
**一. **Spark概述
(1)Spark是一种快速、通用、可扩展的大数据分析引擎计算引擎。
这一站式的计算框架,包含了Spark RDD(这也是Spark Core用于离线批处理)、Spark SQL(交互式查询)、Spark Streaming(实时流计算)、MLlib(机器学习)、GraphX(图计算)等重要处理组件。
(2)spark官方网址:Apache Spark™ - Unified Engine for large-scale data analytics
二.Spark的特点
运行速度快
易于使用
通用性强
适用环境广
速度快:
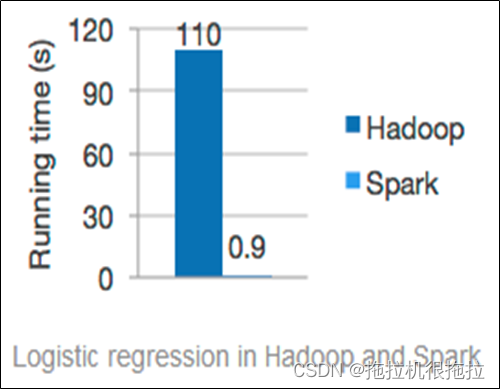
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
易于使用:
可以使用Java,Scala,Python,R,SQL快速写一个Spark应用。
Spark提供了超过80中操作使它更容易生成平行化的应用。它也可以使用Scala,Python,R,SQL shell 进行交互操作。

通用性强:
在Spark的基础上,Spark还提供了包括Spark SQL、Spark Streaming(流计算)、MLlib(机器学习库)及GraphX(图计算)在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。

运行方式:
Spark支持多种运行方式,包括在Hadoop和Mesos上,也支持Standalone的独立运行模式,同时也可以运行在云Kuberbetes上。对于数据源而言,Spark支持从HDFS、HBase、Cassandra及Kafka等多种途径获取数据。

(2)Spark的最大特点:基于内存
三. Spark VS Hadoop(MapReduce)
(1)Spark和Hadoop
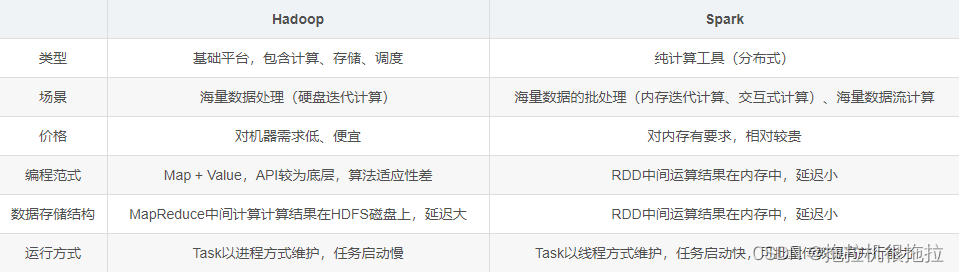
Spark
:是分布式计算平台,是一个用scala语言编写的计算框架。
Hadoop
:是分布式管理、存储、计算的生态系统;其中包括三大部分:HDFS(存储)、 MapReduce(计算)、Yarn(资源调度)
(1)在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今任有许多计算工具基于MR架构,比如非常熟悉的Hive
(2)Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
四.结构化数据、非结构化数据和半结构化数据
(1)结构化数据(Structured Data)
定义:结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。
结构化数据,简单来说就是数据库。结合到典型场景中更容易理解,比如企业ERP、财务系统;医疗HIS数据库;教育一卡通;政府行政审批;其他核心数据库等。基本包括高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。
(2)非结构化数据(Unstructure Data)
定义:非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML, HTML、各类报表、图像和音频/视频信息等等。
非结构化数据其格式非常多样,标准也是多样性的,而且在技术上非结构化信息比结构化信息更难标准化和理解。支持非结构化数据的数据库广泛应用于全文检索和各种多媒体信息处理领域。
(3)半结构化数据(Semi-structured Data)
定义:所谓半结构化数据,就是介于结构化数据(如关系型数据库、面向对象数据库 中的数据)和非结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
五.Spark集群的三种部署模式
Spark有主要有三种部署模式:Spark独立服务器模式、基于YARN的Spark、基于Mesos的Spark
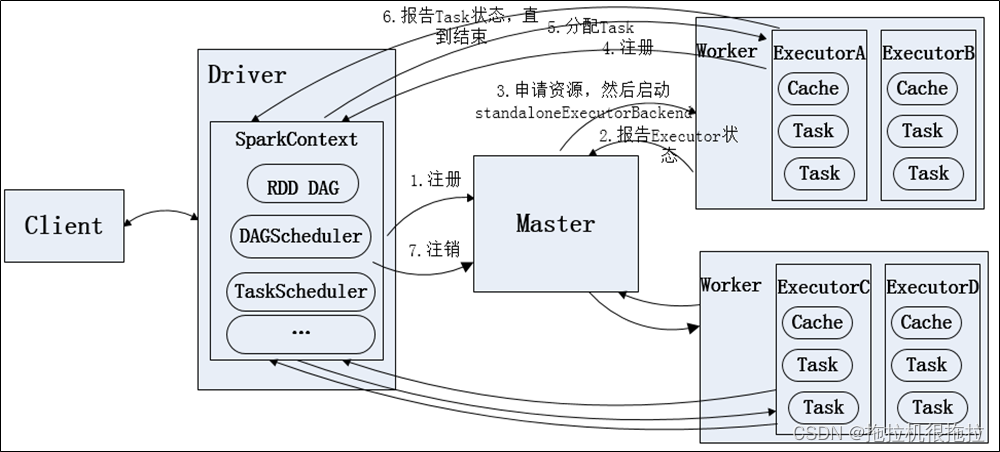
(1)Standalone模式
即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖其它任何资源管理系统。从一定程度上讲是其它两种模式的基础。借助Spark开发模式,我们可以得到一种开发新型计算框架的一般思路。
Standalone模式运行流程
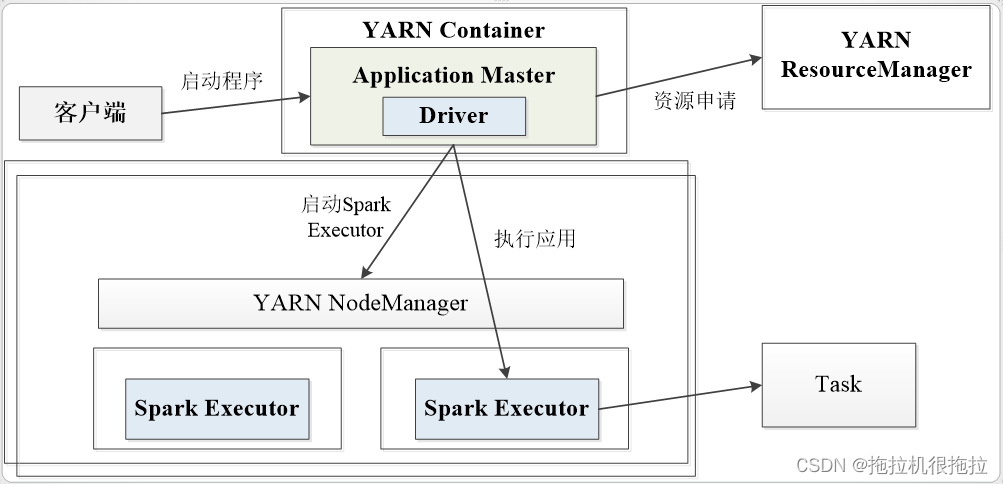
(2)yarn集群模式
在集群模式下,driver在集群中的某个节点(一般是应用程序的主节点)上运行。客户端首先与资源管理器通信,请求资源并运行Spark作业。资源管理器会分配容器(0号容器)并响应客户端。然后客户端向集群提交代码,并在0号容器内启动driver和Spark应用主节点。driver与Spark应用主节点协同工作,然后在由资源管理器分配的容器上创建executor。
YARN容器可位于由节管理器控制的任何容器上。因此所有的资源分配都由资源管理器负责。
Spark应用主节点与资源管理器进行沟通,以获取其他容器来启动executor。
在YARN集群模式下,没有shell,因为driver本身在YARN内部
yarn-cluster运行流程
(3)yarn客户端模式
在YARN客户端模式下,driver在集群之外的节点(一般都是客户端节点)上运行。driver首先需要与资源管理器通信,从而请求资源并运行Spark作业。资源管理器会分配容器(0号容器)并响应driver。driver在0号容器中启动Spark应用主节点。Spark应用主节点在资源管理器分配的容器中创建executor。YARN容器可位于集群中由节点管理器控制的任一节点,因此所有的资源分配都由资源管理器负责。Spark应用主节点与资源管理器进行沟通,以获取其他容器来启动executor
yarn-client运行流程

yarn-cluster和yarn-client区别:
(1)SparkContext初始化不同,这也导致了Driver所在位置的不同,YarnCluster的Driver是在集群的某一台NM上,但是Yarn-Client就是在client机器上;
(2)而Driver会和Executors进行通信,这也导致了Yarn_cluster在提交App之后可以关闭Client,而Yarn-Client不可以;
(3)最后再来说应用场景,Yarn-Cluster适合生产环境,Yarn-Client适合交互和调试。
六.Spark核心数据集RDD
(1)RDD(ResilientDistributedDatasets弹性分布式数据集),可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。
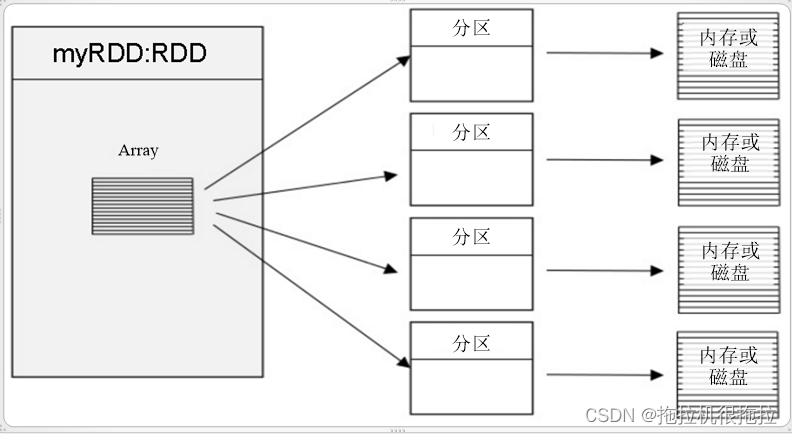
(2)转换算子和行动算子

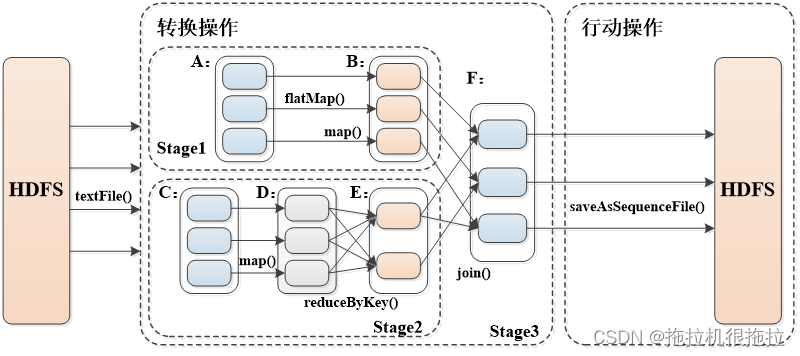
(3)Spark RDD转换和操作示例
(4)宽依赖与窄依赖
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
窄依赖 (Narrow Dependency)
:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
宽依赖(Shuffle Dependency)
:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。

(5)RDD Stage划分
Stage划分算法原理:Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分成互相依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务,然后将这些task以taskSet的形式提交给TaskScheduler运行。
stage切割规则:从后往前,遇到宽依赖就切割stage
Stage概念:由一组并行的task组成
**Task:**Task是在集群上运行的基本单位。一个Task负责处理RDD的一个partition。RDD的多个patition会分别由不同的Task去处理。这些Task的处理逻辑完全是一致的。这一组Task就组成了一个Stage。

版权归原作者 拖拉机很拖拉 所有, 如有侵权,请联系我们删除。