
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
1.高可靠性
Hadoop按位存储和处理数据的能力值得人们信赖 [3] 。
2.高扩展性
Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 。
3.高效性
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
4.高容错性
Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 。
5.低成本
与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低 。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++ [3] 。
Hadoop大数据处理的意义
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里 。
提示:以下是本篇文章正文内容,下面案例可供参考
一、安装Linux镜像文件
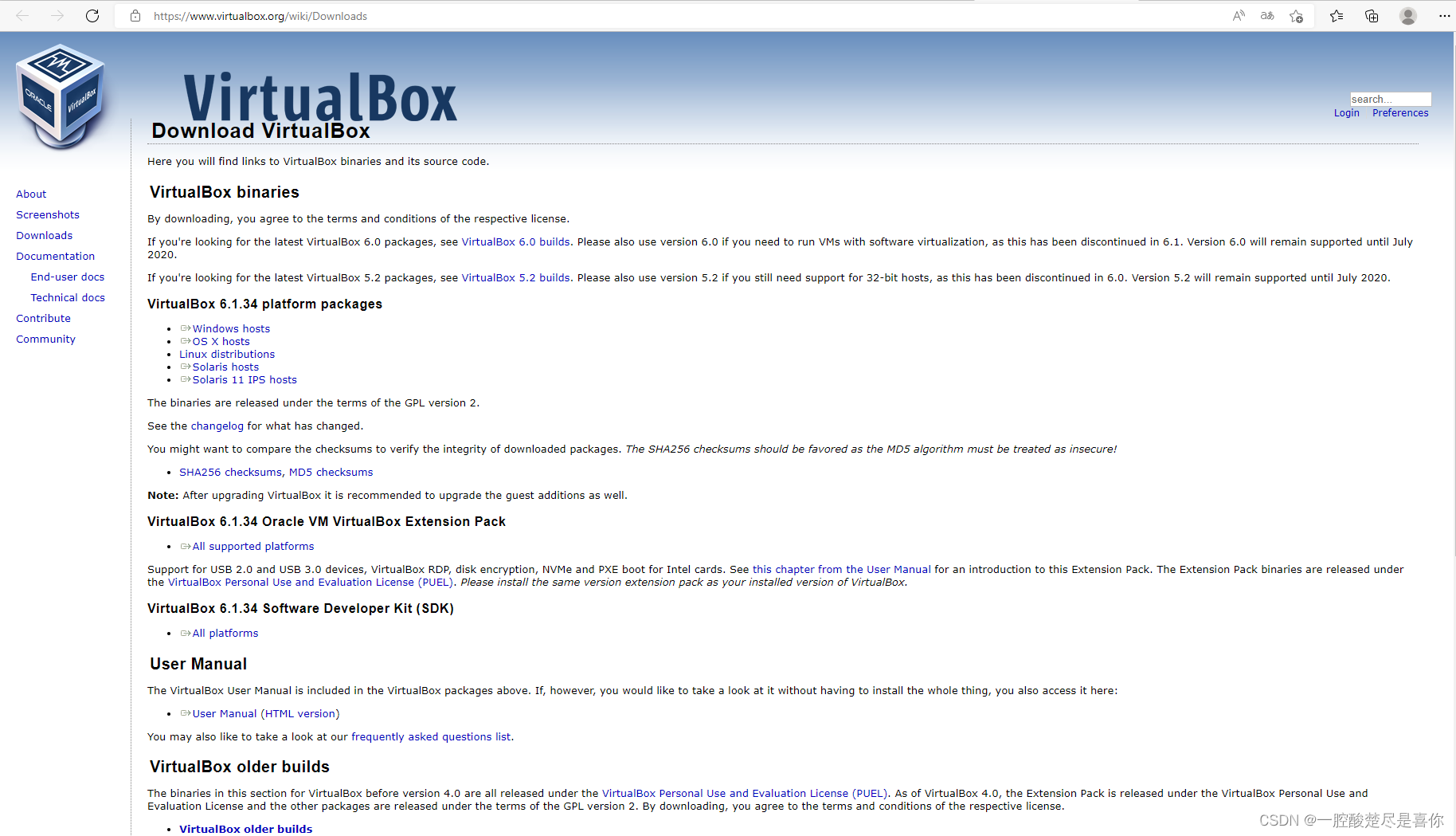
1.从官网上下载Oracle官网上下载virtual Box ,从Ubuntu官网下载系统。
Oracle VirtualBox
https://www.virtualbox.org/wiki/Downloads
Ubuntu20.04
https://ubuntu.com/wsl
2.安装Virtual Box和虚拟机系统
2.1 VirtualBox安装启动。

2.2 VirtualBox安装启动后,新建虚拟电脑。

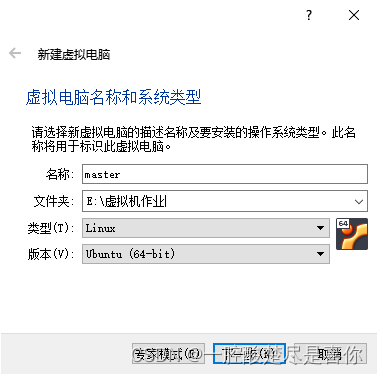
2.3新建虚拟电脑的相关配置。
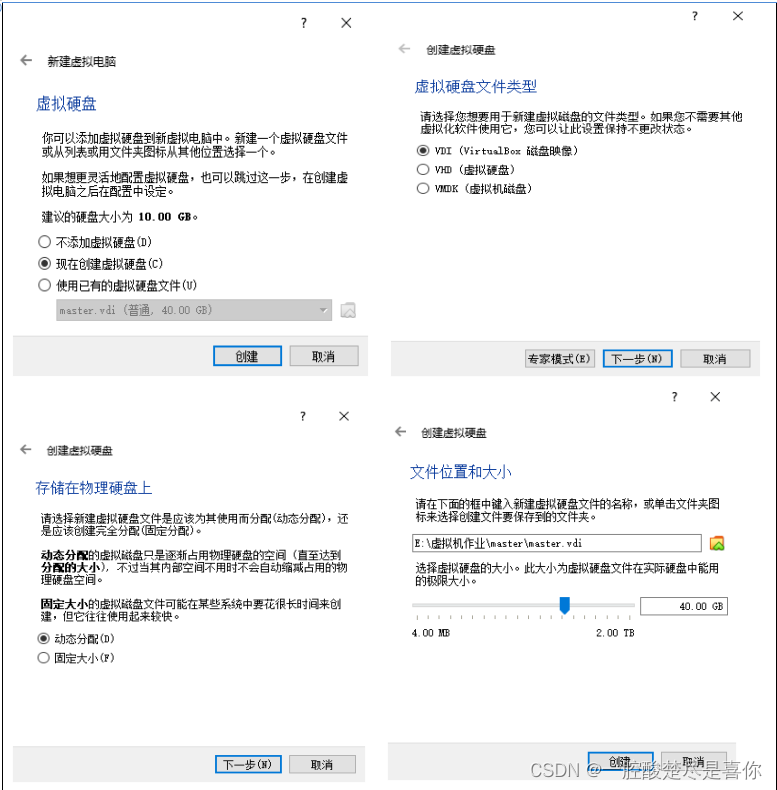
2.4选择启动盘,虚拟机的镜像文件,(本次为Ubuntu20.04版本)。

2.5耐心等待系统安装。

二、打开命令窗口,创建Hadoop用户
$sudo useradd -m hadoop -s /bin/bash //新增hadoop⽤户
$sudo passwd hadoop // 为"hadoop"⽤户设置密码;
$sudo adduser hadoop sudo //为"hadoop"⽤户添加管理员权限;
注销当前账户,使⽤hadoop账户登录
三、更新安排apt和安装Vim编译器
1.更新apt
$sudo apt-get update //更新客户/服务器系统
2.下载vim编译器
$sudo apt-get install vim //下载vim编译器,后续会用到
四、 安装SSH和配置ssh免密登录
1.下载SSH服务端和客户端
$sudo apt-get install openssh-server //ssh下载
2.登录本机
$ssh localhost //输入 'yes',登录本机,每次登录都需密码
3.配置无密码登录
$exit //退出登录
$cd ~/.ssh///切换到ssh目录
$ssh-keygen -t rsa //生成密钥
$cat ./id_rsa/pub >>./authorized_keys //将密钥添加到公钥中
4.无密码登录
$ssh localhost //本次登录无需输入密码
五、安装JAVA环境(安装jdk)
1.下载jdk1.8
https://download.oracle.com/java/18/latest/jdk-18_linux-aarch64_bin.tar.gz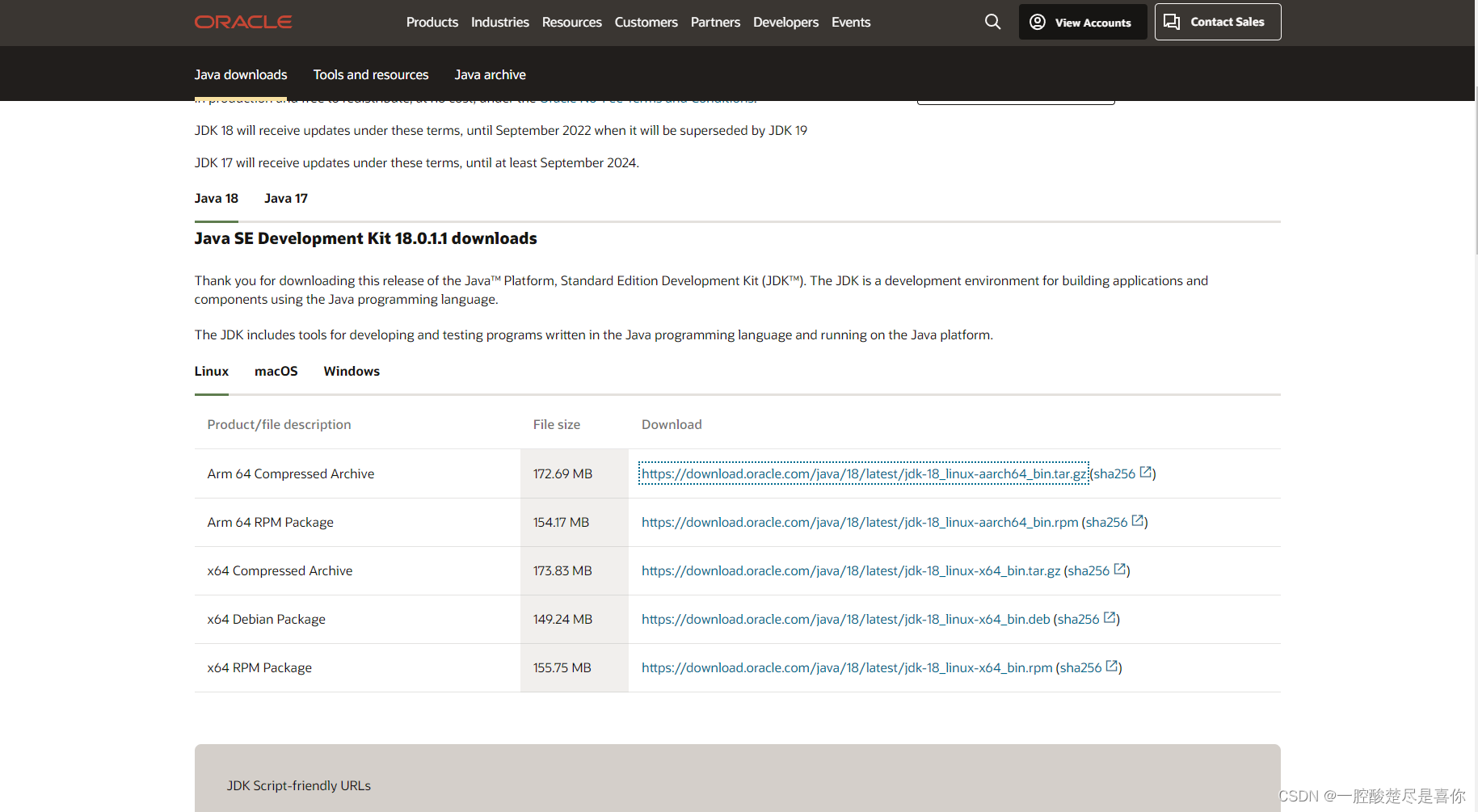
2.打开命令窗口,创建存放jdk文件的目录。
$cd /usr/lib
$sudo mkdir jvm //创建jvm目录,存放JDK文件
3.解压缩jdk压缩包
$cd ~/Downloads //jdk压缩包的位置
$sudo tar -zxvf ./jdk-8u152-linux-x64.tar.gz -C /usr/lib/jvm //根据压缩包版本名称解压
4.配置java环境变量
$sudo vim ~/.bashrc
//按键i进入vim插入模式,在开头添加,跟据所下版本写入,本次采用的是jdk1.8.0_152版本
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_152
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH //将jdk⽬录下可执⾏⽂件加⼊到系统PATH中//写完成后,键盘依次 Esc :wq 保存并推出
$source ~/.bashrc //配置环境变量生效
$java -version //查看java版本//若屏幕显示返回如下信息,则说明安装成功。
java version "1.8.0_152"Java(TM) SE Runtime Environment(build 1.8.0_152-b16)
Java HotSpot(TM)64-Bit Server VM(build 25.152-b16, mixed mode)
六、安装单机Hadoop
1.从Apach官网上下载Hadoop 2.10.1版本
https://downloads.apache.org/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
2.解压安装Hadoop2.10.1
$cd ~/Downloads //切换到Hadoop安装包的位置
$sudo tar -zxf ./hadoop-2.10.1.tar.gz -C /usr/local //将Hadoop解压到/usr/local目录下
$cd /usr/local
$sudo mv ./hadoop-2.10.1/./hadoop //将目录名改为hadoop
$sudo chown -R hadoop ./hadoop //修改目录权限
3.配置Hadoop 环境变量
$sudo vim ~/.bashrc //打开环境变量目录写入
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
4.查看Hadoop版本信息
$hadoop version //查看版本信息/*若屏幕显示返回如下信息,则说明安装成功。
Hadoop 2.10.1
Subversion https://github.com/apache/hadoop -r 1827467c9a56f133025f28557bfc2c562d78e816
Compiled by centos on 2020-09-14T13:17Z
Compiled with protoc 2.5.0
From source with checksum 3114edef868f1f3824e7d0f68be03650
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.10.1.jar
*/
七、配置相关文件
1.配置core-site.xml
$cd /usr/local/hadoop/etc/hadoop //切换到Hadoop目录
$sudo vim core-site.xml //打开core-site.xml文件//在区域内添加<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abasefor other temporary directories.</description></property></configuration>
1.配置hdfs-sitexml
$sudo vim hdfs-site.xml //打开hdfs目录//在区域内添加<configuration><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/dfs/data</value></property><property><name>dfs.replication</name><value>1</value></property></configuration>
八、运行与测试
$hdfs namenode -format //文件系统初始化,后续不用多次初始化
$start-dfs.sh //启动HDFS
$jps //查看进程8885 jps
8072 NameNode
8412 SecondaryNameNode
8223 DataNode
//得到类似结果
总结
以上就是今天要讲的内容,本文仅仅简单介绍了Hadoop单机版的安装,而Hadoop平台提供了许多的功能供我们快速便捷地分布式处理数据,后续我将会不断更新安装文章,供大家参考。
版权归原作者 一腔酸楚尽是喜你 所有, 如有侵权,请联系我们删除。