

Actor-Critic从名字上看包括两部分,参与者(Actor)和评价者(Critic)。其中Actor使用策略函数,负责生成动作(Action)并和环境交互。而Critic使用我们之前讲到了的价值函数,负责评估Actor的表现,并指导Actor下一阶段的动作。
基于策略和基于价值的RL算法
在基于策略的RL中,最优策略是通过直接操纵策略来计算的,而基于价值的函数通过找到最优值函数来隐式地找到最优策略。基于策略的RL在高维和随机的连续动作空间以及学习随机策略方面非常有效。同时,基于价值的RL在样品效率和稳定性方面表现出色。
策略梯度RL的主要挑战是高梯度方差。减少梯度估计方差的标准方法是使用基线函数b(st)[4]。关于添加基线会引起很多关注,这会在梯度估计中引起偏差。有证据表明,基线不能为梯度估算提供基础。
证明基线是无偏见的
REINFORCE算法的策略梯度表达式如下所示:
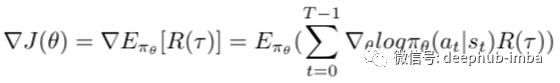
REINFORCE的策略梯度表达的期望形式
我们可以写出轨迹的奖励R(τ)如下:
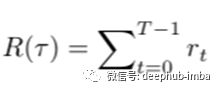
然后添加基线函数,如下所示修改策略梯度表达式:
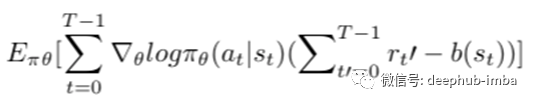
插入基线功能
我们可以将奖励和基准期限称为优势函数。可以表示如下:
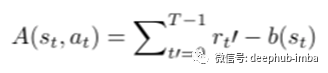
优势功能
在上面的等式中要注意的重要一点是基线b是s_t而不是s_t` [4]的函数
我们可以重新排列表达式,如下所示:

上式是等效的E(X-Y)。由于期望的线性,因此我们可以将E(X-Y)重新排列为E(X)-E(Y)[3]。因此,对上面的等式进行了如下修改:
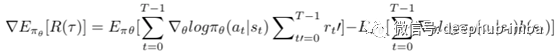
如果带有基线的第二项为零,则可以证明添加基线函数b在梯度估计中未添加偏差。那意味着
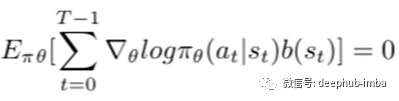
我们可以将期望概括如下:
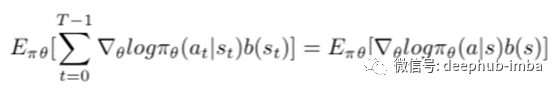
第二项的证明为零,如下所示:

上面的推论证明,添加基线函数对梯度估计没有偏差
Actor-critic
简单来说,Actor-Critic是策略梯度的时间差异(TD)版本[3]。它有两个网络:参与者和评论家。参与者决定应该采取哪种行动,评论家告知参与者该行动有多好,应该如何调整。参与者的学习基于策略梯度方法。相比之下,评论家通过计算价值函数来评估参与者的行动。
这种类型的架构是在生成对抗网络(GAN)中,鉴别器和生成器都参与游戏[2]。生成器生成伪图像,鉴别器使用其真实图像的表示来评估所生成的伪图像的质量[2]。随着时间的流逝,生成器可以创建伪造的图像,这些伪造的图像对于鉴别器是无法区分的[2]。同样,Actor和Critic都参与了游戏,但是与GAN [2]不同,他们都在不断改进。
Actor-critic类似于带有基准的称为REINFORCE的策略梯度算法。强化是MONTE-CARLO的学习,它表示总收益是从整个轨迹中采样的。但是在参与者评论家中,我们使用引导程序。因此,优势功能的主要变化。

策略梯度总回报中的原始优势函数更改为自举。资料来源:[3]
最后,b(st)更改为当前状态的值函数。可以表示如下:

我们可以为actor-critic编写新的修改后的优势函数:

或者,将优势函数称为TD错误,如Actor-Critic框架所示。如上所述,参与者的学习是基于策略梯度的。参与者的策略梯度表达式如下所示:

参与者的政策梯度表达
Actor-Critic算法的伪代码[6]
1、使用来自参与者网络的策略πθ对{s_t,a_t}进行采样。
2、评估优势函数A_t。可以将其称为TD误差δt。在Actor-critic算法中,优势函数是由评论者网络产生的。

3、使用以下表达式评估梯度:
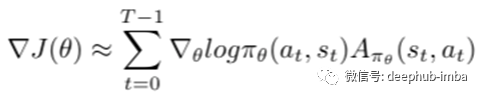
4、更新策略参数θ
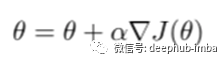
5、更新基于评价者的基于价值的RL(Q学习)的权重。δt等于优势函数。

6、重复1到5,直到找到最佳策略πθ。
引用
- https://inst.eecs.berkeley.edu/~cs188/sp20/assets/files/SuttonBartoIPRLBook2ndEd.pdf
- https://theaisummer.com/Actor_critics/
- http://machinelearningmechanic.com/deep_learning/reinforcement_learning/2019/12/06/a_mathematical_introduction_to_policy_gradient.html
- https://danieltakeshi.github.io/2017/03/28/going-deeper-into-reinforcement-learning-fundamentals-of-policy-gradients/
- https://en.wikipedia.org/wiki/Expected_value
- http://rail.eecs.berkeley.edu/deeprlcourse-fa17/f17docs/lecture_5_actor_critic_pdf
作者:Dhanoop Karunakaran
deephub翻译组