
这几天研究了一下Dinky,确实是一款很不错的软件,功能很强大,也很实用,可以极大的方便我们flink sql的开发工作,同时他也支持其他一些主流数据库的SQL,像starrocks。
下面的连接为Dinky的链接:Dinky (dlink.top)
Dinky号称基于Flink二次开发,没有侵入Flink,所以这一点就值得我们学习,为了了解Dinky我自己也搭建了一套Dinky环境,确实使用起来非常舒适 ,搭建过程也是比较容易,下面简单列一下搭建过程。
1.Dinky环境搭建
**1. **解压到指定目录
上传安装包并解压:
tar -zxvf dlink-release-0.7.3.tar.gz -C /opt/module/
mv dlink-release-0.7.3 dinky
cd dinky
**2. **初始化MySQL数据库
Dinky 采用 mysql 作为后端的存储库,部署需要 MySQL5.7 以上版本,这里我们使用的MySQL是8.0。在 Dinky 根目录 sql 文件夹下分别放置了初始化的dinky.sql文件、升级使用的upgrade/${version}_schema/mysql/ddl 和 dml。如果第一次部署,可以直接将 sql/dinky.sql 文件在 dinky 数据库下执行。(如果之前已经部署,那 upgrade 目录下 存放了各版本的升级 sql ,根据版本号按需执行即可)。
在MySQL中操作如下:
#创建数据库
mysql>
CREATE DATABASE dinky;
#创建用户并允许远程登录
mysql>
create user 'dinky'@'%' IDENTIFIED WITH mysql_native_password by 'dinky';
#授权
mysql>
grant ALL PRIVILEGES ON dinky.* to 'dinky'@'%';
mysql>
flush privileges;
登录创建好的dinky用户,执行初始化sql文件
mysql -udinky -pdinky
mysql>
use dinky;
mysql> source /opt/module/dinky/sql/dinky.sql
**3. **修改配置文件
修改 Dinky 连接 mysql 的配置文件。
cd /opt/module/dinky vim ./config/application.yml
spring:
datasource:
url: jdbc:mysql://${MYSQL_ADDR:hadoop102:3306}/${MYSQL_DATABASE:dinky}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true username: ${MYSQL_USERNAME:dinky} password: ${MYSQL_PASSWORD:dinky} driver-class-name: com.mysql.cj.jdbc.Driverapplication:
name: dinkymvc:
pathmatch: matching-strategy: ant_path_matcher format: date: yyyy-MM-dd HH:mm:ss #json格式化全局配置jackson:
time-zone: GMT+8 date-format: yyyy-MM-dd HH:mm:ssmain:
allow-circular-references: true
**4. **加载依赖
1)加载Flink依赖
Dinky 需要具备自身的 Flink 环境,该 Flink 环境的实现需要用户自己在 Dinky 根目录下 plugins/flink${FLINK_VERSION} 文件夹并上传相关的 Flink 依赖。当然也可在启动文件中指定 FLINK_HOME,但不建议这样做。
cp /opt/module/flink-1.17.0/lib/* /opt/module/dinky/plugins/flink1.17
2****)加载Hadoop依赖
Dinky 当前版本的 yarn 的 perjob 与 application 执行模式依赖 flink-shade-hadoop ,需要额外添加 flink-shade-hadoop-uber-3 包。对于 dinky 来说,Hadoop 3 的uber依赖可以兼容hadoop 2。
将flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar上传到/opt/module/dinky/plugins目录下。
**5. **上传jar包
使用 Application 模式时,需要将flink和dinky相关的包上传到HDFS。
1)创建HDFS目录并上传dinky的jar包
hadoop fs -mkdir -p /dinky/jar/
hadoop fs -put /opt/module/dinky/jar/dlink-app-1.17-0.7.3-jar-with-dependencies.jar /dinky/jar
2****)创建HDFS目录并上传flink的jar包
hadoop fs -mkdir /flink-dist
hadoop fs -put /opt/module/flink-1.17.0/lib /flink-dist
hadoop fs -put /opt/module/flink-1.17.0/plugins /flink-dist
**6. **启停命令
1****)启动命令
cd /opt/module/dinky
sh auto.sh start 1.17
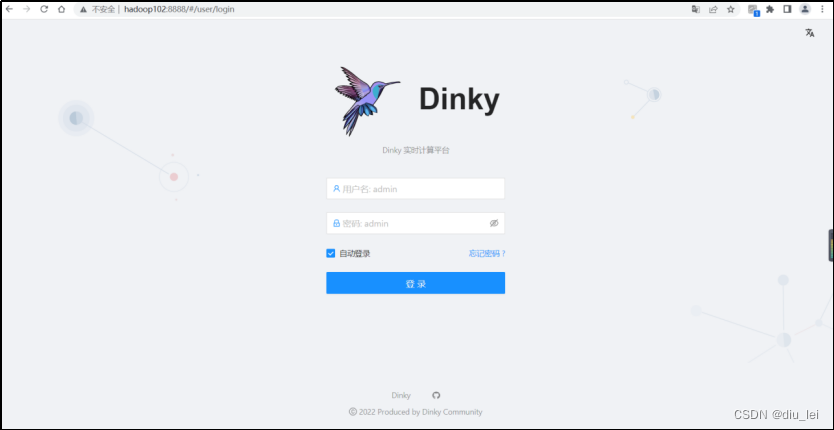
服务启动后,默认端口 8888,http://hadoop102:8888 , 默认用户名/密码: admin/admin
2****)停止命令
停止命令不需要携带Flink版本号。
cd /opt/module/dinky
sh auto.sh stop
3****)重启命令
cd /opt/module/dinky
sh auto.sh restart 1.17
*7. Flink*设置
使用 Application 模式以及 RestAPI 时,需要修改相关Flink配置:配置中心 >> Flink配置。
将“提交FlinkSQL的Jar文件路径”修改为2.5中dlink-app包的路径,点击保存。

2.Dinky基于Flink的二次开发
从上面我们可以看到在Dinky的页面上我们可以写Flink sql,他是使用什么方式把Flink sql提交到Flink集群的,下面我们通过代码看看:
下面是整个Dinky源码的目录结构,和作业提交相关的代码在dlink-admin这个模块中
dlink--父项目
|-dlink-admin--管理中心
|-dlink-alert--告警中心
|-dlink-app--Application Jar
|-dlink-assembly--打包配置
|-dlink-client--Client 中心
| |-dlink-client-1.11--Client-1.11实现
| |-dlink-client-1.12--Client-1.12实现
| |-dlink-client-1.13--Client-1.13实现
| |-dlink-client-1.14--Client-1.14实现
|-dlink-common--通用中心
|-dlink-connectors--Connectors 中心
| |-dlink-connector-jdbc--Jdbc 扩展
|-dlink-core--执行中心
|-dlink-doc--文档
| |-bin--启动脚本
| |-bug--bug 反馈
| |-config--配置文件
| |-doc--使用文档
| |-sql--sql脚本
|-dlink-executor--执行中心
|-dlink-extends--扩展中心
|-dlink-function--函数中心
|-dlink-gateway--Flink 网关中心
|-dlink-metadata--元数据中心
| |-dlink-metadata-base--元数据基础组件
| |-dlink-metadata-clickhouse--元数据-clickhouse 实现
| |-dlink-metadata-mysql--元数据-mysql 实现
| |-dlink-metadata-oracle--元数据-oracle 实现
| |-dlink-metadata-postgresql--元数据-postgresql 实现
| |-dlink-metadata-doris--元数据-doris 实现
| |-dlink-metadata-phoenix-元数据-phoenix 实现
| |-dlink-metadata-sqlserver-元数据-sqlserver 实现
|-dinky-web--React 前端
|-docs--官网文档
作业提交代码的入口:
com.dlink.controller.APIController#submitTask方法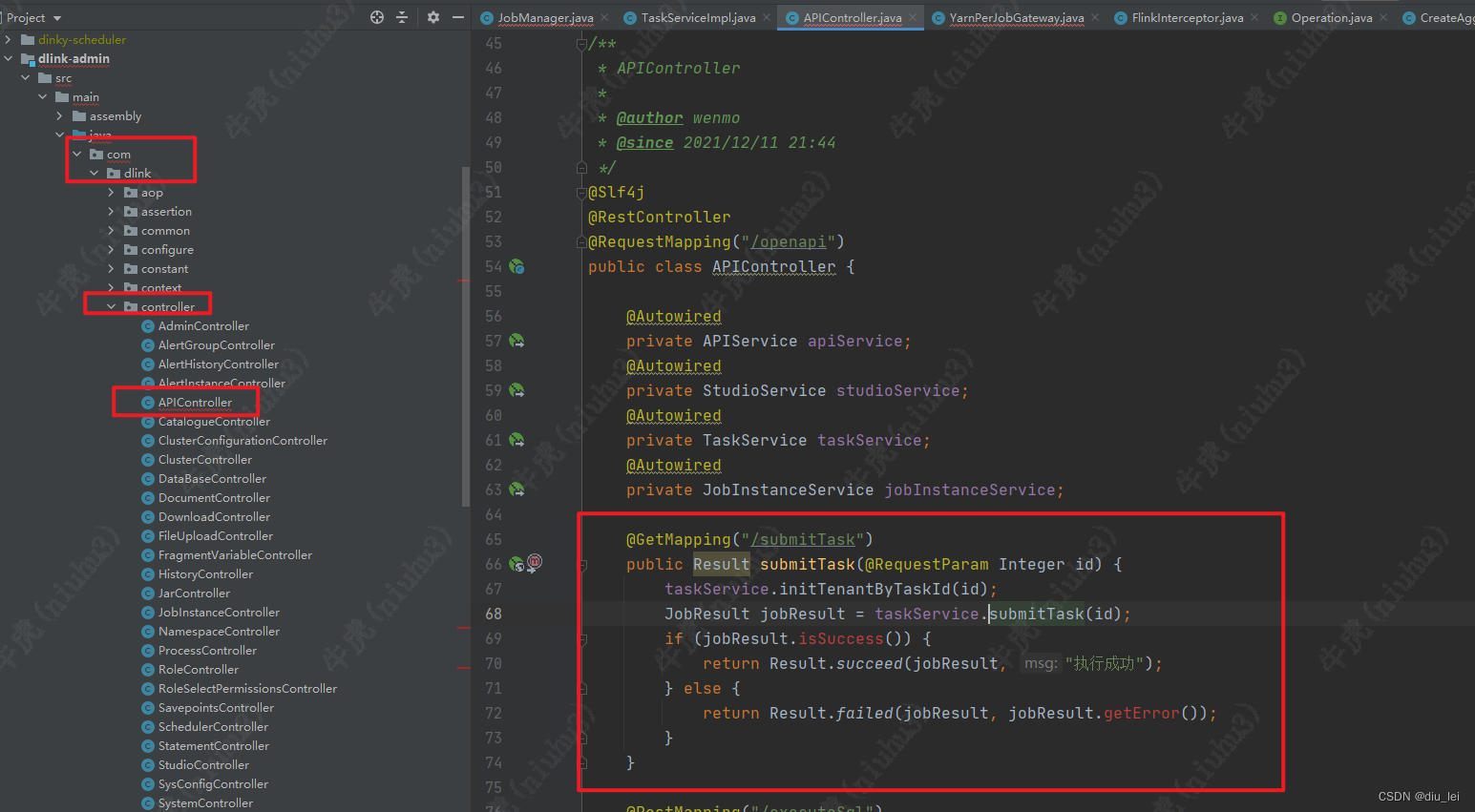
通过调用service层的同名方法提交task

service层的submitTask主要有以下功能:
1.通过taskId获取task
2.判断task的dialect是否是flink sql,如果不是的话调用executeCommonSql方法执行sql
3.获取进程实例processEntity
4.创建jobmanager
5.判断配置的是否是jarTask,是的话调用jobManager.executeJar(),不是的话调用jobManager.executeSql
@Override
public JobResult submitTask(Integer id) {
//通过taskId获取task信息
Task task = this.getTaskInfoById(id);
Asserts.checkNull(task, Tips.TASK_NOT_EXIST);
//判断task的Dialect是否是flink sql 不是的话调用executeCommonSql方法执行sql
if (Dialect.notFlinkSql(task.getDialect())) {
return executeCommonSql(SqlDTO.build(task.getStatement(),
task.getDatabaseId(), null));
}
ProcessEntity process = null;
//获取进程实例 ProcessEntity
if (StpUtil.isLogin()) {
process = ProcessContextHolder.registerProcess(
ProcessEntity.init(ProcessType.FLINKSUBMIT, StpUtil.getLoginIdAsInt()));
} else {
process = ProcessEntity.NULL_PROCESS;
}
process.info("Initializing Flink job config...");
JobConfig config = buildJobConfig(task);
//如果GatewayType是k8s appplication,加载容器
if (GatewayType.KUBERNETES_APPLICATION.equalsValue(config.getType())) {
loadDocker(id, config.getClusterConfigurationId(), config.getGatewayConfig());
}
//创建jobmanager
JobManager jobManager = JobManager.build(config);
process.start();
//判断配置的是否是jarTask,是的话调用jobManager.executeJar(),不是的话调用jobManager.executeSql
if (!config.isJarTask()) {
JobResult jobResult = jobManager.executeSql(task.getStatement());
process.finish("Submit Flink SQL finished.");
return jobResult;
} else {
JobResult jobResult = jobManager.executeJar();
process.finish("Submit Flink Jar finished.");
return jobResult;
}
}
下面为该JobManager的成员变量,他是dinky自己构建的Jobmanager,和flink的区别还是很大的
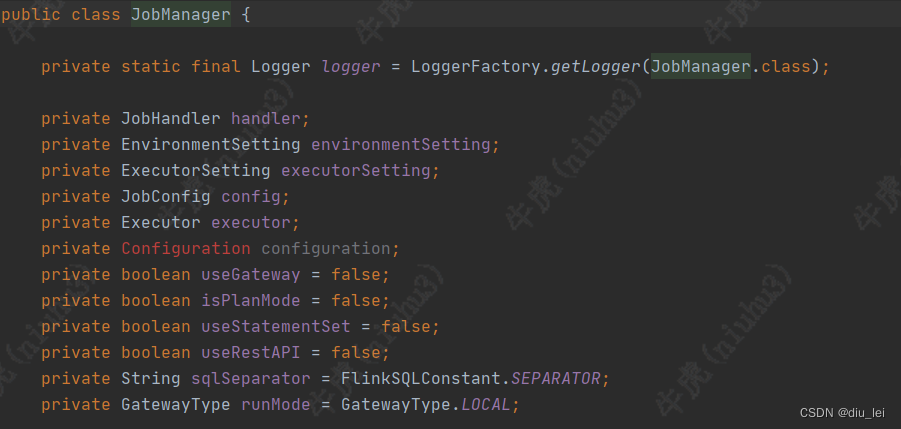
下面为executeSql的方法体,他会根据sql类型将不同sql放进不同的list,封装成JobParam,初始化UDF,执行DDL然后根据是否使用statementSet和 gateway使用不同方式提交insertSql,statementSet是flink的一个特性,他会将多个insert语句拼在一起然后一起执行,gateway是flink二次开发的一个接口不了解gateway的兄弟可以去官网看看,简单来说就是让你可以通过rest api的方式将sql提交给flink(Overview | Apache Flink)
public JobResult executeSql(String statement) {
initClassLoader(config);
//获取进程实例 ProcessEntity
ProcessEntity process = ProcessContextHolder.getProcess();
//初始化job
Job job = Job.init(runMode, config, executorSetting, executor, statement, useGateway);
if (!useGateway) {
job.setJobManagerAddress(environmentSetting.getAddress());
}
JobContextHolder.setJob(job);
ready();
String currentSql = "";
//根据sql类型将sql分类并放进不同的list,封装成JobParam
JobParam jobParam = Explainer.build(executor, useStatementSet, sqlSeparator)
.pretreatStatements(SqlUtil.getStatements(statement, sqlSeparator));
try {
//初始化UDF
initUDF(jobParam.getUdfList(), runMode, config.getTaskId());
//执行DDL
for (StatementParam item : jobParam.getDdl()) {
currentSql = item.getValue();
executor.executeSql(item.getValue());
}
//insert语句的list集合大于0
if (jobParam.getTrans().size() > 0) {
// Use statement set or gateway only submit inserts.
//使用statementSet 和gateWay
if (useStatementSet && useGateway) {
List<String> inserts = new ArrayList<>();
for (StatementParam item : jobParam.getTrans()) {
inserts.add(item.getValue());
}
// Use statement set need to merge all insert sql into a sql.
currentSql = String.join(sqlSeparator, inserts);
//利用gateWay的方式提交sql
GatewayResult gatewayResult = submitByGateway(inserts);
// Use statement set only has one jid.
job.setResult(InsertResult.success(gatewayResult.getAppId()));
job.setJobId(gatewayResult.getAppId());
job.setJids(gatewayResult.getJids());
job.setJobManagerAddress(formatAddress(gatewayResult.getWebURL()));
if (gatewayResult.isSucess()) {
job.setStatus(Job.JobStatus.SUCCESS);
} else {
job.setStatus(Job.JobStatus.FAILED);
job.setError(gatewayResult.getError());
}
//使用statementSet 和不使用gateWay
} else if (useStatementSet && !useGateway) {
List<String> inserts = new ArrayList<>();
for (StatementParam item : jobParam.getTrans()) {
if (item.getType().isInsert()) {
inserts.add(item.getValue());
}
}
if (inserts.size() > 0) {
currentSql = String.join(sqlSeparator, inserts);
// Remote mode can get the table result.
//调用executor.executeStatementSet提交statementSet
TableResult tableResult = executor.executeStatementSet(inserts);
if (tableResult.getJobClient().isPresent()) {
job.setJobId(tableResult.getJobClient().get().getJobID().toHexString());
job.setJids(new ArrayList<String>() {
{
add(job.getJobId());
}
});
}
if (config.isUseResult()) {
// Build insert result.
IResult result = ResultBuilder
.build(SqlType.INSERT, config.getMaxRowNum(), config.isUseChangeLog(),
config.isUseAutoCancel(), executor.getTimeZone())
.getResult(tableResult);
job.setResult(result);
}
}
//使用Gateway 和不使用StatementSet
} else if (!useStatementSet && useGateway) {
List<String> inserts = new ArrayList<>();
for (StatementParam item : jobParam.getTrans()) {
inserts.add(item.getValue());
// Only can submit the first of insert sql, when not use statement set.
break;
}
currentSql = String.join(sqlSeparator, inserts);
//使用submitByGateway方法提交sql
GatewayResult gatewayResult = submitByGateway(inserts);
job.setResult(InsertResult.success(gatewayResult.getAppId()));
job.setJobId(gatewayResult.getAppId());
job.setJids(gatewayResult.getJids());
job.setJobManagerAddress(formatAddress(gatewayResult.getWebURL()));
if (gatewayResult.isSucess()) {
job.setStatus(Job.JobStatus.SUCCESS);
} else {
job.setStatus(Job.JobStatus.FAILED);
job.setError(gatewayResult.getError());
}
} else {
//其他情况使用FlinkInterceptor提交sql
for (StatementParam item : jobParam.getTrans()) {
currentSql = item.getValue();
FlinkInterceptorResult flinkInterceptorResult = FlinkInterceptor.build(executor,
item.getValue());
if (Asserts.isNotNull(flinkInterceptorResult.getTableResult())) {
if (config.isUseResult()) {
IResult result = ResultBuilder
.build(item.getType(), config.getMaxRowNum(), config.isUseChangeLog(),
config.isUseAutoCancel(), executor.getTimeZone())
.getResult(flinkInterceptorResult.getTableResult());
job.setResult(result);
}
} else {
if (!flinkInterceptorResult.isNoExecute()) {
TableResult tableResult = executor.executeSql(item.getValue());
if (tableResult.getJobClient().isPresent()) {
job.setJobId(tableResult.getJobClient().get().getJobID().toHexString());
job.setJids(new ArrayList<String>() {
{
add(job.getJobId());
}
});
}
if (config.isUseResult()) {
IResult result = ResultBuilder.build(item.getType(), config.getMaxRowNum(),
config.isUseChangeLog(), config.isUseAutoCancel(),
executor.getTimeZone()).getResult(tableResult);
job.setResult(result);
}
}
}
// Only can submit the first of insert sql, when not use statement set.
break;
}
}
}
if (jobParam.getExecute().size() > 0) {
if (useGateway) {
for (StatementParam item : jobParam.getExecute()) {
executor.executeSql(item.getValue());
if (!useStatementSet) {
break;
}
}
GatewayResult gatewayResult = null;
config.addGatewayConfig(executor.getSetConfig());
if (runMode.isApplicationMode()) {
gatewayResult = Gateway.build(config.getGatewayConfig()).submitJar();
} else {
StreamGraph streamGraph = executor.getStreamGraph();
streamGraph.setJobName(config.getJobName());
JobGraph jobGraph = streamGraph.getJobGraph();
if (Asserts.isNotNullString(config.getSavePointPath())) {
jobGraph.setSavepointRestoreSettings(
SavepointRestoreSettings.forPath(config.getSavePointPath(), true));
}
gatewayResult = Gateway.build(config.getGatewayConfig()).submitJobGraph(jobGraph);
}
job.setResult(InsertResult.success(gatewayResult.getAppId()));
job.setJobId(gatewayResult.getAppId());
job.setJids(gatewayResult.getJids());
job.setJobManagerAddress(formatAddress(gatewayResult.getWebURL()));
if (gatewayResult.isSucess()) {
job.setStatus(Job.JobStatus.SUCCESS);
} else {
job.setStatus(Job.JobStatus.FAILED);
job.setError(gatewayResult.getError());
}
} else {
for (StatementParam item : jobParam.getExecute()) {
executor.executeSql(item.getValue());
if (!useStatementSet) {
break;
}
}
JobClient jobClient = executor.executeAsync(config.getJobName());
if (Asserts.isNotNull(jobClient)) {
job.setJobId(jobClient.getJobID().toHexString());
job.setJids(new ArrayList<String>() {
{
add(job.getJobId());
}
});
}
if (config.isUseResult()) {
IResult result = ResultBuilder
.build(SqlType.EXECUTE, config.getMaxRowNum(), config.isUseChangeLog(),
config.isUseAutoCancel(), executor.getTimeZone())
.getResult(null);
job.setResult(result);
}
}
}
job.setEndTime(LocalDateTime.now());
if (job.isFailed()) {
failed();
} else {
job.setStatus(Job.JobStatus.SUCCESS);
success();
}
} catch (Exception e) {
String error = LogUtil.getError("Exception in executing FlinkSQL:\n" + currentSql, e);
job.setEndTime(LocalDateTime.now());
job.setStatus(Job.JobStatus.FAILED);
job.setError(error);
process.error(error);
failed();
} finally {
close();
}
return job.getJobResult();
}
executeJar这个方法就简单多了,先初始化job,然后利用gateway将jar包提交到yarn集群
public JobResult executeJar() {
ProcessEntity process = ProcessContextHolder.getProcess();
Job job = Job.init(runMode, config, executorSetting, executor, null, useGateway);
JobContextHolder.setJob(job);
ready();
try {
GatewayResult gatewayResult = Gateway.build(config.getGatewayConfig()).submitJar();
job.setResult(InsertResult.success(gatewayResult.getAppId()));
job.setJobId(gatewayResult.getAppId());
job.setJids(gatewayResult.getJids());
job.setJobManagerAddress(formatAddress(gatewayResult.getWebURL()));
job.setEndTime(LocalDateTime.now());
if (gatewayResult.isSucess()) {
job.setStatus(Job.JobStatus.SUCCESS);
success();
} else {
job.setError(gatewayResult.getError());
job.setStatus(Job.JobStatus.FAILED);
failed();
}
} catch (Exception e) {
String error = LogUtil.getError(
"Exception in executing Jar:\n" + config.getGatewayConfig().getAppConfig().getUserJarPath(), e);
job.setEndTime(LocalDateTime.now());
job.setStatus(Job.JobStatus.FAILED);
job.setError(error);
failed();
process.error(error);
} finally {
close();
}
return job.getJobResult();
}
版权归原作者 diu_lei 所有, 如有侵权,请联系我们删除。