
文章目录
ps:如果没有标注root的,全部使用hadoop用户进行安装
一、基础环境&插件安装(root)
- 可以直接下载我这边上传的相关包,包括搭建过程中的一些缺失包、在线yum源的一些tpm包以及ranger编译后的包。hadoop的一些基础包这边就不上传了。比如hadoop包,因为太大了,这边有提供了下载地址,可自行下载。
- 创建文件夹并上传需要的rpm包:mkdir /opt/rpm
- 安装:rpm -Uvh --force --nodeps *.rpm
- 所有的rpm包都是后续yum源下载的包,如果有遗漏的,可以直接使用yum源下载,如果是无网络线上环境可以参照https://blog.csdn.net/weixin_40496191/article/details/124508488进行无网络rpm安装
- 关闭防火墙1)systemctl stop firewalld2)systemctl disable firewalld.service
- 新建用户:useradd hadoop
- 设置密码:passwd hadoop -->ffcsict123
- 切换hadoop用户
- 在/home/hadoop 目录下创建 module 和 software 文件夹(software 用于存放软件安装包,而 module 用于存放解压后的文件包)1)mkdir /home/hadoop/module2)mkdir /home/hadoop/software
- 修改 module、software 文件夹的所属主和所属组均为 hadoop用户
chown hadoop:hadoop /home/hadoop/modulechown hadoop:hadoop /home/hadoop/software
- 查看 module、software 文件夹的所有者和所属组:ll
二、创建启动脚本,后续使用
- journalnode脚本:vi /home/hadoop/journalnode.shchmod u+x /home/hadoop/journalnode.sh
if[ $# -lt 1] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 journalnode 集群 ===================" echo " --------------- 启动 node10 ---------------" ssh node10 "/home/hadoop/module/hadoop-3.2.2/sbin/hadoop-daemon.sh start journalnode" echo " --------------- 启动 node11 ---------------" ssh node11 "/home/hadoop/module/hadoop-3.2.2/sbin/hadoop-daemon.sh start journalnode" echo " --------------- 启动 node12 ---------------" ssh node12 "/home/hadoop/module/hadoop-3.2.2/sbin/hadoop-daemon.sh start journalnode";;"stop") echo " =================== 关闭 journalnode 集群 ===================" echo " --------------- 关闭 node10 ---------------" ssh node10 "/home/hadoop/module/hadoop-3.2.2/sbin/hadoop-daemon.sh stop journalnode" echo " --------------- 关闭 node11 ---------------" ssh node11 "/home/hadoop/module/hadoop-3.2.2/sbin/hadoop-daemon.sh stop journalnode" echo " --------------- 关闭 node12 ---------------" ssh node12 "/home/hadoop/module/hadoop-3.2.2/sbin/hadoop-daemon.sh stop journalnode";;*) echo "Input Args Error...";; esac - hadoop脚本:vi /home/hadoop/hadoop.shchmod u+x /home/hadoop/hadoop.sh
#!/bin/bash if[ $# -lt 1] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop 集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh node10 "/home/hadoop/module/hadoop-3.2.2/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh node11 "/home/hadoop/module/hadoop-3.2.2/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh node10 "/home/hadoop/module/hadoop-3.2.2/bin/mapred --daemon start historyserver";;"stop") echo " =================== 关闭 hadoop 集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh node10 "/home/hadoop/module/hadoop-3.2.2/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh node11 "/home/hadoop/module/hadoop-3.2.2/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh node10 "/home/hadoop/module/hadoop-3.2.2/sbin/stop-dfs.sh";;*) echo "Input Args Error...";; esac - zookeeper脚本:vi /home/hadoop/zookeeper.shchmod u+x /home/hadoop/zookeeper.sh
#!/bin/bash if[ $# -lt 1] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 node10 ===================" ssh node10 "/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh start" echo " =================== 启动 node11 ===================" ssh node11 "/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh start" echo " =================== 启动 node12 ===================" ssh node12 "/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh start";;"stop") echo " =================== 关闭 node10 ===================" ssh node10 "/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh stop" echo " =================== 关闭 node11 ===================" ssh node11 "/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh stop" echo " =================== 关闭 node12 ===================" ssh node12 "/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh stop";;*) echo "Input Args Error...";; esac - hbase脚本:vi /home/hadoop/hbase.shchmod u+x /home/hadoop/hbase.sh
#!/bin/bashif[ $# -lt 1]then echo "No Args Input..." exit ;ficase $1 in"start") echo " =================== 启动hbaes集群 ===================" cd /home/hadoop/hbase/hbase-2.1.0/bin ./start-hbase.sh;;"stop") echo " =================== 关闭hbase集群 ===================" cd /home/hadoop/hbase/hbase-2.1.0/bin ./stop-hbase.sh;;*) echo "Input Args Error...";;esac
三、安装JDK(root)
- 上传jdk-8u291-linux-x64.tar.gz包到linux服务
- 解压jdk:tar -xvf jdk-8u291-linux-x64.tar.gz
- 配置jdk环境变量:vi /etc/profile,在最后加上以下几行
JAVA_HOME=/opt/jdk/jdk1.8.0_291PATH=$PATH:$JAVA_HOME/binCLASSPATH=:$JAVA_HOME/libexport JAVA_HOMEPATHCLASSPATH - 重新导入环境变量配置:source /etc/profile
- 检查JDK是否安装成功,能看到相关版本信息即安装成功:java -version

四、安装Hadoop
- 下载hadoop-3.2.2.tar.gz:http://archive.apache.org/dist/hadoop/core/
- 上传至/home/hadoop/module
- 解压:tar -xvf hadoop-3.2.2.tar.gz
- 配置hadoop环境变量(使用root用户修改):vi /etc/profile,在最后加上以下几行```export HADOOP_HOME=/home/hadoop/module/hadoop-3.2.2export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbinexport HADOOP_CLASSPATH=`hadoop classpath````
- 重新导入环境变量配置(使用root、hadoop分别刷新):source /etc/profile
- 查看版本,看看是否成功:hadoop version

五、安装 rsync(root)
- 安装:忽略,第一步已经rpm安装
- 启动 rsync 并设置开机自启:
systemctl start rsyncd.servicesystemctl enable rsyncd.service - 修改配置文件:vi /etc/rsyncd.conf
# 运行RSYNC守护进程的用户uid = hadoop# 运行RSYNC守护进程的组gid = hadoop#不使用chrootuse chroot = no# 最大连接数为4max connections =4# CentOS7中yum安装不需指定pid file 否则报错# pid file =/var/run/rsyncd.pid# 指定锁文件lock file=/var/run/rsyncd.lock# 指定日志文件log file =/var/log/rsyncd.logexclude = lost+found/transfer logging = yes# 超时时间timeout =900# 同步时跳过没有权限的目录ignore nonreadable = yes# 传输时不压缩的文件dont compress =*.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2 - 重启rsync: systemctl restart rsyncd.service
六、网络配置(4台服务器,root)
- 克隆三台机子
- 主机名和IP分配(根据自己的需求分配)主机名node10node11node12node13IP地址192.168.248.10192.168.248.11192.168.248.12192.168.248.13
- 修改 UUID 和 IP地址:vi /etc/sysconfig/network-scripts/ifcfg-ens33ps:可通过uuidgen获取UUID
TYPE=EthernetPROXY_METHOD=noneBROWSER_ONLY=yesNAME=ens33UUID=91f1d9bd-946d-42da-a54f-76ac44cc965cDEVICE=ens33ONBOOT=yesIPADDR=192.168.248.10GATEWAY=192.168.248.254NETMAST=255.255.255.0DNS1=8.8.8.8ZONE=public - 修改主机名:vi /etc/hostname(每台都要)
- 修改主机名称映射文件(hosts):vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.248.10 node10192.168.248.11 node11192.168.248.12 node12192.168.248.13 node13 - 重置网络:service network restart
七、rsync脚本配置(root)
- mkdir /home/hadoop/rsync
- vi /home/hadoop/rsync/xsync
- 赋予xsync脚本可执行权限:chmod u+x /home/hadoop/rsync/xsync
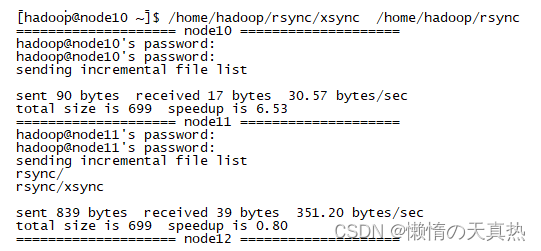
- 测试xsync:/home/hadoop/rsync/xsync /home/hadoop/rsync
八、免密登录配置(4台服务器)
- 生成公钥和私钥:ssh-keygen -t rsa直接一直回车即可
- 将公钥拷贝至本机以及其他节点中ffcsict1231)ssh-copy-id node102)ssh-copy-id node113)ssh-copy-id node124)ssh-copy-id node13
- 测试:ssh node12
九、zk集群搭建(10、11、12)
zookeeper下载:https://zookeeper.apache.org/releases.html#download
- 创建文件夹:mkdir /home/hadoop/zookeeper
- 进入目录:cd /home/hadoop/zookeeper
- 上传安装包:apache-zookeeper-3.6.3-bin.tar.gz
- 解压:tar -xvf apache-zookeeper-3.6.3-bin.tar.gz
- 创建zookeeper数据文件夹:mkdir /home/hadoop/zookeeper/tmp(自定义)
- 进入配置文件目录:cd /home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/conf
- 将“zoo_sample.cfg”重命名为“zoo.cfg”,并打开配置:mv zoo_sample.cfg zoo.cfg4.1 打开zoo.cfg,修改数据文件夹地址:dataDir=/home/hadoop/zookeeper/tmp4.2 打开zoo.cfg,如果需要变更zookeeper端口号,可修改:clientPort=端口号,默认21814.3 打开zoo.cfg,修改8080端口:admin.serverPort=8888(无用端口)4.4 打开zoo.cfg,添加集群配置
#ip+数据同步+通信端口,保证zookeeper、数据同步、通信端口三个端口不同server.1=0.0.0.0:2888:3888server.2=192.168.248.11:2888:3888server.3=192.168.248.12:2888:3888``````#ip+数据同步+通信端口,保证zookeeper、数据同步、通信端口三个端口不同server.1=192.168.248.10:2888:3888server.2=192.168.248.11:2888:3888server.3=192.168.248.12:2888:3888 - 修改配置文件:vi /home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkEnv.sh首行添加JAVA_HOME路径的申明
JAVA_HOME=/opt/jdk/jdk1.8.0_291 - 进入zookeeper数据文件目录:cd /home/hadoop/zookeeper/tmp
- 新建myid并且写入对应的myid,myid为第7步对应的数字(server.数字)
服务器192.168.248.10:echo 1> myid
服务器192.168.248.11:echo 2> myid
服务器192.168.248.12:echo 3> myid
- 启动zookeeper脚本:cd /home/hadoop --> ./zookeeper.sh start
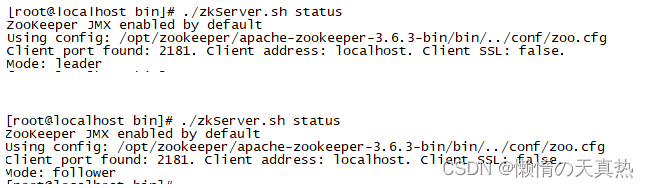
- 查看主从状态:/home/hadoop/zookeeper/apache-zookeeper-3.6.3-bin/bin/zkServer.sh status
十、hadoop集群配置(4台服务器)
- 节点功能ps:NameNode、SecondaryNameNod和ResourceManage很耗内存资源,建议不要配置在同一节点上node10node11node12node13HDFSNameNodeNameNodeDataNodeDataNodeYARNResourceManagerResourceManagerNodeManagerNodeManagerhbaseHMasterHMaster、HRegionServerHRegionServerHRegionServerhivehivemysqlmysqlzookeeperzookeeperzookeeperzookeeper
- 修改核心配置文件:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/core-site.xml在中间添加配置
<!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/home/hadoop/module/hadoop-3.2.2/data</value></property><!-- 配置 HDFS 网页登录使用的静态用户为 hadoop --><property><name>hadoop.http.staticuser.user</name><value>hadoop</value></property><!-- 考虑配置,整合hive 用户代理设置 --><property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property><property><name>ha.zookeeper.quorum</name><value>node10:2181,node11:2181,node12:2181</value></property><property><name>ha.zookeeper.session-timeout.ms</name><value>10000</value></property> - 修改HDFS配置文件:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/hdfs-site.xml在标签中添加配置
<!-- 副本数dfs.replication默认值3,可不配置 --><property><name>dfs.replication</name><value>3</value></property><!-- 节点数据存储地址 --><property><name>dfs.namenode.name.dir</name><value>/home/hadoop/module/hadoop-3.2.2/namenode/data</value></property><property><name>dfs.datanode.data.dir</name><value>/home/hadoop/module/hadoop-3.2.2/datanode/data</value></property><!-- 主备配置 --><!-- 为namenode集群定义一个services name --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 声明集群有几个namenode节点 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- 指定 RPC通信地址 的地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node10:8020</value></property><!-- 指定 RPC通信地址 的地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node11:8020</value></property><!-- http通信地址 web端访问地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node10:50070</value></property><!-- http通信地址 web 端访问地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node11:50070</value></property><!-- 声明journalnode集群服务器 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node10:8485;node11:8485;node12:8485/mycluster</value></property><!-- 声明journalnode服务器数据存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>/home/hadoop/module/hadoop-3.2.2/journalnode/data</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 隔离:同一时刻只能有一台服务器对外响应 --><property><name>dfs.ha.fencing.methods</name><value> sshfence shell(/bin/true)</value></property><!-- 配置失败自动切换实现方式,通过ConfiguredFailoverProxyProvider这个类实现自动切换 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 指定上述选项ssh通讯使用的密钥文件在系统中的位置。 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间(active坏了之后,standby如果没有在30秒之内未连接上,那么standby将变成active) --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property><!-- 开启hdfs允许创建目录的权限,配置hdfs-site.xml --><property><name>dfs.permissions.enabled</name><value>false</value></property><!-- 使用host+hostName的配置方式 --><property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property> - 修改YARN配置文件:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/yarn-site.xml根据虚拟机内存进行设置,参照:https://blog.csdn.net/u010452388/article/details/98234147在标签中添加配置```<property><name>yarn.nodemanager.resource.cpu-vcores</name><value>12</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>10240</value></property><property><name>yarn.log.server.url</name><value>http://node10:19888/jobhistory/logs</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>my-yarn-cluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>node10</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node11</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node10:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node11:8088</value></property><property><name>yarn.resourcemanager.zk-address</name><value>node10:2181,node11:2181,node12:2181</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><property><name>mapred.child.java.opts</name><value>-Xmx1024m</value></property><property><name>yarn.resourcemanager.address.rm1</name><value>node10:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>node10:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>node10:8031</value></property><property><name>yarn.resourcemanager.admin.address.rm1</name><value>node10:8033</value></property><property><name>yarn.nodemanager.address.rm1</name><value>node10:8041</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>node11:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>node11:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>node11:8031</value></property><property><name>yarn.resourcemanager.admin.address.rm2</name><value>node11:8033</value></property><property><name>yarn.nodemanager.address.rm2</name><value>node11:8041</value></property><property><name>yarn.nodemanager.localizer.address</name><value>0.0.0.0:8040</value></property><property><description>NMWebapp address.</description><name>yarn.nodemanager.webapp.address</name><value>0.0.0.0:8042</value></property><property><name>yarn.nodemanager.address</name><value>${yarn.resourcemanager.hostname}:8041</value></property><property><name>yarn.application.classpath</name><value>/home/hadoop/module/hadoop-3.2.2/etc/hadoop:/home/hadoop/module/hadoop-3.2.2/share/hadoop/common/lib/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/common/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/hdfs:/home/hadoop/module/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/hdfs/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/mapreduce/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/yarn:/home/hadoop/module/hadoop-3.2.2/share/hadoop/yarn/lib/*:/home/hadoop/module/hadoop-3.2.2/share/hadoop/yarn/*</value> </property> ```
- 修改MapReduce配置文件:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/mapred-site.xml在标签中添加如下配置
<!-- 指定 MapReduce 程序运行在 Yarn 上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>node10:10020</value></property><!-- 历史服务器 web 端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>node10:19888</value></property> - 修改workers配置文件,指定从节点信息:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/workersps:文件中添加的内容结尾不能有空格,文件中也不能有空行
node12node13 - 创建pid目录:mkdir /home/hadoop/module/hadoop-3.2.2/pids
- 添加用户配置:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/hadoop-env.sh,在最后添加
export HDFS_NAMENODE_USER=hadoop export HDFS_DATANODE_USER=hadoop export HDFS_SECONDARYNAMENODE_USER=hadoop export YARN_RESOURCEMANAGER_USER=hadoop export YARN_NODEMANAGER_USER=hadoop export JAVA_HOME=/opt/jdk/jdk1.8.0_291 export HADOOP_PID_DIR=/home/hadoop/module/hadoop-3.2.2/pids#以下内容暂时忽略,不用添加 #HDFS_DATANODE_SECURE_USER=hdfs#HADOOP_SECURE_DN_USER=yarn - vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/yarn-env.sh
export YARN_PID_DIR=/home/hadoop/module/hadoop-3.2.2/pids - vi /home/hadoop/module/hadoop-3.2.2/sbin/start-dfs.sh和stop-dfs.sh,在头部添加以下内容
HDFS_ZKFC_USER=hadoop
HDFS_JOURNALNODE_USER=hadoop
HDFS_NAMENODE_USER=hadoop
HDFS_SECONDARYNAMENODE_USER=hadoop
HDFS_DATANODE_USER=hadoop
HDFS_DATANODE_SECURE_USER=hadoop
#HADOOP_SECURE_DN_USER=hadoop
- vi /home/hadoop/module/hadoop-3.2.2/sbin/start-yarn.sh和stop-yarn.sh,在头部添加以下内容
#HADOOP_SECURE_DN_USER=hadoopHDFS_DATANODE_SECURE_USER=hadoopYARN_NODEMANAGER_USER=hadoopYARN_RESOURCEMANAGER_USER=hadoop - 分发到其他节点:xsync /home/hadoop/module/hadoop-3.2.2/etc/hadoop/
- 进入路径:cd /home/hadoop
- 启动Journalnode脚本:./journalnode.sh start
- 初始化NameNode(删除所有节点的/home/hadoop/module/hadoop-3.2.2/data和logs目录)1)cd /home/hadoop/module/hadoop-3.2.2/2)hdfs namenode -format
- 将初始化生成的数据拷贝到node11节点(dfs.namenode.name.dir属性):/home/hadoop/module/hadoop-3.2.2/namenodeps:如果是用root用户拷贝的,需要重新赋权 chown -R hadoop:hadoop /home/hadoopscp /opt/kerberos/$account.keytab root@node13:/opt/kerberos
- 在任意一台
NameNode上使用以下命令来初始化 ZooKeeper 中的 HA 状态:hdfs zkfc -formatZK - 创建文件夹:mkdir /tmp/logs
- 启动hadoop脚本:cd /home/hadoop -->./hadoop.sh start
- 赋权其他用户都能读: chmod -R 755 /home/hadoop/ 、chmod-R 700 ~/.
ssh/ - 遇到一些yarn切换active错误,如果是测试环境,可以考虑将tmp底下的yarn相关文件夹删除,重启即可
十一、hive搭建(10)
- 切换路径:cd /home/hadoop/module
- 下载hive:wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz --no-check-certificate
- 解压并且重命名:tar -zxvf apache-hive-3.1.2-bin.tar.gz -> mv apache-hive-3.1.2-bin hive
- 配置环境变量:vi /etc/profile ,最后一行后面加上以下内容
#添加下面两行export HIVE_HOME=/home/hadoop/module/hiveexport PATH=$PATH:$HIVE_HOME/bin重置环境变量:source /etc/profile - 将hadoop的lib中高版本的 /home/hadoop/module/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar包复制到/home/hadoop/module/hive/lib下,并删除hive下的低版本guava包
cp /home/hadoop/module/hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar /home/hadoop/module/hive/librm /home/hadoop/module/hive/lib/guava-19.0.jar - 安装mysql(在node12安装,建议跟后面的ranger安装在同一台服务器):https://blog.csdn.net/weixin_40496191/article/details/124358743
- 切回hadoop用户
- 拷贝core-site文件:cp /home/hadoop/module/hadoop-3.2.2/etc/hadoop/core-site.xml /home/hadoop/module/hive/conf
- 添加Hive核心配置,选择远程MySQL模式:vi /home/hadoop/module/hive/conf/hive-site.xml
<configuration><!-- mysql的主机地址 --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://node10:3306/hivedb?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT</value></property><!-- 固定写法,mysql驱动类的位置 --><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><!-- 修改为你自己的Mysql账号 --><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- 修改为你自己的Mysql密码 --><property><name>javax.jdo.option.ConnectionPassword</name><value>ffcsict123</value></property><!-- 忽略HIVE 元数据库版本的校验,如果非要校验就得进入MYSQL升级版本 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!-- 配置MetaStore端口 --><property><name>hive.metastore.port</name><value>9083</value><description>Hive metastore listener port</description></property><!-- 显示当前使用的数据库 --><property><name>hive.cli.print.current.db</name><value>true</value></property><!-- 显示当前表的列名 --><property><name>hive.cli.print.header</name><value>true</value></property><!-- 配置hiveserver2的端口 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><!-- 绑定到的TCP接口 --><property><name>hive.server2.thrift.bind.host</name><value>node10</value></property><!--设置用户名和密码--><property><name>hive.jdbc_passwd.auth.root</name><value>ffcsict123</value><description/></property><!--支持事务和行级更新--><property><name>hive.support.concurrency</name><value>true</value></property><!--启用分桶设置--><property><name>hive.enforce.bucketing</name><value>true</value></property><!--分区模式设置,动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区。nonstrict模式:表示允许所有的分区字段都可以使用动态分区。--><property><name>hive.exec.dynamic.partition.mode</name><value>nonstrict</value></property><!--hive的锁管理器,不能从一个非ACID会话向ACID表中读写数据--><property><name>hive.txn.manager</name><value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value></property><!--是否在metastore实例上运行initiator和cleaner进程。--><property><name>hive.compactor.initiator.on</name><value>true</value></property><!--每个Metastore中Worker的数量--><property><name>hive.compactor.worker.threads</name><value>1</value></property><!--HIve中日志存放位置--><property><name>hive.querylog.location</name><value>/home/hadoop/module/hive/tmp/querylog</value></property><!--HDFS路径,用于存储不同 map/reduce 阶段的执行计划和这些阶段的中间输出结果。 --><property><name>hive.exec.local.scratchdir</name><value>/home/hadoop/module/hive/tmp/scratchdir</value></property><!--远程资源下载的临时目录--><property><name>hive.downloaded.resources.dir</name><value>/home/hadoop/module/hive/tmp/resources</value></property></configuration> - 上传MySQL的驱动包到/home/hadoop/module/hive/lib目录:mysql-connector-java-8.0.17.jar
- 在MySQL上创建Hive的元数据存储库:create database hivedb;
- 执行Hive的初始化工作
cd /home/hadoop/module/hive/bin
./schematool -initSchema -dbType mysql
- 初始化完成后,在
MySQL的hivedb数据库中查看是否初始化成功:show tables; - 修改mysql的相关编码,主要是防止后续hive建表注释乱码的问题
#修改字段注释字符集ALTERTABLE COLUMNS_V2 modifycolumnCOMMENTvarchar(256)characterset utf8;#修改表注释字符集ALTERTABLE TABLE_PARAMS modifycolumn PARAM_VALUE varchar(20000)characterset utf8;#修改分区参数,支持分区建用中文表示ALTERTABLE PARTITION_PARAMS modifycolumn PARAM_VALUE varchar(20000)characterset utf8;ALTERTABLE PARTITION_KEYS modifycolumn PKEY_COMMENT varchar(20000)characterset utf8;#修改索引名注释,支持中文注释ALTERTABLE INDEX_PARAMS modifycolumn PARAM_VALUE varchar(4000)characterset utf8;#修改视图,支持视图中文ALTERTABLE TBLS modifyCOLUMN VIEW_EXPANDED_TEXT mediumtextCHARACTERSET utf8;ALTERTABLE TBLS modifyCOLUMN VIEW_ORIGINAL_TEXT mediumtextCHARACTERSET utf8; - 在hadoop的active节点赋权
hadoop fs -chmod 777/hadoop fs -chown -R root:root /tmpps1:需要使用hadoop用户赋权 - 如果后面hive主备切换,查询报错不支持standby节点,则需要修改数据库数据 1)hive数据库的dbs表的DB_LOCATION_URI字段配置:hdfs://mycluster/user/hive/warehouse(类似) 2)hive数据库的sds表的LOCATION字段配置:hdfs://mycluster/user/hive/warehouse/student(类似)
- 使用beeline连接测试1)首先启动
hiveserver2服务cd /home/hadoop/module/hivenohup ./bin/hiveserver2>> hiveserver2.log 2>&1&#该服务暂时不启动,因为metastore和mysql在同一台服务,网络互通,不需要开启该服务hive --service metastore > metastore.log 2>&1 &ps1:需要在active节点操作,如果10不是就需要把active转移过来#查看节点hdfs haadmin -getServiceState nn1#转移节点hdfs haadmin -failover nn2 nn1#再次查看hdfs haadmin -getServiceState nn1 ##结果显示active即可ps2:启动很慢,需耐心等待10000端口起来2)hiveserver2服务启动后,使用beeline客户端访问hiveserver2服务cd /home/hadoop/module/hive# 进入beeline客户端bin/beeline# 执行连接hiveserver2操作!connect jdbc:hive2://node10:10000/default#测试create table student(id int,name String);show tables;insert into student values('4','abc222');select * from student;# 或者bin/beeline -u jdbc:hive2://node10:10000/default-n root -p ffcsict1233)hive默认使用的是yarn的default,如果想要切换其他队列,则可以执行以下几种命令(根据版本了,3.1.2的执行第一种)set mapred.job.queue.name=yarnuser1;SET mapreduce.job.queuename=yarnuser1;set mapred.queue.names=yarnuser1;
十二、hbase集群配置(10)
- 创建文件夹:mkdir /home/hadoop/hbase
- 进入文件夹:cd /home/hadoop/hbase
- 下载并传hbase包:https://archive.apache.org/dist/hbase/2.3.5/
- 解压:tar -xvf hbase-2.1.0-bin.tar.gz
- 修改配置文件:vi /home/hadoop/hbase/hbase-2.1.0/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk/jdk1.8.0_291export HADOOP_HOME=/home/hadoop/module/hadoop-3.2.2export HBASE_LOG_DIR=/home/hadoop/hbase/logsexport HBASE_MANAGES_ZK=falseexport HBASE_CLASSPATH=/home/hadoop/module/hadoop-3.2.2/etc/hadoopexport HBASE_PID_DIR=/home/hadoop/module/hadoop-3.2.2/pids # 表示采用HBase自带的ZooKeeper管理,如果想用外部ZooKeeper管理HBase,可忽略本配置,该次配置使用自行安装的zk。# export HBASE_MANAGES_ZK=false - vi /home/hadoop/hbase/hbase-2.1.0/conf/hbase-site.xmlps:记得清除原来的hbase.cluster.distributed配置
<!--region server的共享目录,用来持久化HBase--><property><name>hbase.rootdir</name><value>hdfs://mycluster/hbase</value></property><!--HBase端口--><property><name>hbase.master.info.port</name><value>16010</value></property><!--HBase的运行模式,false是单机模式,true是分布式模式。若为false,HBase和Zookeeper会运行在同一个JVM里面--><property><name>hbase.cluster.distributed</name><value>true</value></property><!--zookeeper集群的URL配置,多个host中间用逗号隔开--><property><name>hbase.zookeeper.quorum</name><value>node10,node11,node12</value></property><!--本地文件系统的临时目录。可以修改到一个更为持久的目录上--><property><name>hbase.tmp.dir</name><value>/home/hadoop/hbase/tmp</value></property><!--如果你打算在本地文件系统中跑hbase,请禁掉此项--><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><!--HBase在zookeeper上数据的根目录znode节点--><property><name>zookeeper.znode.parent</name><value>/hbase</value></property><!--设置zookeeper通信端口,不配置也可以,zookeeper默认就是2181--><property><name>hbase.zookeeper.property.clientPort</name><value>2181</value></property> - 配置从服务器:vi /home/hadoop/hbase/hbase-2.1.0/conf/regionservers
node11node12node13 - 拷贝包:cp /home/hadoop/hbase/hbase-2.1.0/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar /home/hadoop/hbase/hbase-2.1.0/lib/
- 分发hbase配置:xsync /home/hadoop/hbase/hbase-2.1.0
- 启动hbase脚本:cd /home/hadoop --> ./hbase.sh startps:启动节点必须是hadoop的active节点
#查看节点hdfs haadmin -getServiceState nn1#转移节点hdfs haadmin -failover nn2 nn1#再次查看hdfs haadmin -getServiceState nn1 ##结果显示active即可 - 查看:jps

- 访问:http://192.168.248.10:16010/master-status
- 如果想要起多个hmaster,需要在另一个执行脚本即可:./hbase-daemon.sh start master
十三、启动方式
- 切换至脚本路径:cd /home/hadoop
- 启动zk:./zookeeper.sh start
- 启动journalnode:./journalnode.sh start
- 启动hadoop:./hadoop.sh start
- 启动hbase:./hbase.sh start
- 启动hive服务器:
##启动的节点必须是hadoop的active节点cd /home/hadoop/module/hivenohup ./bin/hiveserver2>> hiveserver2.log 2>&1&
十四、相关节点主备切换
- 手动切换namenode的状态的三种方式** 查看namenode节点的状态: hdfs haadmin -getServiceState nn1 nn22.1 将 active 状态从 nn1节点切换到 nn2上:hdfs haadmin -failover nn1 nn22.2 将 nn1 过渡到 Standby:hdfs haadmin -transitionToStandby --forcemanual nn12.3 将 nn2过渡到 Active(不存在active时候):hdfs haadmin -transitionToActive --forceactive --forcemanual nn1
- 手动切换resourcemanager** 查看resourcemanager 节点的状态: yarn rmadmin -getServiceState rm12.1 将 rm1 过渡到 Standby:yarn rmadmin -transitionToStandby --forcemanual rm12.2 将 rm2 过渡到 Active:yarn rmadmin -transitionToActive --forcemanual rm2
十五、yarn相关指令介绍
- 查看yarn正在运行的任务列表:yarn application -list
- kill掉yarn正在运行的任务: yarn application -kill application_id
- 查找yarn已经完成的任务列表:yarn application -appStates finished -list
- 查找yarn所有任务列表:yarn application -appStates ALL -list
- 查看日志详情:yarn logs -applicationId application_id
十六、相关问题整合
- 为什么需要metastore和hiveser1)hiveserver2 会启动一个hive服务端默认端口为:10000,可以通过beeline,jdbc,odbc的方式链接到hive。hiveserver2启动的时候会先检查有没有配置hive.metastore.uris,如果没有会先启动一个metastore服务(通过 Metastore服务连接MySQL获取元数据),然后在启动hiveserver2。如果有配置hive.metastore.uris。会连接到远程的metastore服务。2)Hive充当客户端(是HDFS的客户端也是Metastore的客户端,也是Hive的客户端),又充当服务端(因为有Metastore服务和Hiveserver2服务配置)。在实际生产环境下,可能有多台Hive客户端,MySQL的 IP地址对外不暴露,只暴露给其中一台,那么其他客户端就需要在暴露的那台机器上启动Metastore服务,其他Hive客户端连接这个Metastore服务,进而达到连接Mysql获取元数据的目的。
- 什么时候需要开启metastore和hiveserver2一般情况下,如果需要客户端去连接hive,则需要启动hiveserver2服务,开放10000端口。当hive客户端和MySQL数据库不是处于同一台服务器并且3306端口网络不通时,就需要在mysql服务器端开启metastore服务,并且开放出9083端口。3306端口网络不通的服务器可以通过配置hive-site.xml的metastore的url,间接连接mysql。
<property><name>hive.metastore.uris</name><value>thrift://node10:9083</value></property> - 遇到报错:org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive. Name node is in safe mode.解决:启动hadoop集群时,集群会默认开启安全模式,检查结束后会自动关闭,请耐心等待。如需强制关闭,则执行hdfs dfsadmin -safemode leave ,关闭安全模式ps:如果还是不行,则执行hdfs dfsadmin -safemode forceExit
- Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error原因:所在节点namenode为standby解决:把当前节点切成active即可
- The minimum number of live datanodes is not required. Safe mode will be turned off automatically once the thresholds have been reached. NamenodeHostName:node10原因:节点处于安全模式,手动解除即可解决:hdfs dfsadmin -safemode leave
- org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block原因:存在损坏文件解决:如下
查看受损block:hadoop fsck /hbase -list-corruptfileblocks ---The filesystem under path '/hbase' has 54CORRUPT files CORRUPT说明文件受损删除损坏的block: hadoop fsck /hbase -delete - Datanode denied communication with namenode because hostname cannot be resol原因:由于配置hadoop没有使用host+hostName的配置方式,导致了hadoop无法解析DataNode,对DataNode的注册失败。解决方案:
<property><name>dfs.namenode.datanode.registration.ip-hostname-check</name><value>false</value></property> - 服务器断电,导致数据同步异常,挂掉的服务器resourceManage无法切换到active删除tmp底下的hadoop-yarn-hadoop文件夹,重启集群
本文转载自: https://blog.csdn.net/weixin_40496191/article/details/128521527
版权归原作者 懒惰の天真热 所有, 如有侵权,请联系我们删除。
版权归原作者 懒惰の天真热 所有, 如有侵权,请联系我们删除。