
文章目录
一、实战概述
- 在这个实战中,我们使用了
Hive框架来处理学生的月考成绩数据。首先,我们准备了三个文本文件,分别包含了语文、数学和英语的月考成绩数据。这些数据被上传到HDFS的指定目录。 - 接着,我们启动了
Hive Metastore服务,并通过Hive客户端连接到Hive。在Hive中,我们创建了一个分区表student_score,用于存储学生的成绩数据,其中分区字段为科目(subject)。 - 然后,我们按照科目将数据加载到分区表中,分别加载了语文、数学和英语的成绩数据。通过这样的分区方式,我们能够更方便地对数据进行查询和分析。
- 最后,我们使用
Hive的SQL语句进行统计,计算每个学生在三个科目上的月考平均分。使用了AVG函数和ROUND函数来得到每个学生的平均分,并保留一位小数。这样,我们得到了每个学生在语文、数学和英语三个科目上的月考平均分的统计结果。 - 整个实战过程涉及了
Hive的表创建、分区管理、数据加载和SQL查询等操作,展示了Hive在大数据处理中的灵活性和便捷性。通过这次实战,我们能够更好地理解和掌握Hive框架在数据分析和查询中的应用。
二、提出任务
- 语文月考成绩 -
chinese.txt
1 张晓云 892 张晓云 733 张晓云 674 张晓云 705 张晓云 796 张晓云 877 张晓云 998 张晓云 839 张晓云 9710 张晓云 9211 张晓云 6712 张晓云 861 王东林 492 王东林 833 王东林 674 王东林 495 王东林 936 王东林 877 王东林 658 王东林 929 王东林 6010 王东林 9411 王东林 8112 王东林 901 李宏宇 772 李宏宇 663 李宏宇 894 李宏宇 875 李宏宇 966 李宏宇 797 李宏宇 878 李宏宇 969 李宏宇 6910 李宏宇 8711 李宏宇 9612 李宏宇 79
- 数学月考成绩 -
math.txt
1 张晓云 792 张晓云 833 张晓云 774 张晓云 905 张晓云 896 张晓云 677 张晓云 898 张晓云 939 张晓云 9010 张晓云 8211 张晓云 7712 张晓云 961 王东林 782 王东林 943 王东林 764 王东林 705 王东林 906 王东林 837 王东林 858 王东林 829 王东林 8410 王东林 7811 王东林 9912 王东林 931 李宏宇 862 李宏宇 813 李宏宇 764 李宏宇 935 李宏宇 886 李宏宇 827 李宏宇 818 李宏宇 939 李宏宇 8610 李宏宇 9011 李宏宇 6712 李宏宇 88
- 英语月考成绩 -
english.txt
1 张晓云 782 张晓云 833 张晓云 924 张晓云 665 张晓云 826 张晓云 897 张晓云 798 张晓云 689 张晓云 9610 张晓云 9111 张晓云 8712 张晓云 821 王东林 692 王东林 863 王东林 734 王东林 995 王东林 676 王东林 957 王东林 748 王东林 929 王东林 7610 王东林 8811 王东林 9212 王东林 561 李宏宇 882 李宏宇 783 李宏宇 924 李宏宇 785 李宏宇 896 李宏宇 767 李宏宇 928 李宏宇 759 李宏宇 8810 李宏宇 9211 李宏宇 9712 李宏宇 85
- 利用Hive框架,统计每个同学各科月考平均分
三、完成任务
(一)准备数据
- 启动hadoop服务

1、在虚拟机上创建文本文件
- 创建
subjectavg目录,以下文件内容可在上面复制 - 在里面创建
chinese.txt文件 - 创建
math.txt - 创建
english.txt
2、上传文件到HDFS指定目录
- 创建/subjectavg/input目录,执行命令:
hdfs dfs -mkdir -p /subjectavg/input

- 将文本文件
chinese.txt、math.txt与english.txt,上传到HDFS的/subjectavg/input目录
hdfs dfs -put chinese.txt /subjectavg/input/
hdfs dfs -put math.txt /subjectavg/input/
hdfs dfs -put english.txt /subjectavg/input/



(二)实现步骤
1、启动Hive Metastore服务
- 执行命令:
hive --service metastore &,在后台启动metastore服务
2、启动Hive客户端
- 执行命令:
hive,看到命令提示符hive>
3、创建分区的学生成绩表
执行语句:
create table student_score ( id int, name string, score int ) partitioned by (subject string) row format delimited fields terminated by ' ';

4、按分区加载数据
- 加载
chinese.txt到chinese分区
load data inpath "/subjectavg/input/chinese.txt" overwrite into table student_score partition(subject="chinese");

- 加载math.txt到math分区
load data inpath "/subjectavg/input/math.txt" overwrite into table student_score partition(subject="math");

- 加载english.txt到english分区
load data inpath "/subjectavg/input/english.txt" overwrite into table student_score partition(subject="english");

5、查看分区表全部记录
- 执行语句:
select * from student_score;
6、统计每个学生三科月考平均分
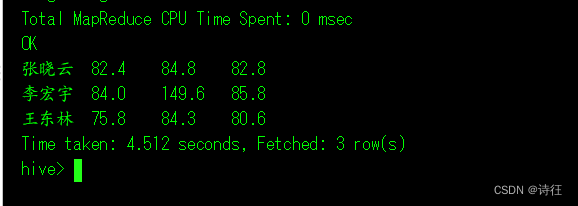
- 执行语句:
SELECT name, ROUND(AVG(CASE WHEN subject = 'chinese' THEN score ELSE NULL END), 1) AS chinese_avg, ROUND(AVG(CASE WHEN subject = 'math' THEN score ELSE NULL END), 1) AS math_avg, ROUND(AVG(CASE WHEN subject = 'english' THEN score ELSE NULL END), 1) AS english_avg FROM student_score GROUP BY name;
SELECT子句
name
: 选择学生的姓名。
ROUND(AVG(CASE WHEN subject = 'chinese' THEN score ELSE NULL END), 1) AS chinese_avg
: 计算学生在"
chinese
"科目的平均分数,并将结果四舍五入到一位小数。使用
CASE
语句,只有当科目是"
chinese
"时才考虑该分数,否则将其视为
NULL
。
ROUND(AVG(CASE WHEN subject = 'math' THEN score ELSE NULL END), 1) AS math_avg
: 计算学生在"
math
"科目的平均分数,同样将结果四舍五入到一位小数。
ROUND(AVG(CASE WHEN subject = 'english' THEN score ELSE NULL END), 1) AS english_avg
: 计算学生在"
english
"科目的平均分数,同样将结果四舍五入到一位小数。
FROM
子句
student_score
: 表示数据来自名为
student_score
的表。
GROUP BY
子句
GROUP BY name
: 将结果按学生姓名进行分组,以便计算每个学生在不同科目上的平均分数。
因此,这个查询将返回一个结果集,其中包含每个学生的姓名以及他们在"
chinese
"、"
math
"和"
english
"科目上的平均分数,四舍五入到一位小数。
四、实战总结
- 本次实战运用
Hive处理学生月考成绩数据,通过创建分区表、加载各科目成绩至对应分区,并使用SQL语句计算平均分,展示了Hive在大数据管理、分析查询及统计计算上的灵活性与便捷性。
本文转载自: https://blog.csdn.net/xujonas/article/details/135449748
版权归原作者 诗彺 所有, 如有侵权,请联系我们删除。
版权归原作者 诗彺 所有, 如有侵权,请联系我们删除。