
Technology Innovation Institute最近发布了Falcon 180B大型语言模型(LLM),它击败了Llama-2 70b,与谷歌Bard的基础模型PaLM-2 Large不相上下。
180B是是Falcon 40B模型一个最新版本。以下是该模型的快速概述:
180B参数模型,两个版本(base和chat)
使用RefinedWeb数据集训练3.5万亿个令牌
上下文最大为2048令牌
它大约是ChatGPT (GPT-3.5)的大小,它有175B个参数。它是最好的吗?截至2023年9月,Falcon 180B在hug Face的模型排行榜上排名第一。

模型变体
Falcon 180B有两个版本——基础版和聊天版。
基础版是一个因果解码器模型。这个模型非常适合对自己的数据进行进一步微调。
聊天版chat与基础版本类似,这也是一个1800亿个参数的因果解码器模型。但是它对Ultrachat5、Platypus6和airboros7指令(聊天)数据集进行了微调。
模型表现
就它的能力而言,Falcon 180B与PaLM-2 Large并肩而立,使其成为最强大的公开可用语言模型之一。
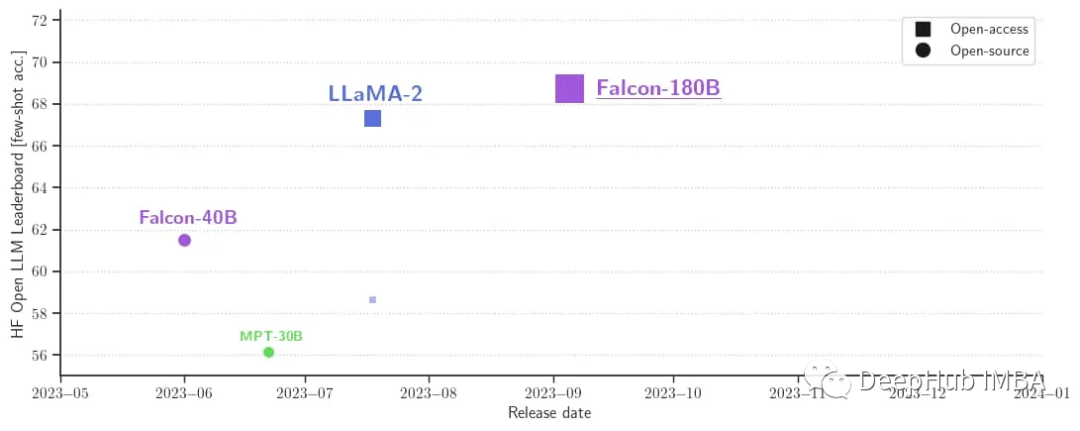
量化的Falcon模型在基准测试中保持了类似的指标。
通过Open LLM排行榜,你会注意到,尽管声称这是最好的Open LLM,但Llama 2的微调版本仍然优于Falcon 180B。但是值得注意的是,最初的Llama 2模型是在Falcon发布之后。

硬件需求
虽然模型是免费使用的,但你很难在普通的gpu上运行它。甚至GPTQ(TheBloke)版本的这个模型,仍然需要超过80GB的VRAM。看看HF帖子中的这张表:
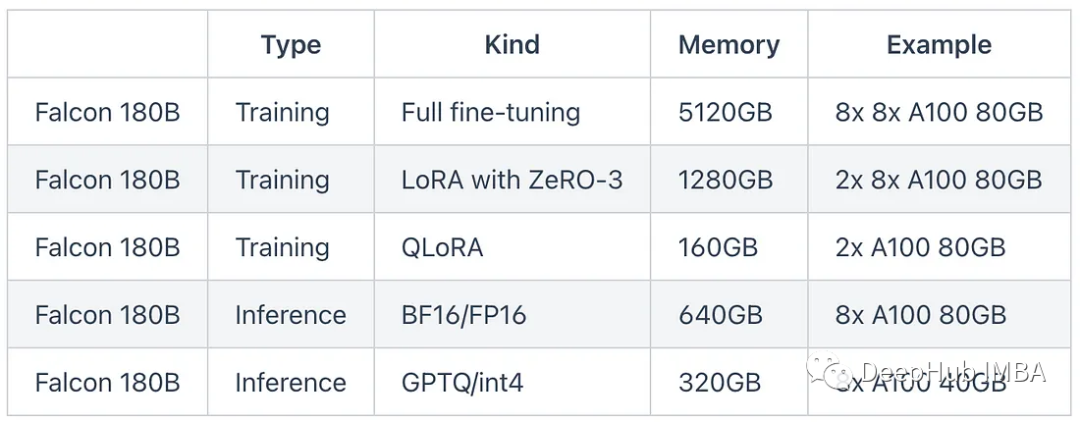
8个A100 80GB gpu -还是在量化到半精度(FP16)之后。选择int4精度仍然需要320GB的内存。
那么8个A100要多少钱呢?以下为美东AWS的A100 GPU每小时价格。
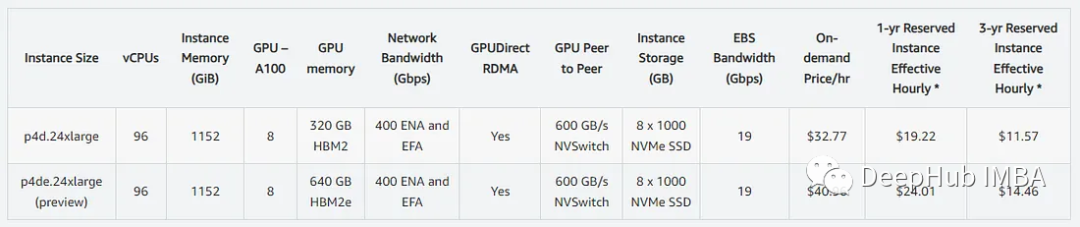
也就是说,如果运行int4,每月大概24,000美元,半精度的话,大概是30,000美元。
数据集的作用
Chinchilla缩放定律指出,一个模型的大小和它的训练数据集应该同步增长,以在给定的计算预算内最大化性能。
Falcon180B使用RefinedWeb数据集对惊人的3.5万亿个令牌进行了训练。RefinedWeb不仅规模庞大,而且还经过精心提炼和增强,并通过一些精心挑选的附加内容进行培训。而TII不断强调RefinedWeb在创建其Falcon模型中的重要性。
该原则在实际应用中的实际含义非常深远,当Llama-65B模型在1.4万亿令牌上进行训练时,可以看到这种效果,并且它的表现明显优于OPT-175B模型,因为后者仅在1800亿令牌上进行训练。这也充分说明了当大型模型缺乏充足的数据时,它们的表现可能会被数据丰富的小型模型超越。
Falcon 180b vs ChatGPT
Falcon 180B可以通过HuggingFace上的Demo来进行测试。Demo被限制在大约1000字的会话长度。
我们将在相同的提示下比较ChatGPT和Falcon 180B的性能。以下是猎鹰180B Demo的默认配置:
Temperature: 0
Max new tokens: 512
Top-p: 0.9
Repetition penalty: 1.1
我们来测试一下他的表现
What is the latest date you have knowledge of?
**Falcon 180B**:
As an AI language model, I do not have knowledge of specific dates unless they
are provided to me. Please provide a specific date or context for me to answer
your question accurately.
**ChatGPT**:
My knowledge is current up to September 2021. I do not have information on
events, developments, or information that has occurred after that date. If you have
questions or need information beyond that date, I may not be able to provide it. Please
verify any information I provide with more up-to-date sources.
也就是说训练的时候没有表明使用数据,不过根据官方的提示,应该就是RefinedWeb的时间了。
代码生成
代码生成是我们比较关注的事情,但是较小的型号(7B-40B)对于代码方面表现不佳所以才出现了专门的Code Llama。
Write a function in python that calculates the square of a sum of two numbers.
Falcon 180B:
Here is a simple function in Python that calculates the square of a sum of two
numbers:
```py
def square_sum(num1, num2):
return (num1 + num2)**2
This function takes two arguments num1 and num2, adds them together, and then
calculates the square of the result using the exponentiation operator (**).
The final result is returned.
For example, if you call square_sum(3, 4), it will return 49, because (3 + 4)
2 = 72 = 49.
**ChatGPT**:
You can create a Python function to calculate the square of the sum of two
numbers like this:
def square_of_sum(num1, num2):
# Calculate the sum of the two numbers
total = num1 + num2
# Calculate the square of the sum
square = total ** 2
return square
# Example usage:
num1 = 5
num2 = 3
result = square_of_sum(num1, num2)
print(f"The square of the sum of {num1} and {num2} is {result}")
This function, square_of_sum, takes two numbers as input, calculates their
sum, and then calculates the square of that sum. The result is returned by the
function. You can call this function with different values of num1 and num2
to calculate the square of the sum of any two numbers.
虽然ChatGPT的代码多,但是180B的代码更简洁,更容易阅读。让我们试一个更难的:
> Write a function in python that splits a list into 3 equal parts and returns alist with a random element of each sublist.
**Falcon 180B**:
Here's a function that does what you're asking for:
import random
def split_list(lst):
n = len(lst)
part_size = n // 3
parts = [lst[i:i+part_size] for i in range(0, n, part_size)]
return [random.choice(part) for part in parts]
This function takes a list lst as input and splits it into three equal parts
using list slicing. It then selects a random element from each sublist using
the random.choice() function and returns a new list containing these elements.
Here's an example usage of the function:
lst = [1, 2, 3, 4, 5, 6, 7, 8, 9]
split_list(lst)
[5, 6, 7]
In this example, the input list lst is split into three equal parts of size 3,
and a random element is selected from each part to form the output list [5, 6, 7].
**ChatGPT**:
You can achieve this by first splitting the list into three equal parts and
then selecting a random element from each sublist. Here's a Python function to
do that:
import random
def split_and_random_elements(input_list):
# Calculate the size of each sublist
sublist_size = len(input_list) // 3
# Split the input list into three sublists
sublists = [input_list[i:i + sublist_size] for i in range(0, len(input_list), sublist_size)]
# Initialize a list to store the random elements
random_elements = []
# Select a random element from each sublist
for sublist in sublists:
if sublist:
random_element = random.choice(sublist)
random_elements.append(random_element)
return random_elements
# Example usage:
input_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
result = split_and_random_elements(input_list)
print(result)
In this function, we first calculate the size of each sublist by dividing the
length of the input list by 3. Then, we use list comprehension to split the
input list into three sublists of equal size. Finally, we iterate through the
sublists and use the random.choice function to select a random element from
each sublist and append it to the random_elements list, which is returned as
the result.
Falcon 180B的代码更简洁,但是它的代码有一个错误输出的例子。这样看对于代码生成而言,还有很大的微调空间。
**QA**
我们用下面这个表提问

Use the data from the markdown table:
|Model|Size|Code|Commonsense Reasoning|World Knowledge|Reading Comprehension|Math|MMLU|BBH|AGI Eval|
| — -| — -| — -| — -| — -| — -| — -| — -| — -| — -|
|Llama 1|7B|14.1|60.8|46.2|58.5|6.95|35.1|30.3|23.9|
|Llama 1|13B|18.9|66.1|52.6|62.3|10.9|46.9|37.0|33.9|
|Llama 1|33B|26.0|70.0|58.4|67.6|21.4|57.8|39.8|41.7|
|Llama 1|65B|30.7|70.7|60.5|68.6|30.8|63.4|43.5|47.6|
|Llama 2|7B|16.8|63.9|48.9|61.3|14.6|45.3|32.6|29.3|
|Llama 2|13B|24.5|66.9|55.4|65.8|28.7|54.8|39.4|39.1|
|Llama 2|70B|**37.5**|**71.9**|**63.6**|**69.4**|**35.2**|**68.9**|**51.2**|**54.2**|
to answer the question:
Calculate how much better (% increase) is Llama 2 7B vs Llama 1 7B on Reading Comprehension?
回答结果如下:
**Falcon 180B**:
The Reading Comprehension score for Llama 1 7B is 58.5 and for Llama 2 7B it is
61.3. To calculate the percentage increase, we use the formula:
Percentage Increase = ((New Value - Old Value) / Old Value) * 100
Plugging in the values, we get:
Percentage Increase = ((61.3 - 58.5) / 58.5) * 100 = 5.1%
Therefore, Llama 2 7B is 5.1% better than Llama 1 7B on Reading Comprehension.
**ChatGPT**:
To calculate the percentage increase in Reading Comprehension between Llama 2
7B and Llama 1 7B, you can use the following formula:
Percentage Increase = [(New Value - Old Value) / Old Value] * 100
In this case:
- New Value (Llama 2 7B Reading Comprehension): 61.3
- Old Value (Llama 1 7B Reading Comprehension): 58.5
Now, plug these values into the formula:
Percentage Increase = [(61.3 - 58.5) / 58.5] * 100
Percentage Increase = [(2.8) / 58.5] * 100
Percentage Increase ≈ 4.79%
So, Llama 2 7B performs approximately 4.79% better than Llama 1 7B on Reading
Comprehension.
两种模型给出了不同的答案。哪一个是正确的?好吧,ChatGPT对了:
Percentage Increase = ((61.3–58.5) / 58.5) * 100 = 5.1%
Falcon 180B的公式是没问题的,但是最后一步的除法算错了。
## 总结
Falcon 180B是目前最大的公开模特。它在排行榜上名列前茅,甚至给那些大牌的专有模式,比如PaLM-2,带来了竞争压力。但是我们的评估表明,它可能还需要有更大的提升。
对于有兴趣测试和评估LLM的个人或组织,有以下建议:
1、定义明确的目标:了解想通过评估达到什么目标。无论是衡量模型在语言理解方面的熟练程度,探索道德考虑,还是测试偏见,有一个明确的目标将指导评估过程。
2、多样化的输入:确保测试数据集包含广泛的主题、语言、文化和复杂性。这确保了对模型能力的全面评估。
3、检查偏差:在模型的反应中积极寻找明显和微妙的偏差。这包括与种族、性别、国籍等有关的偏见。LLM可能会无意中携带训练数据中存在的偏见。
4、复杂场景:不仅给模型提供简单的问题,还要提供复杂的、多方面的场景,以了解其深度和推理能力。
5、一致性:以不同的时间间隔多次运行相同或类似的查询,检查响应的一致性。
6、真实世界用例:在业务领域相关的实际的、真实的场景中测试模型。这给了一个概念,如何很好地将模型集成到实际应用中。
7、与替代方案比较:如果可能,将输出与其他类似的llm进行比较。这将给出一个相对的性能度量。
8、反馈循环:实现一个反馈机制,在这个机制中,评估者可以对模型的响应提供反馈。这对于迭代改进是有价值的。
9、了解局限性:每个模型都有其局限性。注意模型的知识边界、任何预先设定的边界以及它的一般设计约束。
10、安全措施:特别是在面向公众的应用程序中使用该模型时,要实现保护措施以防止有害输出或误用。
11、保持更新:LLM不断发展。随时了解模型的最新版本和改进。
相信随着LLM不断发展,他会与我们的日常生活更加无缝地融合在一起,但是现在还为时过早,而且我个人认为,在硬件限制的情况下,减小模型的大小这个研究方向是非常有前途的,包括,模型压缩,发现更小但是更好的模型,甚至是另外一种更高效的建模方法。