
简介
今天学长向大家介绍一个大数据毕设项目
毕设分享 基于大数据情感分析的网络舆情分析系统(源码+论文)
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 项目分享:见文末!
实现效果
毕业设计 基于大数据情感分析的网络舆情分析系统
1 课题背景
在文本挖掘领域,文本聚类是一类常见而又重要的数据挖掘手段,同时也是很多其他挖掘操作的前置工作。顾名思义,聚类即按照某些特征和规则将整个数据集分成若干组的过程,各个组内元素在某些特征方面具有较高的相似性,而组间元素则在这些特征方面具有较大的差异性,所得到的各个组即为一个聚类,也常称之为“簇”。聚类作为一种无监督的机器学习方法,无需人工对数据进行标注和训练,自动化程度高。目前已被广泛应用于计算机科学、情报学、社会学、生物学等多个领域。随着互联网的高速发展,文本聚类在Web数据处理相关方面应用尤其广泛,例如推荐系统、网络舆情、各类文本挖掘及相关应用。
本项目收集了微博相关热点文章数据,并对评论进行情感分析统计,建立web可视化系统。
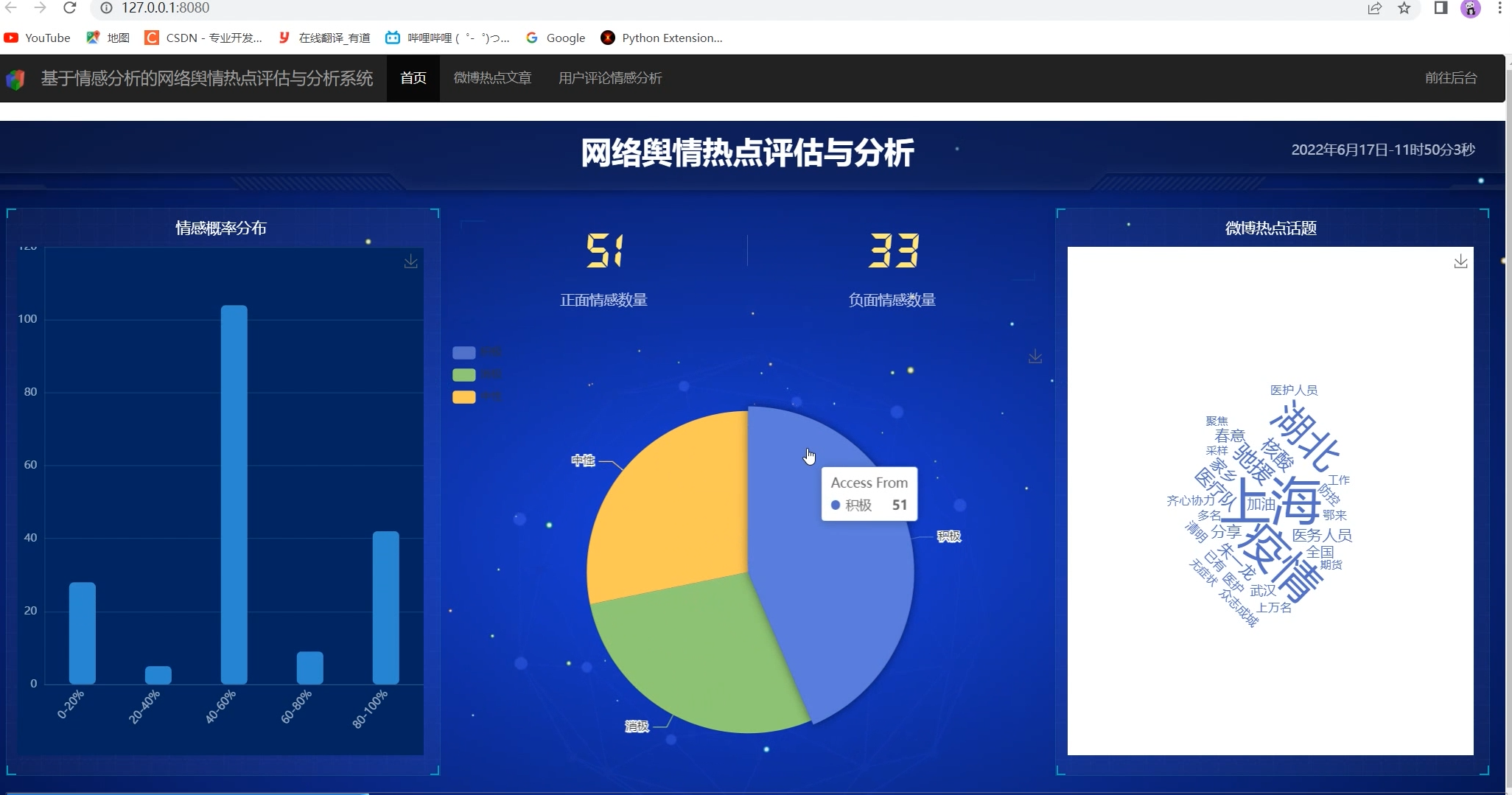
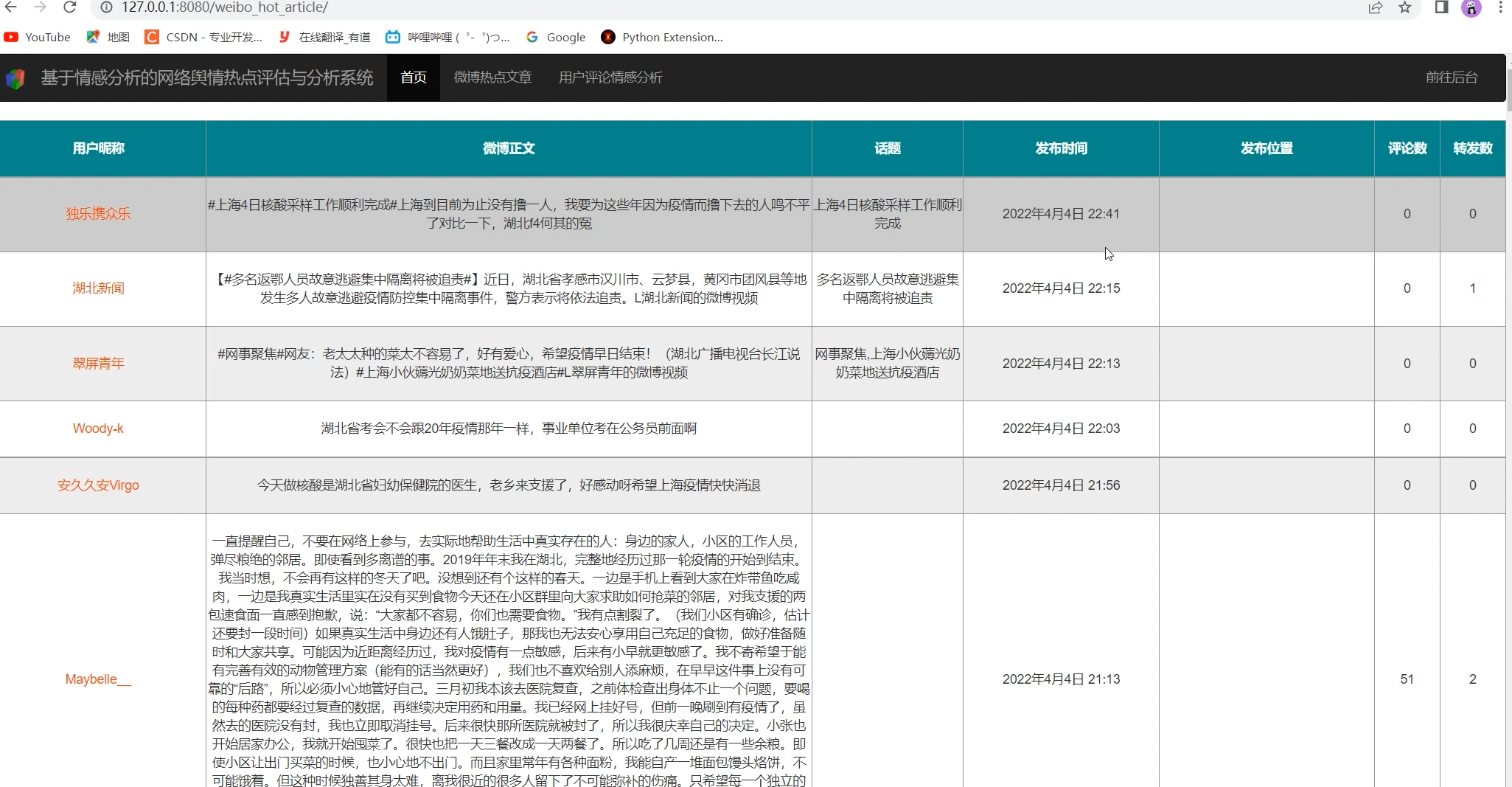
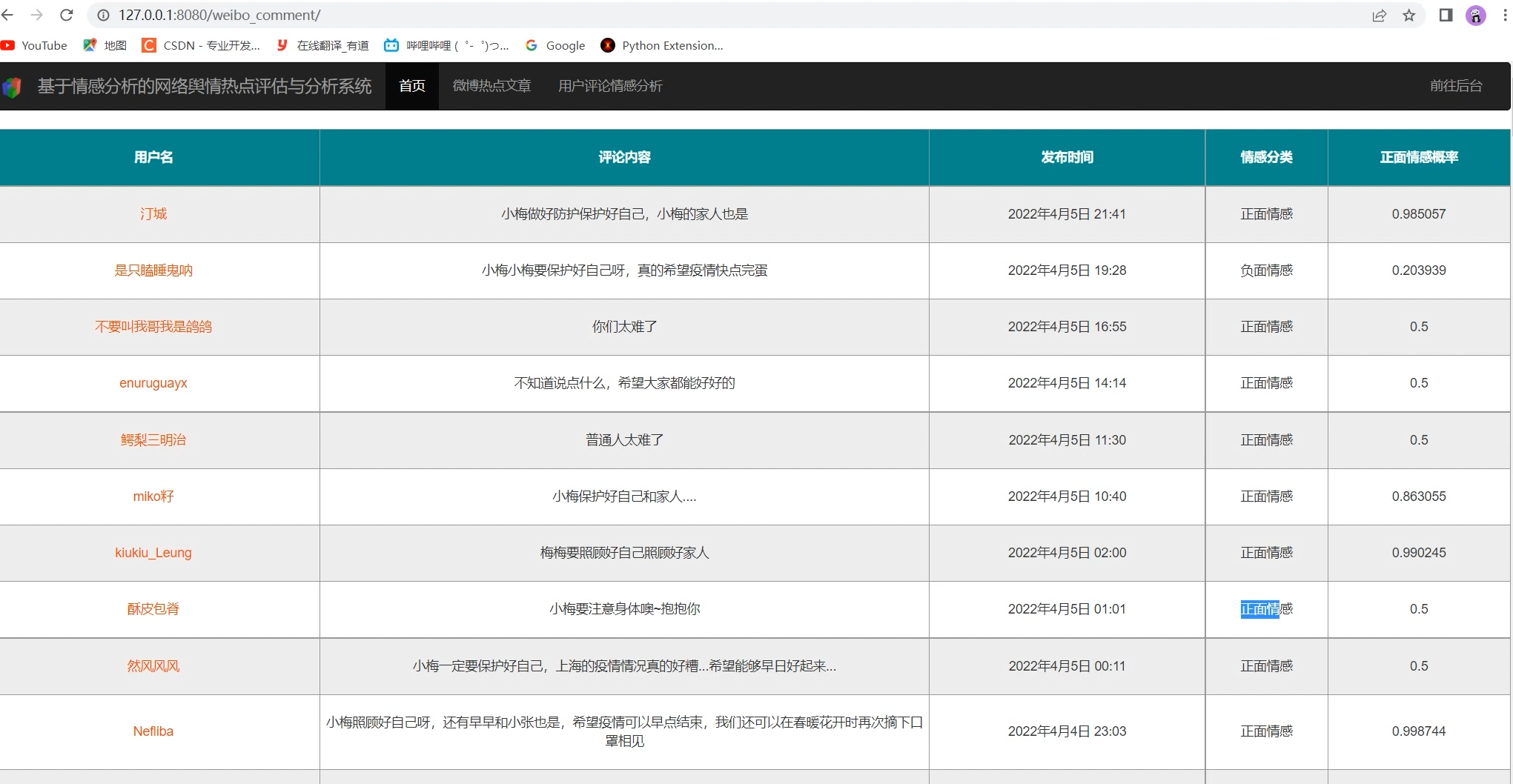
2 实现效果
主界面
3 文本情感分析
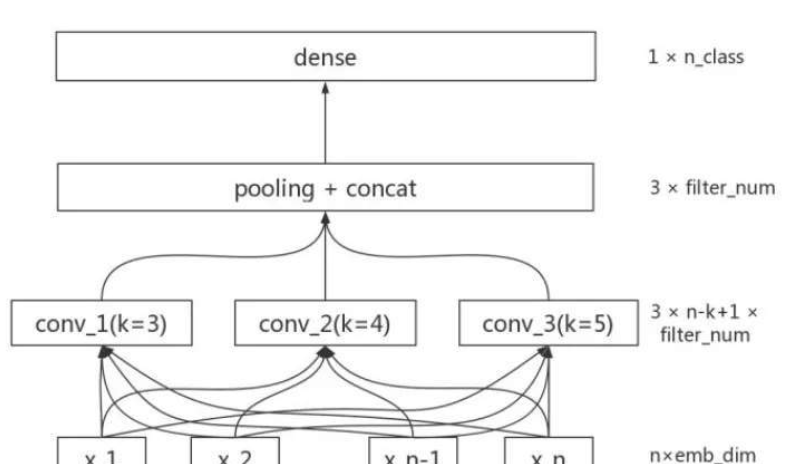
在了解了基于统计方法的情感分析模型优缺点之后,我们看一下深度学习文本分类模型是如何进行文本情感分析分类的。深度学习的一个优势就是可以进行端到端的学习,而省略的中间每一步的人工干预步骤。基于预训练模型生成的词向量,深度学习首先可以解决的一个重要问题就是情感词典的构建。下面我们会以集中典型的文本分类模型为例,展示深度文本分类模型的演进方向和适用场景。

3 Django
Django简介
Python下有多款不同的 Web 框架,Django是最有代表性的一种。许多成功的网站和APP都基于Django。
Django是一个开源的Web应用框架,由Python写成。
Django采用了MVC的软件设计模式,即模型M,视图V和控制器C。
Django的特点
- 强大的数据库功能:用python的类继承,几行代码就可以拥有一个动态的数据库操作API,如果需要也能执行SQL语句。
- 自带的强大的后台功能:几行代码就让网站拥有一个强大的后台,轻松管理内容。
- 优雅的网址:用正则匹配网址,传递到对应函数。
- 模板系统:强大,易扩展的模板系统,设计简易,代码和样式分开设计,更易管理。
- 缓存系统:与memcached或其它缓存系统联用,表现更出色,加载速度更快。
- 国际化:完全支持多语言应用,允许你定义翻译的字符,轻松翻译成不同国家的语言。
基本框架图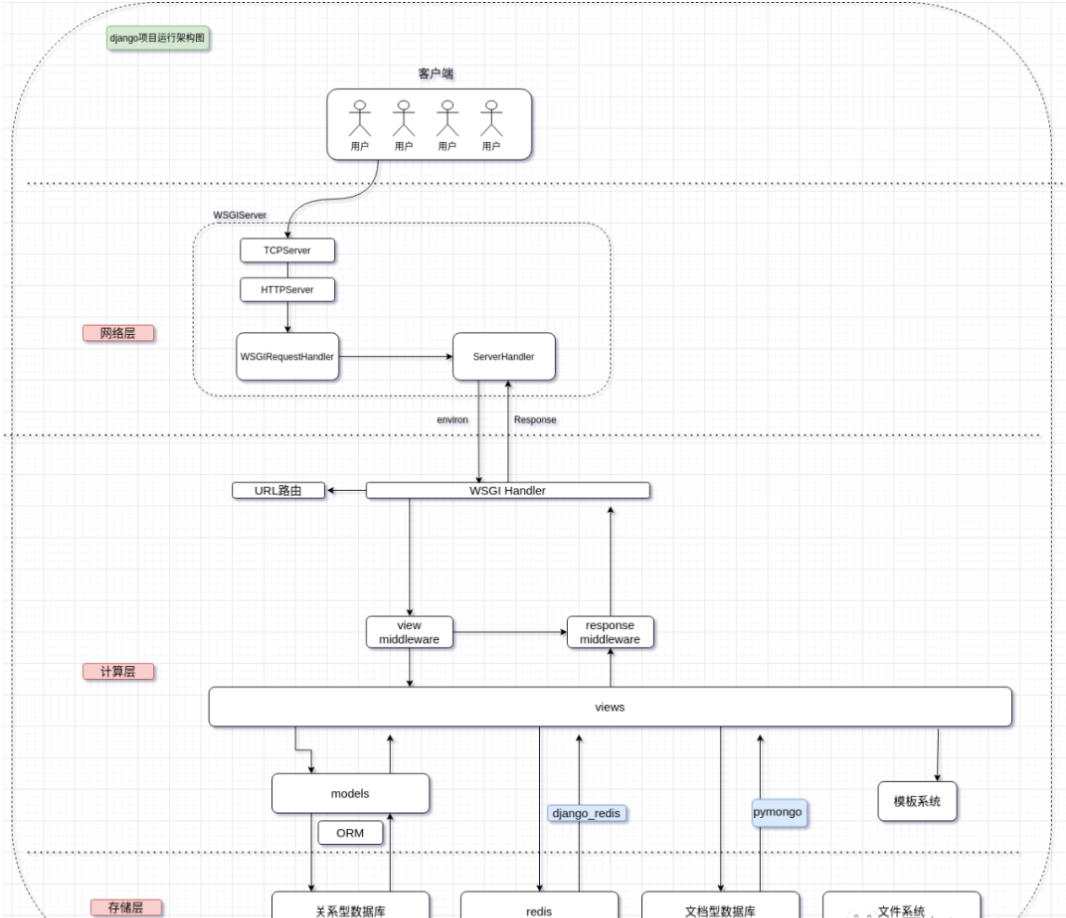
架构图介绍
生产部署环境一般用UWSGI和Gunicorn部署,两者的区别后面系列文章会讲到。
我将django架构分为 网络层,计算层,存储层。
网络层 由wsgi容器解析socket,转化成wsgi协议数据包;
计算层 也就是网上盛传的MVC结构,这同时也是一种设计模式;
存储层 框架对各种数据库服务器的封装;
安装
pip install django
使用
#!/usr/bin/env python'''Django's command-line utility for administrative tasks.'''import os
import sys
defmain():'''Run administrative tasks.'''
os.environ.setdefault('DJANGO_SETTINGS_MODULE','newsServer.settings')try:from django.core.management import execute_from_command_line
except ImportError as exc:raise ImportError("Couldn't import Django. Are you sure it's installed and ""available on your PYTHONPATH environment variable? Did you ""forget to activate a virtual environment?")from exc
execute_from_command_line(sys.argv)if __name__ =='__main__':
main()
4 爬虫
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。爬虫流程图如下: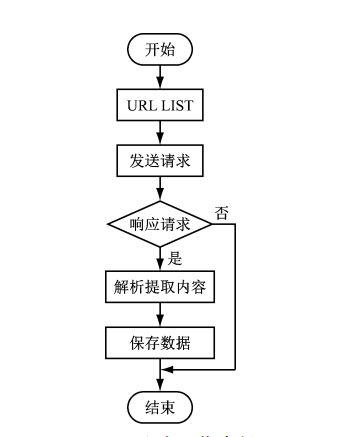
相关代码
defgetnewsdetail(url):# 获取页面上的详情内容并将详细的内容汇集在news集合中
result = requests.get(url)
result.encoding ='utf-8'
soup = BeautifulSoup(result.content, features="html.parser")
title = getnewstitle(soup)if title ==None:returnNone
date = getnewsdate(soup)
mainpage, orimainpage = getmainpage(soup)if mainpage ==None:returnNone
pic_url = getnewspic_url(soup)
videourl = getvideourl(url)
news ={'mainpage': mainpage,'pic_url': pic_url,'title': title,'date': date,'videourl': videourl,'origin': orimainpage,}return news
defgetmainpage(soup):'''
@Description:获取正文部分的p标签内容,网易对正文部分的内容通过文本前部的空白进行标识\u3000
@:param None
'''if soup.find('div',id='article')!=None:
soup = soup.find('div',id='article')
p = soup.find_all('p')for numbers inrange(len(p)):
p[numbers]= p[numbers].get_text().replace("\u3000","").replace("\xa0","").replace("新浪","新闻")
text_all =""for each in p:
text_all += each
logger.info("mainpage:{}".format(text_all))return text_all, p
elif soup.find('div',id='artibody')!=None:
soup = soup.find('div',id='artibody')
p = soup.find_all('p')for numbers inrange(len(p)):
p[numbers]= p[numbers].get_text().replace("\u3000","").replace("\xa0","").replace("新浪","新闻")
text_all =""for each in p:
text_all += each
logger.info("mainpage:{}"+ text_all)return text_all, p
else:returnNone,Nonedefgetnewspic_url(soup):'''
@Description:获取正文部分的pic内容,网易对正文部分的图片内容通过div中class属性为“img_wrapper”
@:param None
'''
pic = soup.find_all('div', class_='img_wrapper')
pic_url = re.findall('src="(.*?)"',str(pic))for numbers inrange(len(pic_url)):
pic_url[numbers]= pic_url[numbers].replace("//",'https://')
logging.info("pic_url:{}".format(pic_url))return pic_url
5 项目分享
🧿 项目分享:见文末!
版权归原作者 faalasou 所有, 如有侵权,请联系我们删除。