
先看看实时分析的Demo效果演示

Demo说明:
- 这个汽车下单Demo支持在PC端进行下单操作,同时也支持多人通过手机扫码在线下单
- 订单数据被实时写入OceanBase TP数据库,并通过Flink CDC 实时同步到OceanBase AP数据库。Demo中的分析看板从AP库中查询最新的数据进行展示。
- 无论是执行简单的
count(*)计数查询,还是进行包含where、group by、order by等多条件的查询,系统都能在近亿级别的数据规模下,保证查询耗时基本在10ms到100ms之间,这充分体现了OceanBase AP数据库的查询性能。(此查询耗时已包含了后端到数据库之间的网络延时,因此数据库内部实际的SQL执行耗时将会更低) - 只建了主键索引。
Demo实现
准备数据库
- TP 数据库: OB 4.3.0 行存 + 开启 Binlog 服务
- AP 数据库: OB 4.3.0 列存
使用 OBCloud 阿里云版本
- 为了降低搭建成本,方便后续和 Flink 以及应用进行集成,直接使用 OBCloud 阿里云版本,数据库配置如下: - OB 版本 4.3.0.1,目前该版本在 OBCloud 需要开通白名单才能购买,具体可以联系官方技术服务同学进行开通。- 我这里购买一个按需付费的集群实例,3 节点,节点规格为 14C70G,价格 ¥32/小时。如果只用于测试,可以申请 🎉 OB Cloud 的 30 天免费试用,最低规格的 1C4G 就可以满足需求。
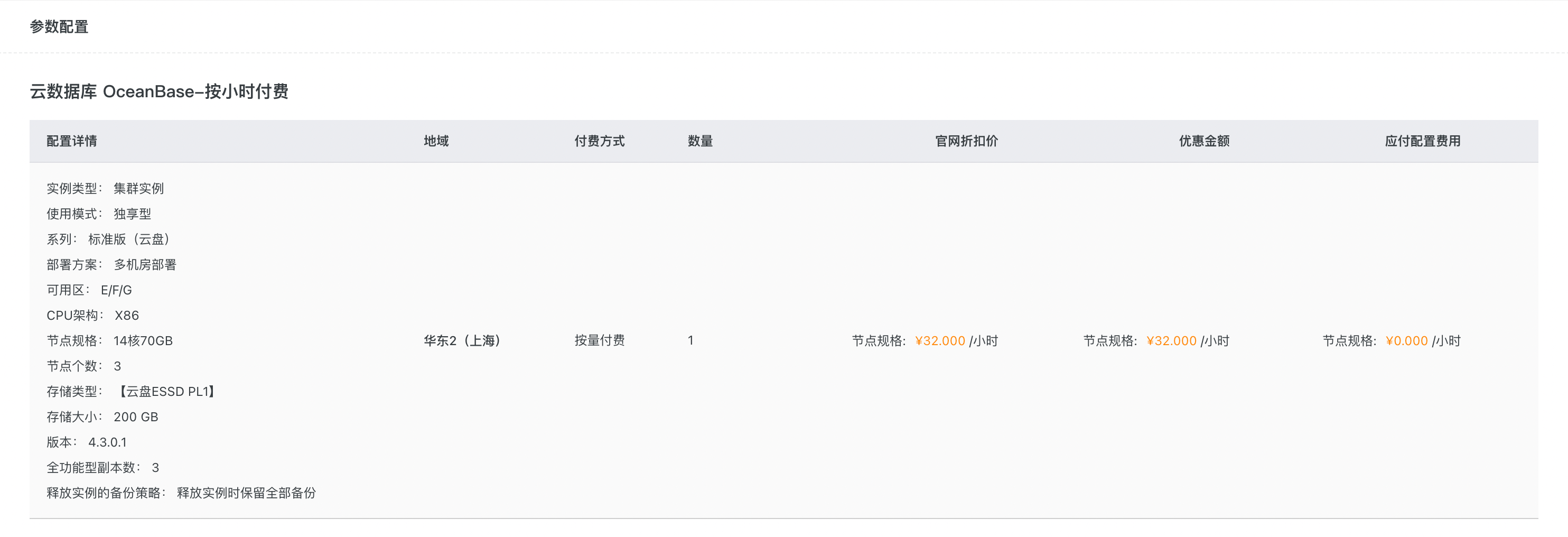
- 在集群实例下创建了 oltp 和 olap 两个租户,用作 TP 和 AP 库,配置如下:

- 在两个租户下分别创建数据库、访问账号,并配置 IP 白名单和公网访问地址,然后就能得到数据库连接串。具体过程不赘述,可以参考我之前的文章 使用阿里云的 OceanBase 云服务。
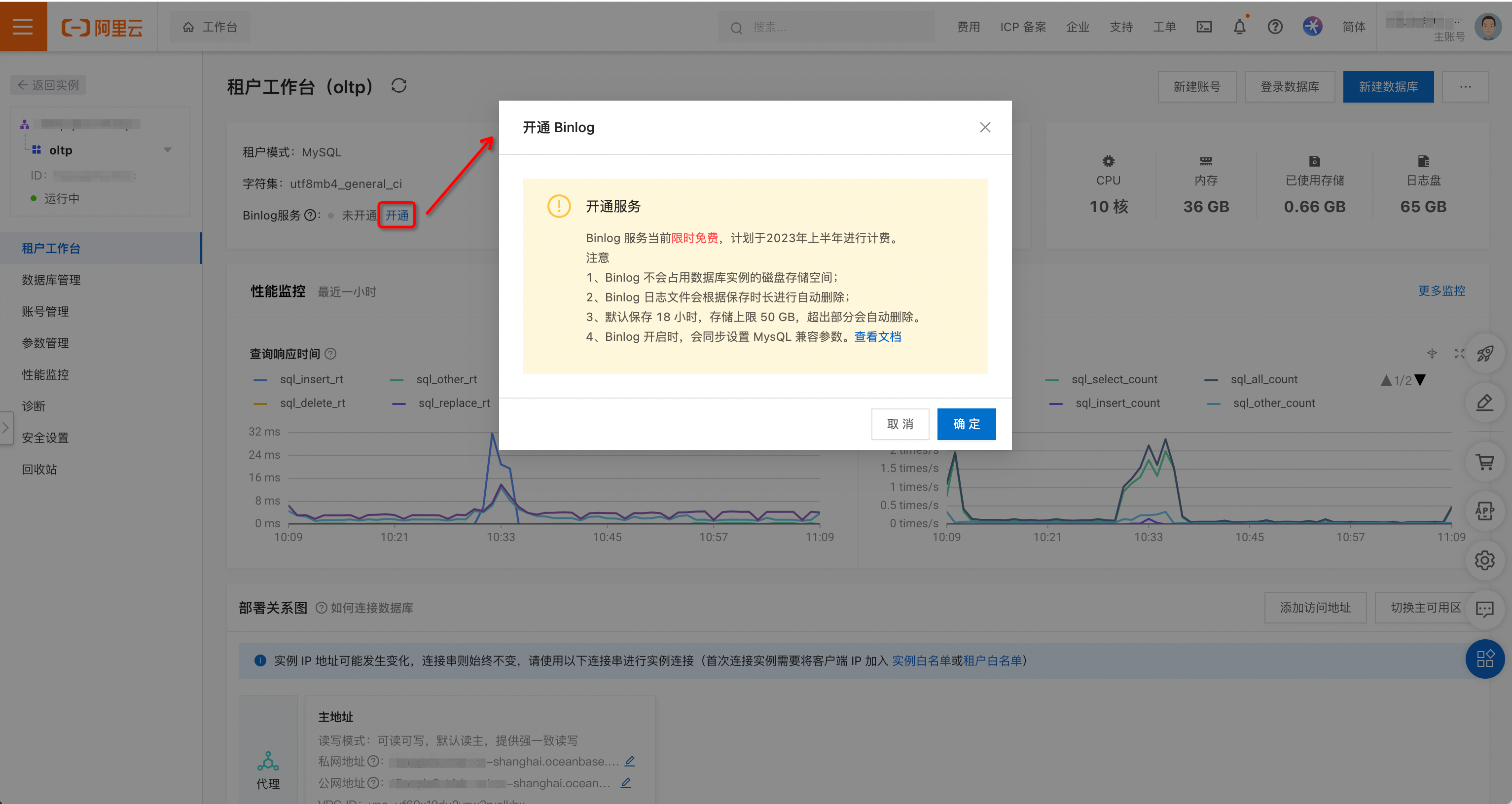
TP 库开通 Binlog 服务
行存表和列存表
- 连接 TP 库,创建 tp_car_orders 表(行存):
create table tp_car_orders(
order_id bigint primary key NOT NULL AUTO_INCREMENT,
-- order_time 默认值由数据库自动生成
order_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
customer_name varchar(25) COLLATE utf8mb4_bin NOT NULL,
sale_nation varchar(25) COLLATE utf8mb4_bin NOT NULL,
sale_region varchar(25) COLLATE utf8mb4_bin NOT NULL,
car_color varchar(25) COLLATE utf8mb4_bin NOT NULL,
car_price decimal(15,2) NOT NULL
);
- 连接 AP 库,创建 ap_car_orders 表(列存)。 - - 由于两张表需要通过 Flink 进行同步,因此两张表的结构几乎完全一样。- 唯二的区别: ① 一个是行存,一个是列存 ② order_time 的默认值不同。
create table ap_car_orders(
order_id bigint primary key NOT NULL AUTO_INCREMENT,
-- order_time 从 tp_car_orders 表同步过来
order_time timestamp NOT NULL,
customer_name varchar(25) COLLATE utf8mb4_bin NOT NULL,
sale_nation varchar(25) COLLATE utf8mb4_bin NOT NULL,
sale_region varchar(25) COLLATE utf8mb4_bin NOT NULL,
car_color varchar(25) COLLATE utf8mb4_bin NOT NULL,
car_price decimal(15,2) NOT NULL
) WITH COLUMN GROUP (each column);
准备 Flink
开通阿里云 Flink
- 本地安装并使用 Flink 进行同步可以参考 OB 官方文档,我这里为了简单,直接使用 阿里云 Flink 托管版本。包年包月比较贵,可以使用按量付费版本,按照指引开通服务即可。
Flink 网络配置
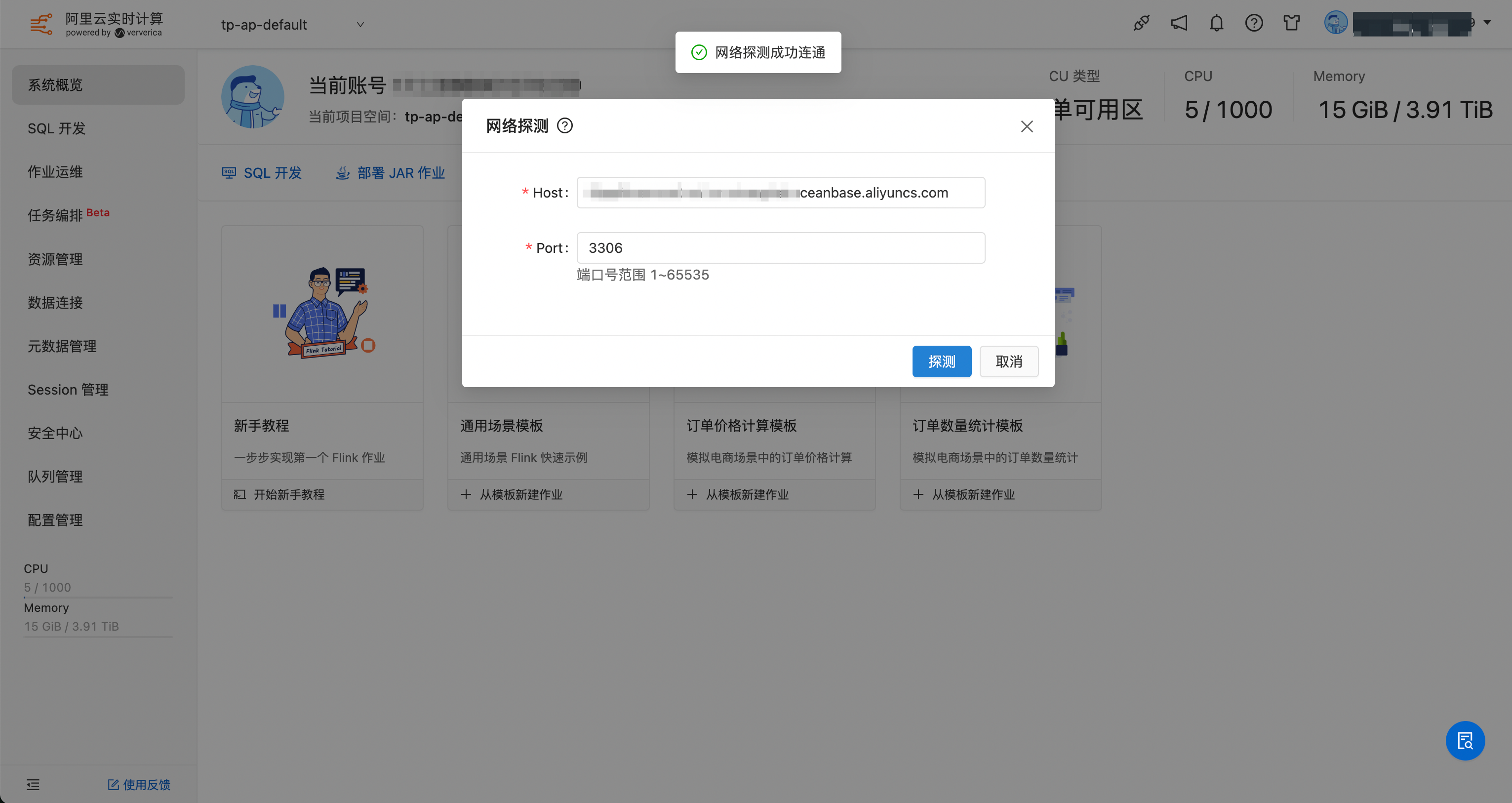
- 进入 Flink 工作空间,使用前建议使用网络探测功能验证数据库是否可正常连接。
- 如果 Flink 和数据库在同一个 VPC: 可以通过数据库私网地址进行连接。
- 如果 Flink 和数据库不在同一个 VPC: - 配置 跨 VPC 访问- 通过数据库公网地址进行连接,但阿里云 Flink 默认不支持访问公网,需要配置 NAT 网关实现 VPC 网络与公网网络互通,详见 文档。
- 保证 Flink 和数据库可以互通之后,网络探测的结果应该如下:
Flink 同步配置
- 进入「配置管理」,修改作业默认配置,将「系统检查点间隔」和「两次系统检查点间最短间隔」两个参数均改为 1 秒,以保证同步的实时性。

Flink SQL 开发
- 进入「SQL 开发-新建-新建空白的留作业草稿」
- 输入以下 SQL 内容:
-- 创建 TP CDC 表,表结构和源表 tp_car_orders 一致
CREATE TEMPORARY TABLE tp_car_orders_cdc (
order_id bigint primary key NOT ENFORCED,
order_time timestamp NOT NULL,
customer_name varchar(25) NOT NULL,
sale_nation varchar(25) NOT NULL,
sale_region varchar(25) NOT NULL,
car_color varchar(25) NOT NULL,
car_price decimal(15,2) NOT NULL
) WITH (
-- OB Binlog 服务兼容 MySQL BinLog 服务,因此可以使用 mysql-cdc 作为连接器
'connector' = 'mysql-cdc',
'hostname' = <HOST>,
'port' = <PORT>,
'username' = <USER_NAME>,
'password' = <PASSWORD>,
'database-name' = 'oltp',
'table-name' = 'tp_car_orders'
);
-- 创建 AP CDC 表,表结构和目标表 ap_car_orders 一致
CREATE TEMPORARY TABLE ap_car_orders_cdc (
order_id bigint primary key NOT ENFORCED,
order_time timestamp NOT NULL,
customer_name varchar(25) NOT NULL,
sale_nation varchar(25) NOT NULL,
sale_region varchar(25) NOT NULL,
car_color varchar(25) NOT NULL,
car_price decimal(15,2) NOT NULL
) WITH (
-- 使用 jdbc 连接器
'connector' = 'jdbc',
'url' = 'jdbc:mysql://<HOST>:<PORT>/olap',
'username' = <USER_NAME>,
'password' = <PASSWORD>,
'table-name' = 'ap_car_orders',
-- 不缓存记录,直接 flush 数据
'sink.buffer-flush.max-rows' = '0',
-- flush 数据的时间间隔设为 0,直接 flush 数据
'sink.buffer-flush.interval' = '0'
);
-- 将 TP CDC 表同步到 AP CDC 表
INSERT INTO ap_car_orders_cdc SELECT * FROM tp_car_orders_cdc;
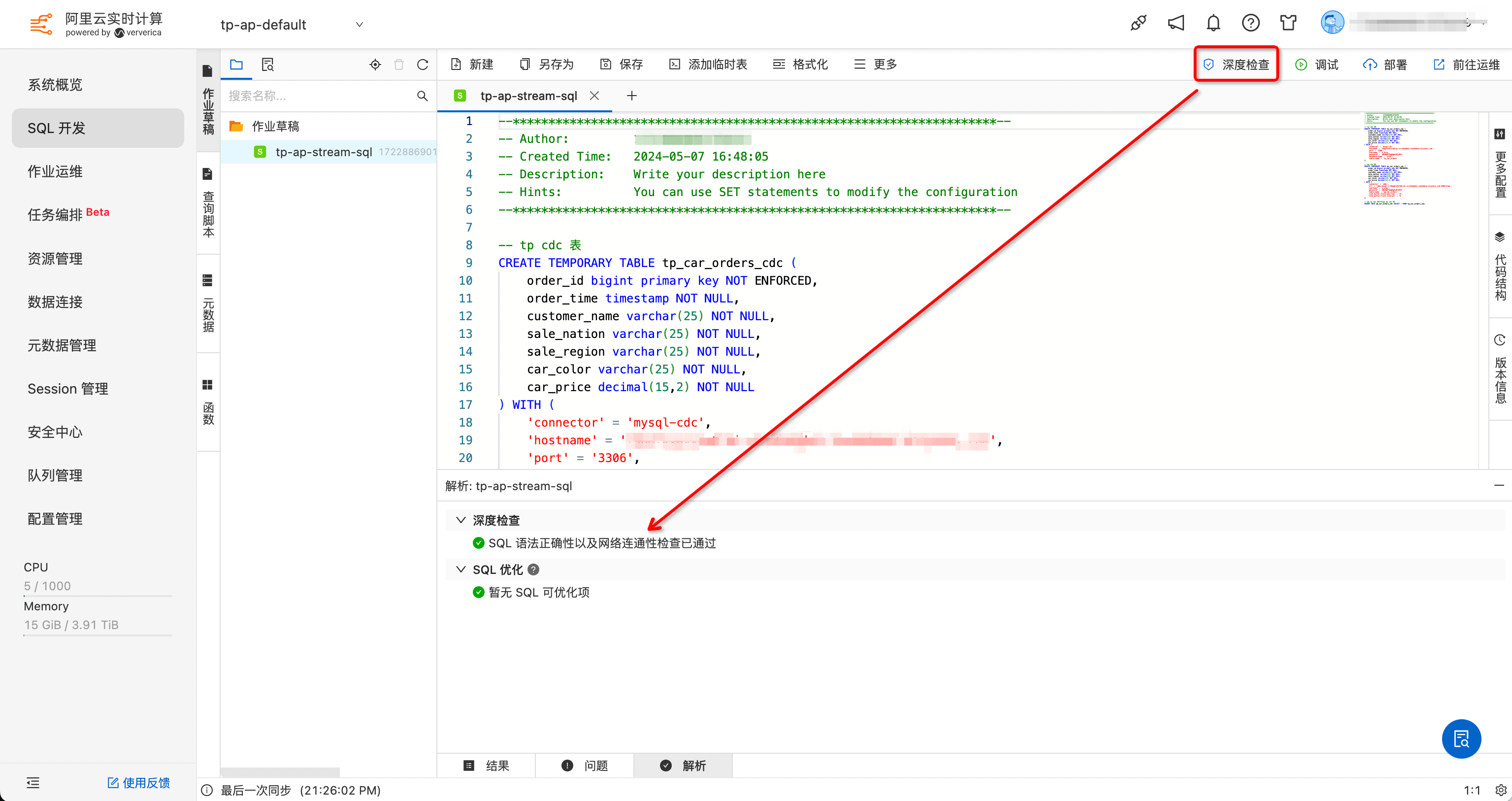
- 📢 注意: 需要调整 ap_car_orders_cdc 以下两个参数,同样的为了保证同步的实时性,我这里均设为
'0',即不做缓存和间隔,直接 flush 数据。这两个参数的用法详见 文档。 -sink.buffer-flush.max-rows-sink.buffer-flush.interval - SQL 语法检查和网络连通性校验:
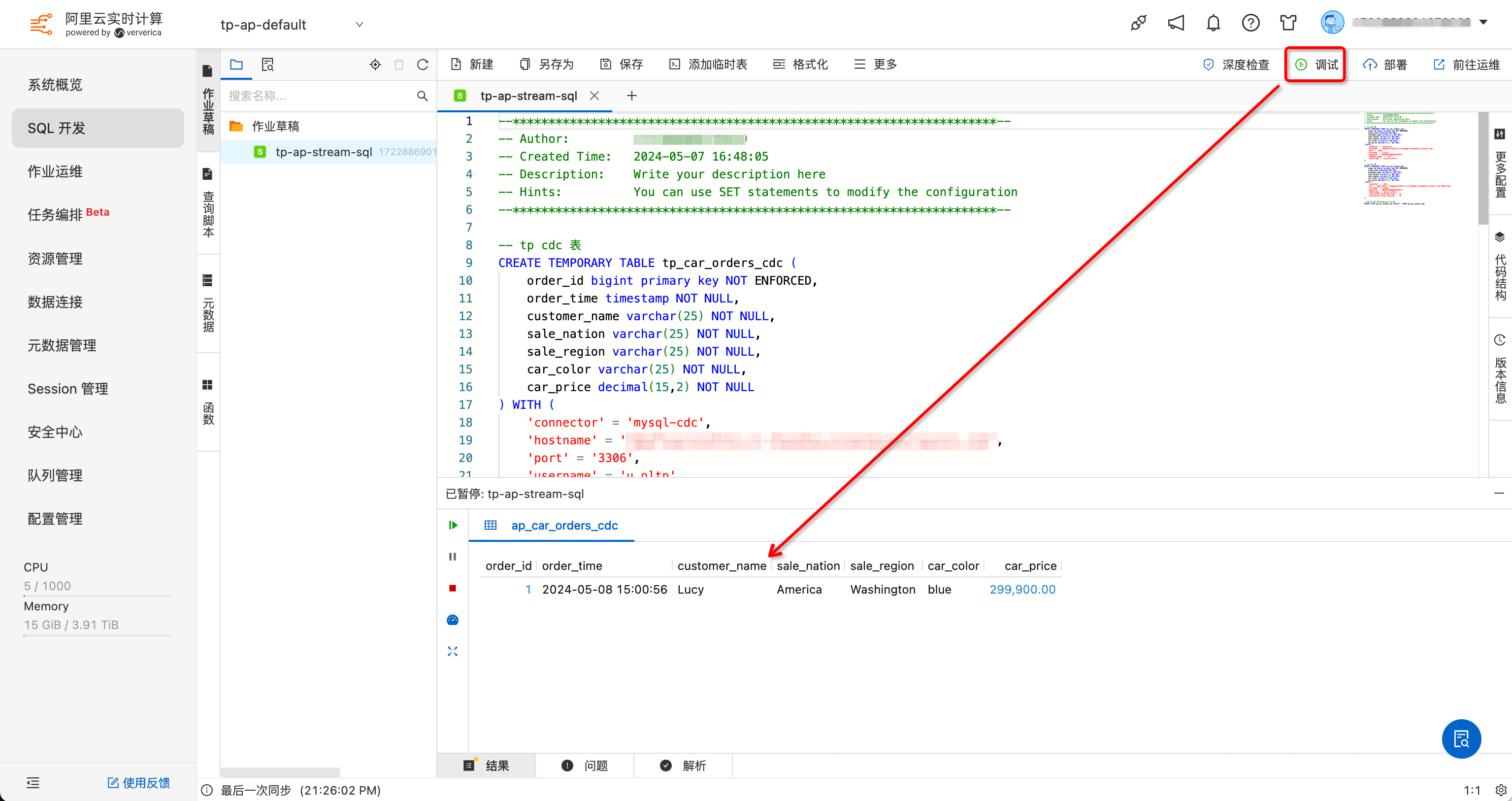
- 启动 SQL 调试,并往 tp_car_orders 表里插入一条数据:
INSERT INTO `tp_car_orders` (`car_price`,`car_color`,`sale_region`,`sale_nation`,`customer_name`) VALUES (299900,'blue','Washington','America','Lucy');
- 预期能够捕获到 tp_car_orders 的数据变更,但变更还不会写入 ap_car_orders,需要实际部署到作业才能写入。
Flink SQL 部署
- 部署 SQL 作业:

- 在「作业运维」即可查看对应作业:
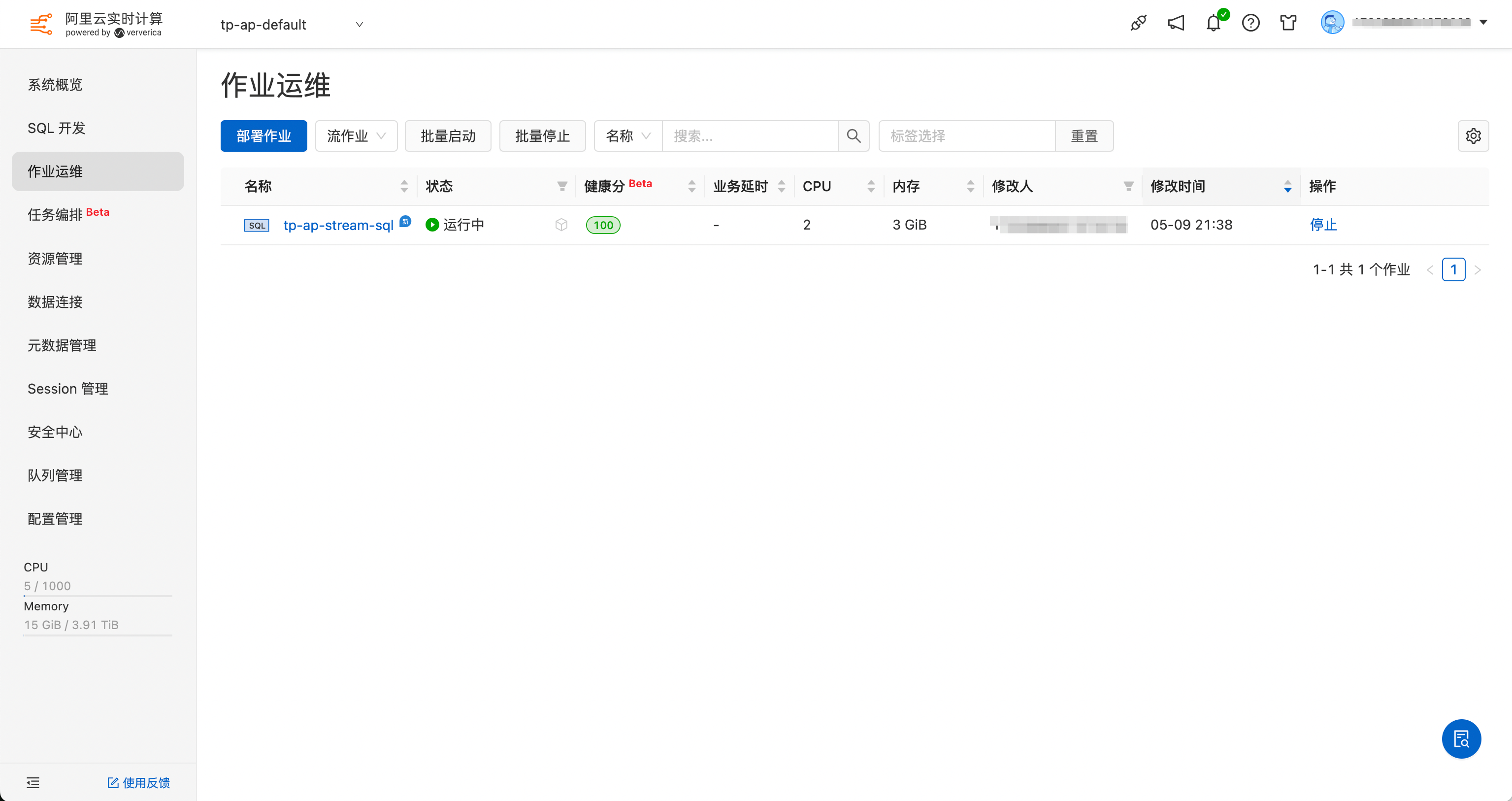
- 部署并启动成功后,重新往 tp_car_orders 表里插入一条数据:
INSERT INTO `tp_car_orders` (`car_price`,`car_color`,`sale_region`,`sale_nation`,`customer_name`) VALUES (299900,'blue','Washington','America','Lucy');
- 可以看到在 ap_car_orders 表中数据已经同步:
mysql> select * from ap_car_orders;
+----------+---------------------+---------------+-------------+-------------+-----------+-----------+
| order_id | order_time | customer_name | sale_nation | sale_region | car_color | car_price |
+----------+---------------------+---------------+-------------+-------------+-----------+-----------+
| 1 | 2024-05-07 17:10:37 | Lucy | America | Washington | blue | 299900.00 |
+----------+---------------------+---------------+-------------+-------------+-----------+-----------+
1 row in set (0.02 sec)
应用配置
- 拉取应用代码: GitHub - dengfuping/oceanbase-playground
pnpm i安装项目依赖。- 新建
.env文件并配置 TP、AP 库的数据库连接串:
OLTP_DATABASE_URL=""
OLAP_DATABASE_URL=""
pnpm run dev启动应用。
导入数据
- clone 代码仓库,通过
npm run seed可 批量导入脚本,默认导入 1.5 亿条数据,可修改脚本逻辑按需调整:

- 导入数据后需要对 AP 库发起一次合并,才能保证最优的查询性能。
mysql> ALTER SYSTEM MAJOR FREEZE;
AP SQL 调优(可选)
- 针对 SQL 建对应索引,详见 索引简介。
- 设置执行并发度,详见 设置并行执行并行度。
- 改为分区表 (按时间分区),详见 分区概述。
运行效果
感兴趣的朋友,可以开通OceanBase的免费试用实例,快速搭建自己的Demo

本文转载自: https://blog.csdn.net/OceanBaseGFBK/article/details/140104994
版权归原作者 OceanBase数据库官方博客 所有, 如有侵权,请联系我们删除。
版权归原作者 OceanBase数据库官方博客 所有, 如有侵权,请联系我们删除。