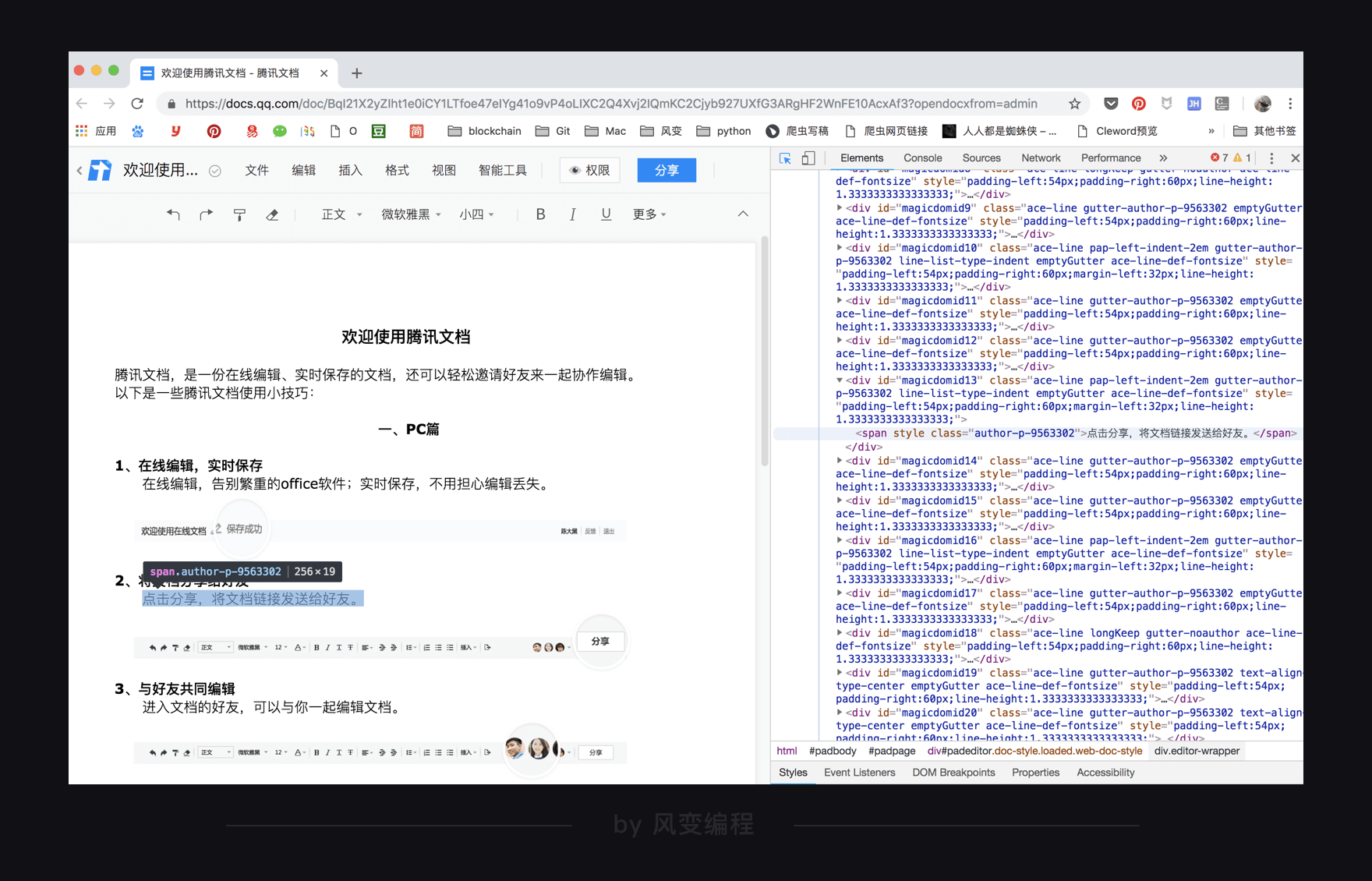
有的网站页面交互复杂,所使用的技术难以被爬取,比如,腾讯文档。
还有的网站,对
URL
的加密逻辑很复杂,比如,第4关爬过的QQ音乐歌曲评论,URL的参数变量找起来挺费劲的。
以上这些情况,想要攻破这些网站的反爬虫技术会有一些难度。
不过,你也不用担心,在本关,我将为你传授一个终极武器——
selenium
,通过它,可以解决以上所有问题。
1. selenium是什么
selenium
是什么呢?它是一个强大的Python库。
它可以做什么呢?它可以用几行代码,控制浏览器,做出自动打开、输入、点击等操作,就像是有一个真正的用户在操作一样。
来看一小段录屏吧,文字在视频面前会显得苍白。
点击这里
这就是我用
selenium
写的脚本,让浏览器自动打开网页,然后输入文字,点击提交按钮。这里用到的代码我都会在后面讲到。
这里要表扬一个我之前教过的用户,他们公司内网的登录和操作很繁琐,登录之后的操作又机械重复,他学会了
selenium
之后,就去写了一个Python程序。
他每天上班的第一件事,就是打开电脑运行自己写的脚本,让浏览器自动打开公司内网完成登录,那些重复的工作也紧跟着一起完成。而他自己,则是坐在那里悠闲地喝茶。
selenium
能控制浏览器,这对解决我们刚刚提出的那几个问题,有什么帮助呢?
首先,当你遇到验证码很复杂的网站时,
selenium
允许让人去手动输入验证码,然后把剩下的操作交给机器。
而对于那些交互复杂、加密复杂的网站,
selenium
问题简化,爬动态网页如爬静态网页一样简单。
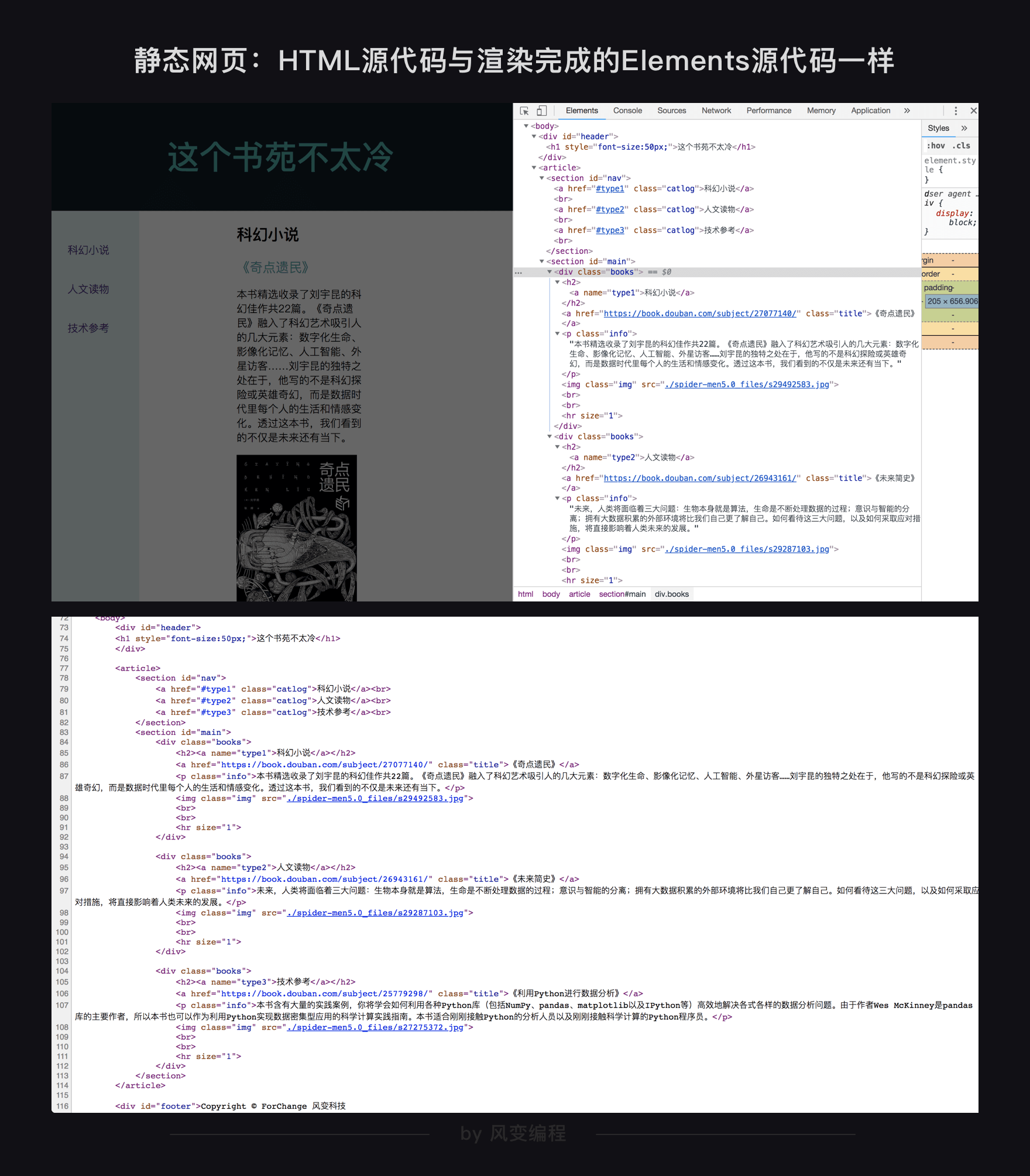
什么是动态网页,什么又是静态网页呢?其实两种网页你都已经接触过了。
第1关教你用
html
写出的网页,就是静态网页。我们使用
BeautifulSoup
爬取这类型网页,因为网页源代码中就包含着网页的所有信息,因此,网页地址栏的
URL
就是网页源代码的
URL
。
后来,你开始接触更复杂的网页,比如QQ音乐,要爬取的数据不在
HTML
源代码中,而是在json中,你就不能直接使用网址栏的
URL
了,而需要找到
json
数据的真实
URL
。这就是一种动态网页。
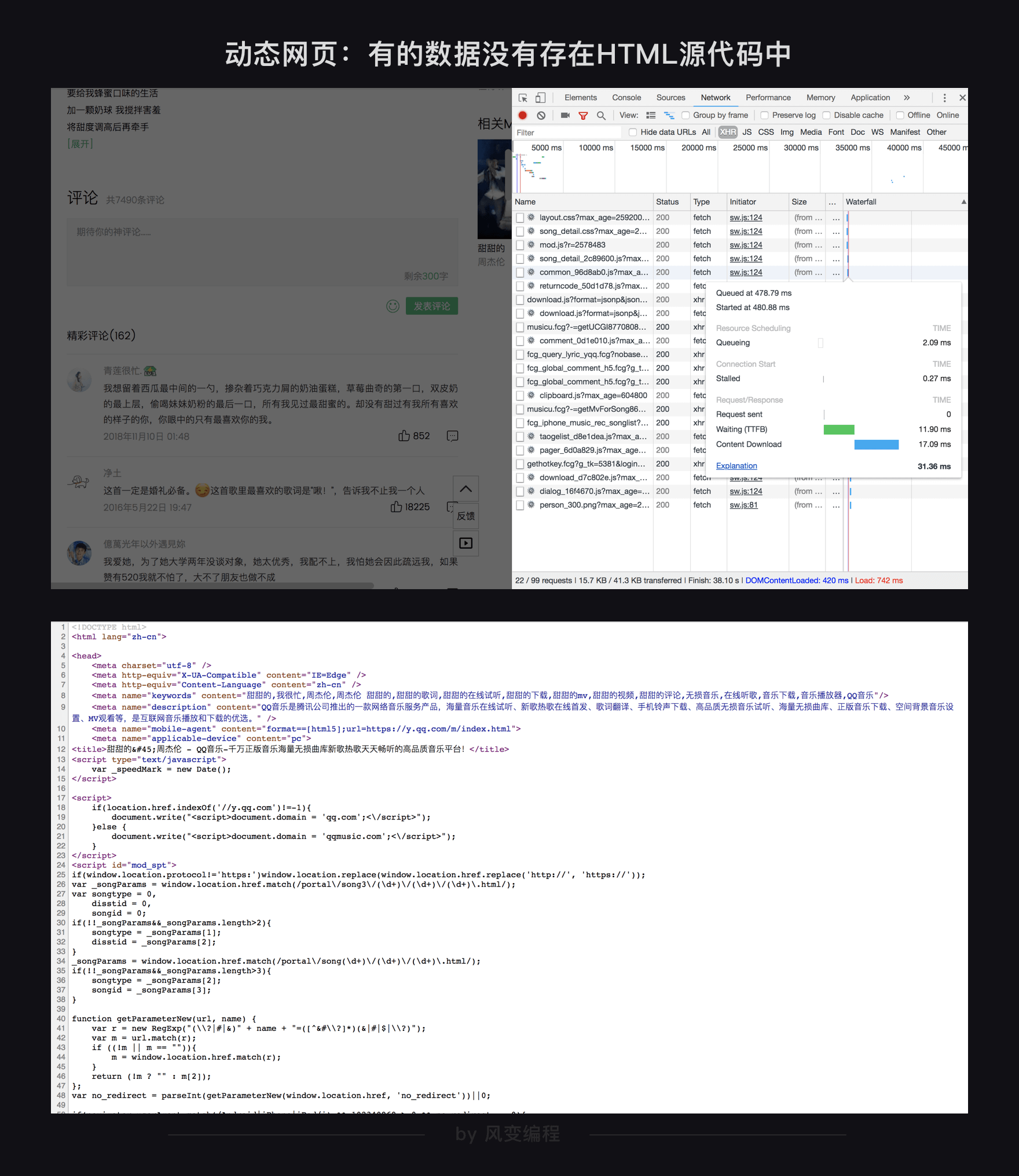
不论数据存在哪里,浏览器总是在向服务器发起各式各样的请求,当这些请求完成后,它们会一起组成开发者工具的
Elements
中所展示的,渲染完成的网页源代码。
点击这里
在遇到页面交互复杂或是
URL
加密逻辑复杂的情况时,
selenium
就派上了用场,它可以真实地打开一个浏览器,等待所有数据都加载到
Elements
中之后,再把这个网页当做静态网页爬取就好了。
说了这么多优点,使用
selenium时
,当然也有美中不足之处。
由于要真实地运行本地浏览器,打开浏览器以及等待网渲染完成需要一些时间,
selenium
的工作不可避免地牺牲了速度和更多资源,不过,至少不会比人慢。
知道了它的优缺点,我们就开始学习如何使用
selenium
吧。
2. 怎么用
首先,和其它所有Python库一样,
selenium
需要安装,方法也很简单, 使用
pip
安装。
pip install selenium # Windows电脑安装selenium
pip3 install selenium # Mac电脑安装selenium
selenium
的脚本可以控制所有常见浏览器的操作,在使用之前,需要安装浏览器的驱动。
我推荐的是Chrome浏览器,打开下面的链接,就可以下载Chrome的安装包了,Windows和Mac都有。
https://localprod.pandateacher.com/python-manuscript/crawler-html/chromedriver/ChromeDriver.html
在正式开始知识的讲解之前,我想首先让你体验一下
selenium
脚本程序在你的本地终端运行的效果。因为在学习
selenium
之初,如果能亲自看到浏览器自动弹出后的操作效果,对你后续的学习会有很大帮助。
下面的代码就是本节课开头动图的代码。你现在不需要去理解具体的意思,等会儿就会学到每一行的用法。
现在只需要把这段代码复制到本地的代码编辑器中运行,体验一下你的浏览器为你自动工作的效果。当然,前提是你已经安装好了
selenium
库以及
Chrome
浏览器驱动。
# 本地Chrome浏览器设置方法
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/')
time.sleep(2)
teacher = driver.find_element_by_id('teacher')
teacher.send_keys('必须是吴枫呀')
assistant = driver.find_element_by_name('assistant')
assistant.send_keys('都喜欢')
time.sleep(1)
button = driver.find_element_by_class_name('sub')
time.sleep(1)
button.click()
time.sleep(1)
driver.close()
除了看程序运行,不如手动打开这个网站看看,做一遍和程序中一样的操作,
URL
给你:
https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
首先引入眼帘的是【你好,蜘蛛侠!】几个大字,一秒之后,它会自动跳转到一个新的页面,请你输入最喜欢的老师和助教,你点击提交之后,它又会跳转到Python之禅的中英对照页面。
仔细看,你会发现,在这个过程中,网页
URL
一直没有变化,可见【你好,蜘蛛侠!】是个动态网页。
体验了
selenium
之后,我们接下来正式开始代码的讲解。
2.1 设置浏览器引擎
和以前一样,使用一个新的Python库,首先要调用它。
selenium
有点不同,除了调用,还需要设置浏览器引擎。
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
以上就是浏览器的设置方式:把Chrome浏览器设置为引擎,然后赋值给变量
driver
。
driver
是实例化的浏览器,在后面你会总是能看到它的影子,这也可以理解,因为我们要控制这个实例化的浏览器为我们做一些事情。
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 对浏览器的设置
driver = RemoteWebDriver("http://chromedriver.python-class-fos.svc:4444/wd/hub", chrome_options.to_capabilities()) # 设置浏览器引擎
配置好了浏览器,就可以开始让它帮我们干活啦!
接下来,我们学习selenium的具体用法,这个部分的知识讲解,都会以你已经见到好几次的,【你好蜘蛛侠!】这个网站为例:
https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
我们还是按照爬虫四步来讲解
selenium
的用法,看看
selenium
如何获取、解析与提取数据。由于本关中提取出的数据都不太复杂,直接在终端打印就好,不会涉及到储存数据这一步。

2.2 获取数据
首先看一下获取数据的代码怎么写吧。
import time
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 打开网页
time.sleep(1)
driver.close() # 关闭浏览器
前面三行代码都是你学过的,调用模块,并且设置浏览器,只有后两行代码是新的。
get(URL)
是
webdriver
的一个方法,它的使命是为你打开指定URL的网页。
刚才说过
driver
在这里是一个实例化的浏览器,因此,就是通过这个浏览器打开网页。
当一个网页被打开,网页中的数据就加载到了浏览器中,也就是说,数据被我们获取到了。
driver.close()
是关闭浏览器驱动,每次调用了
webdriver
之后,都要在用完它之后加上一行
driver.close()
用来关闭它。
就像是,每次打开冰箱门,把东西放进去之后,都要记得关上门,使用
selenium
调用了浏览器之后也要记得关闭浏览器。
把上面的代码复制粘贴在你的本地电脑中运行,你可以看到,一个浏览器自动启动,并为你打开一个网页,停留一秒之后,浏览器关闭。
点击这里
下一步,我们要让浏览器解析并提取数据,然后打印出来,让我们看到返回的运行结果。
2.3 解析与提取数据
我们在前面花两个关卡学习了使用
BeautifulSoup
解析网页源代码,然后提取其中的数据。
selenium
库同样也具备解析数据、提取数据的能力。它和
BeautifulSoup
的底层原理一致,但在一些细节和语法上有所出入。
首先明显的一个不同即是:
selenium
所解析提取的,是
Elements
中的所有数据,而
BeautifulSoup
所解析的则只是
Network
中第0个请求的响应。
本关开头我说过,用
selenium
把网页打开,所有信息就都加载到了
Elements
那里,之后,就可以把动态网页用静态网页的方法爬取了。
selenium
是如何解析与提取数据的呢?我们现在来试试提取【你好蜘蛛侠!】网页中,
<label>
元素的内容吧。
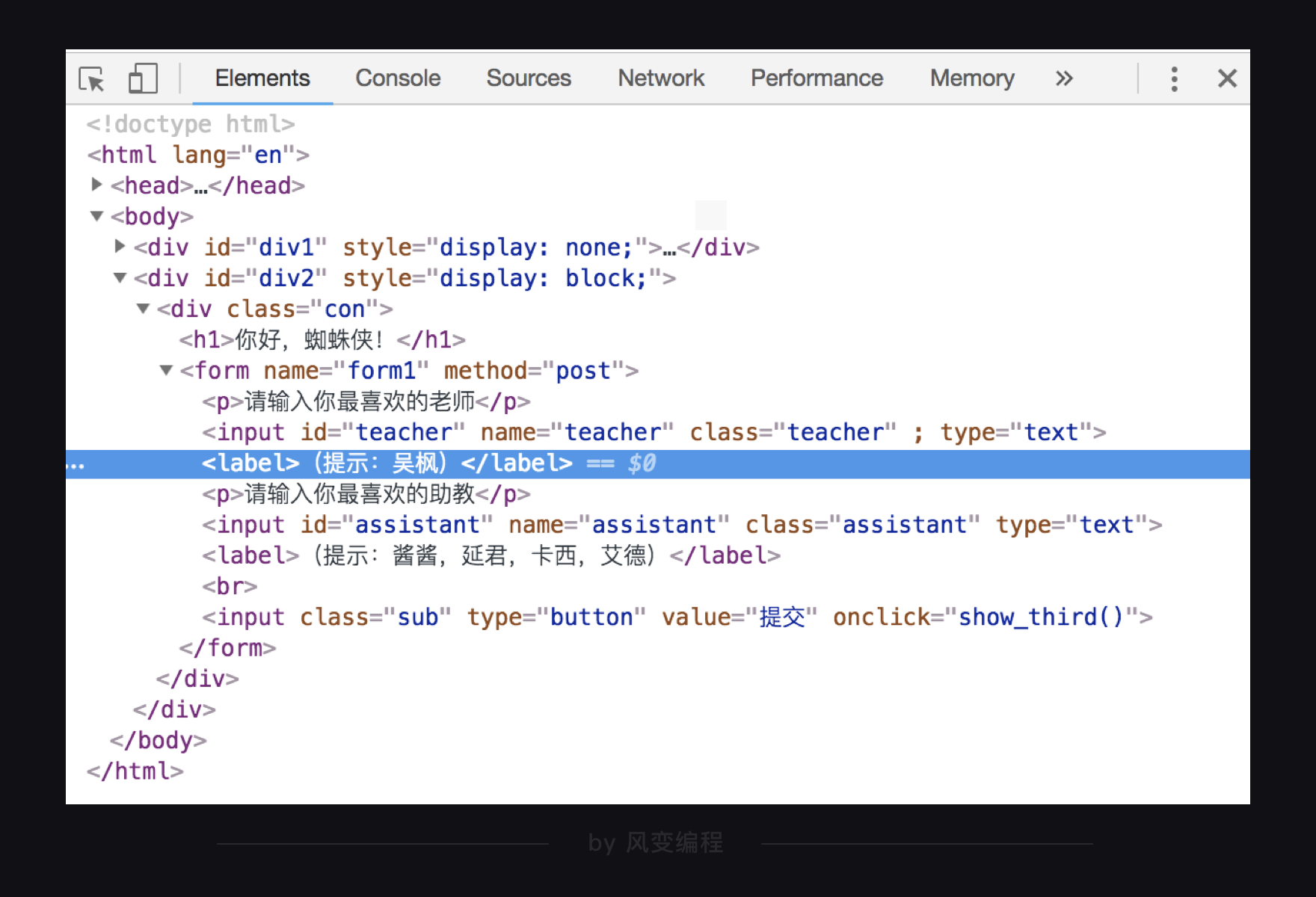
代码我写好了,点击运行看看吧:
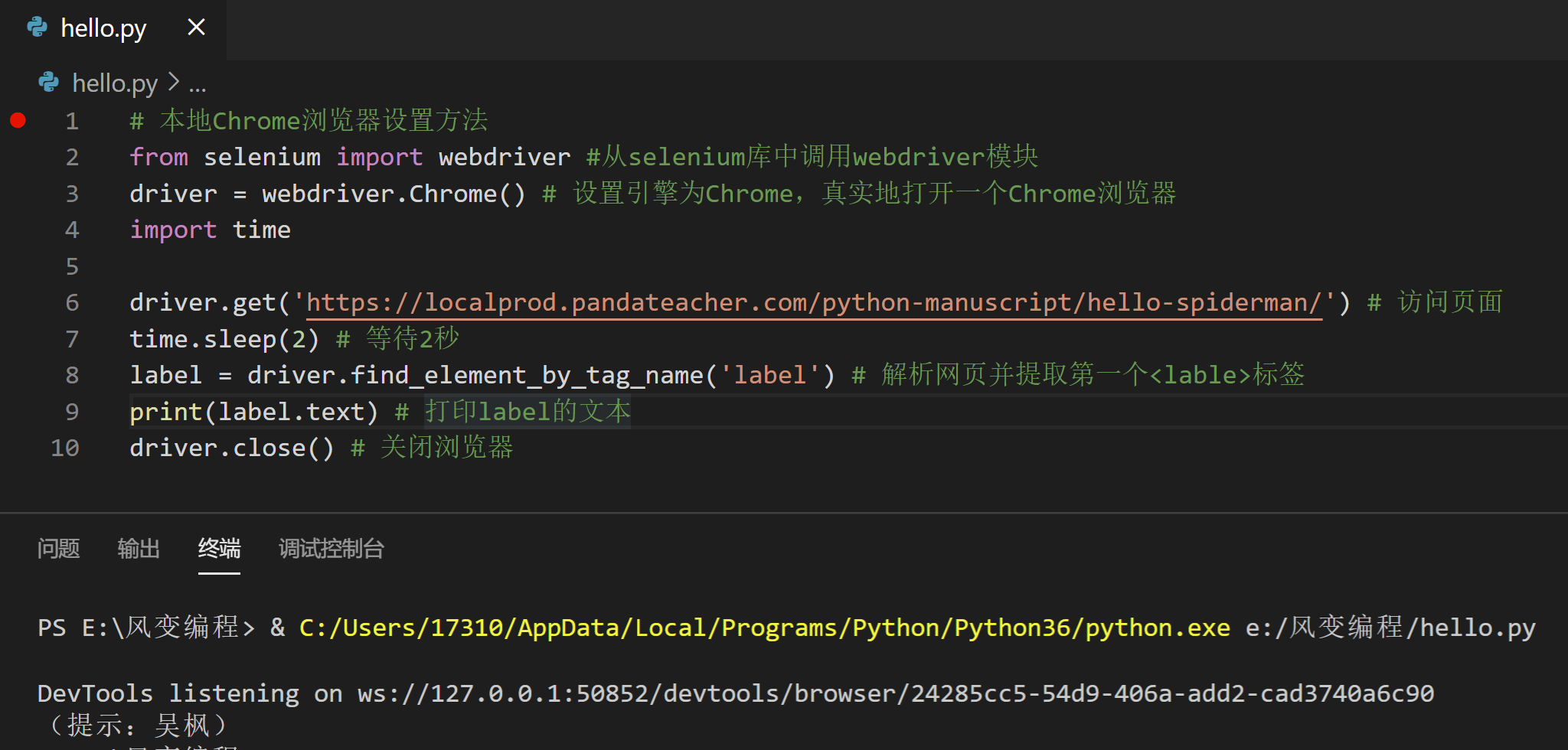
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<lable>标签
print(label.text) # 打印label的文本
driver.close() # 关闭浏览器
从运行结果中可以看到,我们提取出了
<label>(提示:吴枫)</label>
中的文本(
提示:吴枫
)。
上面这段代码只有最后几行代码是新增的,第7行:等待2秒;第8行:然后解析网页并提取网页中第一个
<lable>
标签;第9行:打印label的文本内容。
用
time.sleep(2)
等待两秒,是由于浏览器缓冲加载网页需要耗费一些时间,以及我在这个网页中设置了一秒之后才从首页跳转到输入页面,所以,等待两秒再去解析和提取比较稳妥。
这样来看,解析与提取数据,在这里其实只用了一行代码:
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<lable>标签中的文字
你能否看出,是哪部分在做解析,哪部分在做提取?
先回想下,使用
BeautifulSoup
解析提取数据时,首先要把
Response
对象解析为
BeautifulSoup
对象,然后再从中提取数据。
而在
selenium
中,获取到的网页存在了
driver
中,而后,解析与提取是同时做的,都是由
driver
这个实例化的浏览器完成。
所以,上个问题的答案是:解析数据是由
driver
自动完成的,提取数据是
driver
的一个方法。
清楚了解析与提取的本质,我们接下来详细讲解析数据的方法。
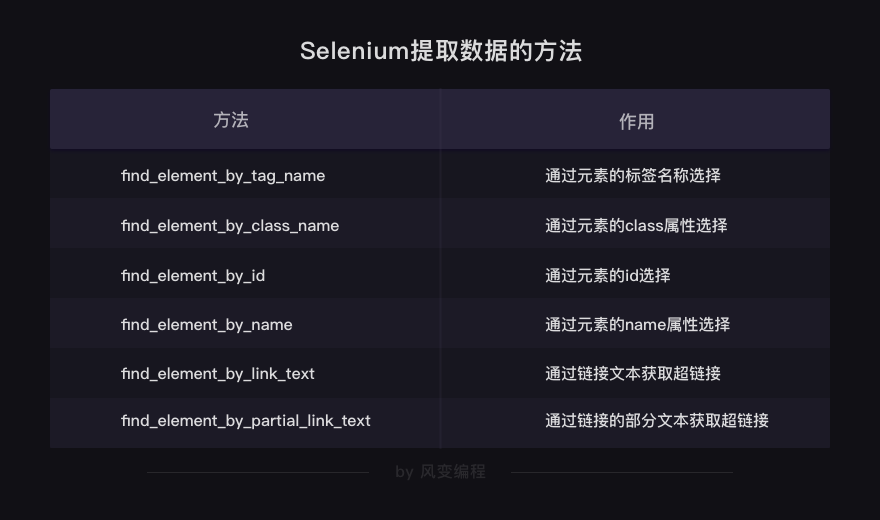
selenium
当然不光能通过标签来提取数据,还有很多查找和提取元素的方法,都是非常直截了当的方法。
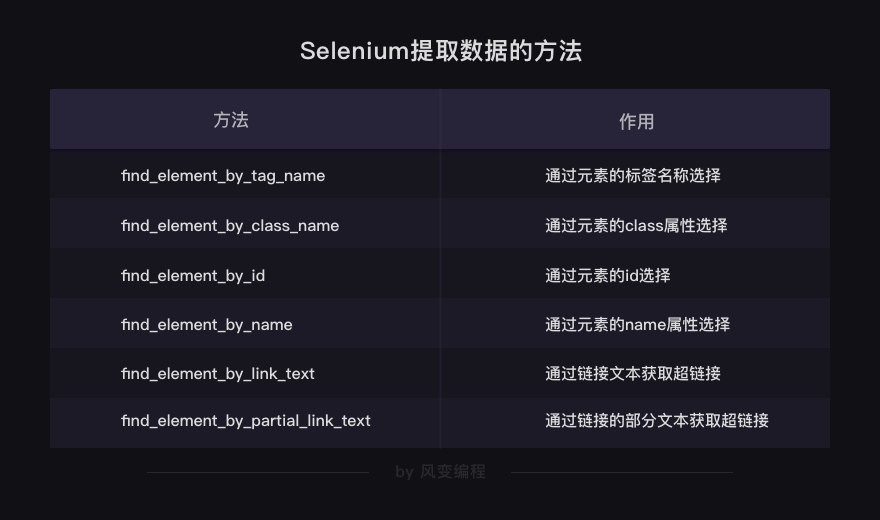
你可以看出,提取数据的方法都是英文直译的意思。举例给你看看它们的用法,请仔细阅读下面代码的注释:

# 以下方法都可以从网页中提取出'你好,蜘蛛侠!'这段文字
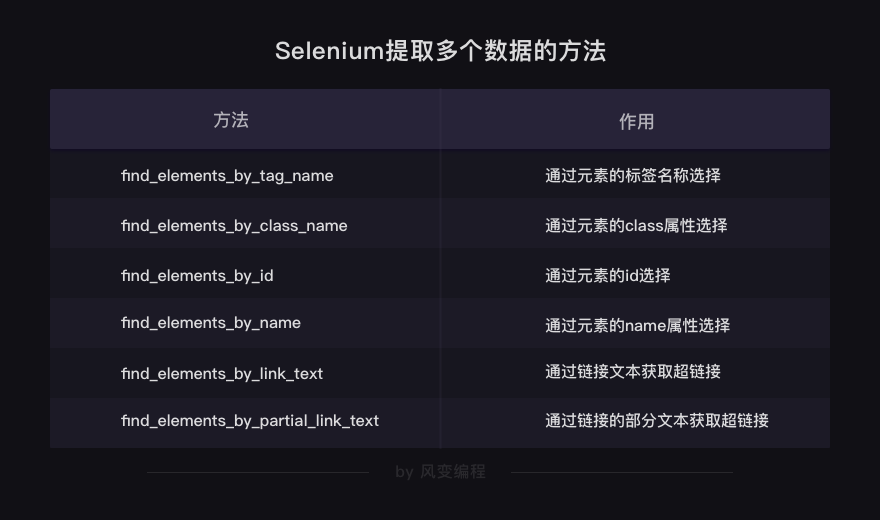
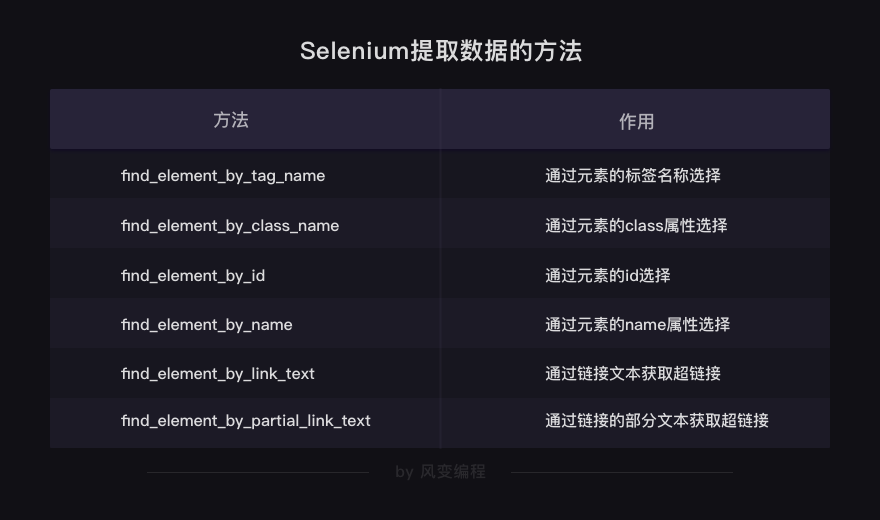
find_element_by_tag_name:通过元素的名称选择
# 如<h1>你好,蜘蛛侠!</h1>
# 可以使用find_element_by_tag_name('h1')
find_element_by_class_name:通过元素的class属性选择
# 如<h1 class="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_class_name('title')
find_element_by_id:通过元素的id选择
# 如<h1 id="title">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_id('title')
find_element_by_name:通过元素的name属性选择
# 如<h1 name="hello">你好,蜘蛛侠!</h1>
# 可以使用find_element_by_name('hello')
#以下两个方法可以提取出超链接
find_element_by_link_text:通过链接文本获取超链接
# 如<a href="spidermen.html">你好,蜘蛛侠!</a>
# 可以使用find_element_by_link_text('你好,蜘蛛侠!')
find_element_by_partial_link_text:通过链接的部分文本获取超链接
# 如<a href="https://localprod.pandateacher.com/python-manuscript/hello-spiderman/">你好,蜘蛛侠!</a>
# 可以使用find_element_by_partial_link_text('你好')
以上就是提取单个元素的方法了。
那么,我们提取出的元素是什么类呢?这种对象有什么属性和方法呢?我们现在就来看看。请阅读下面的代码,然后点击运行:
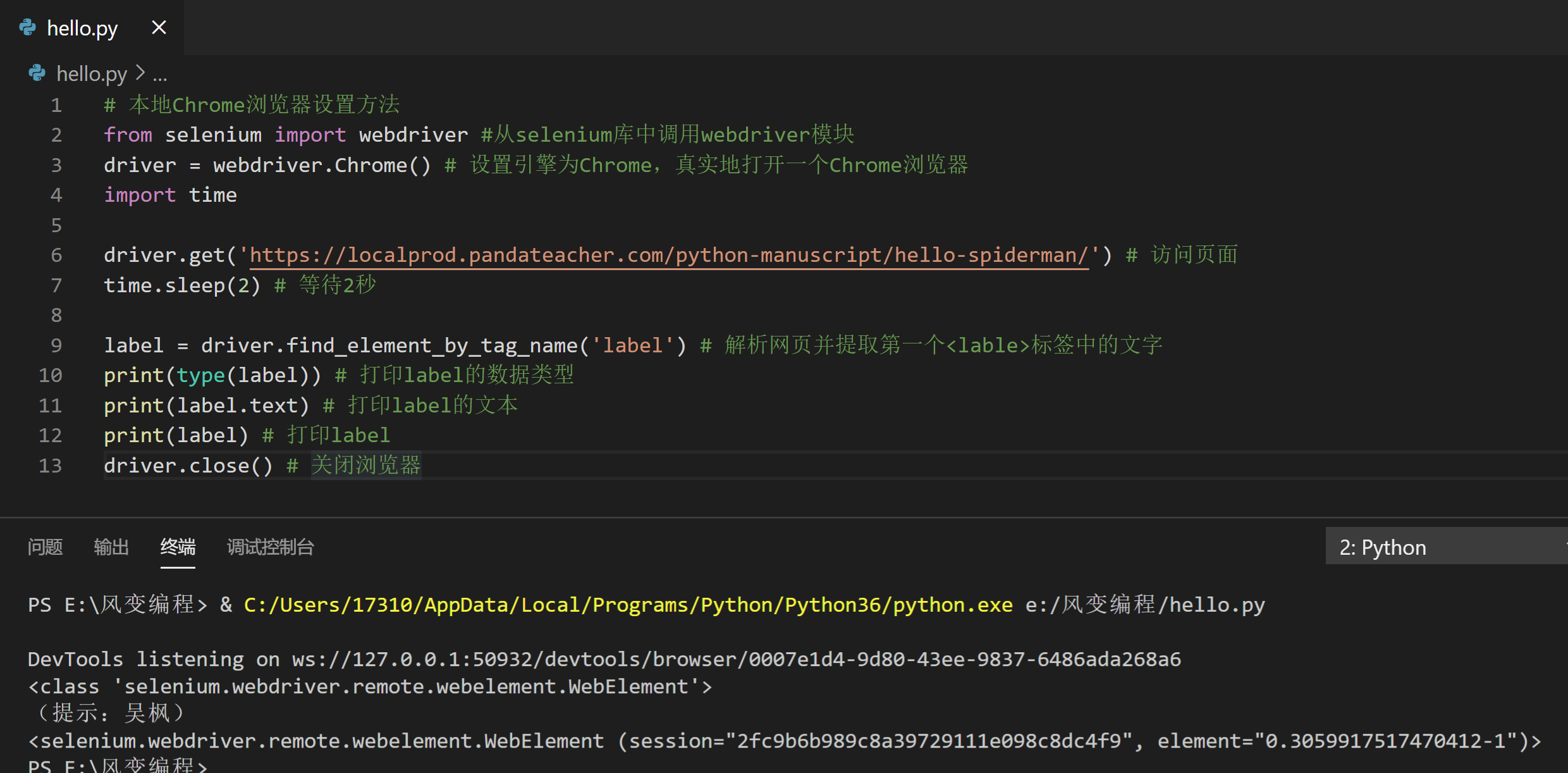
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待2秒
label = driver.find_element_by_tag_name('label') # 解析网页并提取第一个<lable>标签中的文字
print(type(label)) # 打印label的数据类型
print(label.text) # 打印label的文本
print(label) # 打印label
driver.close() # 关闭浏览器
运行结果有3行,分别是:
<class 'selenium.webdriver.remote.webelement.WebElement'>
、
label
的文本(
提示:吴枫
)、以及
label
本身。
可见,提取出的数据属于
WebElement
类对象,如果直接打印它,返回的是一串对它的描述。
而它与
BeautifulSoup
中的
Tag
对象类似,也有一个属性
.text
,可以把提取出的元素用字符串格式显示。
还想补充的是,
WebElement类
对象与
Tag
对象类似,它也有一个方法,可以通过属性名提取属性的值,这个方法是
.get_attribute()
。

我们来举个例子:
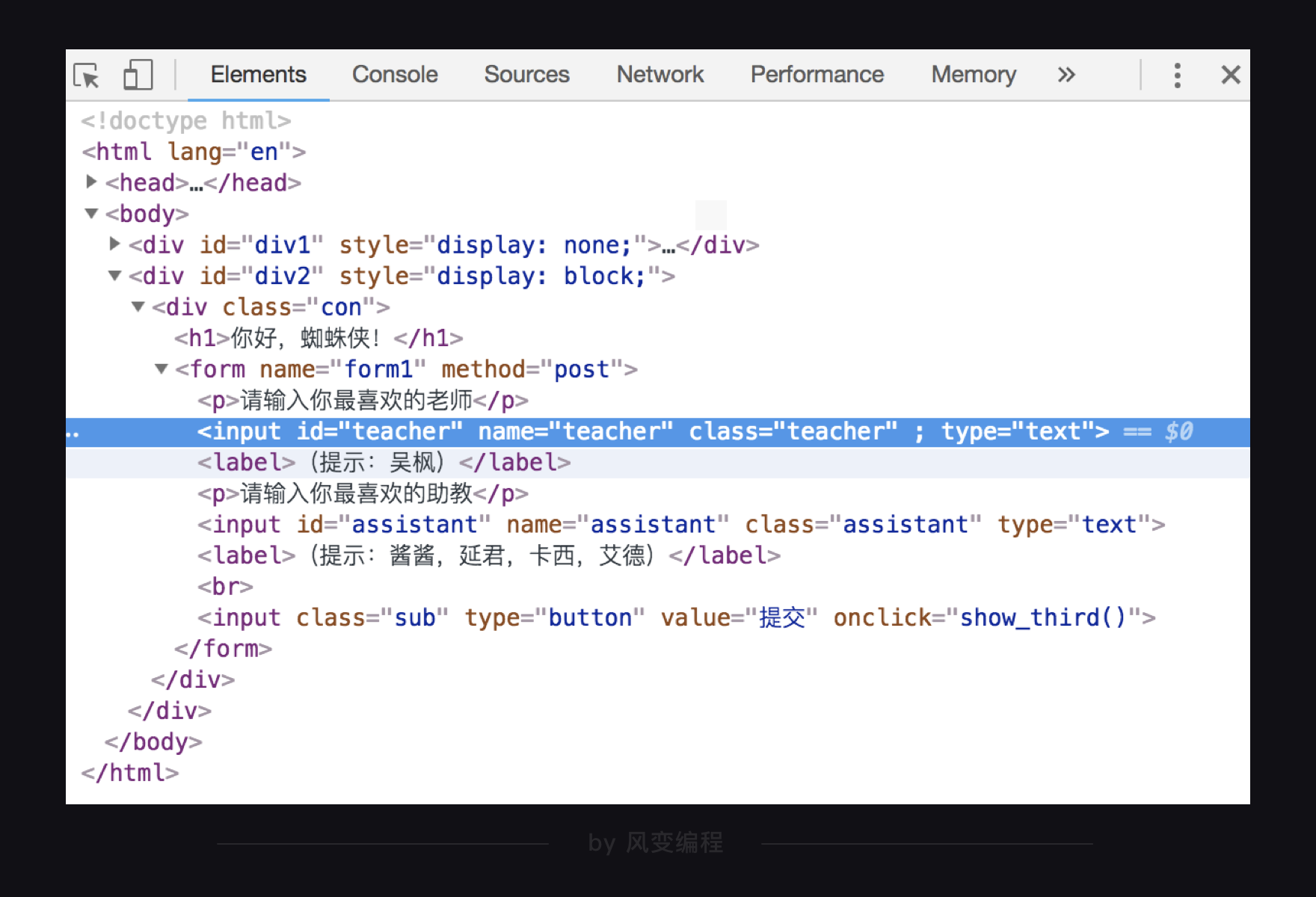
我们试试,通过
class="teacher"
定位到上图中标亮的元素,然后提取出
type
这个属性的值
text
。

# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待两秒
label = driver.find_element_by_class_name('teacher') # 根据类名找到元素
print(type(label)) # 打印label的数据类型
print(label.get_attribute('type')) # 获取type这个属性的值
driver.close() # 关闭浏览器
因此,我们可以总结出,
selenium
解析与提取数据的过程中,我们操作的对象转换:

刚才,我们做的都是提取出网页中的第一个符合要求的数据,接下来,我们就看看提取多个元素的方法吧。
find_element_by_
与
BeautifulSoup
中的
find
类似,可以提取出网页中第一个符合要求的元素;既然
BeautifulSoup
有提取所有元素的方法
find_all
,
selenium
也同样有方法。
方法也一样很简单,把刚才的
element
换成复数
elements
就好了。
我们来试试提取出【你好,蜘蛛侠!】的所有
label
标签中的文字。
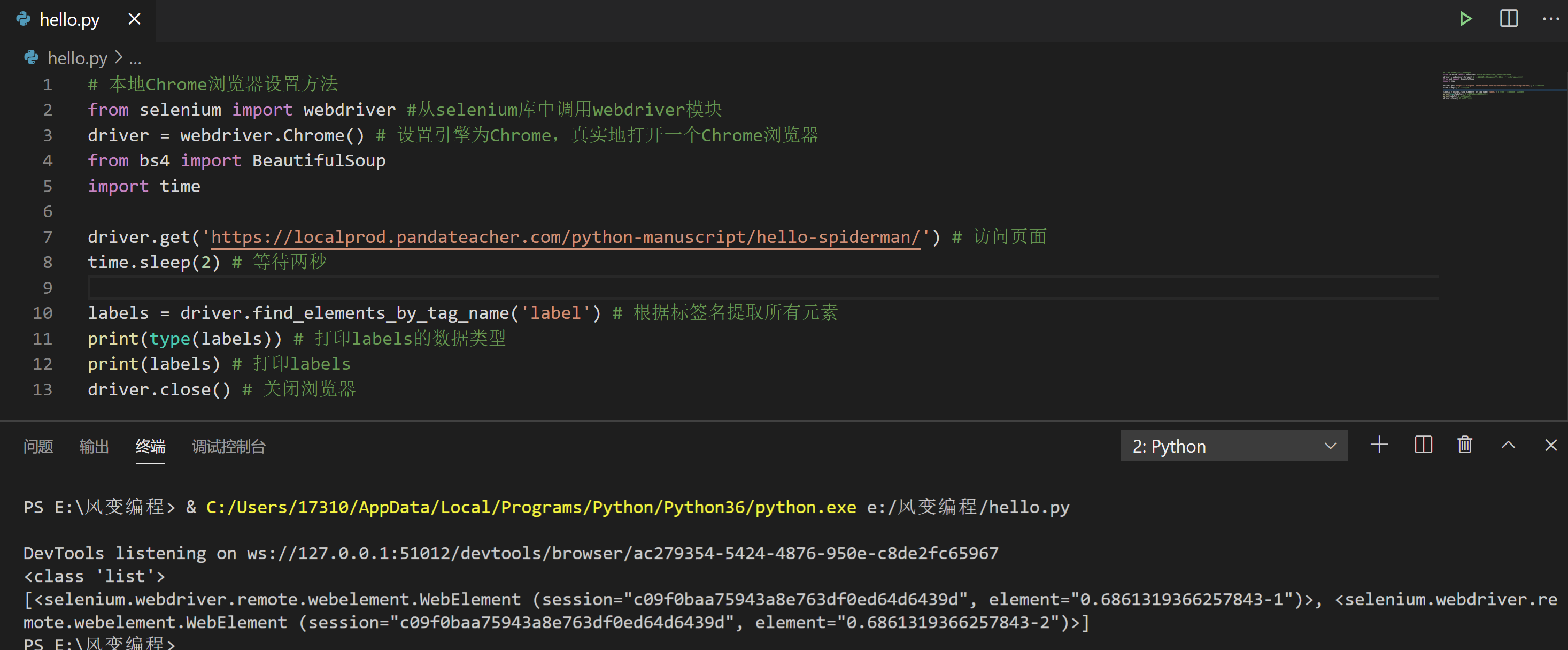
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
from bs4 import BeautifulSoup
import time
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待两秒
labels = driver.find_elements_by_tag_name('label') # 根据标签名提取所有元素
print(type(labels)) # 打印labels的数据类型
print(labels) # 打印labels
driver.close() # 关闭浏览器
从运行结果可以看到,提取出的是一个列表,
<class 'list'>
。而列表的内容就是
WebElements
对象,这些符号是对象的描述,我们刚才学过,需要用
.text
才能返回它的文本内容。
既然得到了列表,就可以和
find_all
返回的结果类似,同样用
for
循环遍历列表就可以提取出列表中的每一个值了。
那么,请你写一下这个代码吧:
提取出网页
你好,蜘蛛侠!
中,所有
label
标签中的文字。
URL: https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
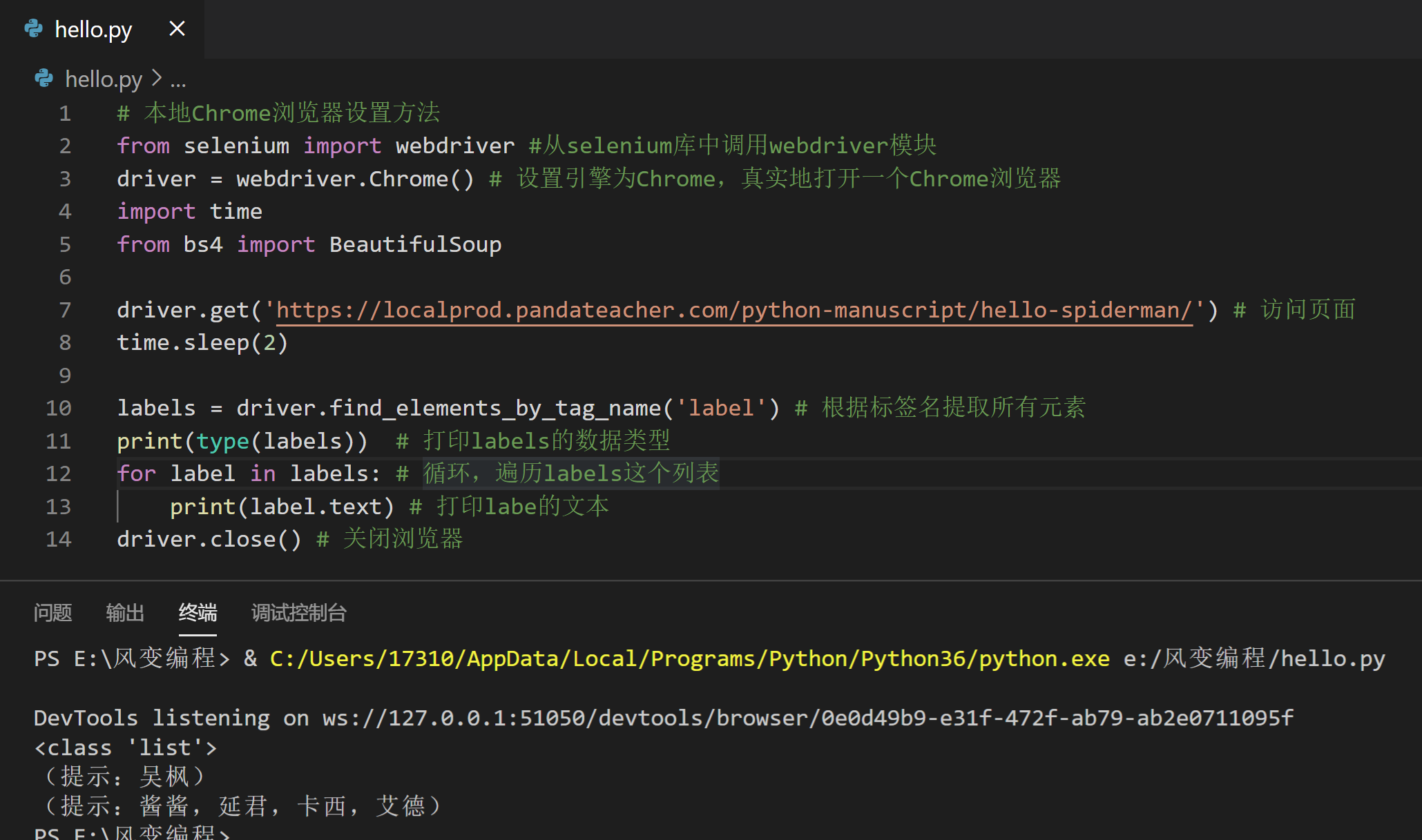
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
from bs4 import BeautifulSoup
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2)
labels = driver.find_elements_by_tag_name('label') # 根据标签名提取所有元素
print(type(labels)) # 打印labels的数据类型
for label in labels: # 循环,遍历labels这个列表
print(label.text) # 打印labe的文本
driver.close() # 关闭浏览器
以上就是
selenium
的解析与提取数据的方法了。
除了用
selenium
解析与提取数据,还有一种解决方案,那就是,使用
selenium
获取网页,然后交给
BeautifulSoup
解析和提取。
接下来,我们就看看,
selenium
与
BeautifulSoup
如何快乐地合作。
我们回顾一下
BeautifulSoup
的工作方式吧。

BeautifulSoup
需要把字符串格式的网页源代码解析为
BeautifulSoup
对象,然后再从中提取数据。
selenium
刚好可以获取到渲染完整的网页源代码。
如何获取呢?也是使用
driver
的一个方法:
page_source
。
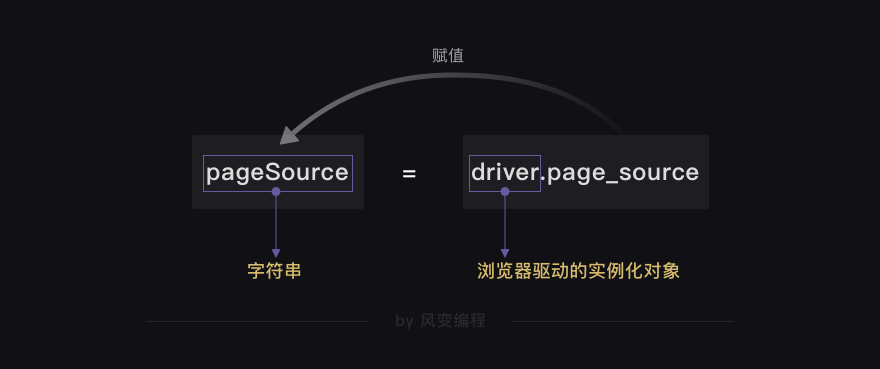
HTML源代码字符串 = driver.page_source
我们现在就来实操一下,获取【你好,蜘蛛侠!】的网页源代码:
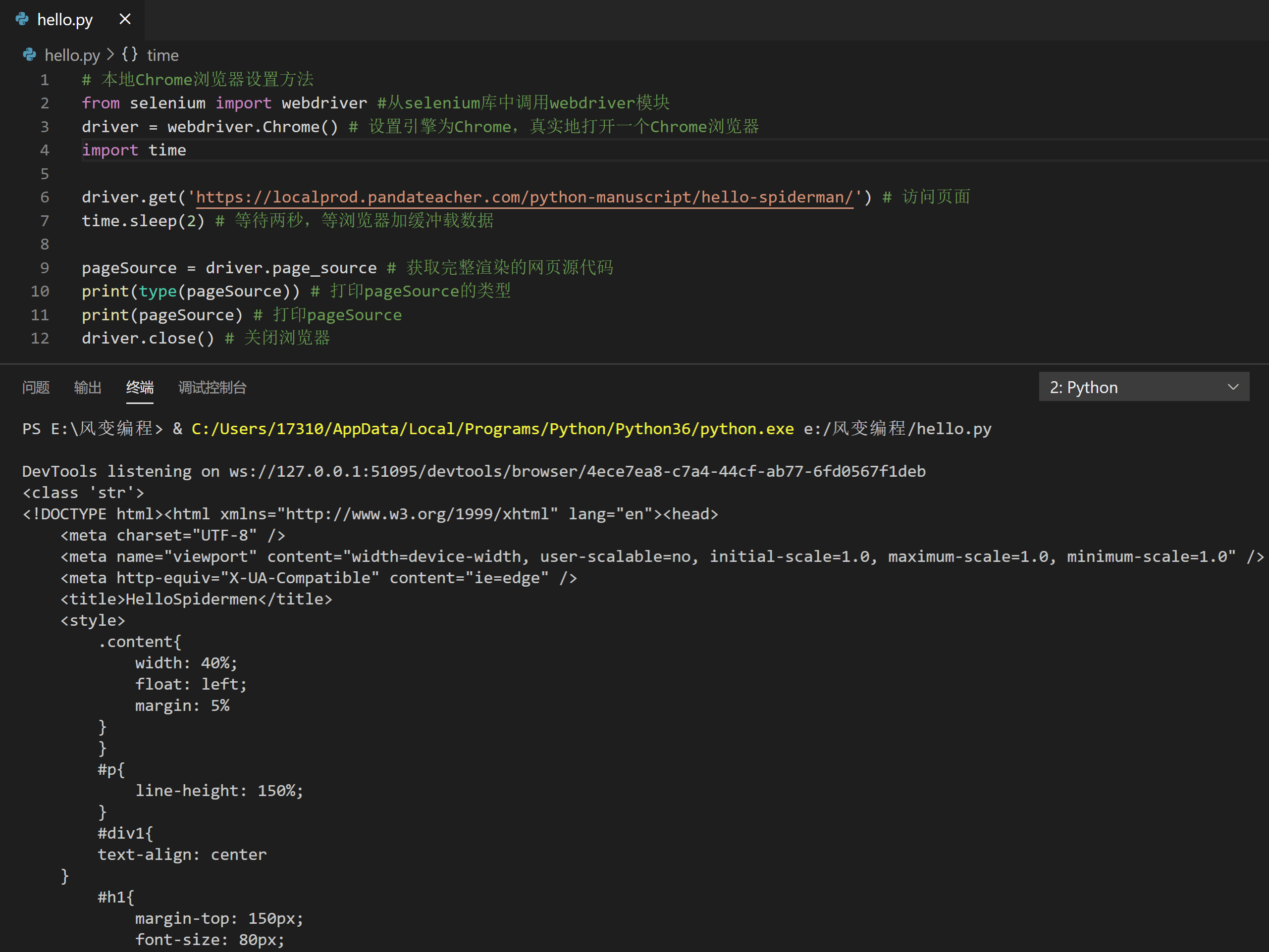
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 等待两秒,等浏览器加缓冲载数据
pageSource = driver.page_source # 获取完整渲染的网页源代码
print(type(pageSource)) # 打印pageSource的类型
print(pageSource) # 打印pageSource
driver.close() # 关闭浏览器
跟我抄写一遍这段代码吧,设置浏览器的部分我已经帮你写好了:

我们成功获取并打印出了网页源代码O(∩_∩)O~~而且它的数据类型是
<class 'str'>
。
你还记不记得,用
requests.get()
获取到的是
Response
对象,在交给
BeautifulSoup
解析之前,需要用到
.text
的方法才能将
Response
对象的内容以字符串的形式返回。
而使用
selenium
获取到的网页源代码,本身已经是字符串了。
获取到了字符串格式的网页源代码之后,就可以用
BeautifulSoup
解析和提取数据了,这是我留给你的一个课后作业。
到这里,解析与提取数据的方法就讲解完了。
关于
selenium
的用法,还有什么没有讲呢?对!就是我们在本关开头演示的功能,控制浏览器自动输入文本,并且点击提交。
点击这里
网页
URL
再给你一次:
https://localprod.pandateacher.com/python-manuscript/hello-spiderman/
我现在就为你解开这个谜底。
2.4 自动操作浏览器
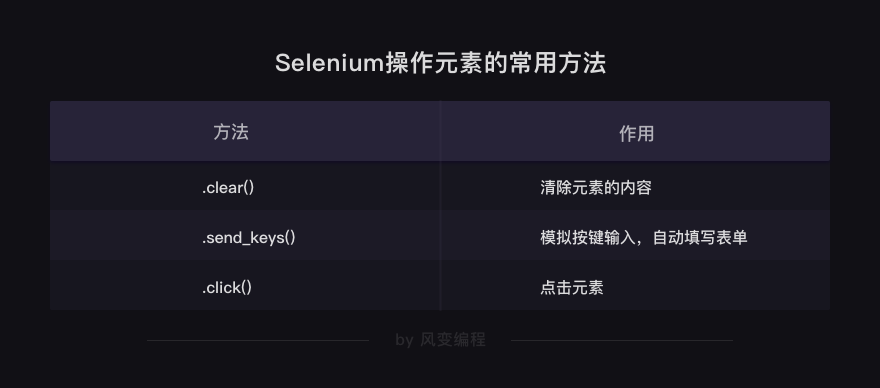
其实,要做到上面动图中显示的效果,你只需要新学两个方法就好了:
.send_keys() # 模拟按键输入,自动填写表单
.click() # 点击元素
用这两行代码,再搭配刚才所讲的解析提取数据的方法,就可以完成操作浏览器的效果了。
学到这里,我们就可以写下全部代码了,这也正是我在开头给你的,让你复制到本地运行过的代码。
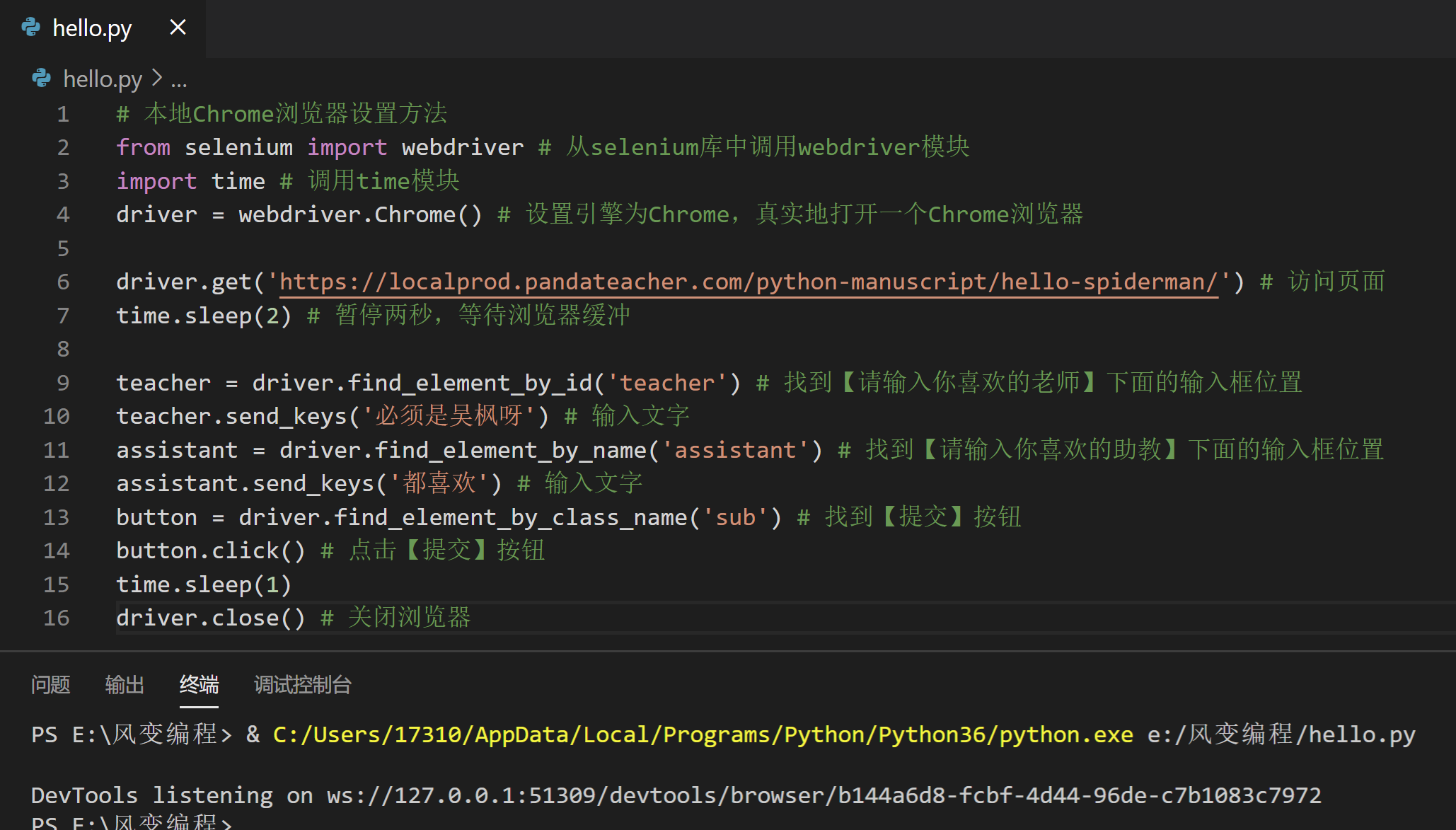
# 本地Chrome浏览器设置方法
from selenium import webdriver # 从selenium库中调用webdriver模块
import time # 调用time模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 暂停两秒,等待浏览器缓冲
teacher = driver.find_element_by_id('teacher') # 找到【请输入你喜欢的老师】下面的输入框位置
teacher.send_keys('必须是吴枫呀') # 输入文字
assistant = driver.find_element_by_name('assistant') # 找到【请输入你喜欢的助教】下面的输入框位置
assistant.send_keys('都喜欢') # 输入文字
button = driver.find_element_by_class_name('sub') # 找到【提交】按钮
button.click() # 点击【提交】按钮
time.sleep(1)
driver.close() # 关闭浏览器
重点关注最后的8行代码,这段代码所做的是两次输入以及一次点击的操作,然后等待一秒,关闭浏览器驱动。
跟我抄一遍这个代码作为练习吧!我把它改为了课程系统中的浏览器设置,这部分代码已经为你准备好,你只需要从访问页面的命令开始写就好。
由于这个代码的命令都是控制浏览器做一些操作,因此终端不会返回任何结果。
你在抄写的时候,有没有发现,最后的6行代码是两两对应的,在每一次输入和点击之前,都要先定位到对应的位置,查找定位用的方法就是前面学过的,解析与提取数据的方法。
比如,在输入你喜欢的老师之前,首先要在网页源代码中找到输入框的位置,方法还是我们之前学过的方法,点击开发者工具左上角的小箭头,然后把鼠标放在网页的空格处。
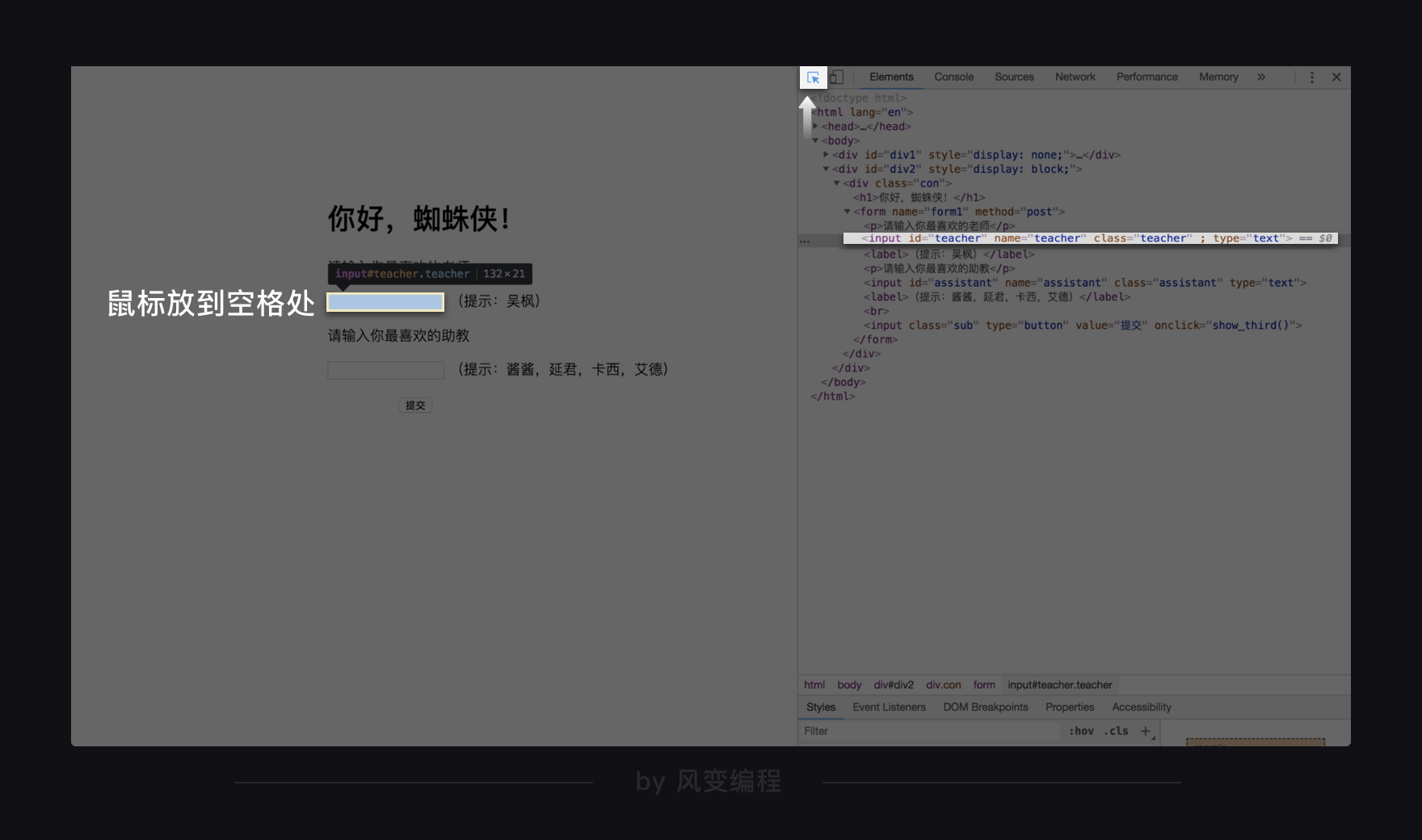
从网页源代码可以看出,可以根据
id="teacher"
,或者
class="teacher"
查找定位到这里。
把提取到的位置信息赋值给
teacher
,然后再用
teacher.send_keys()
的方法输入你想填到这个空里的文本。
这样就完成了一个完整的操作,后面的两个操作,方法都是类似的。由此,整个代码也就写出来了。
还想补充一个小知识,除了输入和点击的两个方法,经常配合它们会用到的,还有一个方法
.clear()
,用于清除元素的内容。
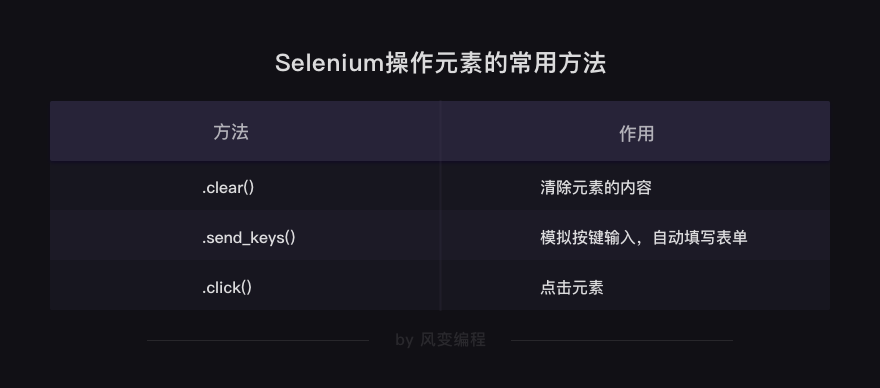
假如,在刚才的空格中,已经输入了【蜘蛛侠】,如果你想改成【吴枫】,就需要先用
.clear()
清除掉【蜘蛛侠】这几个文字,再填写新的文字。
到这里,本关知识讲解的部分就全部完成了,我们接下来一起做一个项目吧~
每次学到新知识,都要及时通过实操练习,巩固所学的知识,这样才能对知识形成更深的理解和记忆。
3. 实操运用
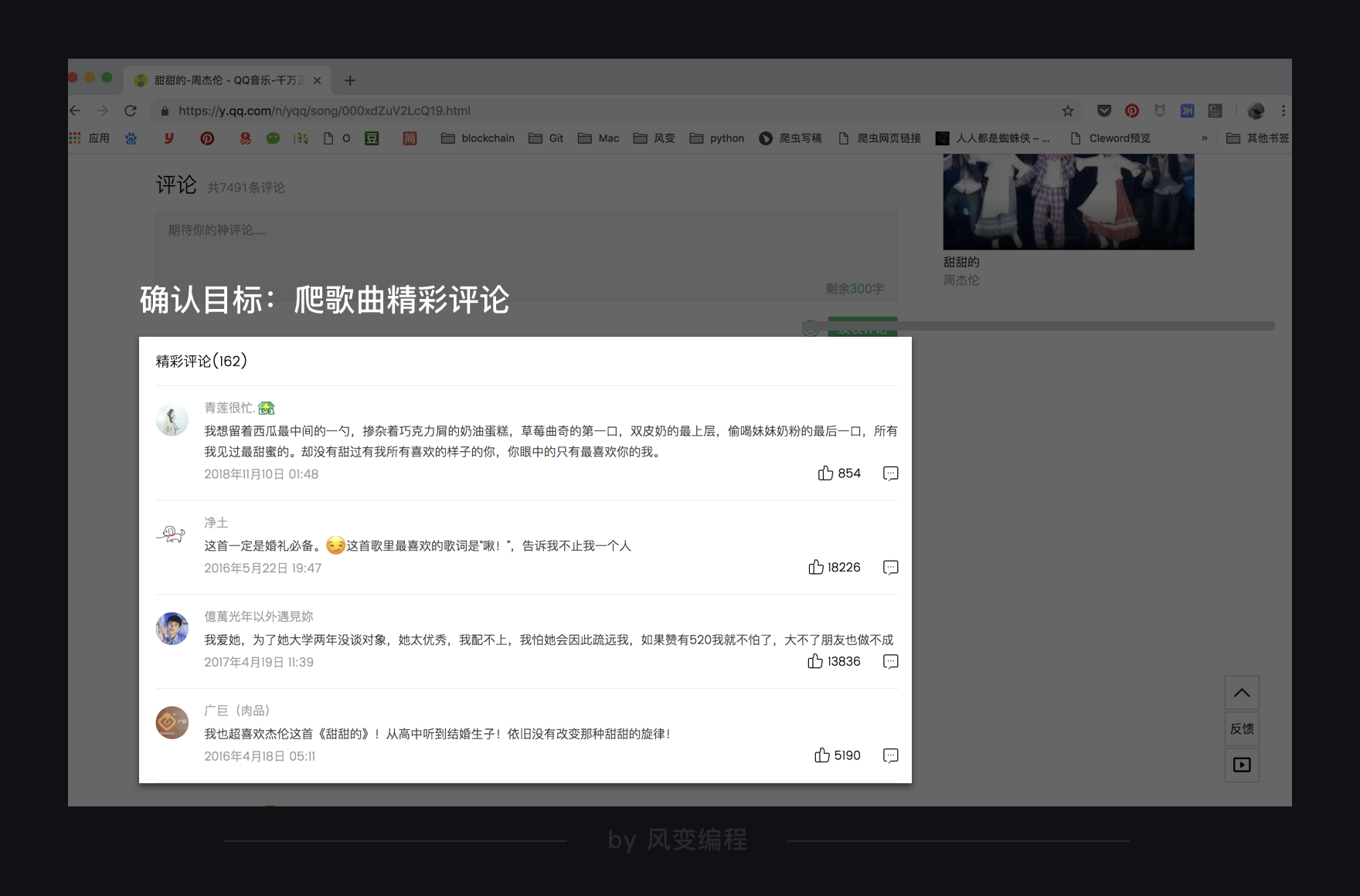
3.1 确认目标
我们这次试试用
selenium
爬取QQ音乐的歌曲评论,我选的歌是《甜甜的》。
https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html
不知道你还有没有印象,在第6关学
json
时,爬过QQ音乐的歌曲最新评论,我们这次来爬精彩评论,两种评论的爬取方法本质是一样的。
现在带你用
selenium
再做一次之前做过的项目,当然不是我偷懒拍脑袋的决定,而是经过了深思熟虑,因为,同一个项目可以做两次,甚至可以做很多次。
使用不同的路径,到达相同的目的,这种学习和训练方法,会帮你把知识搞得更加透彻。
确认了目标,我们就开始行动吧!照旧,在写代码之前,要先分析思路。
3.2 分析过程
依旧按照爬虫的四个步骤来分析。
首先是获取数据:
通过第6关的学习,你已经知道,网页源代码中没有我们想要的评论,而是存在了
Json
中,需要通过查看
XHR
,找到每一页评论的
Json
数据真实URL,才能获取到数据。
我们这次是用
selenium
,就不需要花费精力去查找和破解URL了,因为,通过
selenium
打开浏览器的操作,数据就被加载到
elements
中了。
获取更多的评论的方法,也变得非常简单,直接使用
selenium
控制浏览器点击【点击加载更多】的按钮,评论数据自然就都加载到
elements
中了,简直完美:
点击这里
接下来是解析与提取数据:
第一种解决思路是使用
selenium
提取数据的方法。
第二种解决思路是,先获取到完整网页源代码,然后用
BeautifulSoup
抓取。这两种方法都能完成解析提取的工作。
最后的存储数据这一步我们跳过不做了,直接在终端打印。
梳理清楚了全部过程,就可以开始写!代!码!啦!
3.3 代码实现
首先,调用所有需要的模块,设置好Chrome浏览器引擎,访问网页,获取数据。
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
然后,用selenium的解析提取方法,获取歌曲评论并打印。
需要注意的是,在获取到网页之后,解析与提取之前,要加上time.sleep(2),因为网页的加载需要零点几秒的时间,保险起见,我们等待2秒。
提取数据的时候,首先需要知道数据存在了网页的什么位置,还是老办法,【右键-检查】,把鼠标放在歌曲精彩评论那里,找到
Elements
中对应的位置:
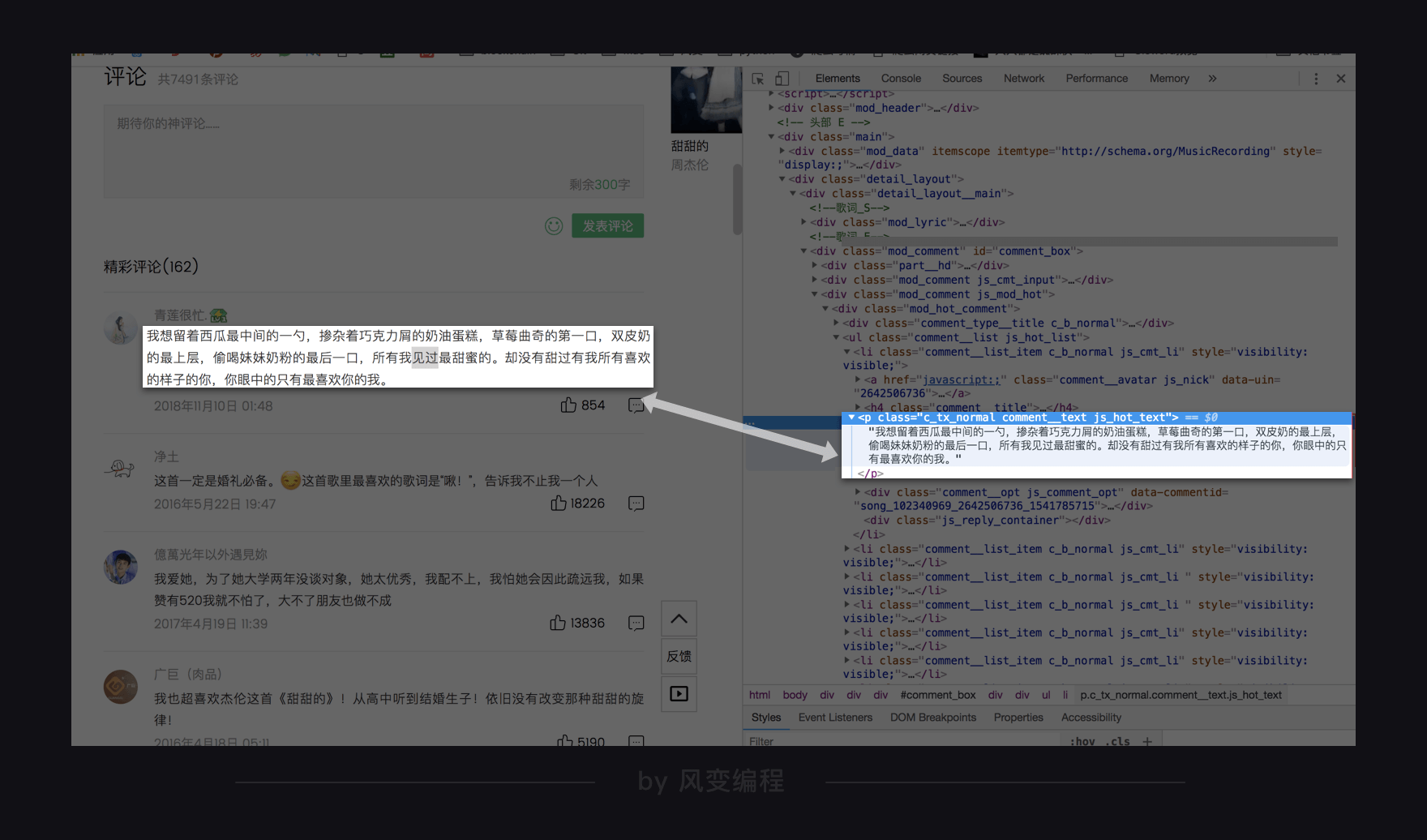
这里要注意的是,这个网页源代码中,评论所在的元素中,class属性就有好多个,而使用selenium时,只能用其中一个属性来提取数据。
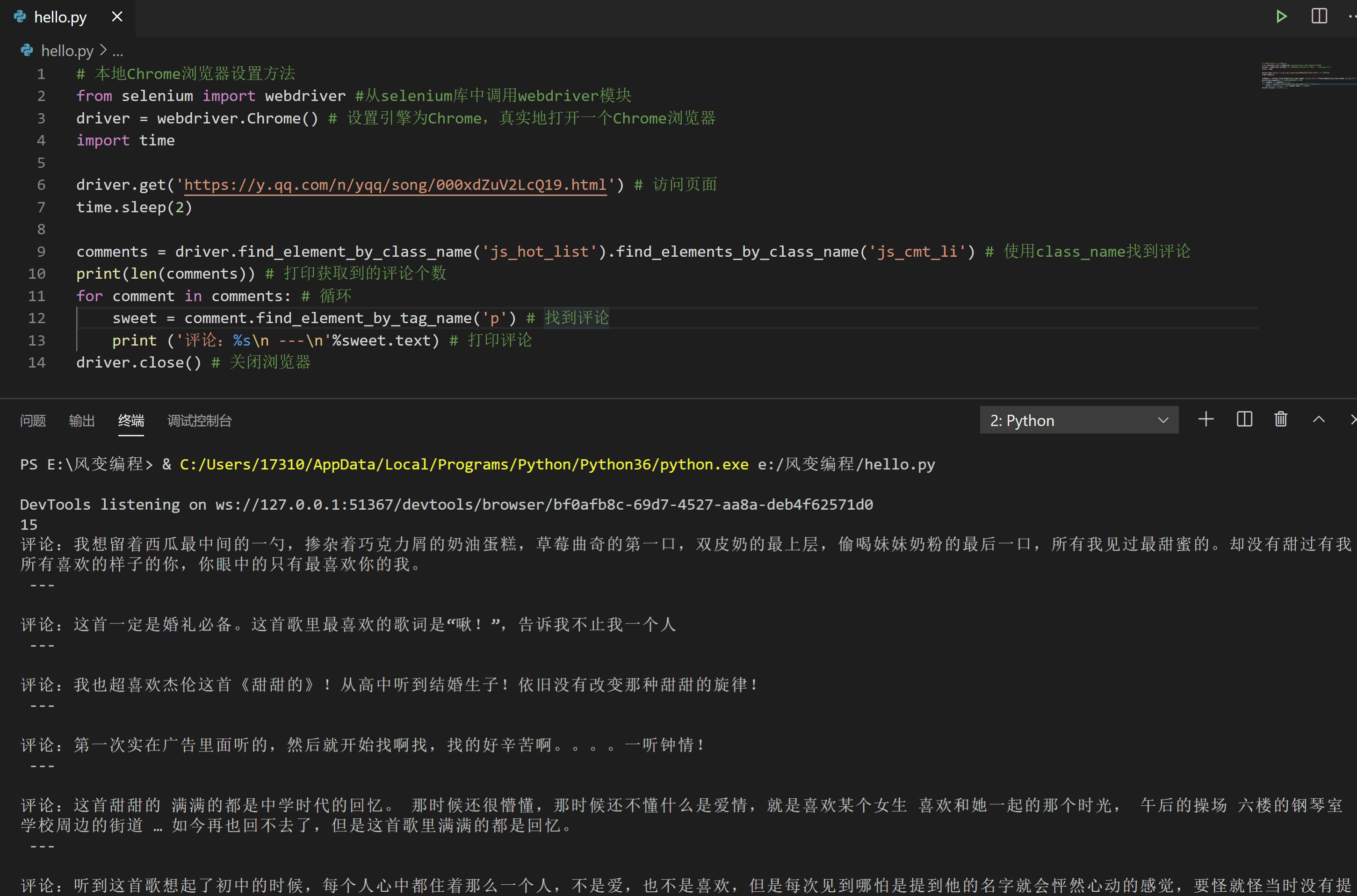
通过分析网页结构,我们选择用class_name与tag_name来提取数据。获取这首歌曲第一页精彩评论的代码就可以写出来了:

# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
time.sleep(2)
comments = driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li') # 使用class_name找到评论
print(len(comments)) # 打印获取到的评论个数
for comment in comments: # 循环
sweet = comment.find_element_by_tag_name('p') # 找到评论
print ('评论:%s\n ---\n'%sweet.text) # 打印评论
driver.close() # 关闭浏览器
这次提取出了15个评论,下一步,我们要获取更多评论。点击网页中的【点击加载更多】,就会加载出新的15个评论的数据。
点击这里
这时候,写代码的方法就很明朗了,首先找到【点击加载更多】在网页源代码中的位置,点击它,等待源代码加载完成之后就可以把全部30个评论提取出来了。

我为你写下了前半部分代码,请你把后面的补全吧:
在QQ音乐中,获取歌曲《甜甜的》30个精彩评论。 URL: https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html
tips:网页默认有15个评论,点击加载更多之后,又会出现15个评论。
我为你写下了前面的代码,请你把后面的部分补全吧。
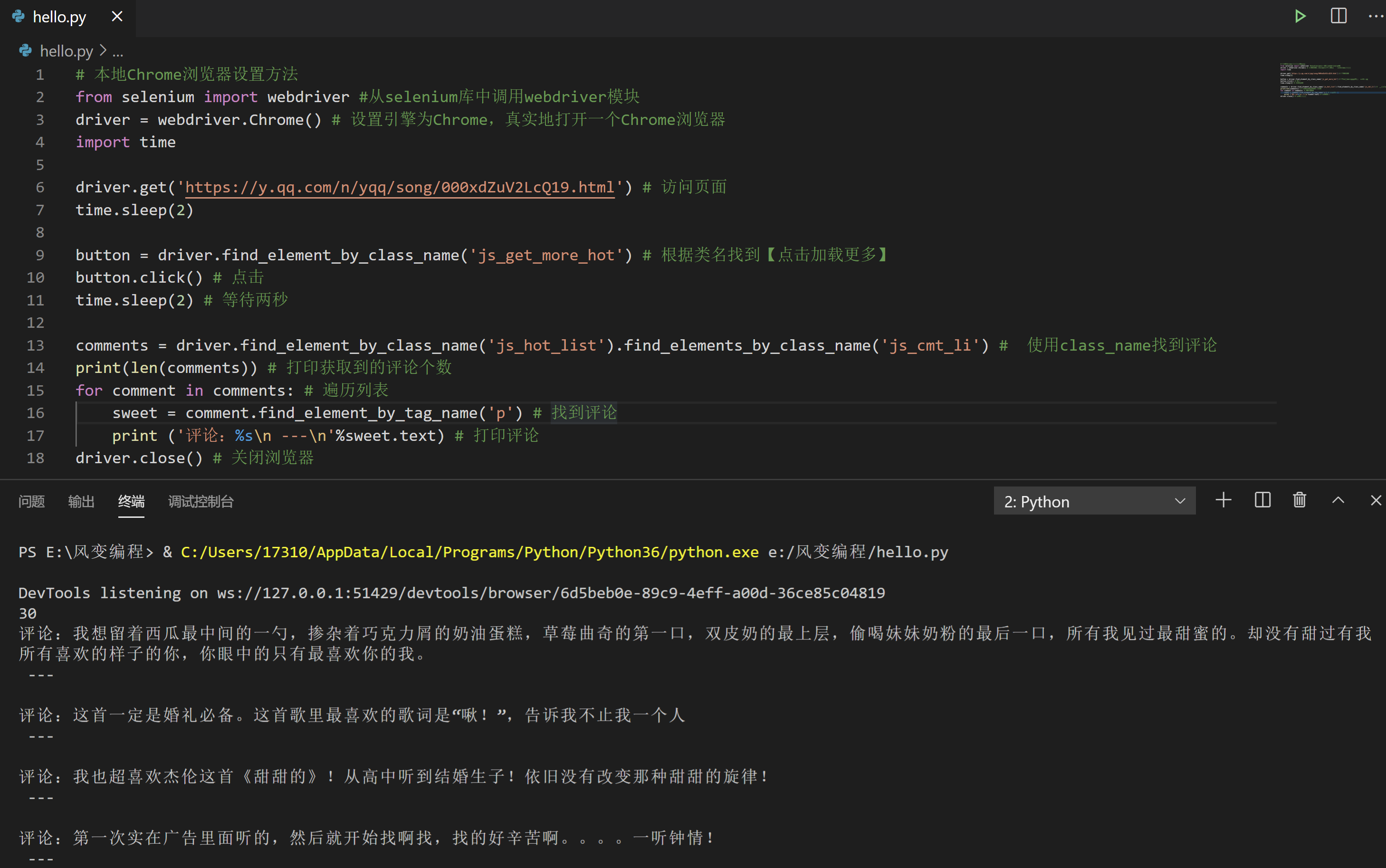
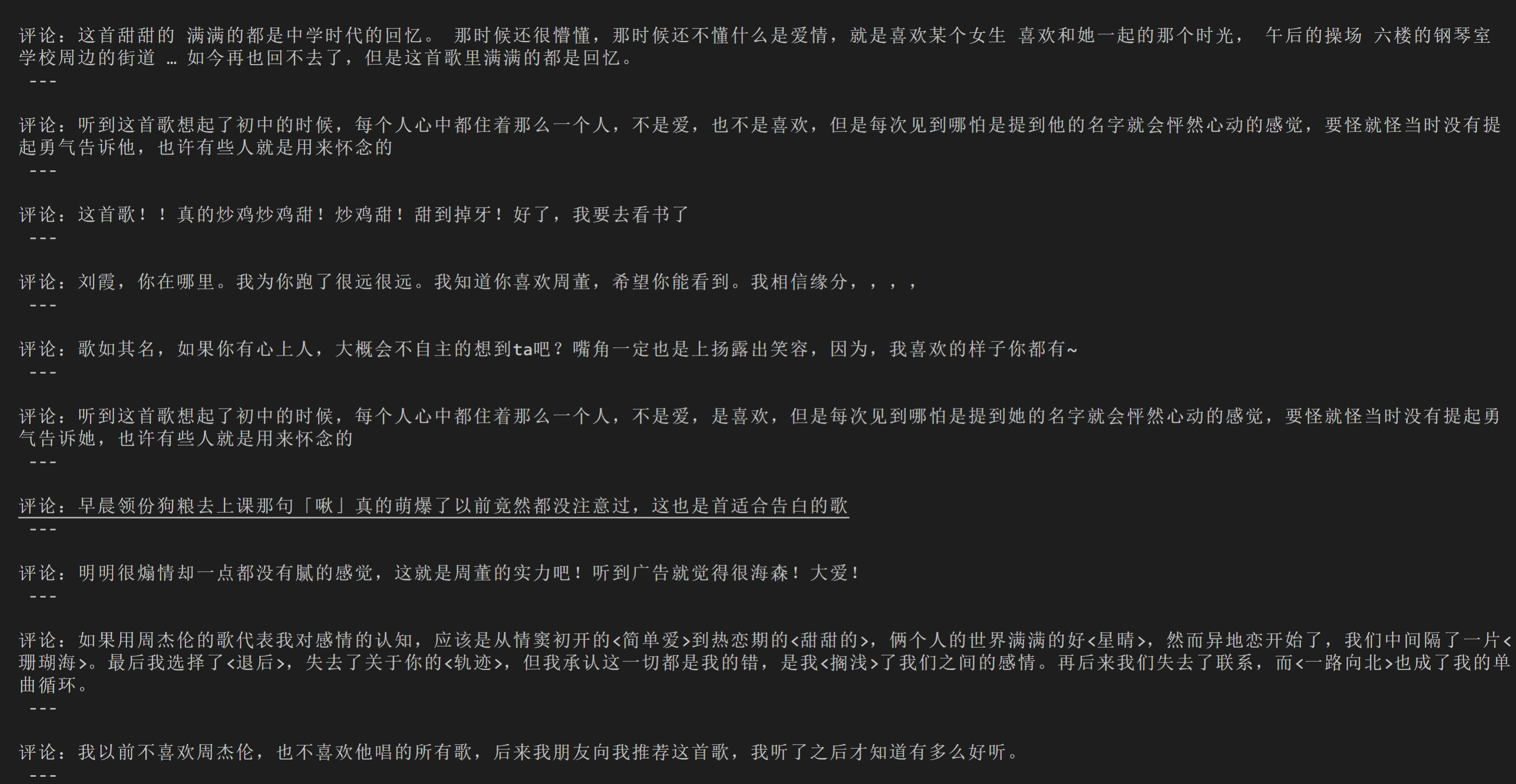
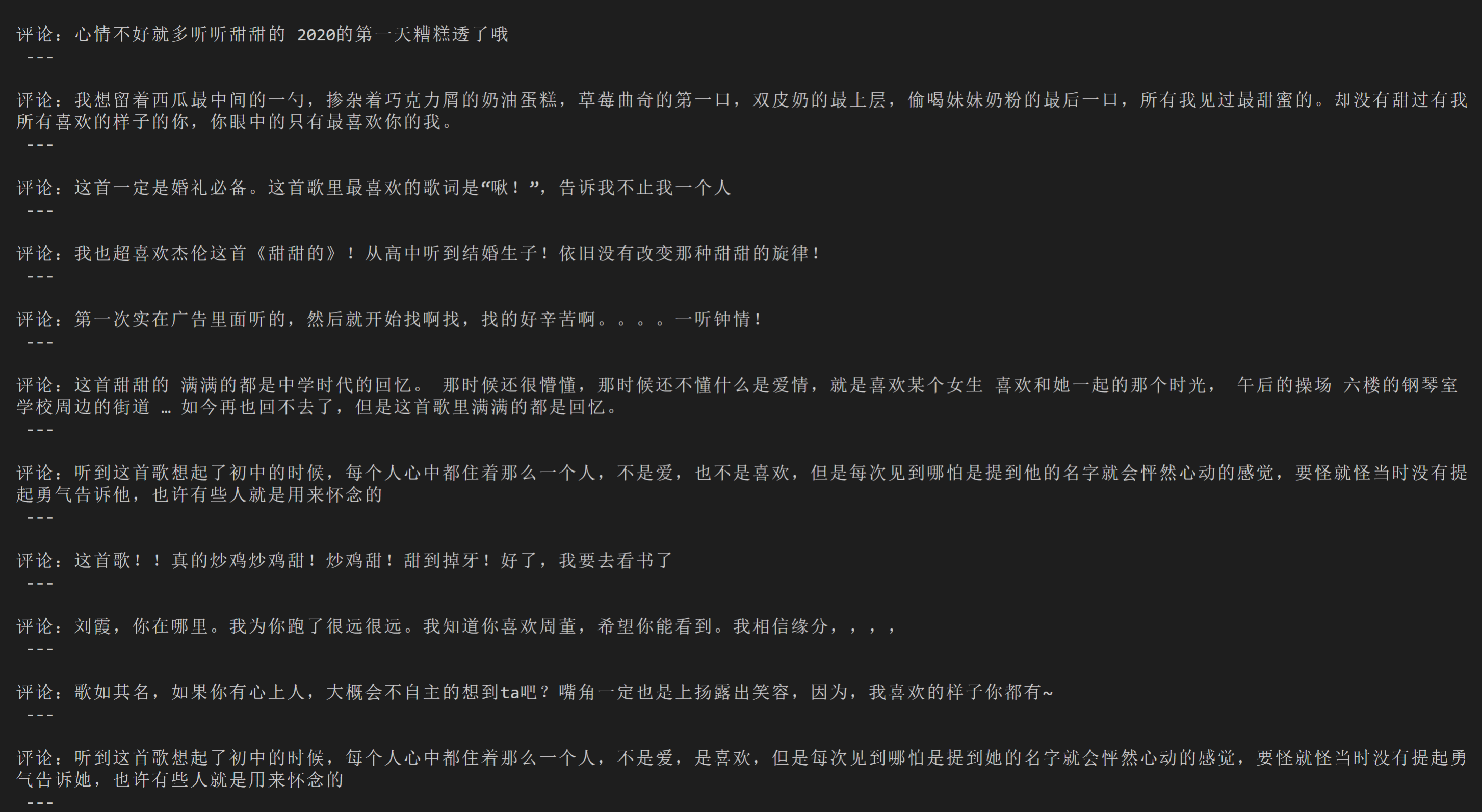
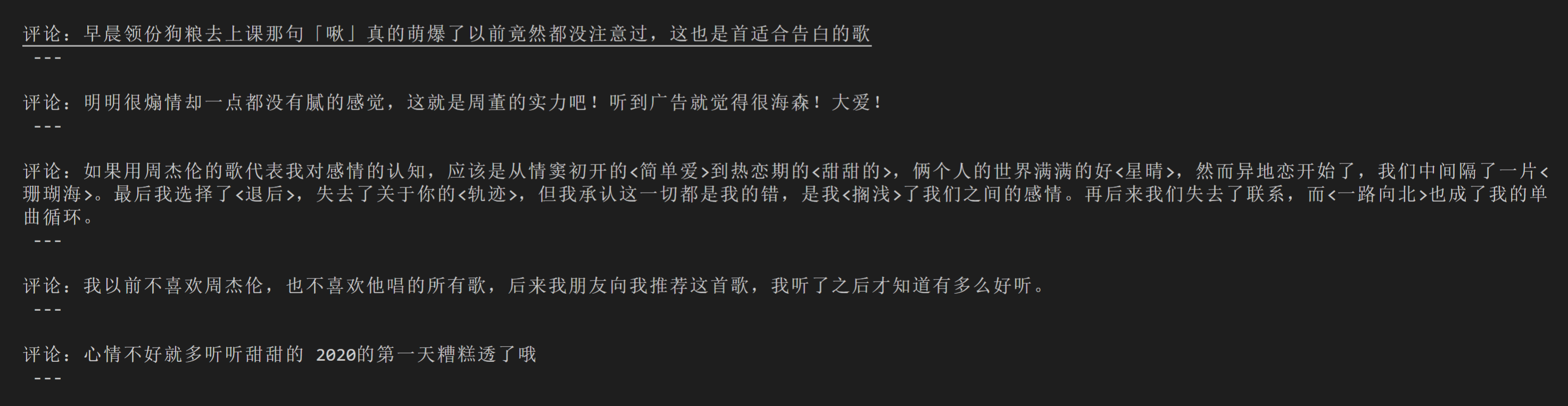
# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
import time
driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
time.sleep(2)
button = driver.find_element_by_class_name('js_get_more_hot') # 根据类名找到【点击加载更多】
button.click() # 点击
time.sleep(2) # 等待两秒
comments = driver.find_element_by_class_name('js_hot_list').find_elements_by_class_name('js_cmt_li') # 使用class_name找到评论
print(len(comments)) # 打印获取到的评论个数
for comment in comments: # 遍历列表
sweet = comment.find_element_by_tag_name('p') # 找到评论
print ('评论:%s\n ---\n'%sweet.text) # 打印评论
driver.close() # 关闭浏览器
成功获取到了两页的评论,掌声给你~

如果你还想获取更多评论,再加上一个循环,和一个条件判断——能否找到点击翻页的选项,就可以实现啦。代码我在这里就不写了,你可以自己在课后练习,练习的目的是学会方法,而没有必要真的把上千条评论全部获取到。
刚才用的是第一种解析与提取的方法,当然还可以使用第二种方法:
selenium
和
BeautifulSoup
结合。
先用
selenium
获取完整的网页源代码,然后使用你已经熟悉的
BeautifulSoup
解析和提取数据。
代码我写好了,和刚才的区别就是最后几行代码:

# 本地Chrome浏览器设置方法
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
from bs4 import BeautifulSoup
import time
driver.get('https://y.qq.com/n/yqq/song/000xdZuV2LcQ19.html') # 访问页面
time.sleep(2)
button = driver.find_element_by_class_name('js_get_more_hot') # 根据类名找到【点击加载更多】
button.click() # 点击
time.sleep(2) # 等待两秒
pageSource = driver.page_source # 获取Elements中渲染完成的网页源代码
soup = BeautifulSoup(pageSource,'html.parser') # 使用bs解析网页
comments = soup.find('ul',class_='js_hot_list').find_all('li',class_='js_cmt_li') # 使用bs提取元素
print(len(comments)) # 打印comments的数量
for comment in comments: # 循环
sweet = comment.find('p') # 提取评论
print ('评论:%s\n ---\n'%sweet.text) # 打印评论
driver.close() # 关闭浏览器 # 关闭浏览器
到这里,代码就全部写完了。
我们用了与第4关不同的方法,完成了相同的项目。而且,在解析与提取数据的时候,也采用了两种方法去实现。
学会了这么多种方法,以后再遇到类似问题,就可以根据实际情况来评估,用哪些方法可以实现,然后挑选其中一种方法去做项目了。
4. 本关总结
感谢努力的你,学完了全部知识,还做了项目,我们现在又到了关卡快要结束的时刻了。
在这一关,我教你安装了
selenium
与Chrome驱动,然后介绍了浏览器的两种设置方法:本地的设置方法与教学系统中的方法。本地的设置方法是这样的:
# 本地Chrome浏览器的可视模式设置:
from selenium import webdriver #从selenium库中调用webdriver模块
driver = webdriver.Chrome() # 设置引擎为Chrome,真实地打开一个Chrome浏览器
这种设置方法可以让你看到浏览器的操作过程。我想在这里补充的是,在本地的操作环境中,你还可以把自己电脑中的Chrome浏览器设置为静默模式,也就是说,让浏览器只是在后台运行,并不在电脑中打开它的可视界面。
因为在做爬虫时,通常不需要打开浏览器,爬虫的目的是爬到数据,而不是观看浏览器的操作过程,在这种情况下,就可以使用浏览器的静默模式,
它的设置方法是这样的:
# 本地Chrome浏览器的静默默模式设置:
from selenium import webdriver #从selenium库中调用webdriver模块
from selenium.webdriver.chrome.options import Options # 从options模块中调用Options类
chrome_options = Options() # 实例化Option对象
chrome_options.add_argument('--headless') # 把Chrome浏览器设置为静默模式
driver = webdriver.Chrome(options = chrome_options) # 设置引擎为Chrome,在后台默默运行
它与教学系统中所采用的浏览器设置方法有些类似,如果你想在本地运行静默模式,就可以这样设置。
与上面浏览器的可视设置相比,5、6、7行代码是新增的,首先调用了一个新的类——
Options
,然后通过它的方法和属性,给浏览器输入了一个参数——
headless
。第7行代码中,把刚才所做的浏览器设置传给了Chrome浏览器。
浏览器的可视模式与静默模式的设置,就是以上四行代码的区别。你懂的,这之后所有代码都是一样的。
嘱咐好了所有要讲给你的知识,那就继续每一关结尾例行的总结吧~
我们刚才学习了使用
selenium
获取数据的方法:
.get('URL')
。
解析与提取数据的方法:
以及在这个过程中,对象的转换过程:

除了上面的方法,
selenium
还可以搭配
BeautifulSoup
解析提取数据,前提是先获取字符串格式的网页源代码。
HTML源代码字符串 = driver.page_source
以及自动操作浏览器的一些方法。
还有,在用完浏览器之后,要记得关闭它,以免资源浪费,在代码的结尾处加一行
driver.close()
就好。
到这里,你应该能感受到,Selenium是一个强大的网络数据采集工具,它的优势是简单直观,而它当然也有缺点。
由于是真实地模拟人操作浏览器,需要等待网页缓冲的时间,在爬取大量数据的时候,速度会比较慢。
通常情况,在爬虫项目中,
selenium
都是用在其它方法无法解决,或是很难解决的问题时,才会用到。
当然,除了爬虫,
selenium
的使用场景还有很多。比如:它可以控制网页中图片文件的显示、控制CSS和JavaScript的加载与执行等等。
我们的课程只是带你入门,讲了一些简单常用的操作,还想进一步学习的话,可以通过selenium的官方文档链,目前只有英文版:
https://seleniumhq.github.io/selenium/docs/api/py/api.html
还可以参考这个中文文档:
https://selenium-python-zh.readthedocs.io/en/latest/
5. 习题练习
5.1 习题一
5.1.1 练习介绍
上一关学cookies的时候,我带你登录了人人都是蜘蛛侠,然后发表了一个评论。
现在又学了selenium,你还可以使用与上一关不同的方式登录博客,并且发表评论。
5.1.2 要求:
首先,手动注册博客注册蜘蛛侠
然后,注册邮箱会收到一份新邮件,邮件含有设置密码的跳转链接,点击链接进行密码设置,别忘了拿出小本本记住密码和账号。
其次,利用代码登录博客人人都是蜘蛛侠。
最后,在文章《未来已来(三)——同九义何汝秀》中,发表一个评论,这个评论中必须要带有“selenium”这个词。
5.1.3 目的:
练习selenium的使用
5.1.4 前期准备(手动):
注册蜘蛛侠注册博客
2.注册邮箱会收到一份新邮件,邮件含有设置密码的跳转链接,点击链接进行
密码设置
,别忘了拿出小本本记住密码和账号。
博客注册页面:
https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php?action=register
博客设置密码页面(注册的邮箱将会收到的密码设置链接的入口邮件):

5.1.5 代码实现:
人人都是蜘蛛侠。登录博客
2.在文章《未来已来(三)——同九义何汝秀》中,发表一个评论,这个评论中必须要带有“selenium”这个词。
博客登录页面:
https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php
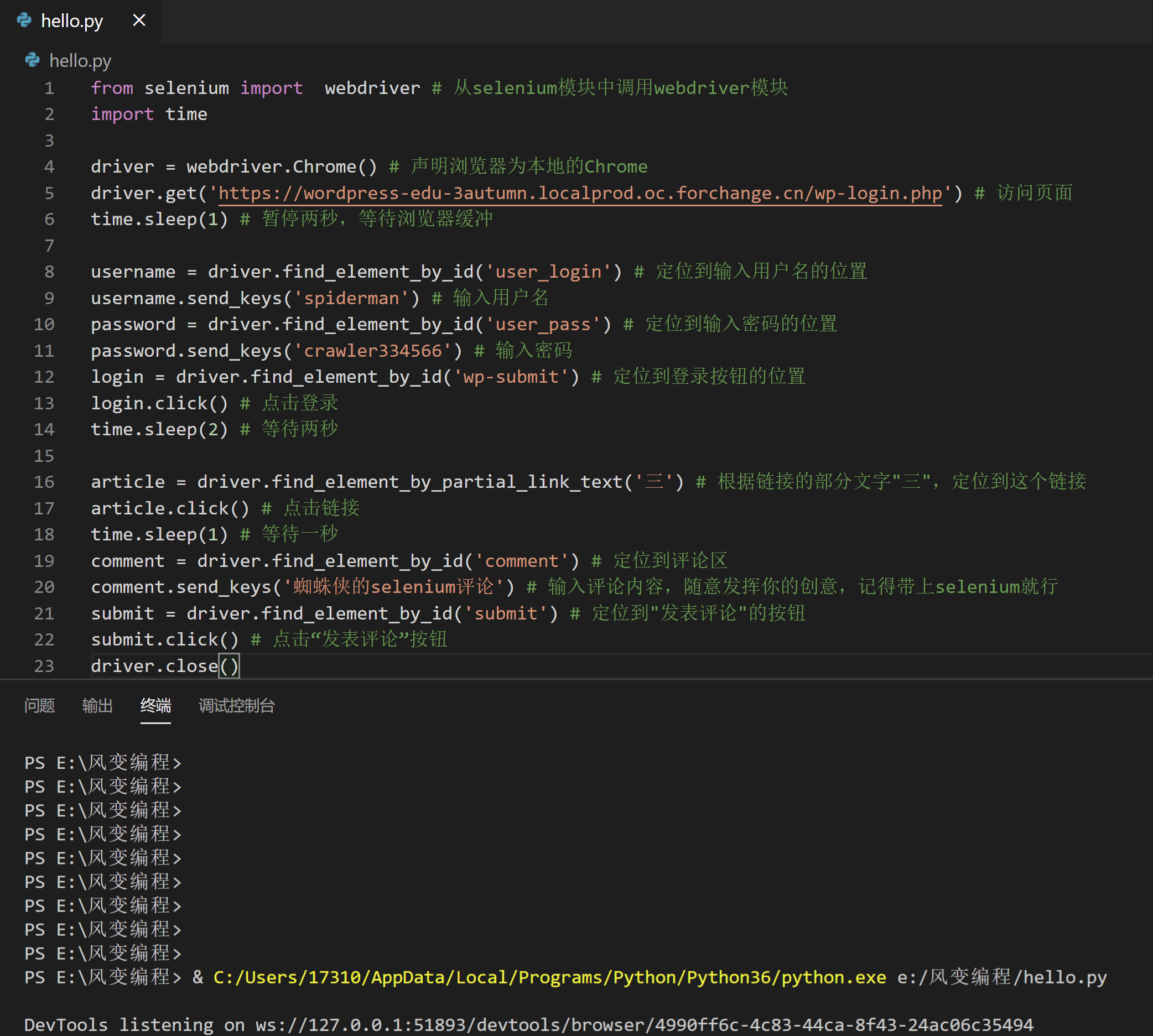
from selenium import webdriver # 从selenium模块中调用webdriver模块
import time
driver = webdriver.Chrome() # 声明浏览器为本地的Chrome
driver.get('https://wordpress-edu-3autumn.localprod.oc.forchange.cn/wp-login.php') # 访问页面
time.sleep(1) # 暂停两秒,等待浏览器缓冲
username = driver.find_element_by_id('user_login') # 定位到输入用户名的位置
username.send_keys('spiderman') # 输入用户名
password = driver.find_element_by_id('user_pass') # 定位到输入密码的位置
password.send_keys('crawler334566') # 输入密码
login = driver.find_element_by_id('wp-submit') # 定位到登录按钮的位置
login.click() # 点击登录
time.sleep(2) # 等待两秒
article = driver.find_element_by_partial_link_text('三') # 根据链接的部分文字"三",定位到这个链接
article.click() # 点击链接
time.sleep(1) # 等待一秒
comment = driver.find_element_by_id('comment') # 定位到评论区
comment.send_keys('蜘蛛侠的selenium评论') # 输入评论内容,随意发挥你的创意,记得带上selenium就行
submit = driver.find_element_by_id('submit') # 定位到"发表评论"的按钮
submit.click() # 点击“发表评论”按钮
driver.close()
5.2 习题二
1.练习介绍
这就是我在关卡中跟你说的,给你留的课后作业。
2.要求:
爬取网页你好,蜘蛛侠!中的Python之禅中英文版本,并且打印。
3.目的:
练习使用selenium爬取动态网页的信息。
练习selenium与BeautifulSoup的搭配使用。
5.2.1 第一种方法:selenium
这次我们要用
selenium
单独完成这个爬虫。
获取数据、解析数据、提取数据这三个步骤全部都由
selenium
来完成。
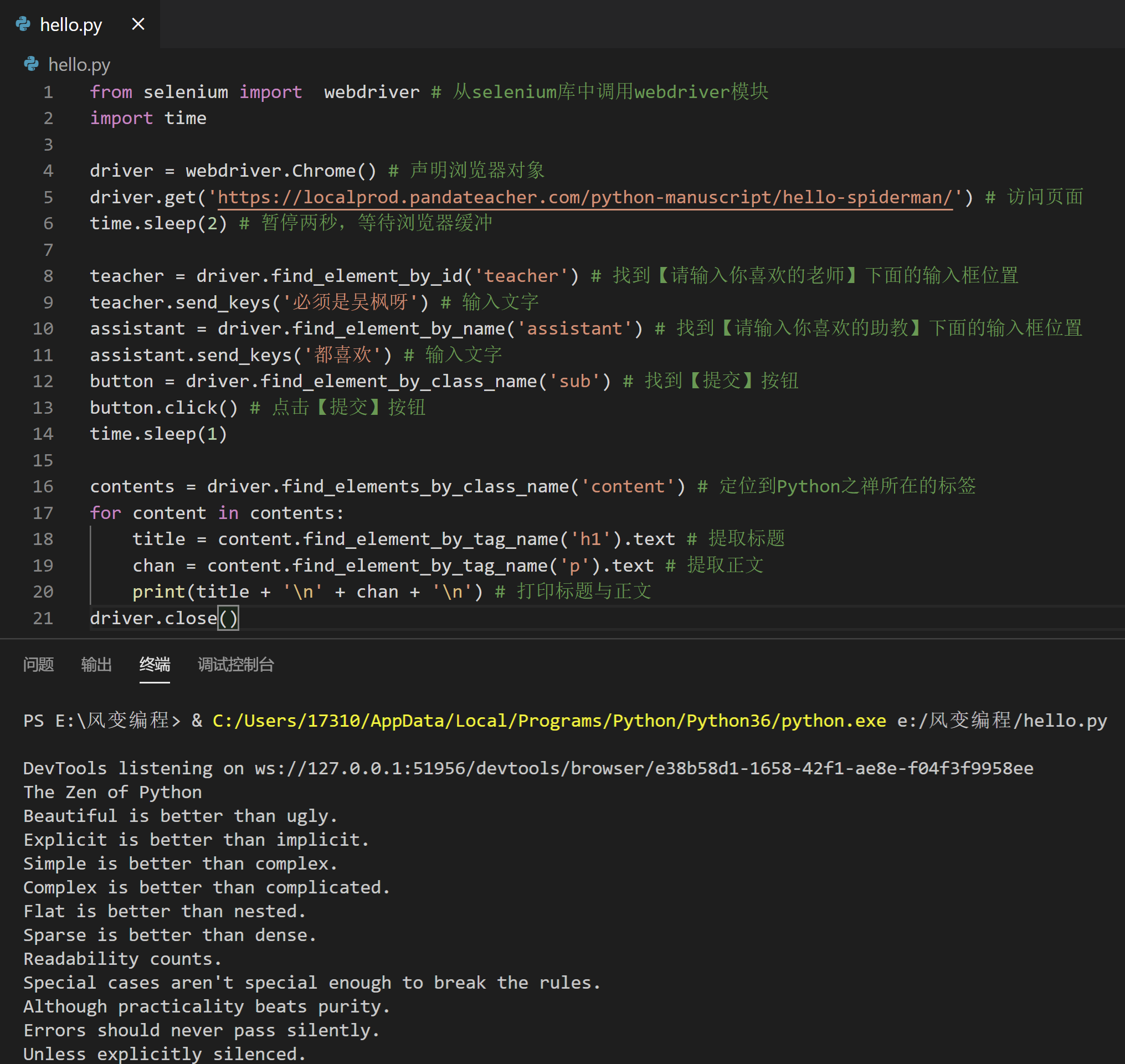
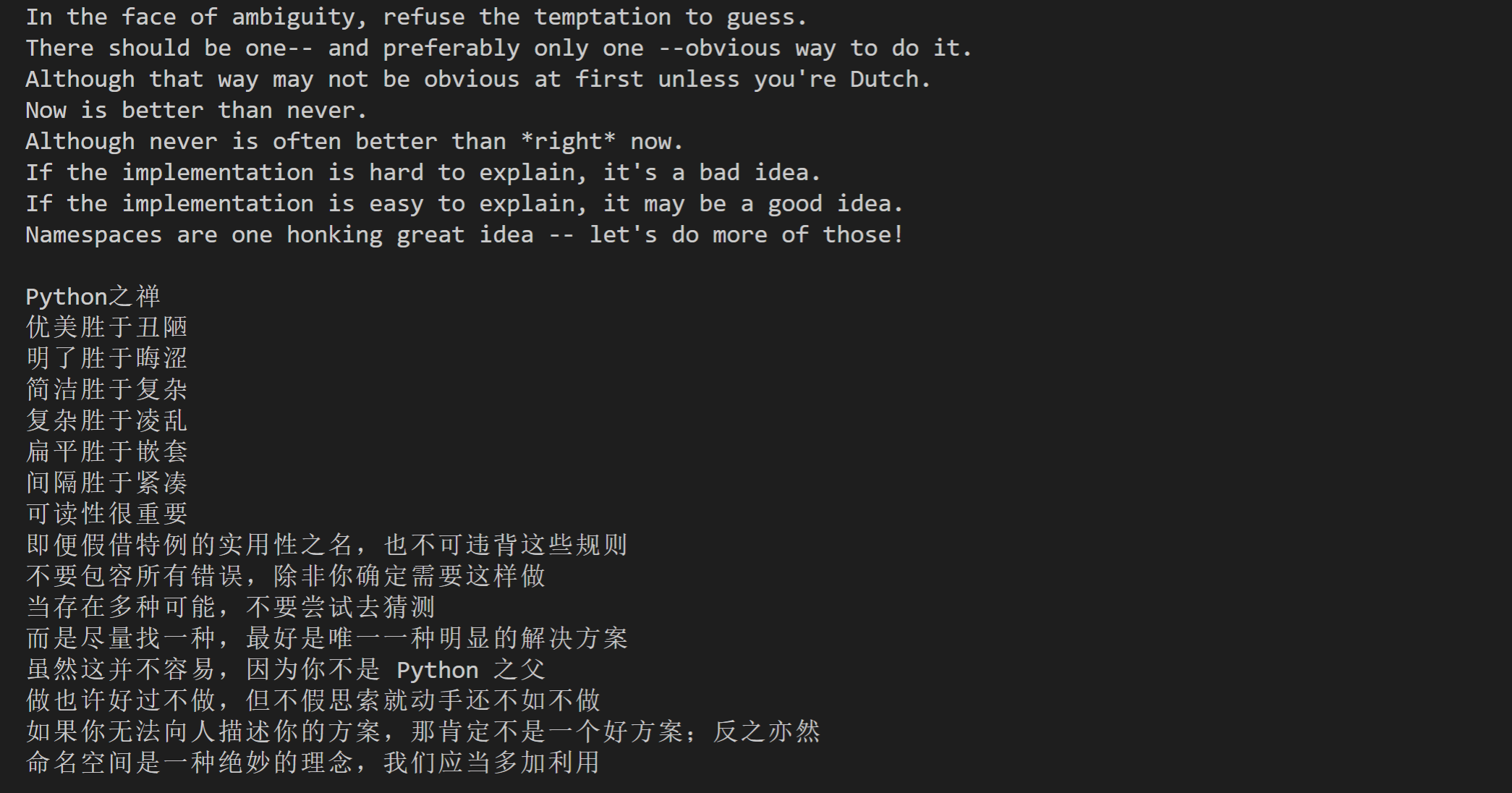
from selenium import webdriver # 从selenium库中调用webdriver模块
import time
driver = webdriver.Chrome() # 声明浏览器对象
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 暂停两秒,等待浏览器缓冲
teacher = driver.find_element_by_id('teacher') # 找到【请输入你喜欢的老师】下面的输入框位置
teacher.send_keys('必须是吴枫呀') # 输入文字
assistant = driver.find_element_by_name('assistant') # 找到【请输入你喜欢的助教】下面的输入框位置
assistant.send_keys('都喜欢') # 输入文字
button = driver.find_element_by_class_name('sub') # 找到【提交】按钮
button.click() # 点击【提交】按钮
time.sleep(1)
contents = driver.find_elements_by_class_name('content') # 定位到Python之禅所在的标签
for content in contents:
title = content.find_element_by_tag_name('h1').text # 提取标题
chan = content.find_element_by_tag_name('p').text # 提取正文
print(title + '\n' + chan + '\n') # 打印标题与正文
driver.close()
5.2.2 第二种方法:selenium 与 BeautifulSoup配合
先用
selenium
获取到渲染完成的
Elements
中的网页源代码,然后,
BeautifulSoup
登场解析和提取数据。

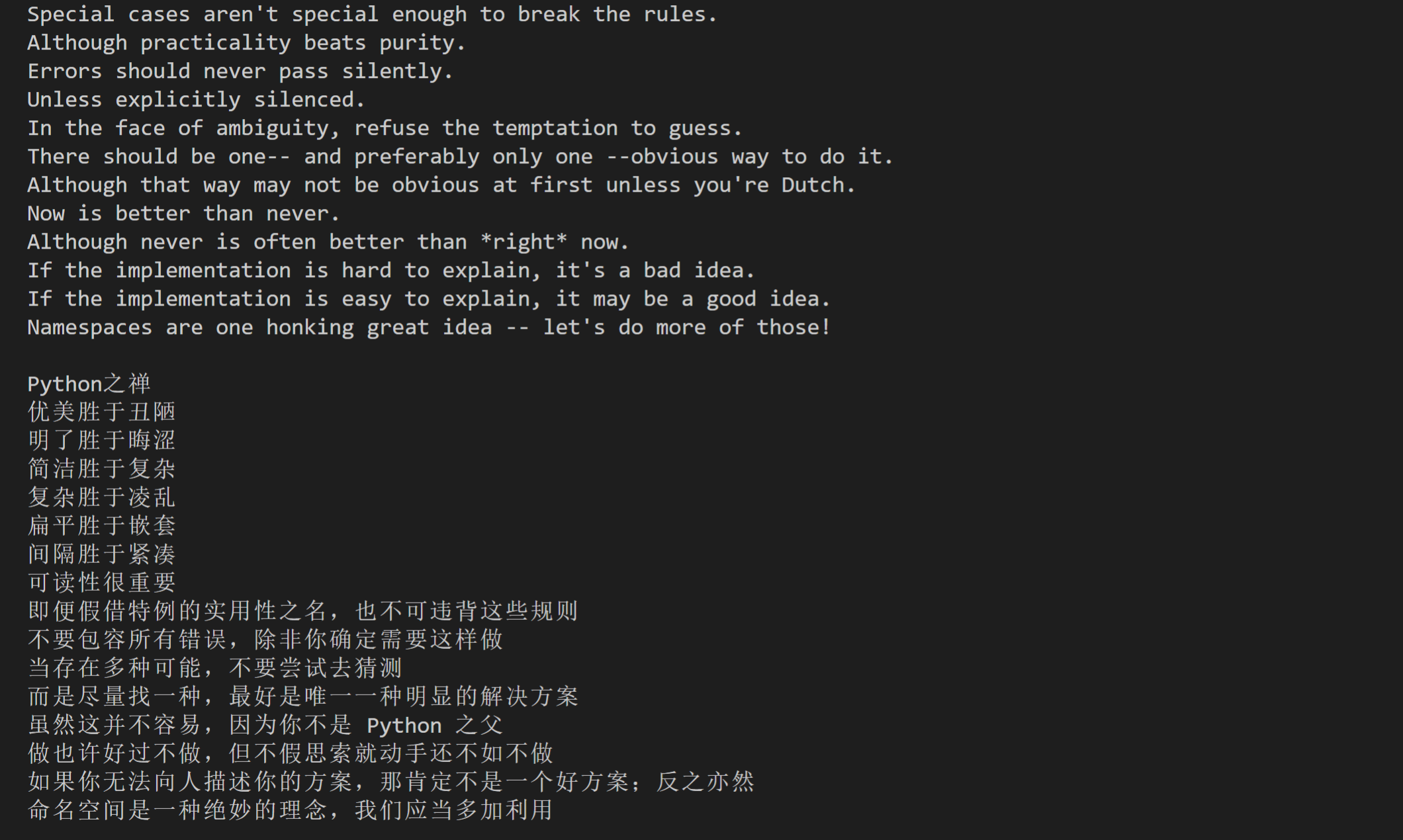
from selenium import webdriver # 从selenium库总调用webdriver模块
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome() # 声明浏览器对象
driver.get('https://localprod.pandateacher.com/python-manuscript/hello-spiderman/') # 访问页面
time.sleep(2) # 暂停两秒,等待浏览器缓冲
teacher = driver.find_element_by_id('teacher') # 定位到【请输入你喜欢的老师】下面的输入框位置
teacher.send_keys('必须是吴枫呀') # 输入文字
assistant = driver.find_element_by_name('assistant') # 定位到【请输入你喜欢的助教】下面的输入框位置
assistant.send_keys('都喜欢') # 输入文字
button = driver.find_element_by_class_name('sub') # 定位到【提交】按钮
button.click() # 点击【提交】按钮
time.sleep(1) # 等待一秒
pageSource = driver.page_source # 获取页面信息
soup = BeautifulSoup(pageSource,'html.parser') # 使用bs解析网页
contents = soup.find_all(class_="content") # 找到源代码Python之禅中文版和英文版所在的元素
for content in contents: # 遍历列表
title = content.find('h1').text # 提取标题
chan = content.find('p').text.replace(' ','') # 提取Python之禅的正文,并且去掉文字前面的所有空格
print(title + chan + '\n') # 打印Python之禅的标题与正文
driver.close()
版权归原作者 退役小学生呀 所有, 如有侵权,请联系我们删除。