
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:目标检测系列——开山之作RCNN原理详解
🍊近期目标:拥有10000粉丝
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
文章目录
目标检测系列——Fast R-CNN原理详解
写在前面
在上一篇,我们介绍过RCNN的原理,详情戳☞☞☞了解🌱🌱🌱这里再来简要概述一下RCNN的算法步骤:
- 候选区域生成
- 神经网络提取特征
- SVM分类器分类
- 回归器修正候选框位置
继RCNN发布后,RGB大神又发表了Fast R-CNN🍍🍍🍍先来看看论文中表示Fast R-CNN结果的图片,如下:
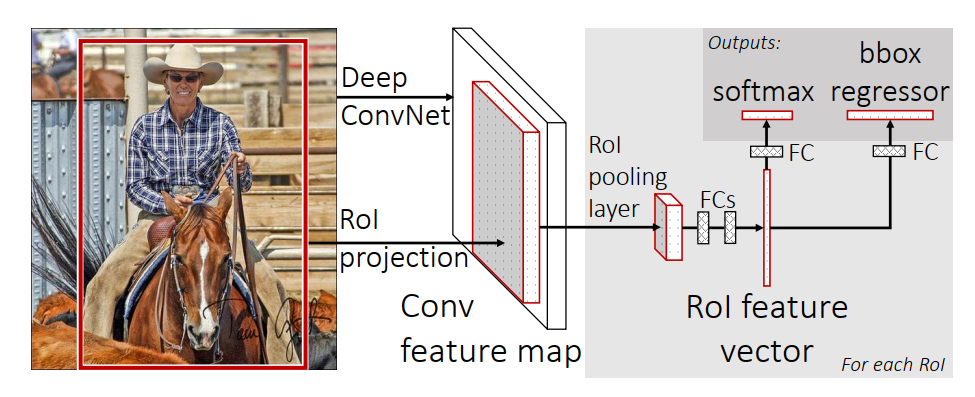
关于这张经典的图片,现在大家只要又一个直观的感受即可,后面会深度解析。此篇文章较RCNN有了较大提示,Fast R-CNN其主要步骤如下:
- 候选区域生成
- 完整图像输入网络,候选框投影到特征图得到特征矩阵
- 特征矩阵经ROI pooling层缩放至统一大小,后将特征图展平得到预测结果
可以看到,仅从RCNN和Fast R-CNN的步骤来看,它们还是存在一些差异的,下面将会具体谈谈这些步骤的具体细节,一起来看看吧🍀🍀🍀
候选区域生成
候选区域生成和R-CNN没有区别,同样采用的是SS算法,这里就不重复介绍了,不清楚的可以参考上篇R-CCN博文🍂🍂🍂
完整图像输入网络,候选框投影到特征图得到特征矩阵
还记得在R-CNN中我们输入网络的是什么嘛?这里就不卖关子了,在R-CNN中我们输人的是经SS算法得到的2000个候选框,这显然需要巨大的计算量;而在Fast R-CNN中,我们仅需要将原始图像输入到特征提取网络中得到原始图像的特征图即可。🌼🌼🌼这里你或许存在这样的问题:既然输入网络的是原始图像,那第一步在原始图像中生成的候选框该怎么利用呢?其实这一部分是借鉴了何凯明的SPP-Net——原始图像中的某个候选框经过神经网络后会映射到所得特征图的相应位置,这个位置是可计算的。为方便大家理解,我画了下图供大家参考:
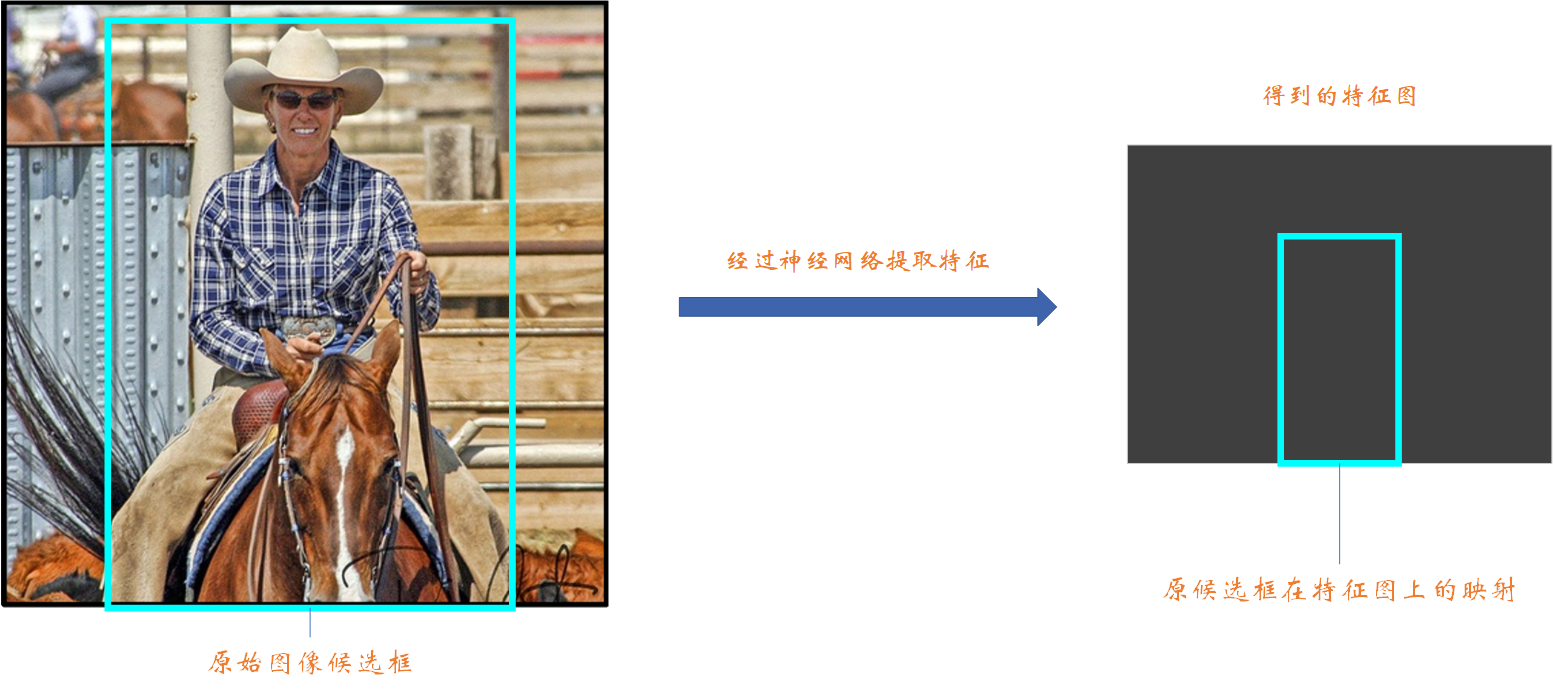
关于上述的映射规则,大家可以参考这篇博文:SPP-net 🍉🍉🍉
特征矩阵经ROI pooling层缩放至统一大小,后将特征图展平得到预测结果
在Fast R-CNN中,我们没有像R-CNN中一样对图片进行强制缩放,而是我们在得到特征图上的映射后(也即候选框),将这些候选框进行ROI pooling操作将不同大小的候选框统一缩放至统一的大小,ROI pooling的操作如下图所示:即不论原始特征图大小如何,我们都先将特征图分成77=49等份,然后每一份采用最大池化或平均池化,将原特征图下采样成77统一大小。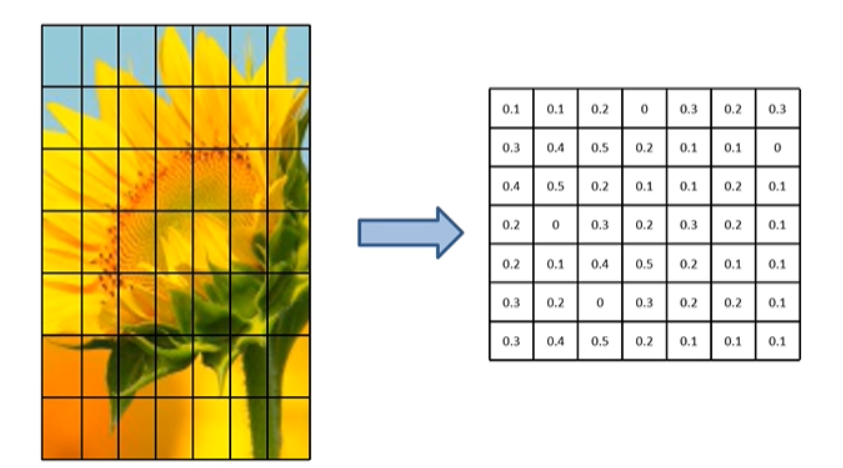
特征图变成统一尺寸后,就可以将其展平送入全连接层了,之后再接上softmax层和regressor层即可输出。
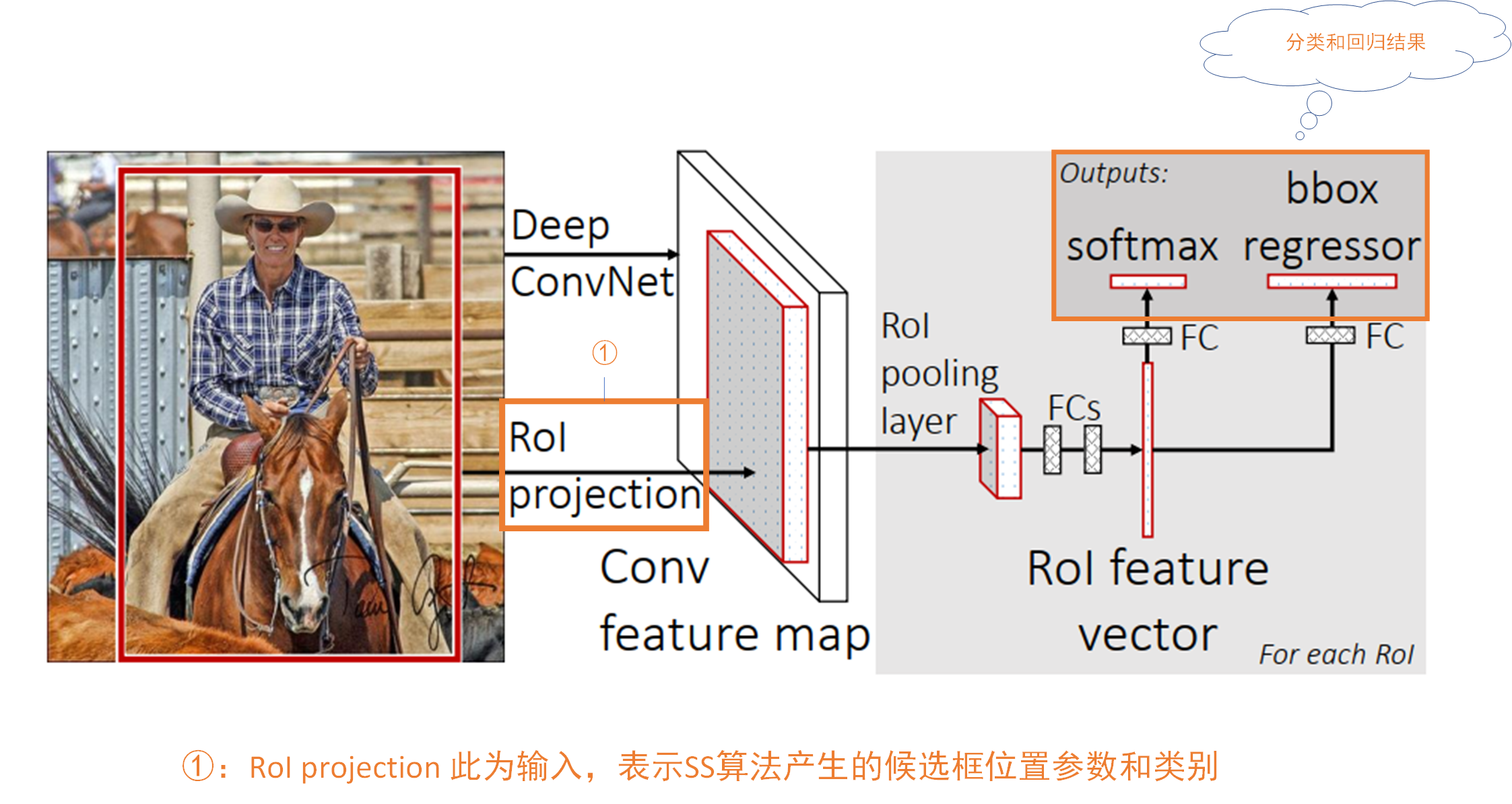
Fast R-CNN完整流程
通过上文的讲述,现在相信大家再看这个图会更加深刻。大致过程和上文所述一致,这里不在叙述🌵🌵🌵
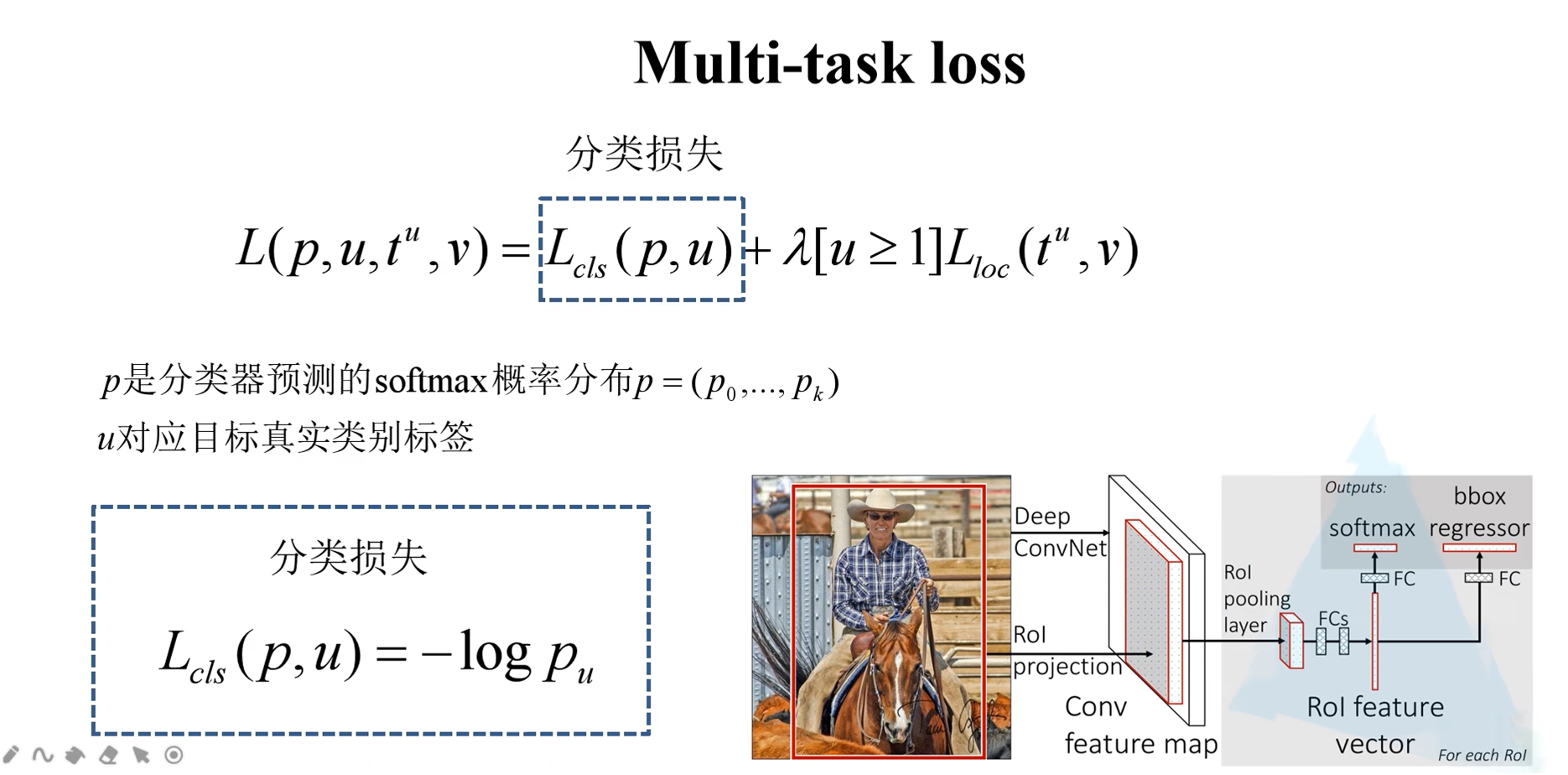
损失函数
损失函数共有两部分组成,一部分是分类损失,一部分是边界框回归损失。

小结
Fast R-CNN的原理部分就介绍到这里了,希望可以对大家有所帮助。🍀🍀🍀后续会更新Faster_RCNN的内容以及相关代码讲解,一起加油吧!!!
参考链接
RCNN理论合集🍁🍁🍁
深度学习_FasterRCNN论文详解🍁🍁🍁
如若文章对你有所帮助,那就🛴🛴🛴
咻咻咻咻
duang点个赞呗
对人工智能感兴趣的可以扫码加入C站人工智能官方社群,欢迎各位小伙伴加入交流学习,一起进步!!
版权归原作者 秃头小苏 所有, 如有侵权,请联系我们删除。