
一、数据仓库的操作
1.在Hive中创建一个数据仓库,名为DB
create database DB;
以上创建了一个BD库,但是这一条sql可以进一步优化,我们可以加上if not exists
create database if not exists DB;
2.查看数据仓库BD的信息及路径
describe database DB;
3.删除名为DB的数据仓库
drop database if exist DB;
二、Hive数据表的操作
1.查看已经存在的表,因为如果创建已经存在的表的话会报错
show tables;
2..创建一个名为cat的内部表,有两个字段为cat_id和cat_name,字符类型为string。
create table cat(cat_id string, cat_name string);
如果重复创建则会出现以下情况
- 修改cat表格结构,对于cat表添加两个字段group_id和cat_code.
alter table cat add columns(group_id string,cat_code string);
4.使用desc命令查看以下加完字段的cat表结构
desc cat;
5.修改cat2的表名 , 把cat2重命名为cat3
alter table cat2 rename to cat3;
6.删除名为cat3的表并查看
drop table cat3;
show tables;
7.创建与表相同结构的表,创建一个与cat表结构相同的表,名为cat4, 这里要用到like关键字
create table cat4 like cat
8.从本地文件系统中导入数据到Hive表
在Hive中创建一个cat_group表,包含group_id和group_name两个字段,字符类型为string,以"\t" 为分隔符, 并查看结果
create table cat_group(group_id string,group_name string) row format delimited fields terminated by '\t' stored as textfile;
[row format delimited]关键字,是用来设置创建的表在加载数据的时候,支持的列分隔符。
[stored as textfile]关键字,是用来设置加载数据的数据类型,默认是TEXTFILE,如果文件数据是纯文本,就是使用 [stored as textfile],然后从本地直接拷贝到HDFS上,Hive直接可以识别数据。
将Linux本地/data/hive2目录下的cat_group文件导入到Hive的cat_group表中
load data local inpath '/data/hive2/cat_group' into table cat_group;
9.从本地文件系统中导入数据到Hive
在HDFS上创建/myhive2目录
hadoop fs -mkdir /myhive2
然后将本地的/data/hive2/下面的cat_group表上传到HDFS的/myhive2上,并查看是否创建成功
hadoop fs -put /datahive2/cat_group /myhive2
hadoop fs -ls /myhive2
接着,在Hive中创建名为cat_group1的表,创表语句如下:
create table cat_group1(group_id string,group_name string)
row format delimited fields terminated by '\t' stored as textfile;
最后,将HDFS下/myhive2中的表cat_group导入到Hive中的cat_group1表中,并查看结果
load data inpath '/myhive2/cat_group' into table cat_group1;
select * from cat_group1 limit10;
10.从别的表中查询出相应的数据并导入到Hive中
首先在hive中创建一个名为cat_group2的表
create table cat_group2(group_id string,group_name string)
row format delimited fields terminated by '\t' stored as textfile;
用下面两种方式将cat_group1表中的数据导入到cat_group2表中
insert into table cat_group2 select * from cat_group1;
insert overwrite table cat_group2 select * from cat_group1;
(insert overwrite 会覆盖数据)。
导入完成后,用select语句查询cat_group2表
select * from cat_group2 limit 10;
11.在创建表的时候从别的表中查询出相应数据并插入到所创建的表中
create table cat_grup3 as select * from cat_group2;
创建并导入完成,用select语句查询实验结果。
select * from cat_group3 limit 10;
三、三种常见的数据导出方式
12.导出到本地文件系统
首先在Linux本地创建/data/hive2/out目录
mkdir -p /data/hive2/out
并将Hive中的cat_group表导出到本地文件系统/data/hive2/out中
insert overwrite local directory '/data/hive2/out' select * from cat_group;
注意:方法和导入数据到Hive不一样,不能用insert into来将数据导出。
到处完成后,在Linux本地切换到/data/hive2/out目录, 通过cat命令查询导出文件的内容
cd /data/hive2/out
ls
cat 000000_0
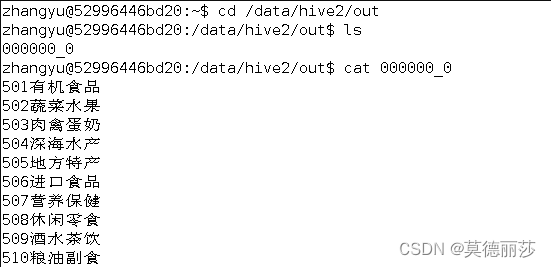
通过上图可以看到导出的数据,字段之间没有分割开,所以我们使用下面的方式,将输出字段以“\t”键分割。
insert overwrite local directory '/data/hive2/out' select group_id,concat('\t',group_name) from cat_group;
13.导出到Hive的另一个表中
将Hive中表cat_group中的数据导入到cat_group4中(两表字段及字符类型相同)。
首先在Hive中创建一个表cat_group4,有group_id和group_name两个字段,字符类型为string,以‘\t’为分隔符。
create table cat_group4(group_id string,group_name string)
row format delimited fields terminated by '\t' stored as textfile;
然后将cat_group中的数据导入到cat_group4中
insert into table cat_group4 select * from cat_group;
四、Hive分区的操作
创建表分区, 在Hive中创建一个分区表goods,包含goods_id和goods_status两个字段,字符类型为string, 分区为cat_id, 字符类型为string , 以"\t"为分隔符
create table goods(goods_id strings, goods_status strings)row format delimited fields terminated by"\t";
查看表goods结构
desc goods;
向分区插入数据, 将本地/data/hive2下的表goods中数据插入到分区表goods中
首先,在Hive下创建一个非分区表goods_1表, 用于存储本地/data/hive2下的表goods中的数据
create table goods_1(goods_id string,goods_status string,cat_id string)
row format delimited fields terminated by '\t';
将本地/data/hive2下的表goods中的数据导入到Hive中的goods_1中
load data local inpath '/data/hive2/goods' into table goods_1;
再将goods_1中的数据导入到分区表goods中
insert into table goods partition(cat_id='52052') select goods_id,goods_status from goods_1 where cat_id='52052';
查看表goods中的分区
show partitions goods;
修改表分区, 将分区表中的分区列cat_id = 52052改为52051,并查看修改后的分区名
alter table goods partition(cat_id=52052) rename to partition(cat_id=52051);
show partitions goods;
删除表分区
在删除goods分区表之前,先将goods表被分出一个goods_2表
create table goods_2(goods_id string,goods_status string) partitioned by (cat_id string)
row format delimited fields terminated by '\t';
insert into table goods_2 partition(cat_id='52052') select goods_id,goods_status from goods_1 where cat_id='52052';
删除goods表中的cat_id分区
alter table goods drop if exist partition(cat_id='52051');
五、Hive桶的操作
创建桶
创建一个名为goods_t的表, 包含两个字段goods_id和goods_status, 字符类型都为string, 按照cat_id string分区,按godds_status列聚类和goods_id列排序,划分成两个桶
create table goods_t(goods_id string,goods_status string) partitioned by(cat_id string)
clustered by(goods_status) sorted by (goods_id) into 2 buckets
设置环境变量
set hive.enforce.bucketing=true;
向goods_t表格
中插入goods_2表中的数据
from goods_2 insert overwrite table goods_t partition(cat_id='52063') select goods_id,good_status
查看结果
select * from goods_t tablesample(bucket 1 out of 2 on goods_id);

版权归原作者 莫德丽莎 所有, 如有侵权,请联系我们删除。