
前言
canal 是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
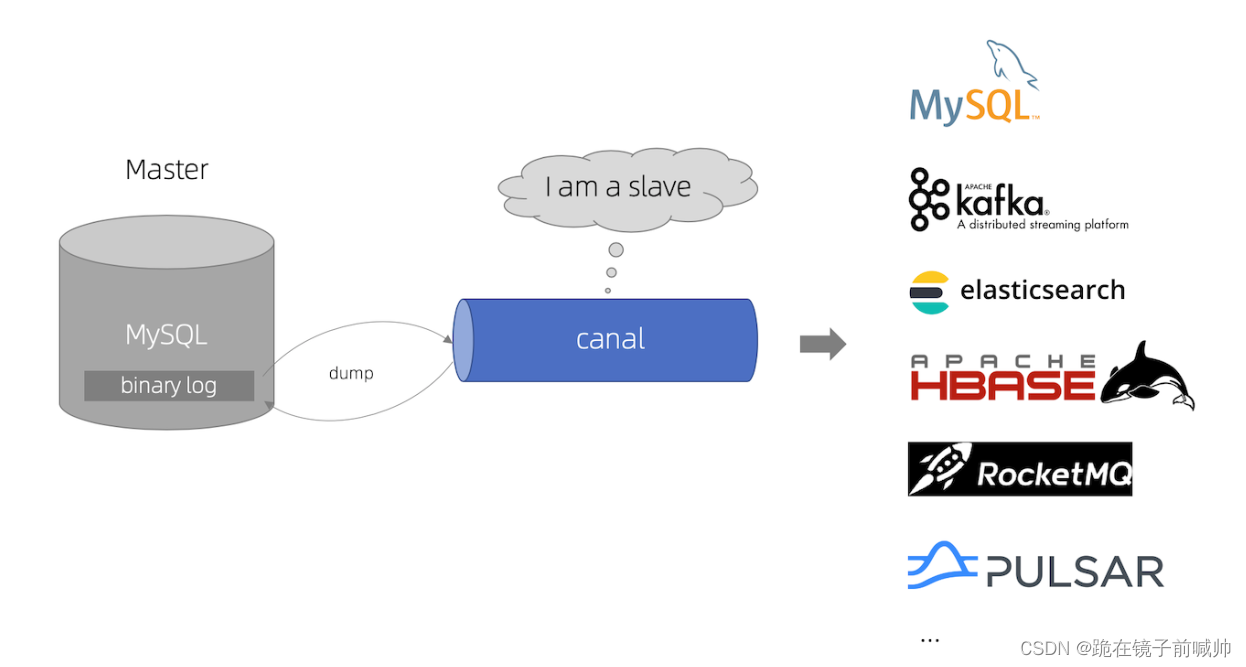
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
Canal工作原理
Canal工作原理
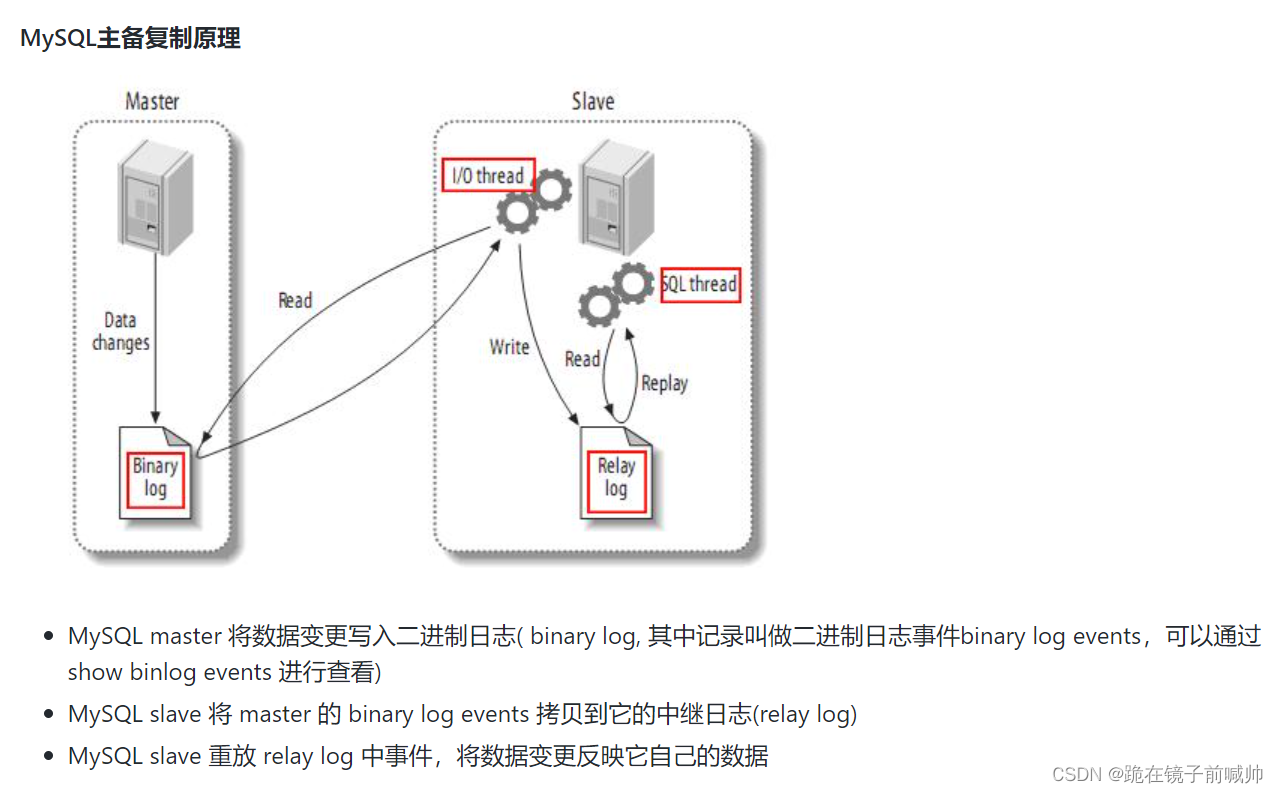
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议。
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )。
- canal 解析 binary log 对象(原始为 byte 流)。
Canal架构
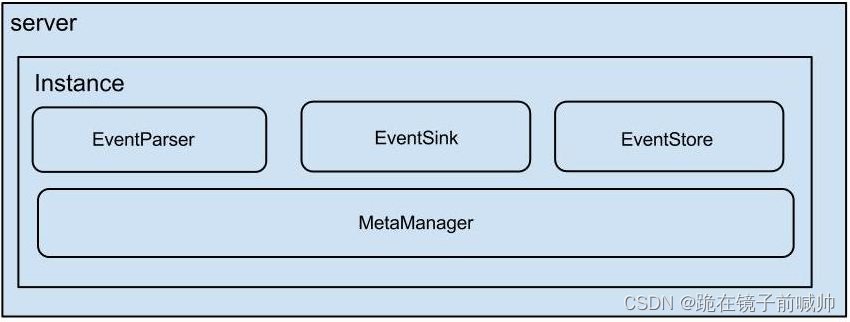
- server 代表一个 canal 运行实例,对应于一个 jvm
- instance 对应于一个数据队列 (1个 canal server 对应 1…n 个 instance )
- instance 下的子模块: eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析 eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作 eventStore: 数据存储 metaManager: 增量订阅 & 消费信息管理器
EventParser在向MySQL发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功 ),传送成功之后更新Log Position。流程图如下:
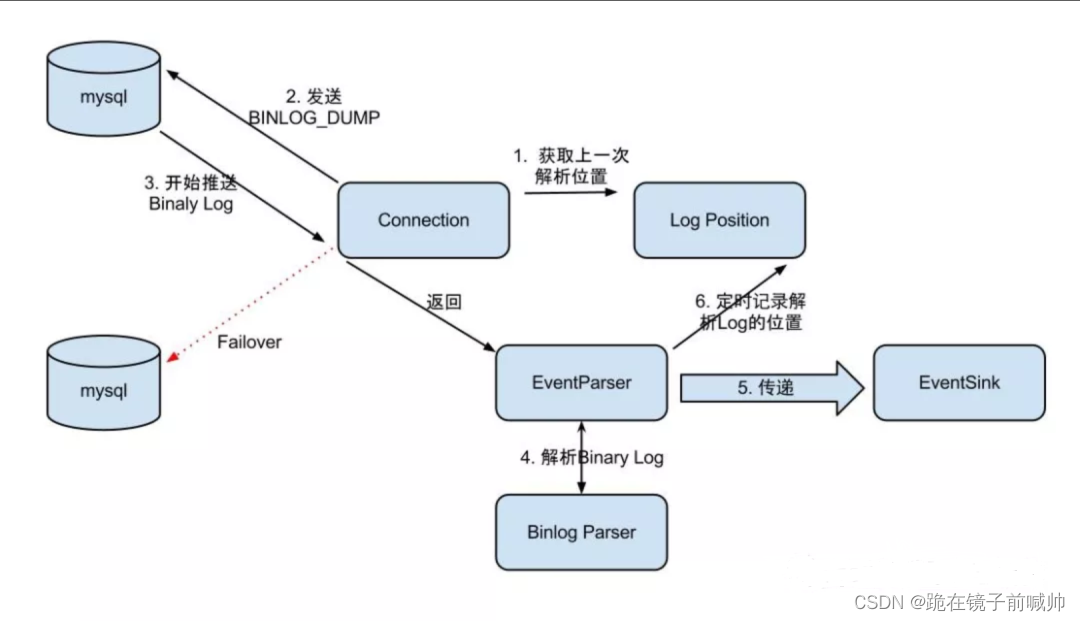
- EventSink起到一个类似channel的功能,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工。EventSink是连接EventParser和EventStore的桥梁。
- EventStore实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
- MetaManager是增量订阅&消费信息管理器,增量订阅和消费之间的协议包括get/ack/rollback,分别为:
MessagegetWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]voidrollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
voidack(long batchId),顾名思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
Canal环境搭建
准备
- 检查binlog功能是否有开启:show variables like ‘log_bin’,如果on则已开启,显示off则未开启。未开启需要先开启 Binlog 写入功能,配置 binlog-format 为ROW 模式,my.cnf (win下为my.ini)中配置如下
log-bin=mysql-bin #binlog文件名
binlog_format=ROW #选择row模式
server_id=1 #mysql实例id,不能和canal的slaveId重复
注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
MySQL的binLog
- STATEMENT 记录的是执行的sql语句
- ROW 记录的是真实的行数据记录
- MIXED 记录的是1+2,优先按照1的模式记录
- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATEUSER canal IDENTIFIEDBY'canal';GRANTSELECT,REPLICATIONSLAVE,REPLICATIONCLIENTON*.* TO'canal'@'%';--GRANTALLPRIVILEGESON*.* TO'canal'@'%';FLUSHPRIVILEGES;
启动
- 下载 canal, 访问 release 页面 , 选择需要的包下载, 如以 1.0.17 版本为例
- canal-adapter(canal-client) 相当于canal的客户端,会从canal-server中获取数据(需要配置为tcp方式),然后对数据进行同步,可以同步到MySQL、Elasticsearch和HBase等存储中去。相较于canal-server自带的canal.serverMode,canal-adapter提供的下游数据接受更为广泛。
- canal-admin 为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
- canal-deployer(canal-server) 可以直接监听MySQL的binlog,把自己伪装成MySQL的从库,只负责接收数据,并不做处理。接收到MySQL的binlog数据后可以通过配置canal.serverMode:tcp, kafka, rocketMQ, rabbitMQ连接方式发送到对应的下游。其中tcp方式可以自定义canal客户端进行接受数据,较为灵活。
- 配置修改,修改conf/example/instance.properties配置文件
#################################################
## mysql serverId , v1.0.26+ will autoGen
# mysql 集群配置中的serverId概念,需要保证和当前mysql集群中id唯一 (v1.1.x版本之后canal会自动生成,不需要手工指定)
canal.instance.mysql.slaveId=1212
# enable gtid use true/false
# 是否启用mysql gtid的订阅模式
canal.instance.gtidon=false
# position info
# mysql 主库链接地址
canal.instance.master.address=127.0.0.1:3306
# mysql 主库链接时起始的binlog文件
canal.instance.master.journal.name=
# mysql 主库链接时起始的binlog偏移量
canal.instance.master.position=
# mysql 主库链接时起始的binlog的时间戳
canal.instance.master.timestamp=
# mysql 主库链接时对应的gtid位点
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
# aliyun rds 对应的实例id信息(如果不需要在本地binlog超过18小时被清理后自动下载oss上的binlog,可以忽略该值)
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
# mysql 数据库帐号
canal.instance.dbUsername=canal
# mysql 数据库密码
canal.instance.dbPassword=canal
# mysql 数据解析编码,代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK,ISO-8859-1
canal.instance.connectionCharset =UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
# mysql 数据解析关注的表,Perl正则表达式,多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
# 注意:此过滤条件只针对row模式的数据有效(ps. mixed/statement因为不解析sql,所以无法准确提取tableName进行过滤)
canal.instance.filter.regex=.*\\..*
# table black regex
# mysql 数据解析表的黑名单,表达式规则见白名单的规则
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=yang
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
#如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
常见的匹配规则:
- 所有表:.* or .\…
- canal schema下所有表: canal\…*
- canal下的以canal打头的表:canal.canal.*
- canal schema下的一张表:canal.test1
- 多个规则组合使用:canal\…*,mysql.test1,mysql.test2 (逗号分隔)
- 进入bin目录下启动虚拟机的mysql
- sh bin/startup.sh(win下是运行 startup.bat)
工程搭建
- 修改pom.xml,添加依赖
# 服务端口
server.port=10000
# 服务名
spring.application.name=canal-client
# 环境设置:dev、test、prod
spring.profiles.active=dev
# mysql数据库连接
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/yang?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&useSSL=true&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=root
# 监听样例使用
# canal.client.instances.example.host=127.0.0.1
# canal.client.instances.example.port=11111
canal 依赖
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.0</version></dependency>
其他依赖(用则添加)
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
- 编写canal自定义客户端类(也可以使用canal-adapter)
官网样例
packagecom.example.canal.yang;importcom.alibaba.otter.canal.client.CanalConnector;importcom.alibaba.otter.canal.client.CanalConnectors;importcom.alibaba.otter.canal.protocol.CanalEntry.*;importcom.alibaba.otter.canal.protocol.Message;importorg.springframework.stereotype.Component;importjava.net.InetSocketAddress;importjava.util.List;@ComponentpublicclassCanalClient{privatefinalstaticintBATCH_SIZE=1000;/**
* @Description: canal 客户端
* @Author: yangjj_tc
* @Date: 2022/11/11 11:38
*/publicvoidrun()throwsException{// 创建链接CanalConnector connector =CanalConnectors.newSingleConnector(newInetSocketAddress("127.0.0.1",11111),"example","canal","canal");try{// 打开连接
connector.connect();// 订阅数据库表,来覆盖服务端初始化时的设置
connector.subscribe(".*\..*");// 回滚到未进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始拿
connector.rollback();while(true){// 获取指定数量的数据Message message = connector.getWithoutAck(BATCH_SIZE);// 获取批量IDlong batchId = message.getId();// 获取批量的数量int size = message.getEntries().size();// 如果没有数据if(batchId ==-1|| size ==0){try{// 线程休眠2秒Thread.sleep(2000);}catch(InterruptedException e){
e.printStackTrace();}}else{// 如果有数据,处理数据printEntry(message.getEntries());}// 进行 batch id 的确认
connector.ack(batchId);}}catch(Exception e){
e.printStackTrace();}finally{
connector.disconnect();}}/**
* @Description: canal server 解析binlog获得的实体类信息
* @Author: yangjj_tc
* @Date: 2022/11/11 11:37
*/privatestaticvoidprintEntry(List<Entry> entrys){for(Entry entry : entrys){if(entry.getEntryType()==EntryType.TRANSACTIONBEGIN|| entry.getEntryType()==EntryType.TRANSACTIONEND){// 开启/关闭事务的实体类型,跳过continue;}// RowChange对象,包含了一行数据变化的所有特征RowChange rowChage;try{
rowChage =RowChange.parseFrom(entry.getStoreValue());}catch(Exception e){thrownewRuntimeException("ERROR ## parser of eromanga-event has an error , data:"+ entry.toString(),
e);}// 获取操作类型:insert/update/delete类型EventType eventType = rowChage.getEventType();// 打印Header信息System.out.println(String.format("================》; binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));// 判断是否是DDL语句if(rowChage.getIsDdl()){System.out.println("================》;isDdl: true,sql:"+ rowChage.getSql());}// 获取RowChange对象里的每一行数据,打印出来for(RowData rowData : rowChage.getRowDatasList()){// 如果是删除语句if(eventType ==EventType.DELETE){printColumn(rowData.getBeforeColumnsList());// 如果是新增语句}elseif(eventType ==EventType.INSERT){printColumn(rowData.getAfterColumnsList());// 如果是更新的语句}else{// 变更前的数据System.out.println("------->; before");printColumn(rowData.getBeforeColumnsList());// 变更后的数据System.out.println("------->; after");printColumn(rowData.getAfterColumnsList());}}}}privatestaticvoidprintColumn(List<Column> columns){for(Column column : columns){System.out.println(column.getName()+" : "+ column.getValue()+" update="+ column.getUpdated());}}}
表数据同步样例
packagecom.example.canal.yang;importcom.alibaba.otter.canal.client.CanalConnector;importcom.alibaba.otter.canal.client.CanalConnectors;importcom.alibaba.otter.canal.protocol.CanalEntry.*;importcom.alibaba.otter.canal.protocol.Message;importcom.google.protobuf.InvalidProtocolBufferException;importorg.apache.commons.dbutils.DbUtils;importorg.apache.commons.dbutils.QueryRunner;importorg.springframework.stereotype.Component;importjavax.annotation.Resource;importjavax.sql.DataSource;importjava.net.InetSocketAddress;importjava.sql.Connection;importjava.sql.SQLException;importjava.util.List;importjava.util.Queue;importjava.util.concurrent.ConcurrentLinkedQueue;@ComponentpublicclassCanalClient{privateQueue<String>SQL_QUEUE=newConcurrentLinkedQueue<>();@ResourceprivateDataSource dataSource;publicvoidrun(){CanalConnector connector =CanalConnectors.newSingleConnector(newInetSocketAddress("127.0.0.1",11111),"example","","");int batchSize =1000;try{
connector.connect();
connector.subscribe("canal.canal_test");
connector.rollback();try{while(true){Message message = connector.getWithoutAck(batchSize);long batchId = message.getId();int size = message.getEntries().size();if(batchId ==-1|| size ==0){Thread.sleep(1000);}else{dataHandle(message.getEntries());}
connector.ack(batchId);if(SQL_QUEUE.size()>=1){executeQueueSql();}}}catch(InterruptedException e){
e.printStackTrace();}catch(InvalidProtocolBufferException e){
e.printStackTrace();}}finally{
connector.disconnect();}}privatevoiddataHandle(List<Entry> entrys)throwsInvalidProtocolBufferException{for(Entry entry : entrys){if(EntryType.ROWDATA== entry.getEntryType()){RowChange rowChange =RowChange.parseFrom(entry.getStoreValue());EventType eventType = rowChange.getEventType();if(eventType ==EventType.DELETE){saveDeleteSql(entry);}elseif(eventType ==EventType.UPDATE){saveUpdateSql(entry);}elseif(eventType ==EventType.INSERT){saveInsertSql(entry);}}}}privatevoidsaveDeleteSql(Entry entry){try{RowChange rowChange =RowChange.parseFrom(entry.getStoreValue());List<RowData> rowDatasList = rowChange.getRowDatasList();for(RowData rowData : rowDatasList){List<Column> columnList = rowData.getBeforeColumnsList();StringBuffer sql =newStringBuffer("delete from "+ entry.getHeader().getTableName()+" where ");for(Column column : columnList){if(column.getIsKey()){// 暂时只支持单一主键
sql.append(column.getName()+"="+ column.getValue());break;}}SQL_QUEUE.add(sql.toString());}}catch(InvalidProtocolBufferException e){
e.printStackTrace();}}privatevoidsaveUpdateSql(Entry entry){try{RowChange rowChange =RowChange.parseFrom(entry.getStoreValue());List<RowData> rowDatasList = rowChange.getRowDatasList();for(RowData rowData : rowDatasList){List<Column> newColumnList = rowData.getAfterColumnsList();StringBuffer sql =newStringBuffer("update "+ entry.getHeader().getTableName()+" set ");for(int i =0; i < newColumnList.size(); i++){
sql.append(" "+ newColumnList.get(i).getName()+" = '"+ newColumnList.get(i).getValue()+"'");if(i != newColumnList.size()-1){
sql.append(",");}}
sql.append(" where ");List<Column> oldColumnList = rowData.getBeforeColumnsList();for(Column column : oldColumnList){if(column.getIsKey()){// 暂时只支持单一主键
sql.append(column.getName()+"="+ column.getValue());break;}}SQL_QUEUE.add(sql.toString());}}catch(InvalidProtocolBufferException e){
e.printStackTrace();}}privatevoidsaveInsertSql(Entry entry){try{RowChange rowChange =RowChange.parseFrom(entry.getStoreValue());List<RowData> rowDatasList = rowChange.getRowDatasList();for(RowData rowData : rowDatasList){List<Column> columnList = rowData.getAfterColumnsList();StringBuffer sql =newStringBuffer("insert into "+ entry.getHeader().getTableName()+" (");for(int i =0; i < columnList.size(); i++){
sql.append(columnList.get(i).getName());if(i != columnList.size()-1){
sql.append(",");}}
sql.append(") VALUES (");for(int i =0; i < columnList.size(); i++){
sql.append("'"+ columnList.get(i).getValue()+"'");if(i != columnList.size()-1){
sql.append(",");}}
sql.append(")");SQL_QUEUE.add(sql.toString());}}catch(InvalidProtocolBufferException e){
e.printStackTrace();}}publicvoidexecuteQueueSql(){int size =SQL_QUEUE.size();for(int i =0; i < size; i++){String sql =SQL_QUEUE.poll();System.out.println("[sql]----> "+ sql);this.execute(sql.toString());}}publicvoidexecute(String sql){Connection con =null;try{if(null== sql)return;
con = dataSource.getConnection();QueryRunner qr =newQueryRunner();int row = qr.execute(con, sql);System.out.println("update: "+ row);}catch(SQLException e){
e.printStackTrace();}finally{DbUtils.closeQuietly(con);}}}
注解监听样例(依赖下载不下来用这个导入到项目)
<dependency>
<groupId>com.xpand</groupId>
<artifactId>starter-canal</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
packagecom.example.canal.yang;importcom.alibaba.otter.canal.protocol.CanalEntry;importcom.xpand.starter.canal.annotation.*;@CanalEventListenerpublicclassCanalDataEventListener{/**
* @Description: 增加数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:16
*/@InsertListenPointpublicvoidonEventInsert(CanalEntry.EventType eventType,CanalEntry.RowData rowData){
rowData.getAfterColumnsList().forEach((c)->System.out.println("By--Annotation: "+ c.getName()+" :: "+ c.getValue()));}/**
* @Description: 修改数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:17
*/@UpdateListenPointpublicvoidonEventUpdate(CanalEntry.RowData rowData){System.out.println("UpdateListenPoint");
rowData.getAfterColumnsList().forEach((c)->System.out.println("By--Annotation: "+ c.getName()+" :: "+ c.getValue()));}/**
* @Description: 删除数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:17
*/@DeleteListenPointpublicvoidonEventDelete(CanalEntry.EventType eventType){System.out.println("DeleteListenPoint");}/**
* @Description: 自定义数据监听
* @Author: yangjj_tc
* @Date: 2022/11/11 15:18
*/@ListenPoint(destination ="example", schema ="canal", table ={"canal_test","tb_order"},
eventType =CanalEntry.EventType.UPDATE)publicvoidonEventCustomUpdate(CanalEntry.EventType eventType,CanalEntry.RowData rowData){System.err.println("DeleteListenPoint");
rowData.getAfterColumnsList().forEach((c)->System.out.println("By--Annotation: "+ c.getName()+" :: "+ c.getValue()));}@ListenPoint(destination ="example", schema ="canal",// 所要监听的数据库名
table ={"canal_test"},// 所要监听的数据库表名
eventType ={CanalEntry.EventType.UPDATE,CanalEntry.EventType.INSERT,CanalEntry.EventType.DELETE})publicvoidonEventCustomUpdateForTbUser(CanalEntry.EventType eventType,CanalEntry.RowData rowData){getChangeValue(eventType, rowData);}publicstaticvoidgetChangeValue(CanalEntry.EventType eventType,CanalEntry.RowData rowData){if(eventType ==CanalEntry.EventType.DELETE){
rowData.getBeforeColumnsList().forEach(column ->{// 获取删除前的数据System.out.println(column.getName()+" == "+ column.getValue());});}else{
rowData.getBeforeColumnsList().forEach(column ->{// 打印改变前的字段名和值System.out.println(column.getName()+" == "+ column.getValue());});
rowData.getAfterColumnsList().forEach(column ->{// 打印改变后的字段名和值System.out.println(column.getName()+" == "+ column.getValue());});}}}
- 触发数据库变更
开始测试,首先启动MySQL、Canal Server,还有刚刚写的Spring Boot项目。然后创建表:
DROPTABLEIFEXISTS `canal_test`;CREATETABLE `canal_test` (
`id` intNOTNULL,
`name` varchar(255)CHARACTERSET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOTNULL,
`age` intNOTNULL,PRIMARYKEY(`id`)USINGBTREE)ENGINE=InnoDBCHARACTERSET= utf8mb4 COLLATE= utf8mb4_0900_ai_ci ROW_FORMAT=Dynamic;
如果新增一条数据到表中:
INSERTINTO `yang`.`canal_test` (`id`, `name`, `age`)VALUES(1,'1',1);

总结
canal的好处在于对业务代码没有侵入,因为是基于监听binlog日志去进行同步数据的。实时性也能做到准实时,其实是很多企业一种比较常见的数据同步的方案。
通过上面的学习之后,我们应该都明白canal是什么,它的原理,还有用法。实际上这仅仅只是入门,实际项目我们是配置MQ模式,配合RocketMQ或者Kafka,canal会把数据发送到MQ的topic中,然后通过消息队列的消费者进行处理。
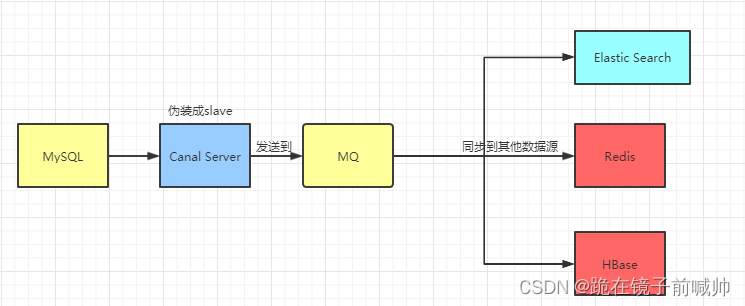
Canal的部署也是支持集群的,需要配合ZooKeeper进行集群管理。
Canal还有一个简单的Web管理界面。
版权归原作者 跪在镜子前喊帅 所有, 如有侵权,请联系我们删除。