
前言
哈希表是一种被广泛应用在多种编程思想的数据结构,在Java中哈希结构被应用在集合等的编写中
我们熟知的LinkedHashset还有** HashMap、LinkedHashMap、HashTable**中,它们的底层都使用了 哈希表。那么通过这段时间的学习,我自己对哈希表进行简单的总结和叙述,避免以后忘记。
一、哈希表是什么?
在前言中,我简单的说了哈希数据结构被广泛的使用,那么它的实现究竟是怎样的。哈希表就是它的思想体现,首先,我通过查询对比大致这样介绍的,**散列表(Hash table,也叫哈希表)**,是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。这种介绍不是针对java语言来介绍的而是通过数学思想介绍,相对的准确。Java也是这样去实现的哈希表,但是并不好理解。在学习中老师通过源码为我们总结了比较简单的理解方式,下面是我对哈希表学习的总结,
二、在Java中Hash表的实现
1.知识引入
首先,我们以HashSet集合对哈希表的源码作为引子,去了解底层的路线。那我们首先应该知道,在java中set集合的一些特性
Set接口:
特点:1.没有索引值2.不能重复HashSet:无序:新增顺序和取出顺序不一定一致
底层:哈希表(HashSet底层其实是HashMap)
import java.util.HashSet;
import java.util.Set;
public class Test03 {
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(5);
set.add(5);
set.add(5);
System.out.println(set.size());
}
}
执行结果
1
3.跟踪源码
** 那么看到上面代码的执行结果,我们就应该想一下,底层哈希表是怎么处理相同元素存储去重操作的,(根据断点Debug过程就不再叙述,我将我们要说的哈希表的源码去重操作部分展示)将断点打在第二个添加操作上,F5执行。我们可以看到过程会进过这几行底层的源码**
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
//计算哈希值
if ((tab = table) == null || (n = tab.length) == 0)
//判断数组中该位置是否为空,或者数组长度不足,
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//重点***查重主要就在这边,判断该位置的元素和要添加的元素的哈希值是否相同,并且该位置的元素是否地址相同,或者该位置的元素和要添加的元素值是否相同
4.总结描述
**从这里我们可以简单的对哈希表添加元素过程和无序做叙述,**
新增过程:
a.计算新增元素的哈希值b.(假设数组已经创建出来),通过 hash%数组长度c.如果该位置为null:则直接新增如果该位置不为null:c1.判断该元素是否重复:c11.如果不重复,则新增到该索引值位置链表的最后面c12.如果重复:则不新增无序,因为哈希值的计算有各种可能,通过哈希值进行确定元素添加的位置,因此元素存储的无序性就不奇怪了
特殊的: String覆盖重写了HashCode方法,只要内容相同,哈希值一定相同。
三、扩容规则的叙述
1.文字叙述
上面是有关哈希表新增过程的简单叙述,哈希表在新增过程中它的扩容规则又是怎样的?
在JDK1.8之前:哈希表底层实现是数组+链表,在JDK1.8之后:底层实现是数组+链表/红黑树,(是指在未达到一定条件时它的底层运转依旧是数组+链表)那么这个条件是什么,有这么几条总结,
1.当同一索引值下元素个数>8,并且数组长度<64
2.数组的索引值占有率75%
扩容后的新容量 = 旧容量<<1 (也就是扩容后的新容量是旧容量的二倍)
在哈希表中,通过链表来存储数据,通过数组记录索引值,设置每个索引之下不得多余8个元素,否则就要进行扩容或者转换为红黑树
2.图例介绍
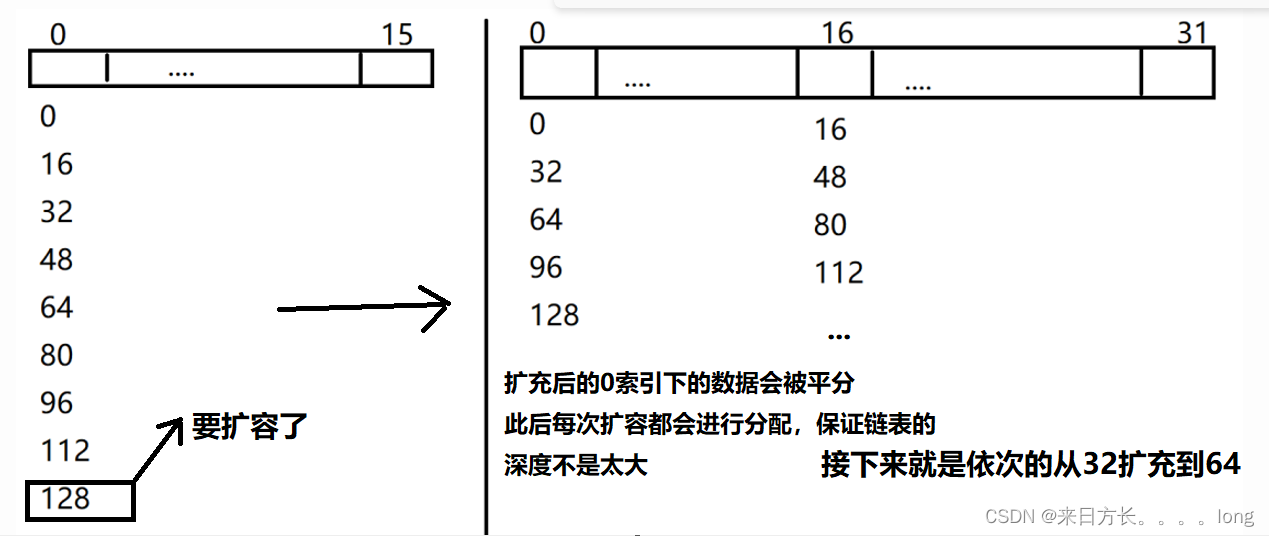
转化为树的条件是
当同一索引值下元素个数>8,并且数组长度>=64的时候,就回将链表转化为红黑树,就是上面的图扩容到64后,下标为0的索引下元素大于8个时。此处就不再附图了。
扩容中的加载因子,可以手动的调整,但是一般不建议调整
总结:
到这里就是我对哈希值的一些简单的叙述,新增过程:
a.计算新增元素的哈希值b.(假设数组已经创建出来),通过 hash%数组长度c.如果该位置为null:则直接新增如果该位置不为null:c1.判断该元素是否重复:c11.如果不重复,则新增到该索引值位置链表的最后面c12.如果重复:则不新增
扩容规则
1.当同一索引值下元素个数>8,并且数组长度<64
2.数组的索引值占有率75%
当同一索引值下元素个数>8,并且数组长度>=64,将链表转化为红黑树
版权归原作者 来日方长。。。。long 所有, 如有侵权,请联系我们删除。