
范式建模
1) 范式建模-概念与特点
在数据仓库中采取范式建模法,主要由Inmon 所提倡,核心是为解决关系型数据库中数据存储,而利用的一种技术层面上的方法。目前,我们在关系型数据库中的建模方法,大部分采用的是三范式建模法。在数据仓库的模型设计中,如果采取范式建模法,一般也要遵从第三范式。
一个符合第三范式的关系必须具有以下三个条件 :
1、 每个属性值唯一,不具有多义性 ;
2、每个非主属性必须完全依赖于整个主键,而非主键的一部分 ;
3、 每个非主属性不能依赖于其他关系中的属性,因为这样的话,
这种属性应该归到其他关系中去。
2) 范式建模-案例
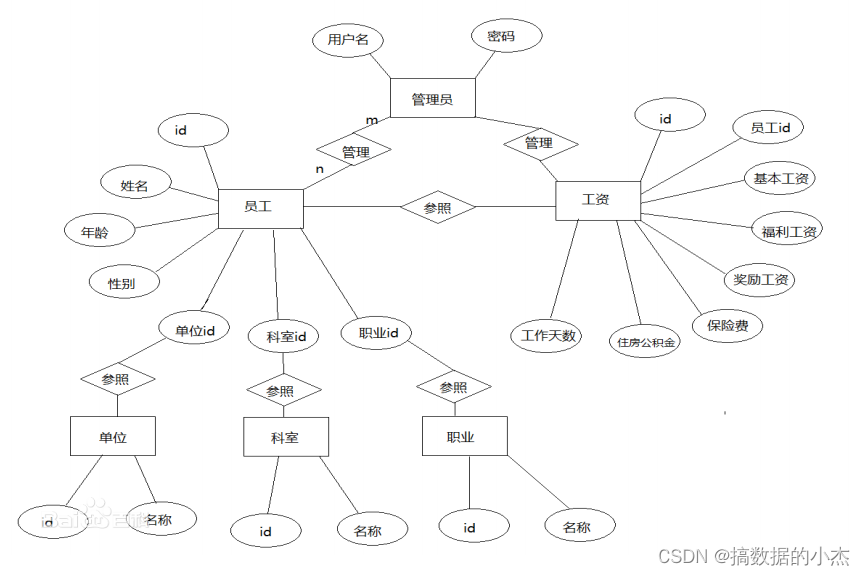

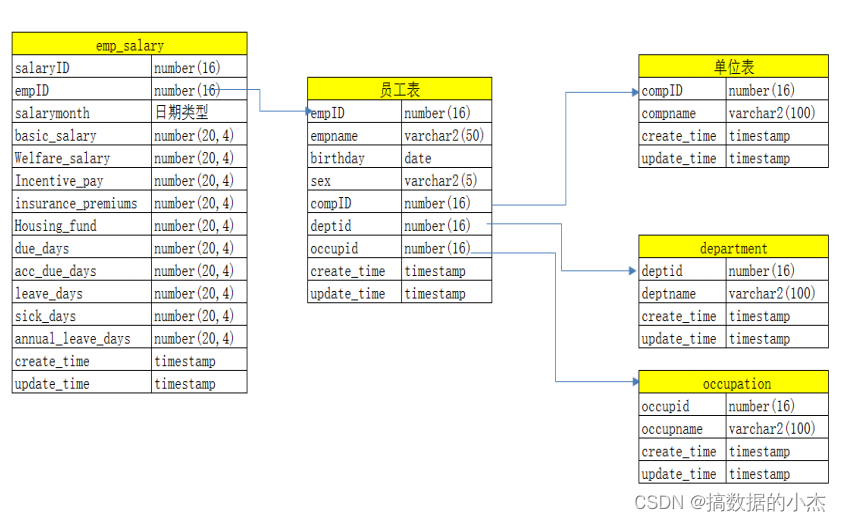
维度建模(dimensional modeling)
专门用于分析型数据库、数据仓库、数据集市建模的方法。 它本身属于一种关系建模方法,但和之前在操作型数据库中介绍的关系建模方法相比增加了两个概念:
1. 维度表(dimension) 表示对分析主题所属类型的描述。
2. 事实表(fact table) 表示对分析主题的度量。
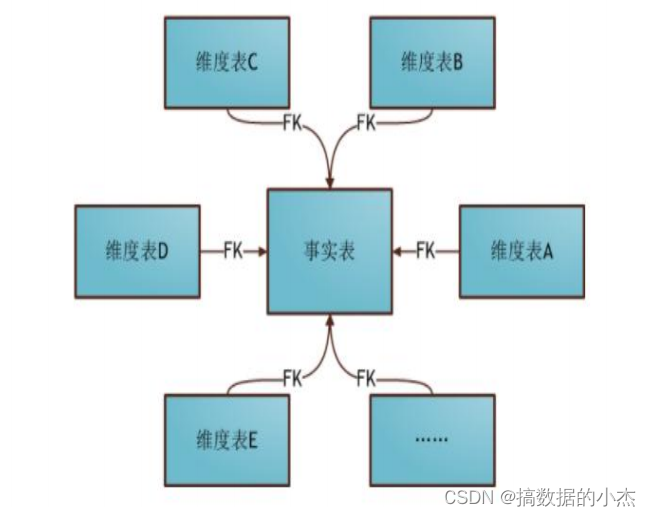
维度建模---星型模型
星型模式是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样。
维度建模---雪花模型
雪花模式的维度表可以拥有其他维度表的,虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能也比星型模型要低。所以一般不是很常用。

维度建模---星座模型
星座模式是星型模式延伸而来,星型模式是基于一张事实表的,而星座模式是基于多张事实表的,而且共享维度信息。 前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。 在业务发展后期,绝大部分维度建模都采用的是星座模式。

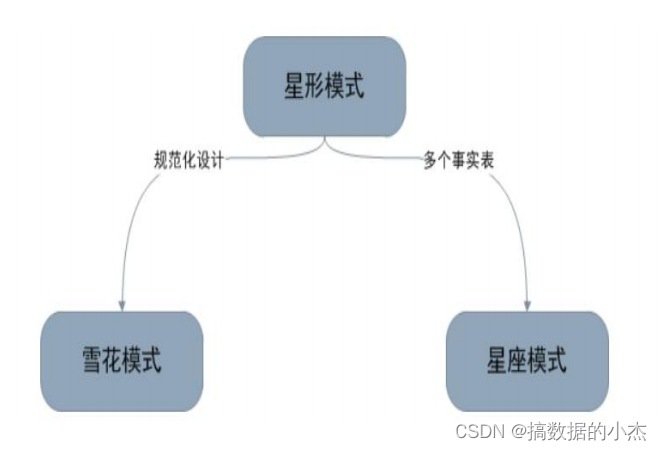
** 三种模型之间的关系**
维度建模过程
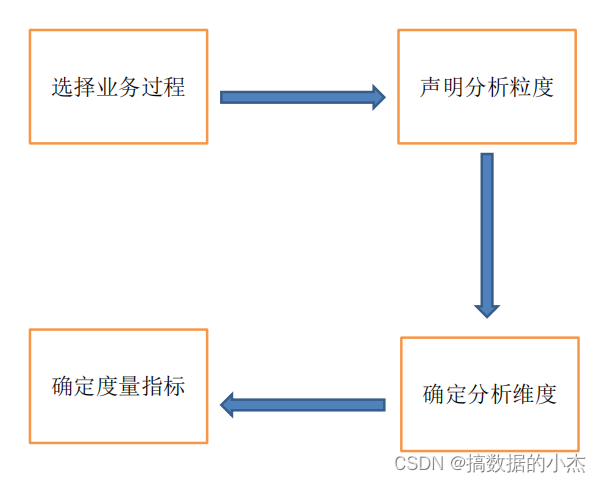
第一步 选取业务处理
业务处理过程是组织机构中进行的一般都由源系统提供支持的[自然业务活动]。要记住的重要一点是,这里谈到的业务处理过程并不是指业务部门或者职能。
第二步 定义粒度
粒度定义意味着对各事实表行实际代表的内容给出明确的说明。 粒度传递了同事实表度量值相联系的细节所达到的程度方面的信息。它给出了后面这个问题的答案:“如何描述事实表的单个行?”。 粒度定义是不容轻视的至关重要的步骤。 在定义粒度时应优先考虑为业务处理获取最有原子性的信息而开发维度模型。 原子型数据是所收集的最详细的信息,是高维度结构化的。 度量值越细微并具有原子性,就越能够确切地知道更多的事情。 原子型数据可为分析方面提供最大限度的灵活性,维度模型的细节性数据是稳如泰山的,并随时准备接受业务用户的特殊攻击。
第三步 选定维度
维度所引出的问题是,“业务人员将如何描述从业务处理过程得到的数据?”应该用一组在每个度量上下文中取单一值而代表了所有可能情况的丰富描述,将事实表装扮起来。 常见维度的例子包括日期、产品、客户、账户和机构等。
第四步 确定事实(度量指标)
事实的确定可以通过回答“要对什么内容进行评测”这个问题来进行。
1、针对某个特定的行为动作,建立一个以行为活动最小单元为粒度的事实表。
2、针对某个实体对象在当前时间上的状况。我们通过对这个实体对象在不同阶段存储它的快照。
3、针对业务活动中的重要分析和跟踪对象,统计在整个企业不同业务活动中的发生情况。
本文转载自: https://blog.csdn.net/n2670820434/article/details/140159924
版权归原作者 搞数据的小杰 所有, 如有侵权,请联系我们删除。
版权归原作者 搞数据的小杰 所有, 如有侵权,请联系我们删除。