
前言
大数据时代下,针对大数据处理的新技术也在不断地开发和运用中,并逐渐成为数据处理挖掘行业广泛使用的主流技术之一。在大数据时代,Hadoop作为处理大数据的分布式存储和计算框架,在国内外大、中、小型企业中已得到了广泛应用。学习Hadoop技术是从事大数据行业工作必不可少的一步。
一.综述
1.概念
Hadoop由Apache基金会开发,开源的,可靠的,可扩展的,用于分布式计算的分布式系统基础架构或框架。负责数据的分布式存储和备份,资源管理器,提高资源在集群中的利用率,提高执行效率。

2.核心组件
Hadoop有3大核心组件,分别是分布式文件系统HDFS、分布式计算框架MapReduce和集群资源管理器YARN。
2.1HDFS
HDFS是以分布式进行存储的文件系统,主要负责集群数据的存储与读取。是一个主/从(Master/Slave)体系架构的分布式文件系统。架构如图所示
文件系统主要包含一个NameNode、一个Secondary NameNode和多个DataNode。
2.1.1分布式原理
HDFS作为一个分分布式系统可以划分成多个子系统或模块,各自运行在不同的机器上,子系统或模块之间通过网络通信进行协作,实现最终的整体功能。利用多个节点共同协作完成一项或多项具体业务功能的系统即为分布式系统。 分布式文件系统,主要体现在3个方面
2.1.2特点


2.2MapReduce
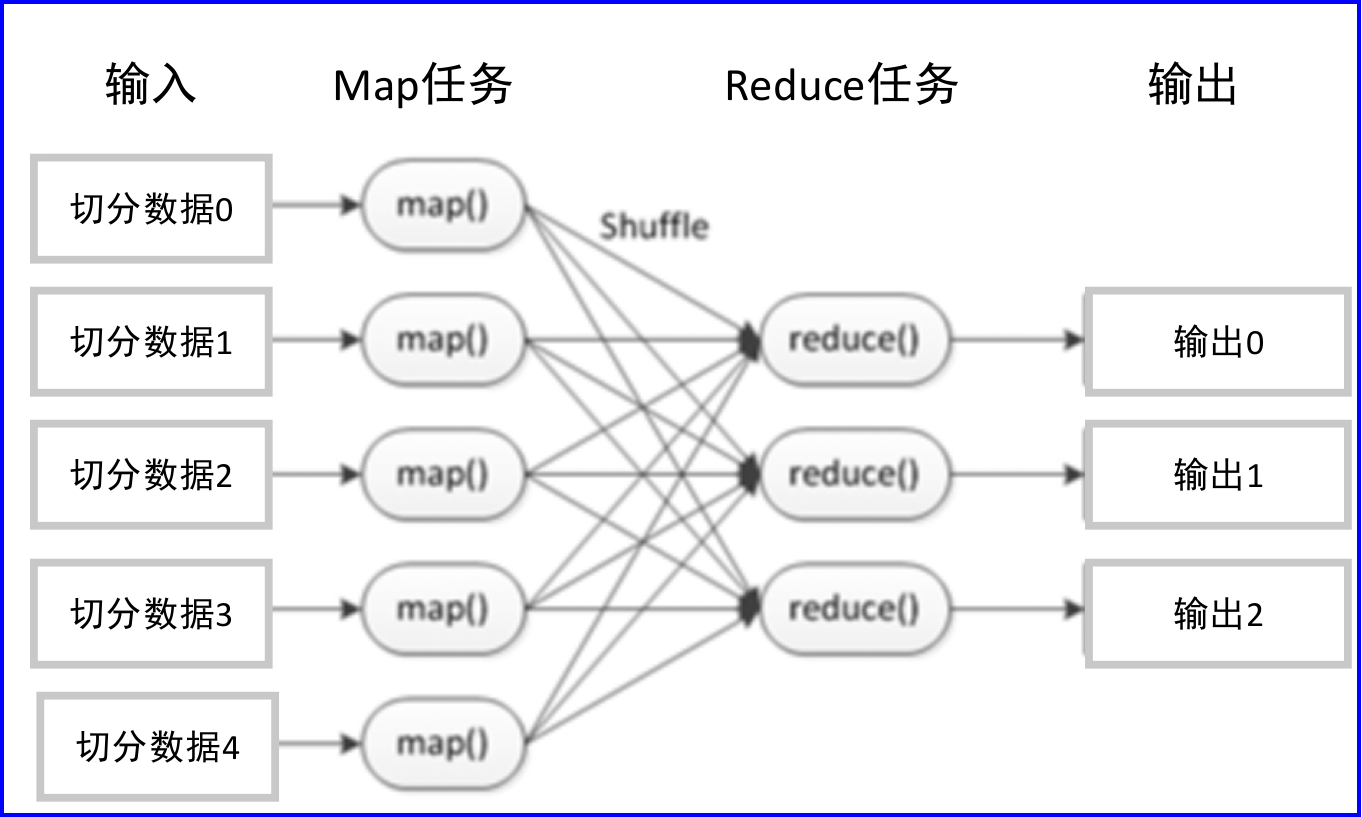
MapReduce是Hadoop的核心计算框架,是用于大规模数据集(大于1TB)并行运算的编程模型,主要包括Map(映射)和Reduce(规约)两个阶段。 MapReduce的核心思想是,当启动一个MapReduce任务时,Map端将会读取HDFS上的数据,将数据映射成所需要的键值对类型并传至Reduce端。Reduce端接收Map端键值对类型的中间数据,并根据不同键进行分组,对每一组键相同的数据进行处理,得到新的键值对并输出至HDFS。
2.2.1工作原理
一个完整的MapReduce过程包含数据的输入与分片、Map阶段数据处理、Shuffle&Sort阶段数据整合、Reduce阶段数据处理、数据输出等阶段。
2.3YARN
YARN是Hadoop的资源管理器,提交应用至YARN上执行可以提高资源在集群的利用率,加快执行速率。 Hadoop YARN的目的是使得Hadoop数据处理能力超越MapReduce。 YARN的另一个目标就是拓展Hadoop,使得YARN不仅可以支持MapReduce计算,而且还可以很方便地管理如Hive、HBase、Pig、Spark/Shark等组件的应用程序。
YARN的基本组成结构 YARN主要由ResourceManager、NodeManager、ApplicationMaster和Client Application这4部分构成。
2.3.1工作流程

二.Hadoop集群搭建和配置
Hadoop集群环境可以分为单机环境、伪分布式环境和完全分布式环境。
单机环境是指在一台单机上运行Hadoop,没有分布式文件系统,直接读取本地操作系统的文件。 伪分布式环境可以看作在一台单机上模拟并组建多节点集群。
完全分布式环境则是在多台单机上组建分布式集群。
为贴近真实的生产环境,建议搭建完全分布式模式的Hadoop集群环境。因此,本章将介绍在个人计算机上安装配置虚拟机,并在虚拟机中搭建Hadoop完全分布式集群的完整过程。
为了保证能顺畅地运行Hadoop集群,并能够进行基本的大数据开发调试,建议个人计算机硬件的最低配置为:内存至少8GB,硬盘可用容量至少100GB,CPU为Intel i5以上的多核(建议八核及以上)处理器。
Hadoop相关软件安装包及其版本说明
Hadoop完全分布式集群是主从架构,一般需要使用多台服务器组建。 本书中使用的Hadoop集群拓扑结构。
三.HDFS分布式文件系统
HDFS的中文翻译是Hadoop分布式文件系统(Hadoop Distributed File System)。它本质还是程序,主要还是以树状目录结构来管理文件(和linux类似,/表示根路径),且可以运行在多个节点上(即分布式)。
HDFS(Hadoop Distributed File System)是Hadoop项目的核心组件之一,它是一个高度容错性的系统,设计用来在廉价的硬件上部署。
HDFS解决了核心问题:在普通硬件上高效、可靠地存储和访问超大规模的数据集,为大数据应用提供底层的分布式存储服务。
HDFS遵循主从架构(Master/Slave),主要由一个NameNode和多个DataNode组成。这种架构使得HDFS能够跨多台计算机存储和处理文件,实现分布式存储和计算。

1.常用命令
显示HDFS指定路径下的所有文件
hdfs dfs -ls /
在HDFS上创建文件夹
hdfs dfs -mkdir -p /1/dir1/dir2
将指定目录的所有文件显示出来,包括子目录里的文件
hdfs dfs -ls -R /
上传本地文件到HDFS
hdfs dfs -put /usr/local/hadoop-3.1.3/test/test.txt /1/dir1/dir2
查看文件
hdfs dfs -cat /1/dir1/dir2/test.txt
将HDFS的<src path>文件下载到本地文件系统的<local dst>路径
hdfs dfs -get /1/dir1/dir2/test.txt ~
②hdfs dfs -get /1/dir1/dir2/test.txt ~
删除HDFS上的文件或者目录
hdfs dfs -rm /1/dir1/test.txt
改变指定文件(夹)的所有者或者所属组(change owner)
hdfs dfs -chown hsn:hahahsn /hellow.txt
四.MapReduce分布式计算框架
MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。一个基本完整的MapReduce程序流程,包括:数据分片-数据映射-数据混洗-数据归约-数据输出
一个MapReduce例子:对以下左侧“输入”数据进行词频统计,输出结果如右侧“输出”所示
五.HBase分布式数据库
1.数据模型

2.HBase基本架构
- master:作为集群的协调者,负责监控所有的RegionServer实例。 - 上述功能通过多个后台线程实现: 1. LoadBalancer:周期性检查region在RegionServer上的分布是否均衡,通过hbase.balancer.period参数配置检查周期,默认为5分钟。2. CatalogJanitor:负责定期检查和清理hbase:meta表中的冗余或过期数据。3. MasterProcWAL:记录master需要执行的任务到预写日志WAL中,确保在master故障时,backupMaster能够读取这些日志并恢复操作。- 主要功能包括: 1. 管理元数据表hbase:meta,接收并处理用户关于表的创建、修改和删除的请求。2. 监控region的分布情况,确保负载均衡,处理region的故障转移和拆分操作。- RegionServer:负责存储和处理HBase中的数据。 1. 主要职责有: 1. 处理数据的读写操作,如put(写入)和get(查询)。2. 执行region的拆分和合并操作,这些操作在master的监控下进行。- Zookeeper: 1. HBase利用Zookeeper来管理master的高可用性、记录RegionServer的状态和位置信息,以及存储meta表的位置。2. 在HBase 2.3版本推出的MasterRegistry模式下,客户端可以直接与master通信,减少了对Zookeeper的依赖,从而减轻了Zookeeper的压力,但可能增加了master的负担。- HDFS:作为HBase的底层存储系统,为HBase提供高可用和高容错的数据存储服务。

总结
Hadoop适用于大规模数据处理、实时数据处理、大规模图计算、机器学习和数据挖掘、日志处理和监控以及数据存储和备份等多个应用场景。
版权归原作者 张昕玥20230322119 所有, 如有侵权,请联系我们删除。