
在本文中,我将介绍一个名为Locust的性能测试工具。我将从Locust的功能特性出发,结合实例对Locust的使用方法进行介绍。
概述
Locust主要有以下的功能特性:
- 在Locust测试框架中,测试场景是采用纯Python脚本进行描述的。不需要笨重的UI和臃肿的XML
- 对于最常见的
http(s)协议的系统,Locust采用Python的requests作为客户端,使得脚本编写大大简化。除了http(s)协议的系统之外,Locust还支持测试其他系统或协议,只需要我们为测试的内容编写一个客户端就可以了。 - 在模拟并发方面,
Locust是基于事件驱动,使用gevent提供的非阻塞IO和coroutine来实现网络层的并发请求,使得单个进程处理千个并发用户。再加上Locust支持分布式,使得支持数十万并发用户不是梦。 Locust有一个简单干净的Web界面,可以实时显示测试进度。在测试运行期间,可以随时更改负载。它还可以在没有UI的情况下运行,便于用于CI/CD测试。
我们都知道服务端性能测试工具最核心的部分是压力发生器,而压力发生器的核心要点有两个:一是真实模拟用户操作,二是模拟有效并发。
- 相比 LoadRunner、Jmeter 这种压测工具(通过线程对应一个用户/并发的方式产生负载)而言,Locust能够以比较低的成本产生负载(LoadRunner 一个 Vuser 占用内存数M甚至数十MB,而 Jmeter 最高并发数受限于 JVM 大小)。
- 支持BDD(行为驱动开发)编写任务以及执行任务,能够更好地模拟用户真实的操作流程。
脚本结构介绍
下面通过一个简单的案例学习一下locust的基本使用:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time:2022/3/26 9:38 上午# @Author:boyizhangfrom locust import TaskSet, HttpUser, task, run_single_user
classBaiduTaskSet(TaskSet):"""
任务集
"""@taskdefsearch_by_key(self):
self.client.get('/')classBaiduUser(HttpUser):"""
- 会产生并发用户实例
- 产生的用户实例会依据规则去执行任务集
"""# 定义的任务集
tasks =[BaiduTaskSet,]
host ='http://www.baidu.com'if __name__ =='__main__':# debug:调试任务是否可以跑通
run_single_user(BaiduUser)
从脚本中可以看出,脚本主要包含两个类:BaiduTaskSet与BaiduUser,BaiduTaskSet继承TaskSet,BaiduUser继承HttpUser(HttpUser继承User)。
BaiduTaskSet是定义用户执行的任务细节,而BaiduUser(User)则是负责生成用户实例去执行这些任务。
User类就好比是一群蝗虫,而每一只蝗虫就是一个类的实例。相应的,TaskSet类就好比是蝗虫的大脑,控制着蝗虫的具体行为,即实际业务场景测试对应的任务集。
HttpUser(User)
在
User类
中,具有一个
client
属性,它对应着虚拟用户作为客户端所具备的请求能力。
- 通常情况下,我们不会直接使用
User类,因为其client属性没有绑定任何方法。 - 在使用
User类时,需要先继承User类,然后在继承子类中的client属性中绑定客户端的实现类。
对于常见的
HTTP(S)
协议,我们可以继承
HttpUser
类。HttpUser 是最常用的用户类。它添加了一个client属性,用于发出 HTTP 请求。
- 其
client属性绑定了HttpSession类,而HttpSession又继承自requests.Session。因此在测试HTTP(S)的Locust脚本中,我们可以通过client属性来使用Python requests库的所有方法,调用方式也与requests完全一致。 - 由于
requests.Session的使用,因此client的方法调用之间就自动具有了状态记忆的功能。常见的场景就是,在登录系统后可以维持登录状态的Session,从而后续HTTP请求操作都能带上登录态。
而对于HTTP(S)以外的协议,我们同样可以使用Locust进行测试,
- 虽然Locust 仅内置了对 HTTP/HTTPS 的支持,但它可以扩展到测试几乎任何系统。只需要基于
User类实现client即可。 - 我们可以使用locust-plugins,这个是第三方维护的库,支持
Kafka、mqtt,webdriver等测试。
TaskSet
介绍
TaskSet
类实现了用户实例所执行任务的调度算法,包括规划任务执行顺序、挑选下一个任务、执行任务、休眠等待、中断控制等。在此基础上,我们就可以在
TaskSet
子类中采用非常简洁的方式来描述业务测试场景,对所有行为(任务)进行组织和描述,并可以对不同任务的权重进行配置。
在TaskSet子类中定义任务信息时,可以采取两种方式,@task装饰器和tasks属性。
- 采用
@task装饰器
from locust import TaskSet, task, constant
classMyTaskSet(TaskSet):defon_start(self):"""
用户开始执行此任务集时触发
:return:
"""print("task is running")defon_stop(self):"""
用户停止执行此任务集时触发
:return:
"""print(("task is stopped"))@task(2)deftask1(self):print("User instance (%r) executing my_task1"% self)@taskdeftask2(self):print("User instance (%r) executing my_task2"% self)
- 采用tasks属性
可以使用list,也可以使用dict。如果使用list,则权重为1:1
from locust import User, task, constant
classMyTaskSet(TaskSet):defon_start(self):"""
用户开始执行此任务集时触发
:return:
"""print("task is running")defon_stop(self):"""
用户停止执行此任务集时触发
:return:
"""print(("task is stopped"))deftask1(self):print("User instance (%r) executing my_task1"% self)deftask2(self):print("User instance (%r) executing my_task2"% self)
tasks ={task1:2, task2:1}# 如果是列表的形式,那执行任务的权限均为1:1# tasks = [task1, task2]
在如上两种定义任务信息的方式中,均设置了权重属性,即执行
task1
的频率是
task2
的两倍。若不指定执行任务的权重,则相当于比例为1:1。
on_start()
与
on_stop()
方法,分别重写父类的TaskSet的
on_start()
与
on_stop()
。分别在用户开始和停止执行此任务集时触发。
TaskSet 嵌套-真实模拟用户场景
TaskSet 类的任务可以是其他 TaskSet 类,允许它们嵌套任意数量的级别。这使我们能够以更真实的方式定义模拟用户的行为。
classNestTaskSet(TaskSet):@task(3)defget_index_page(self):print("get_Index_page")@task(7)classget_forum_page(TaskSet):@task(3)defget_view_detail(self):print('get_view_detail')@task(1)defcreate_forum(self):print('create_forum')@task(1)defstop(self):print('exit forum page')
self.interrupt()@task(1)defget_info(self):print('get info')
from locust import HttpUser, TaskSet, task, between
classForumThread(TaskSet):passclassForumPage(TaskSet):# wait_time can be overridden for individual TaskSets
wait_time = between(10,300)# TaskSets can be nested multiple levels
tasks ={
ForumThread:3}@task(3)defforum_index(self):pass@task(1)defstop(self):
self.interrupt()classAboutPage(TaskSet):passclassWebsiteUser(HttpUser):
wait_time = between(5,15)# We can specify sub TaskSets using the tasks dict
tasks ={
ForumPage:20,
AboutPage:10,}# We can use the @task decorator as well as the # tasks dict in the same Locust/TaskSet@task(10)defindex(self):pass
关于 TaskSet 需要特别注意的是,它们永远不会停止执行其任务,需要手动调用该
TaskSet.interrupt()
方法来停止执行。
在上面的案例一中,如果没有stop方法,那么一旦用户进入了get_forum_page之后,就无法从此类中跳出来了,只会执行get_forum_page下的task。
脚本编写
案例1:
百度搜索流量比较大,现在想针对百度的搜索接口进行压测,如何写压测脚本呢?
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time:2022/3/27 5:15 下午# @Author:boyizhangimport random
from locust import TaskSet, task, FastHttpUser, HttpUser,run_single_user
from locust.clients import ResponseContextManager
from locust.runners import logger
classBaiduTask(TaskSet):@taskdefsearch_by_baidu(self):
wd = random.choice(self.user.share_data)
path =f"/s?wd={wd}"with self.client.get(path,catch_response=True)as res:# 如果想同一接口不同参数放在同一组,可用下面这种方式# with self.client.get(path,catch_response=True,name="/s?wd=[wd]") as res:
res: ResponseContextManager
# 如果不满足,则标记为failureif res.status_code !=200:
res.failure(res.text)defon_start(self):
logger.info('hello')defon_stop(self):
logger.info('goodbye')classBaidu(HttpUser):
host ='https://www.baidu.com'
tasks =[BaiduTask,]
share_data =['波小艺','boxiaoyi','性能测试','locust']if __name__ =='__main__':
run_single_user(Baidu)
在案例当中,通过在HttpUser的子类中定义一个列表share_data,在执行任务集时,可以随机选取列表share_data中的一个元素作为接口入参。
脚本执行
揭开了Locust的第一层神秘的面纱后:脚本结构介绍,下面继续结合案例讲下Locust的执行。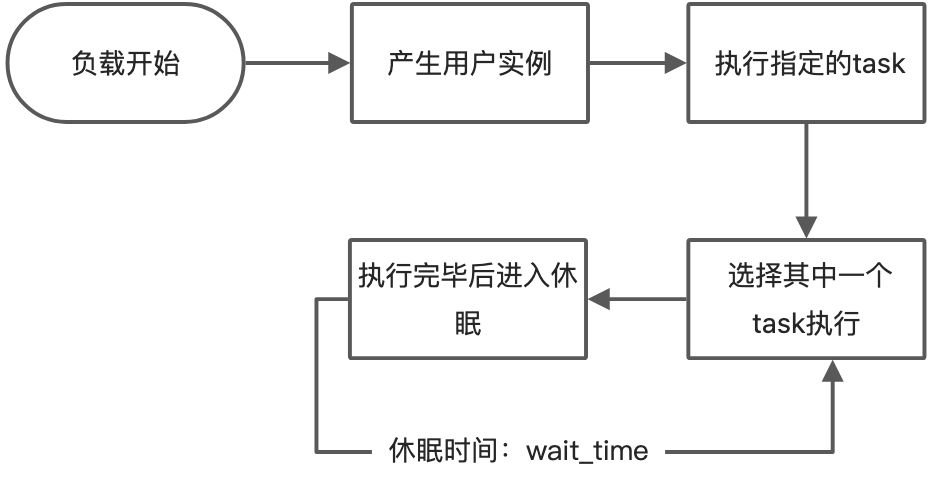
负载测试启动时,会按照用户定义的
Number of users
以及
Spawn rate
生成用户实例。
- 用户实例执行指定的TaskSet
- 用户实例将选中
TaskSet的任务之一去执行 - 执行完毕之后线程使用户处于休眠并持续指定时间(用户定义的
wait_time) - 休眠结束之后,再从
TaskSet的任务中选择一个新任务执行 - 再次等待,依此类推。
以上就是Locust大致的执行流程。
执行方式
命令行执行
可以通过
locust -h
查看Locust的命令行参数。也可以通过查看:Locust命令行参数解析 获取具体用法。
$ locust -f example.py --headless --users 10 --spawn-rate 1 -H http://www.boxiaoyi.com -t 300s
- -f: 指定执行的Locust脚本
- –headless:禁用 Web 界面(使用终端)),并立即开始测试。使用 -u 和 -t 控制用户数和运行时间
- -u/–users:并发 Locust 用户的峰值数量。主要
--headless或--autostart一起使用。可以在测试期间通过键盘输入 w、W(生成 1、10 个用户)和 s、S(停止 1、10 个用户)来更改 - -r/–spawn-rate:以(每秒用户数)生成用户的速率。主要与
-–headless或-–autostart一起使用 - -t/–run_time:在指定的时间后停止,例如(300s、20m、3h、1h30m 等)。仅与
--headless或--autostart一起使用。默认永远运行。 - –autostart: 立即开始测试(不禁用 Web UI)。使用 -u 和 -t 控制用户数和运行时间。可同时使用终端以及web ui页面观察
由于命令行执行的支持,加上参数的支持,可以进行集成到CI/CD的流程当中,不过有一点需要注意的是,需要指定
--run_time
,否则将无法自动退出该流程。
web ui界面执行
$ locust -f example.py
启动 Locust 后,打开浏览器并将其指向 http://localhost:8089。会展示以下页面: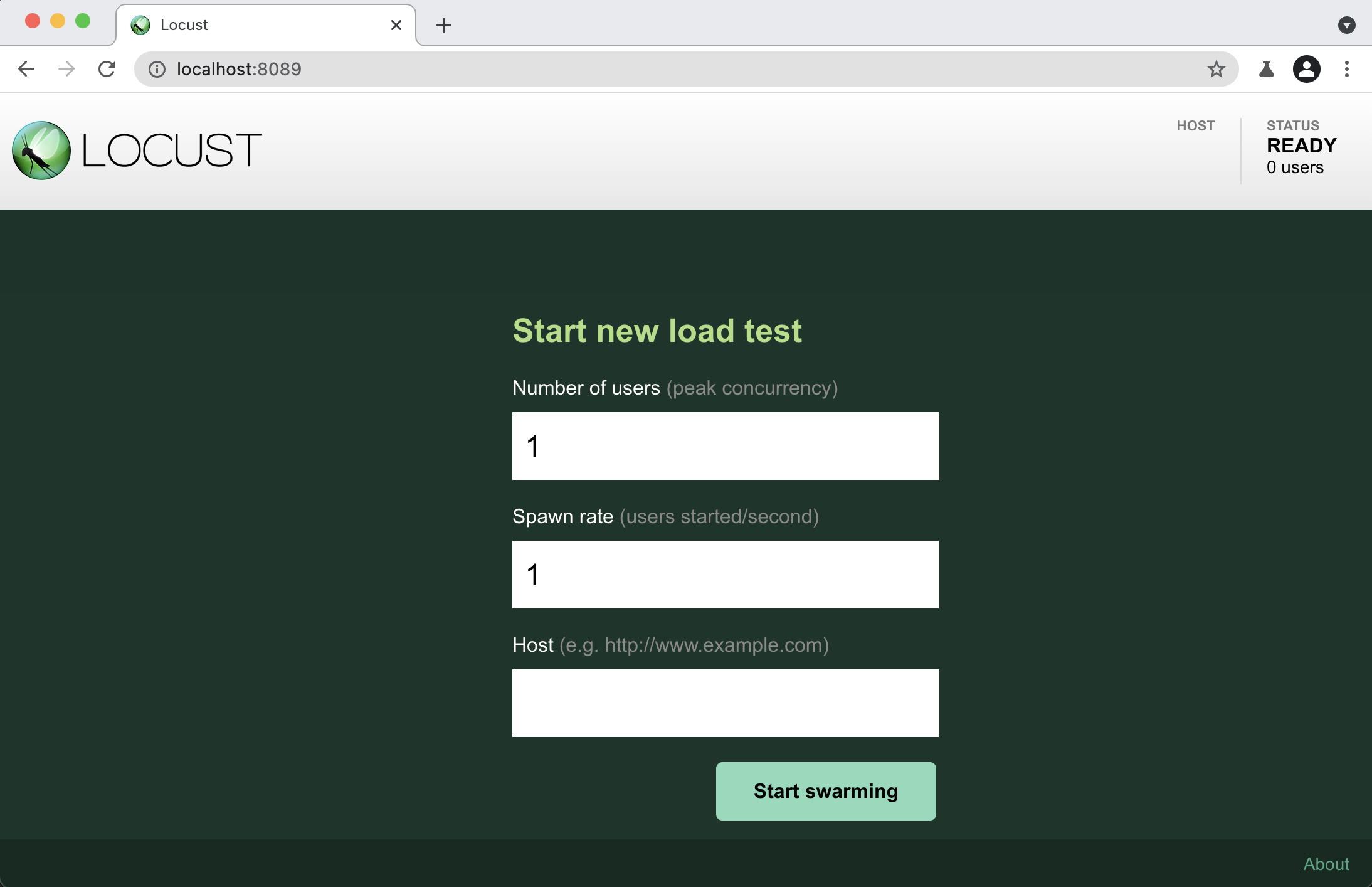
点击start swarming,即可开始负载测试。
执行策略
单机执行
分布式执行
运行 Locust 的单个进程可以模拟相当高的吞吐量。对于一个简单的测试计划,它应该能够每秒发出数百个请求,如果使用FastHttpUser则数千个。但是如果你的测试计划很复杂或者你想运行更多的负载,你就需要扩展到多个进程,甚至可能是多台机器。
我们可以使用
--master
标志Master启动一个Locust实例,并使用
--worker
标志Worker启动多个工作实例。
- 如果worker进程与master进程在同一台机器上,建议worker的数量不要超过机器的CPU核数。一旦超过,发压效果可能不增反减。
- 如果worker进程与master进程不在同一台机器上,可以使用
--master-host将它们指向运行master进程的机器的IP/主机名。 - 在Locust在执行分布式时,master和worker机器实例上一定要有locusfile的副本。
- master实例运行Locust的Web界面,并告诉workers何时产生/停止用户。worker运行用户并将统计数据发送回master实例。master实例本身不运行任何用户。
注意点
- 因为Python不能完全利用每个进程一个以上的内核(参见GIL),所以通常应该在Worker机器上为每个处理器内核运行一个Worker实例,以便利用它们的所有计算能力。
- 对于每个Worker实例可以运行的用户数量几乎没有限制。只要用户的总请求率/RPS不太高,Locust/gevent就可以在每个进程中运行数千甚至数万个用户。
- 如果Locust即将耗尽CPU资源,它将记录一个警告。
如何使用分布式?
- 开启Master实例:
locust -f my_locustfile.py --master
- 然后在每个Worker上(xxx为master实例的IP,或者如果您的Worker与主计算机在同一台计算机上,则完全省略该参数):
locust -f my_locustfile.py --worker --master-host=xxx
其他参数:
- –master:将 locust 设置为 master 模式。Web 界面将在此节点上运行。
- –worker:将蝗虫设置为worker模式。
- –master-host=X.X.X.X:可选择与–worker设置master节点的主机名/IP 一起使用(默认为 127.0.0.1)
- –master-port=5557:可选地与–worker设置master节点的端口号一起使用(默认为 5557)。
- –master-bind-host=X.X.X.X:可选地与–master. 确定master节点将绑定到的网络接口。默认为 *(所有可用接口)。
- –master-bind-port=5557:可选地与–master. 确定master节点将侦听的网络端口。默认为 5557。
- –expect-workers=X:在使用 启动主节点时使用–headless。然后,主节点将等待 X 个worker节点连接,然后再开始测试。
使用docker执行分布式
version:'3'services:master:image: locustio/locust
ports:- 8089:8089- 5557:5557volumes:- ./:/myexample
command:-f /myexample/locustfile.py WebsiteUser --master -H http://www.baidu.com
worker:image: locustio/locust
links:- master
volumes:- ./:/myexample
command:-f /myexample/locustfile.py WebsiteUser --worker --master-port=5557
启动
$ docker-compose -d -f myexample/run_locust_by_docker.yml up --scale worker=3
结果分析
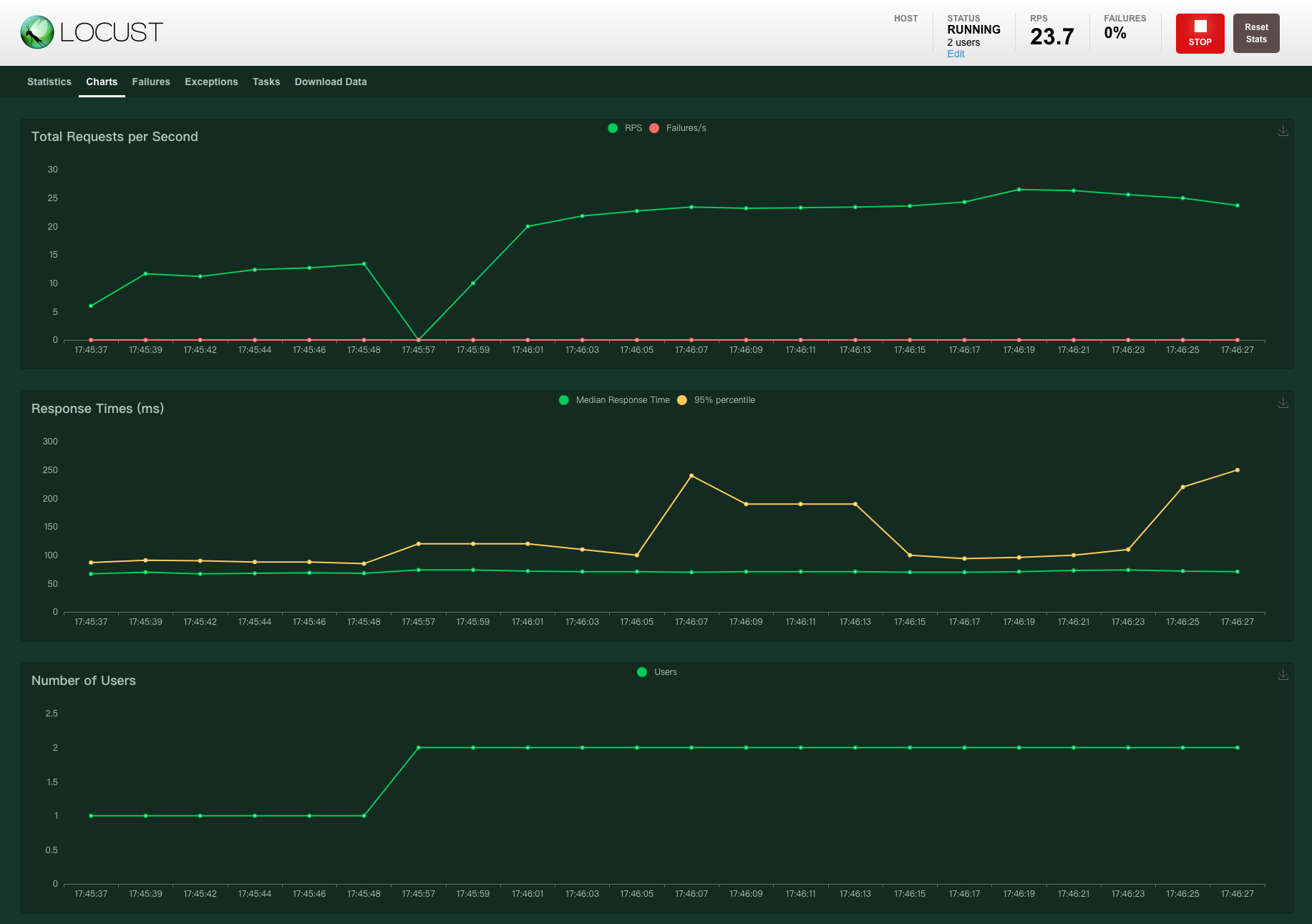
Locust在执行测试的过程中,我们可以在web界面中实时地看到结果运行情况。主要展示了以下指标:并发数、RPS、失败率、响应时间 latency,另外还展示了部分指标的趋势图,如案例1-图3。
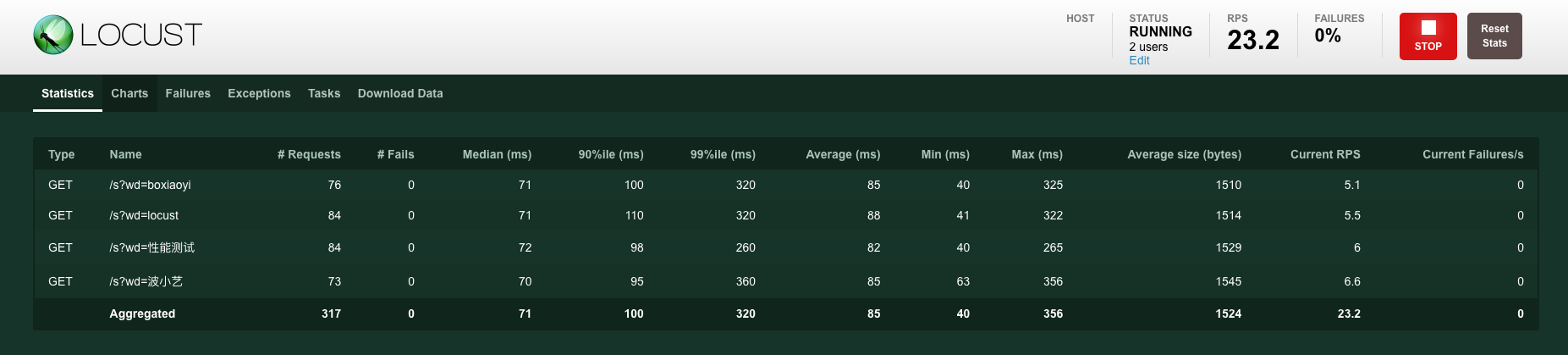
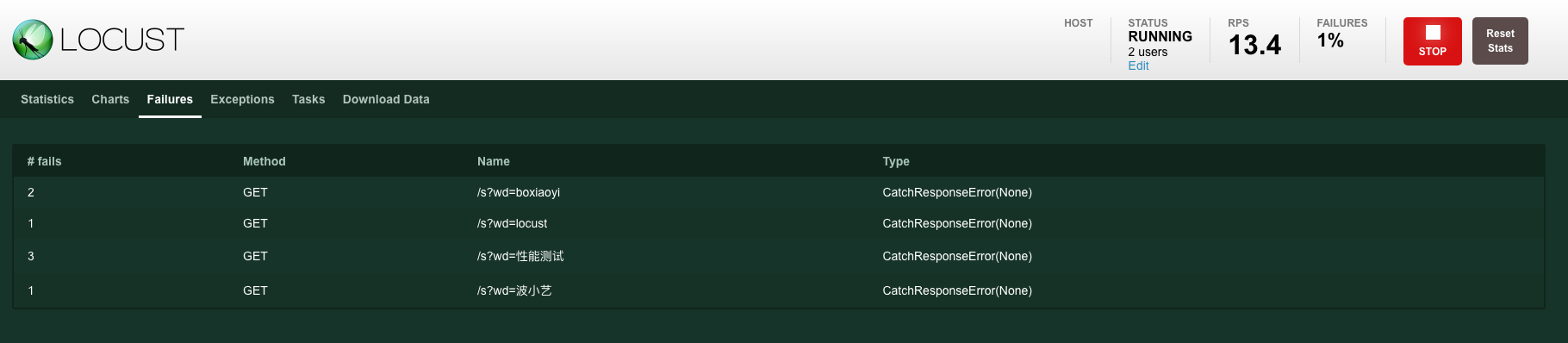
版权归原作者 波小艺 所有, 如有侵权,请联系我们删除。