
介绍
本章节主要说明各类型
flink sql
的先后编写执行顺序,另外简单写一些实际可用的案例。
推荐大家使用 StreamX 进行 flink sql 任务的开发和上线,官网地址:http://streamxhub.com/docs/intro
编写顺序
- set1. 该语句主要是设置本次提交任务环境的一些参数,因此必须写到所有语句的开头,在其他语句执行之前必须先设置参数,之后的语句执行才能使用到设置好的参数。2. 特殊设置:
sql 方言,默认情况下,flink 使用的是自己的方言,但如果想要迁移之前一些hive sql语句,可能想直接使用flink sql引擎直接执行语句,以减少迁移的成本。 此时就可以将设置sql方言的set语句放到insert语句之前,而不是放到最开头。 倘若是直接将设置sql方言的set语句放到最开头,则下面的建表、创建函数之类的语句可能会出错。 - create1. 如果需要用到 hive ,比如读写 hive 表,或者是将创建的虚拟表的信息放到 hive 元数据,就需要有创建 hive catalog 的语句。2. 创建虚拟表来连接外部系统。3. 其他 1. 创建自定义函数。2. 创建数据库。3. 创建视图
- load1. 如果想要用到 hive 模块,比如使用 hive 的一些函数,则需要加载 hive 模块,加载完 hive 模块之后,平台就自动拥有了 hive 和 core(flink) 这两个模块,默认解析顺序为
core->hive。 - use1. 创建了 hive 的 catalog 之后,必须写
use catalog语句来使用创建的 hive catalog,否则无法连接 hive 元数据。2. 加载了 hive 模块之后,可以通过use modules hive, core语句来调整模块解析顺序。 - insert1.
insert语句是真正的flink sql任务。
写在前面
以下所有的案例中涉及到的各组件版本如下:
- java:1.8
- scala:2.12.15
- flink:1.15.1
- kafka:1.1.1
- hadoop:2.8.3
- hive:2.3.6
- mysql:5.7.30
- hbase:1.4.9
kafka source
案例中的 kafka 主题
data_gen_source
中的数据来源于 flink sql 连接器
datagen
生成的随机数据,频率为1秒一条,该主题将作为后面其他案例的 source 使用。
-- 生成随机内容的 source 表createtable data_gen (
id integercomment'订单id',
product_count integercomment'购买商品数量',
one_price doublecomment'单个商品价格')with('connector'='datagen','rows-per-second'='1','fields.id.kind'='random','fields.id.min'='1','fields.id.max'='10','fields.product_count.kind'='random','fields.product_count.min'='1','fields.product_count.max'='50','fields.one_price.kind'='random','fields.one_price.min'='1.0','fields.one_price.max'='5000');-- kafka sink 表createtable kafka_sink (
id integercomment'订单id',
product_count integercomment'购买商品数量',
one_price doublecomment'单个商品价格')with('connector'='kafka','topic'='data_gen_source','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','format'='csv','csv.field-delimiter'=' ');insertinto kafka_sink
select id, product_count, one_price
from data_gen
;
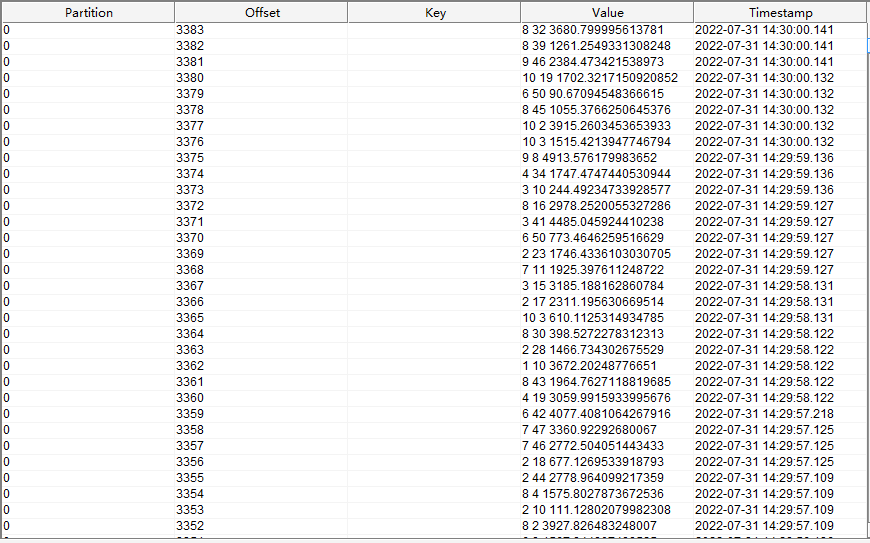
kafka 中
data_gen_source
主题的数据如下图所示:
kafka -> kafka
kafka 作为 source 和 sink 的案例。
-- 创建连接 kafka 的虚拟表作为 sourceCREATETABLE source_kafka(
id integercomment'订单id',
product_count integercomment'购买商品数量',
one_price doublecomment'单个商品价格')WITH('connector'='kafka','topic'='data_gen_source','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','properties.group.id'='for_source_test','scan.startup.mode'='latest-offset','format'='csv','csv.field-delimiter'=' ');-- 创建连接 kafka 的虚拟表作为 sinkcreatetable sink_kafka(
id integercomment'订单id',
total_price doublecomment'总价格')with('connector'='kafka','topic'='for_sink','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','format'='csv','csv.field-delimiter'=' ');-- 真正要执行的任务,计算每个订单的总价insertinto sink_kafka
select id, product_count * one_price as total_price
from source_kafka
;
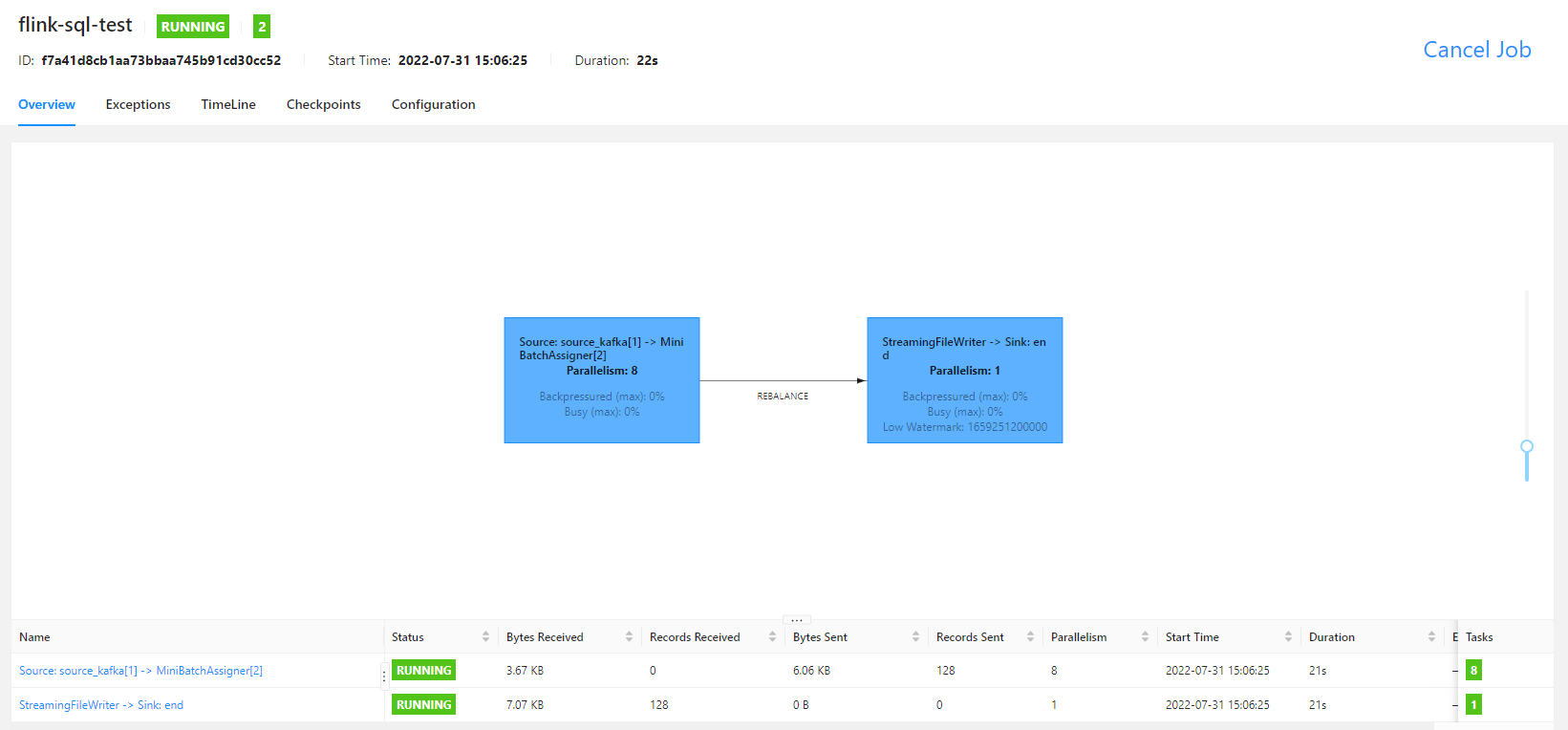
运行之后,flink UI 界面如下
sink 端的 kafka 接收到以下数据
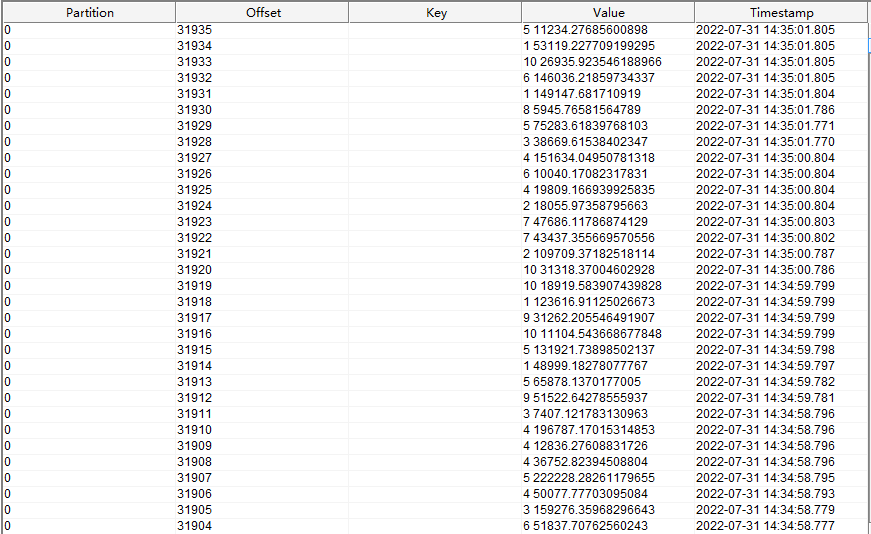
可以看到,value 中两个数字使用空格分隔,分别是订单的 id 和 订单总价。
kafka -> hive
写入无分区表
下面的案例演示的是将 kafka 表中的数据,经过处理之后,直接写入 hive 无分区表,具体 hive 表中的数据什么时候可见,具体请查看
insert
语句中对 hive 表使用的 sql 提示。
hive 表信息
CREATETABLE`test.order_info`(`id`intCOMMENT'订单id',`product_count`intCOMMENT'购买商品数量',`one_price`doubleCOMMENT'单个商品价格')ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info'
TBLPROPERTIES ('transient_lastDdlTime'='1659250044');
flink sql 语句
-- 如果是 flink-1.13.x ,则需要手动设置该参数set'table.dynamic-table-options.enabled'='true';-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。-- 创建catalogcreate catalog hive with('type'='hive','hadoop-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources','hive-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources');use catalog hive;-- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。-- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。CREATEtemporaryTABLE source_kafka(
id integercomment'订单id',
product_count integercomment'购买商品数量',
one_price doublecomment'单个商品价格')WITH('connector'='kafka','topic'='data_gen_source','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','properties.group.id'='for_source_test','scan.startup.mode'='latest-offset','format'='csv','csv.field-delimiter'=' ');insertinto test.order_info
-- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数/*+
OPTIONS(
-- 设置写入的文件滚动时间间隔
'sink.rolling-policy.rollover-interval' = '10 s',
-- 设置检查文件是否需要滚动的时间间隔
'sink.rolling-policy.check-interval' = '1 s',
-- sink 并行度
'sink.parallelism' = '1'
)
*/select id, product_count, one_price
from source_kafka
;
任务运行之后,就可以看到如下的 fink ui 界面了
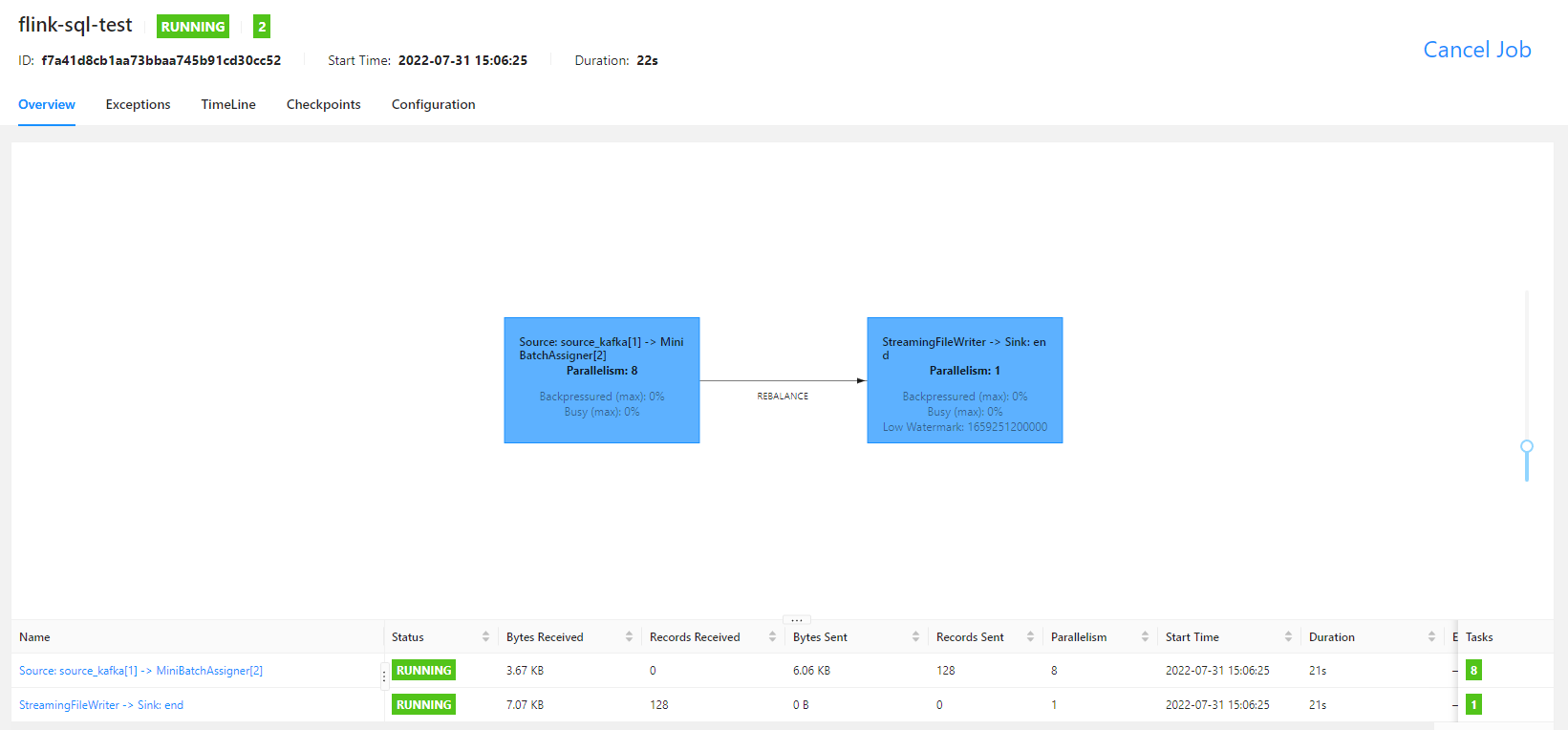
本案例使用 streaming 方式运行, checkpoint 时间为 10 s,文件滚动时间为 10 s,在配置的时间过后,就可以看到 hive 中的数据了
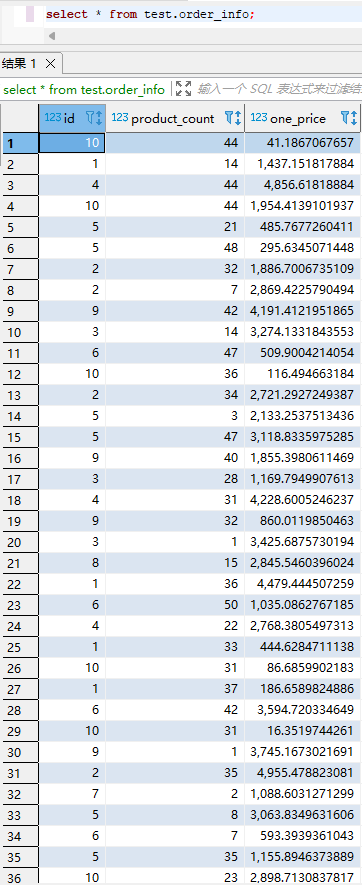
从 hdfs 上查看 hive 表对应文件的数据,如下图所示
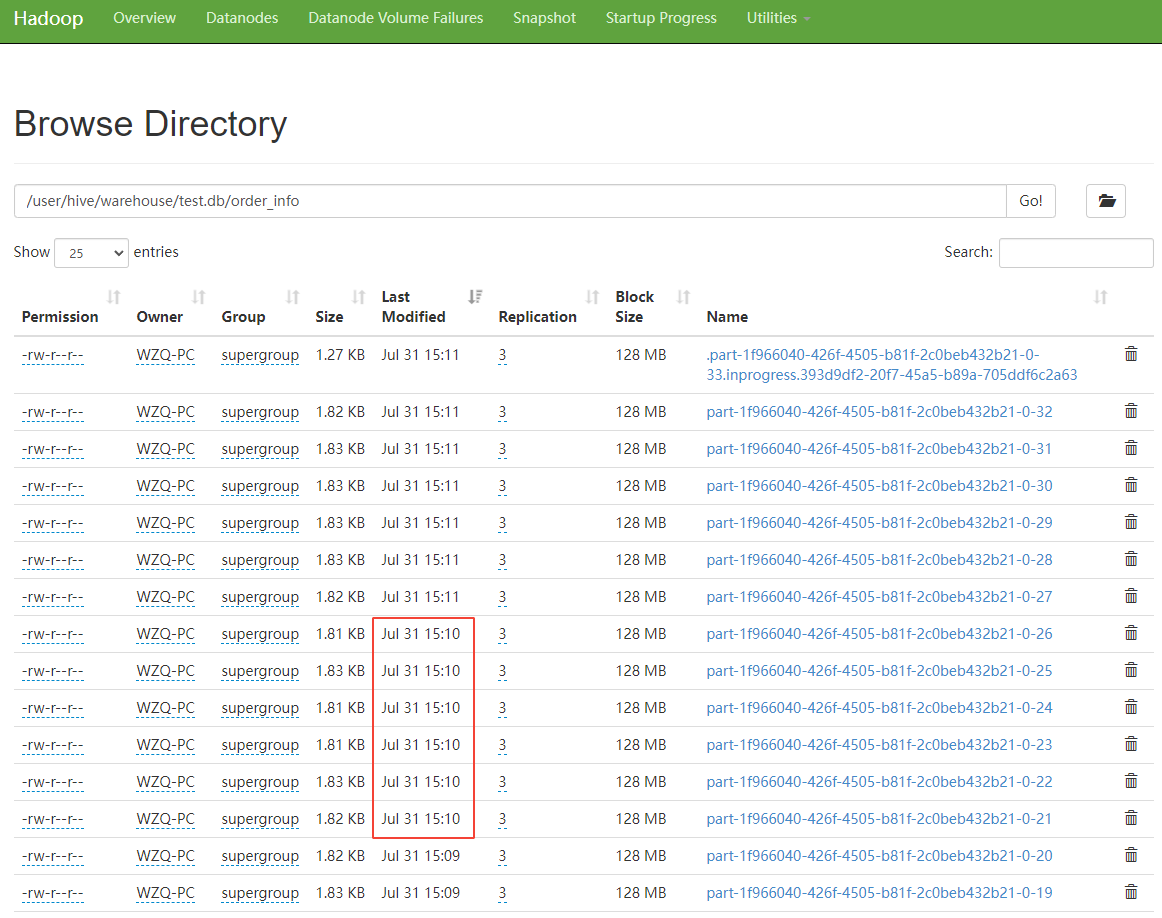
可以看到,1 分钟滚动生成了 6 个文件,最新文件为 .part 开头的文件,在 hdfs 中,以
.
开头的文件,是不可见的,说明这个文件是由于我关闭了 flink sql 任务,然后文件无法滚动造成的。
有关读写 hive 的一些配置和读写 hive 表时其数据的可见性,可以看考读写hive页面。
写入分区表
hive 表信息如下
CREATETABLE`test.order_info_have_partition`(`product_count`intCOMMENT'购买商品数量',`one_price`doubleCOMMENT'单个商品价格')
PARTITIONED BY(`minute` string COMMENT'订单时间,分钟级别',`order_id`intCOMMENT'订单id')ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/order_info_have_partition'
TBLPROPERTIES ('transient_lastDdlTime'='1659254559');
flink sql 语句
-- 如果是 flink-1.13.x ,则需要手动设置该参数set'table.dynamic-table-options.enabled'='true';-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。-- 创建catalogcreate catalog hive with('type'='hive','hadoop-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources','hive-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources');use catalog hive;-- 创建连接 kafka 的虚拟表作为 source,此处使用 temporary ,是为了不让创建的虚拟表元数据保存到 hive,可以让任务重启是不出错。-- 如果想让虚拟表元数据保存到 hive ,则可以在创建语句中加入 if not exist 语句。CREATEtemporaryTABLE source_kafka(
event_time TIMESTAMP(3) METADATA FROM'timestamp',
id integercomment'订单id',
product_count integercomment'购买商品数量',
one_price doublecomment'单个商品价格')WITH('connector'='kafka','topic'='data_gen_source','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','properties.group.id'='for_source_test','scan.startup.mode'='latest-offset','format'='csv','csv.field-delimiter'=' ');insertinto test.order_info_have_partition
-- 下面的语法是 flink sql 提示,用于在语句中使用到表时手动设置一些临时的参数/*+
OPTIONS(
-- 设置分区提交触发器为分区时间
'sink.partition-commit.trigger' = 'partition-time',
-- 'partition.time-extractor.timestamp-pattern' = '$year-$month-$day $hour:$minute',
-- 设置时间提取器的时间格式,要和分区字段值的格式保持一直
'partition.time-extractor.timestamp-formatter' = 'yyyy-MM-dd_HH:mm',
-- 设置分区提交延迟时间,这儿设置 1 分钟,是因为分区时间为 1 分钟间隔
'sink.partition-commit.delay' = '1 m',
-- 设置水印时区
'sink.partition-commit.watermark-time-zone' = 'GMT+08:00',
-- 设置分区提交策略,这儿是将分区提交到元数据存储,并且在分区目录下生成 success 文件
'sink.partition-commit.policy.kind' = 'metastore,success-file',
-- sink 并行度
'sink.parallelism' = '1'
)
*/select
product_count,
one_price,-- 不要让分区值中带有空格,分区值最后会变成目录名,有空格的话,可能会有一些未知问题
date_format(event_time,'yyyy-MM-dd_HH:mm')as`minute`,
id as order_id
from source_kafka
;
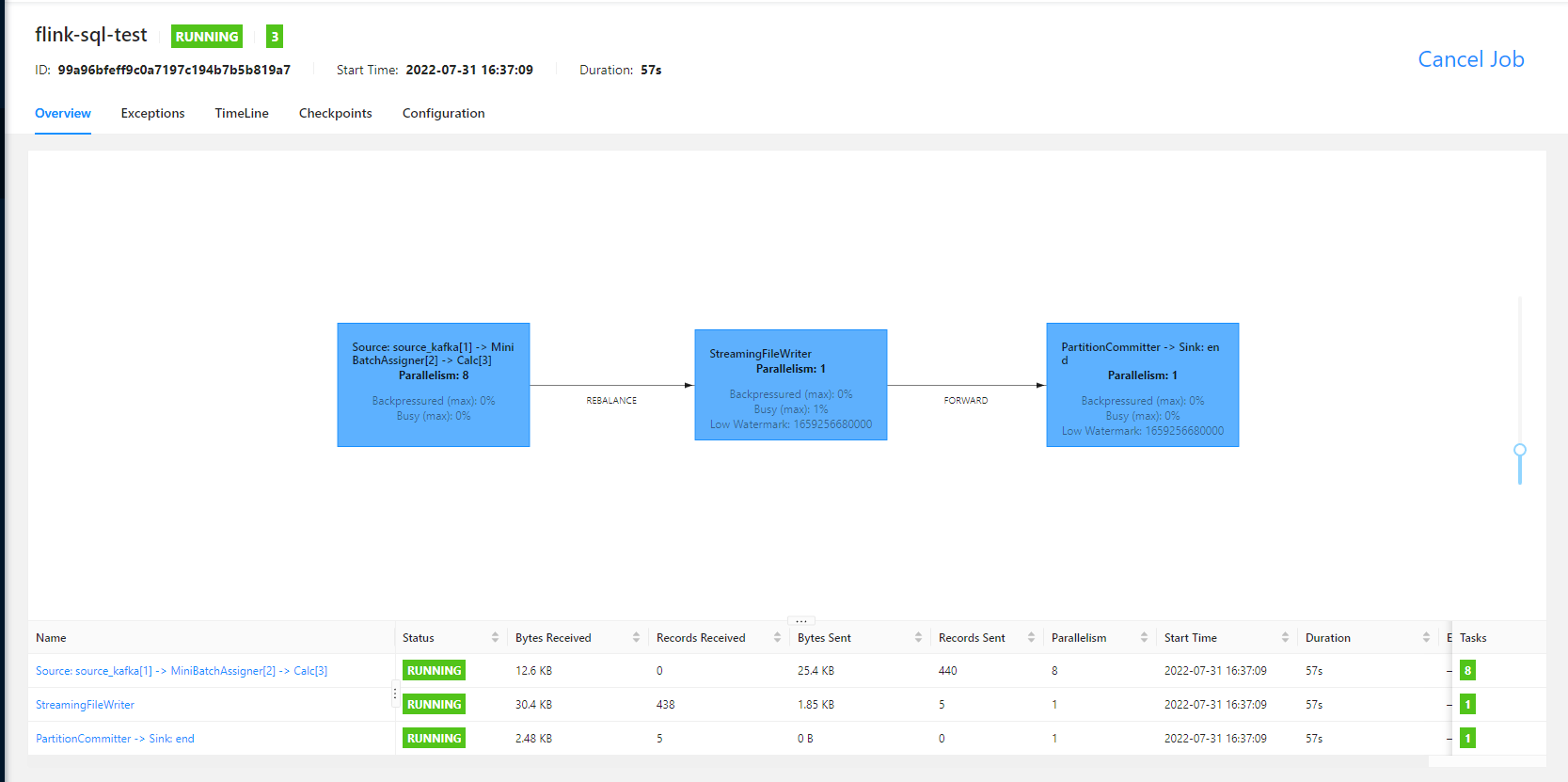
flink sql 任务运行的 UI 界面如下
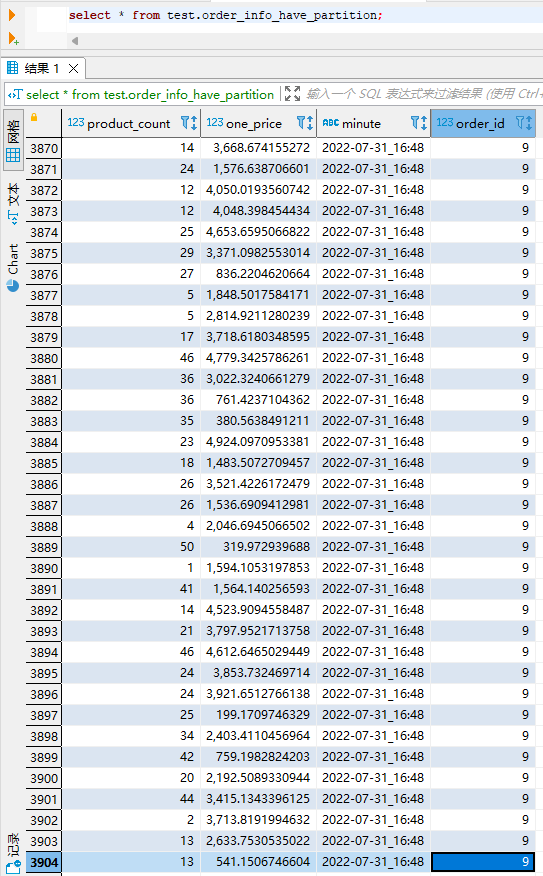
1 分钟之后查看 hive 表中数据,如下
查看 hive 表对应 hdfs 上的文件,可以看到
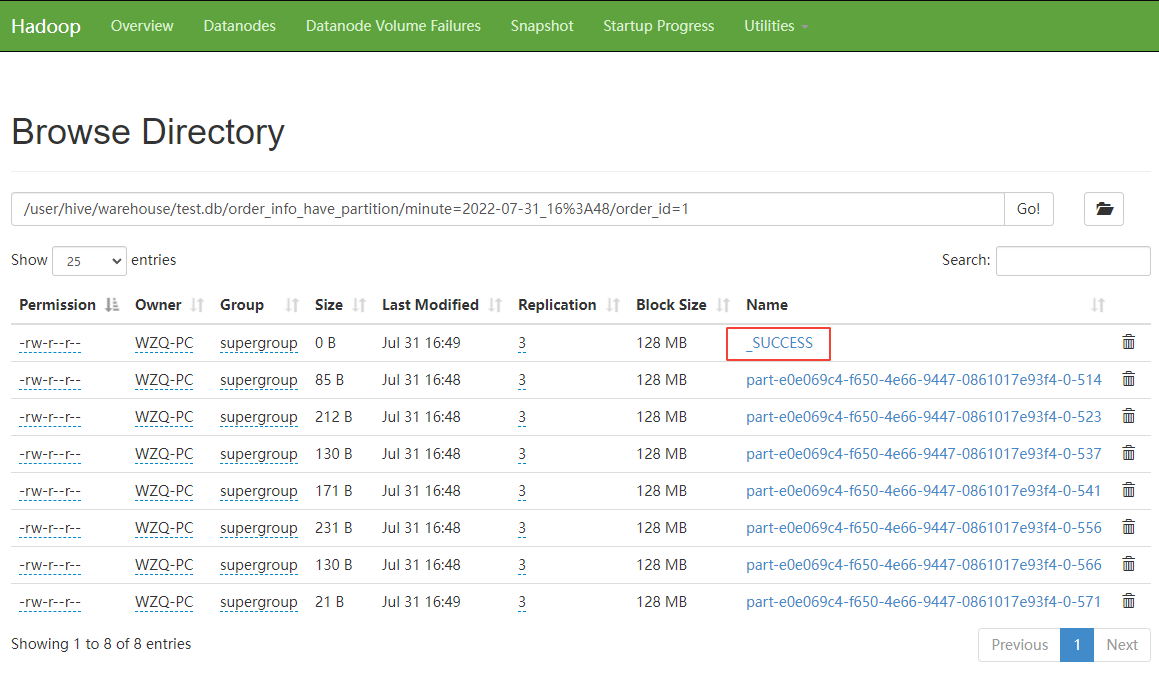
从上图可以看到,具体的分区目录下生成了
_SUCCESS
文件,表示该分区提交成功。
hive -> hive
source,
source_table
表信息和数据
CREATETABLE`test.source_table`(`col1` string,`col2` string)ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/source_table'
TBLPROPERTIES ('transient_lastDdlTime'='1659260162');
source_table
表中的数据如下
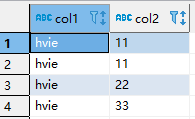
sink,
sink_table
表信息如下
CREATETABLE`test.sink_table`(`col1` string,`col2` array<string>comment'保存 collect_list 函数的结果',`col3` array<string>comment'保存 collect_set 函数的结果')ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/sink_table'
TBLPROPERTIES ('transient_lastDdlTime'='1659260374');
sink_table
表数据如下
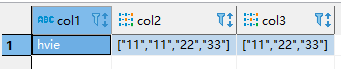
下面将演示两种 sql 方言,将
source_table
表数据,写入
sink_table
表,并且呈现上面图示的结果
使用 flink 方言
set'table.local-time-zone'='GMT+08:00';-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。-- 创建catalogcreate catalog hive with('type'='hive','hadoop-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources','hive-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources');use catalog hive;-- 加载 hive module 之后,flink 就会将 hive 模块放到模块解析顺序的最后。-- 之后flink 引擎会自动使用 hive 模块来解析 flink 模块解析不了的函数,如果想改变模块解析顺序,则可以使用 use modules hive, core; 语句来改变模块解析顺序。load module hive;insert overwrite test.sink_table
select col1, collect_list(col2)as col2, collect_set(col2)as col3
from test.source_table
groupby col1
;
使用hive方言
set'table.local-time-zone'='GMT+08:00';-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。-- 创建catalogcreate catalog hive with('type'='hive','hadoop-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources','hive-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources');use catalog hive;-- 加载 hive module 之后,flink 就会将 hive 模块放到模块解析顺序的最后。-- 之后flink 引擎会自动使用 hive 模块来解析 flink 模块解析不了的函数,如果想改变模块解析顺序,则可以使用 use modules hive, core; 语句来改变模块解析顺序。load module hive;-- 切记,设置方言之后,之后所有的语句将使用你手动设置的方言进行解析运行-- 这儿设置了使用 hive 方言,因此下面的 insert 语句就可以直接使用 hive sql 方言了,也就是说,下面可以直接运行 hive sql 语句。set'table.sql-dialect'='hive';-- insert overwrite `table_name` 是 flink sql 方言语法-- insert overwrite table `table_name` 是 hive sql 方言语法insert overwrite table test.sink_table
select col1, collect_list(col2)as col2, collect_set(col2)as col3
from test.source_table
groupby col1
;
lookup join
该例中,将 mysql 表作为维表,里面保存订单信息,之后去关联订单流水表,最后输出完整的订单流水信息数据到 kafka。
订单流水表读取的是 kafka
data_gen_source
主题中的数据,数据内容如下
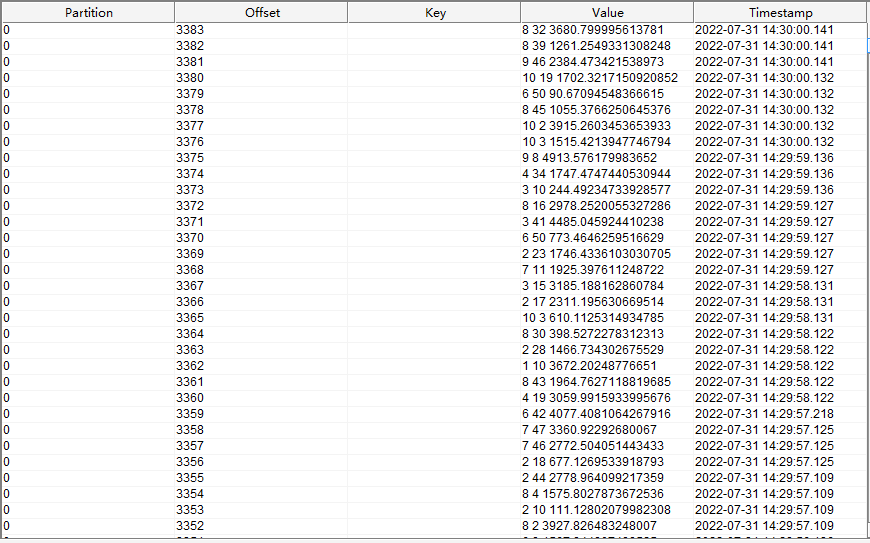
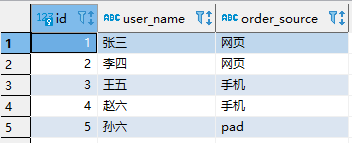
mysql 表
dim.order_info
信息为
CREATETABLE`order_info`(`id`int(11)NOTNULLCOMMENT'订单id',`user_name`varchar(50)DEFAULTNULLCOMMENT'订单所属用户',`order_source`varchar(50)DEFAULTNULLCOMMENT'订单所属来源',PRIMARYKEY(`id`))ENGINE=InnoDBDEFAULTCHARSET=utf8;
mysql 表
dim.order_info
数据为
实际执行的 flink sql 为
set'table.local-time-zone'='GMT+08:00';-- 订单流水CREATEtemporaryTABLE order_flow(
id intcomment'订单id',
product_count intcomment'购买商品数量',
one_price doublecomment'单个商品价格',-- 一定要添加处理时间字段,lookup join 需要该字段
proc_time as proctime())WITH('connector'='kafka','topic'='data_gen_source','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','properties.group.id'='for_source_test','scan.startup.mode'='latest-offset','format'='csv','csv.field-delimiter'=' ');-- 订单信息createtable order_info (
id intPRIMARYKEYNOT ENFORCED comment'订单id',
user_name string comment'订单所属用户',
order_source string comment'订单所属来源')with('connector'='jdbc','url'='jdbc:mysql://node01:3306/dim?useSSL=false','table-name'='order_info','username'='username','password'='******');-- 创建连接 kafka 的虚拟表作为 sinkcreatetable sink_kafka(
id intPRIMARYKEYNOT ENFORCED comment'订单id',
user_name string comment'订单所属用户',
order_source string comment'订单所属来源',
product_count intcomment'购买商品数量',
one_price doublecomment'单个商品价格',
total_price doublecomment'总价格')with('connector'='upsert-kafka','topic'='for_sink','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','key.format'='csv','value.format'='csv','value.csv.field-delimiter'=' ');-- 真正要执行的任务insertinto sink_kafka
select
a.id,
b.user_name,
b.order_source,
a.product_count,
a.one_price,
a.product_count * a.one_price as total_price
from order_flow as a
-- 一定要添加 for system_time as of 语句,否则读取 mysql 的子任务会被认为是有界流,只读取一次,之后 mysql 维表中变化后的数据无法被读取leftjoin order_info for system_time asof a.proc_time as b
on a.id = b.id
;
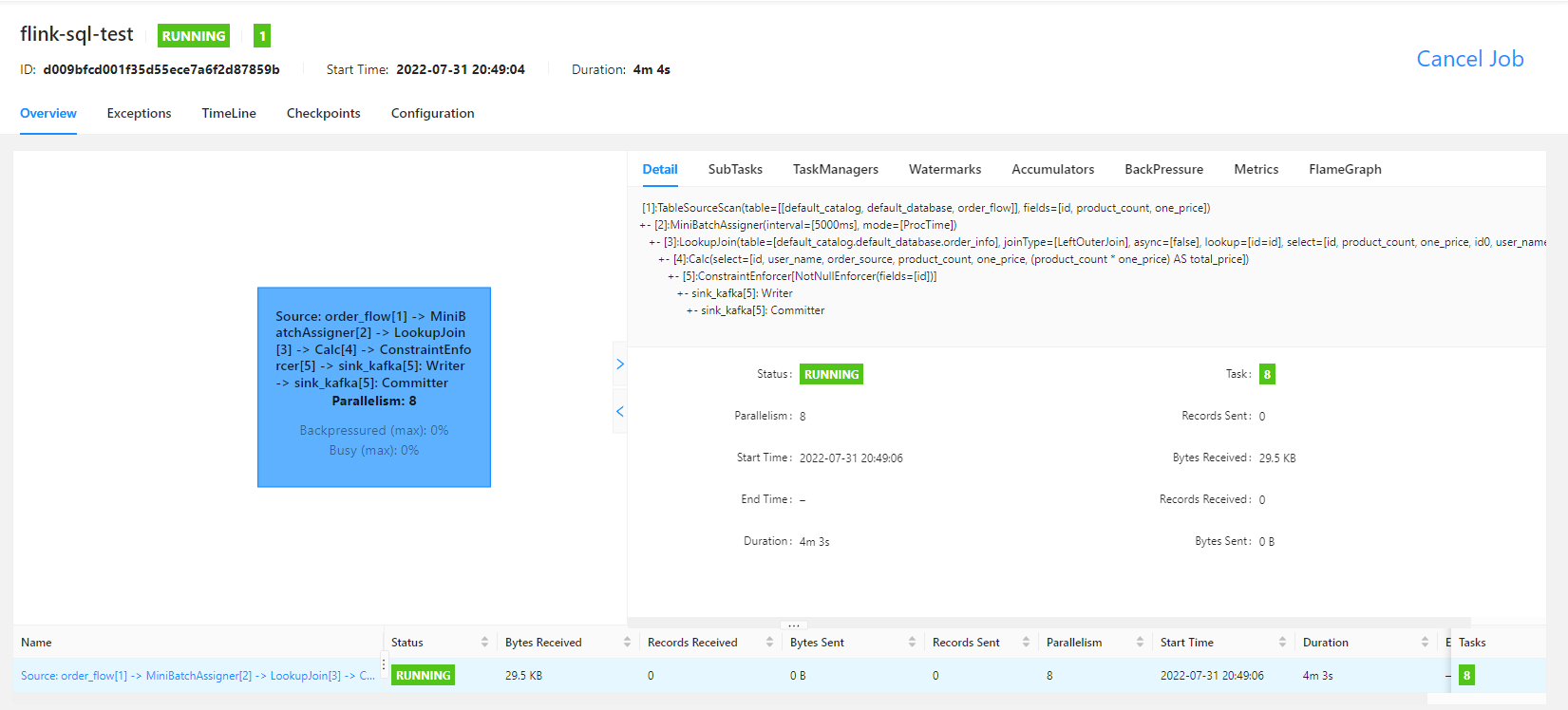
flink sql 任务运行之后,flink UI 界面显示为
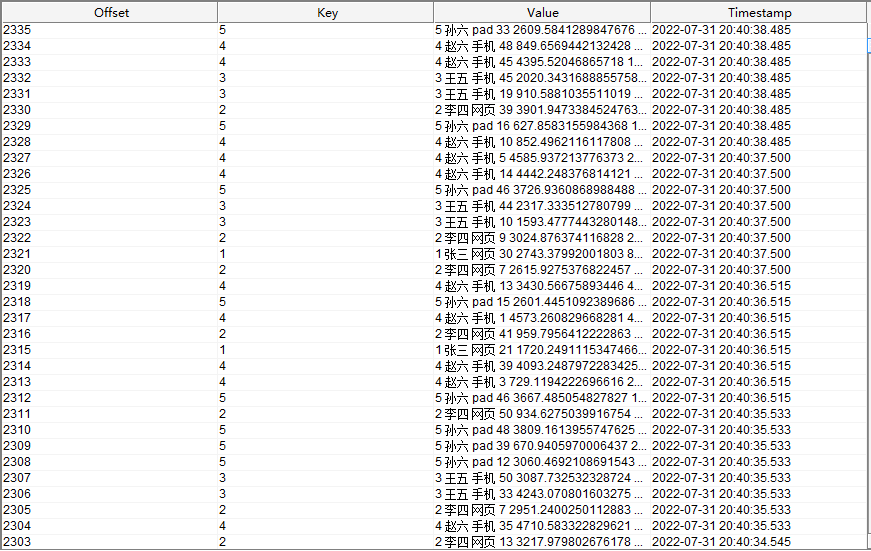
最后查看写入 kafka 中的数据为
此时,修改 mysql 中的数据,修改之后为
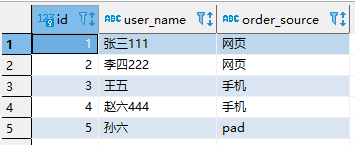
再查看写入 kafka 中的数据为
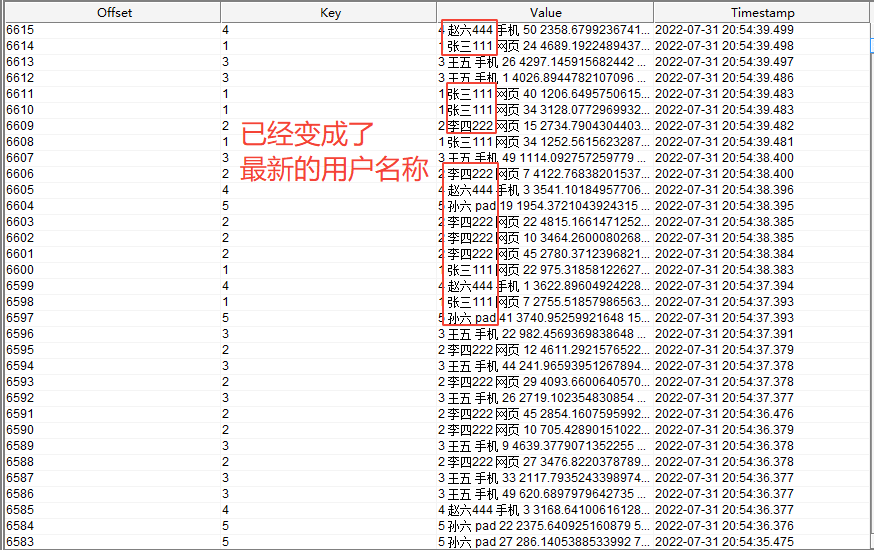
其他
如果 kafka 中的订单流数据中的某个订单 id 在维表 mysql 中找不到,而且 flink sql 任务中使用的是 left join 连接,
则匹配不到的订单中的 user_name 和 product_count 字段将为空字符串,具体如下图所示
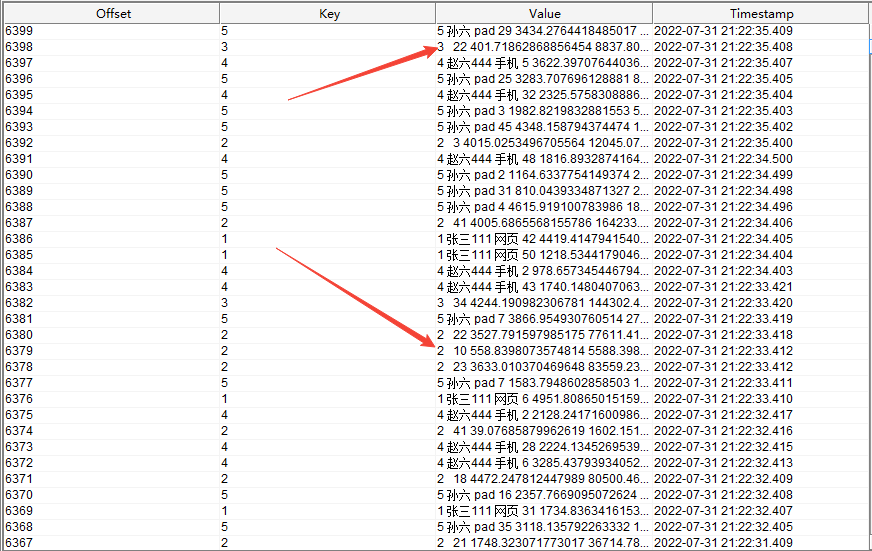
temporal join(时态连接)
该案例中,将 upsert kafka 主题
order_info
中的数据作为维表数据,然后去关联订单流水表,最后输出完整的订单流水信息数据到 kafka。
订单流水表读取的是 kafka
data_gen_source
主题中的数据,数据内容如下
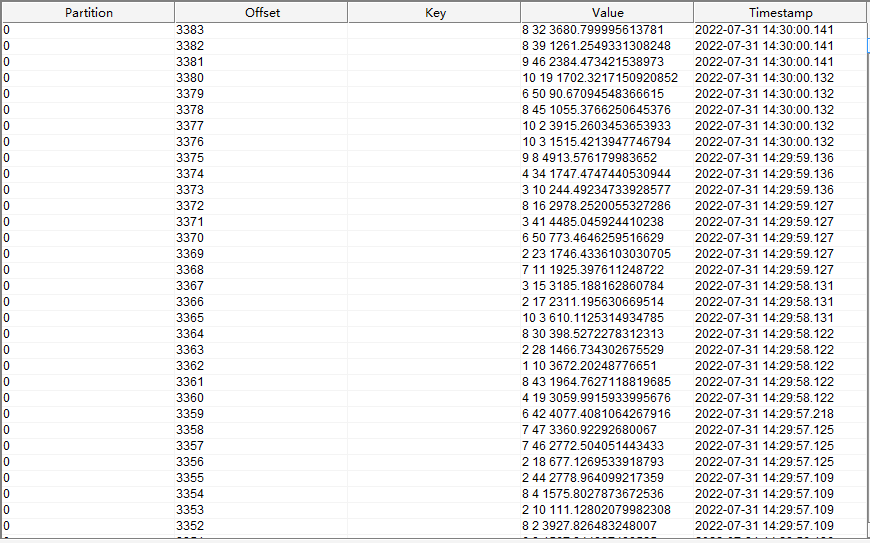
订单信息维表读取的是 kafka
order_info
主题中的数据,数据内容如下

实际执行的 flink sql 为
set'table.local-time-zone'='GMT+08:00';-- 如果 source kafka 主题中有些分区没有数据,就会导致水印无法向下游传播,此时需要手动设置空闲时间set'table.exec.source.idle-timeout'='1 s';-- 订单流水CREATEtemporaryTABLE order_flow(
id intcomment'订单id',
product_count intcomment'购买商品数量',
one_price doublecomment'单个商品价格',-- 定义订单时间为数据写入 kafka 的时间
order_time TIMESTAMP_LTZ(3) METADATA FROM'timestamp' VIRTUAL,
WATERMARK FOR order_time AS order_time
)WITH('connector'='kafka','topic'='data_gen_source','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','properties.group.id'='for_source_test','scan.startup.mode'='latest-offset','format'='csv','csv.field-delimiter'=' ');-- 订单信息createtable order_info (
id intPRIMARYKEYNOT ENFORCED comment'订单id',
user_name string comment'订单所属用户',
order_source string comment'订单所属来源',
update_time TIMESTAMP_LTZ(3) METADATA FROM'timestamp' VIRTUAL,
WATERMARK FOR update_time AS update_time
)with('connector'='upsert-kafka','topic'='order_info','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','key.format'='csv','value.format'='csv','value.csv.field-delimiter'=' ');-- 创建连接 kafka 的虚拟表作为 sinkcreatetable sink_kafka(
id intPRIMARYKEYNOT ENFORCED comment'订单id',
user_name string comment'订单所属用户',
order_source string comment'订单所属来源',
product_count intcomment'购买商品数量',
one_price doublecomment'单个商品价格',
total_price doublecomment'总价格')with('connector'='upsert-kafka','topic'='for_sink','properties.bootstrap.servers'='node01:9092,node02:9092,node03:9092','key.format'='csv','value.format'='csv','value.csv.field-delimiter'=' ');-- 真正要执行的任务insertinto sink_kafka
select
order_flow.id,
order_info.user_name,
order_info.order_source,
order_flow.product_count,
order_flow.one_price,
order_flow.product_count * order_flow.one_price as total_price
from order_flow
leftjoin order_info FOR SYSTEM_TIME ASOF order_flow.order_time
on order_flow.id = order_info.id
;
flink sql 任务运行的 flink UI 界面如下
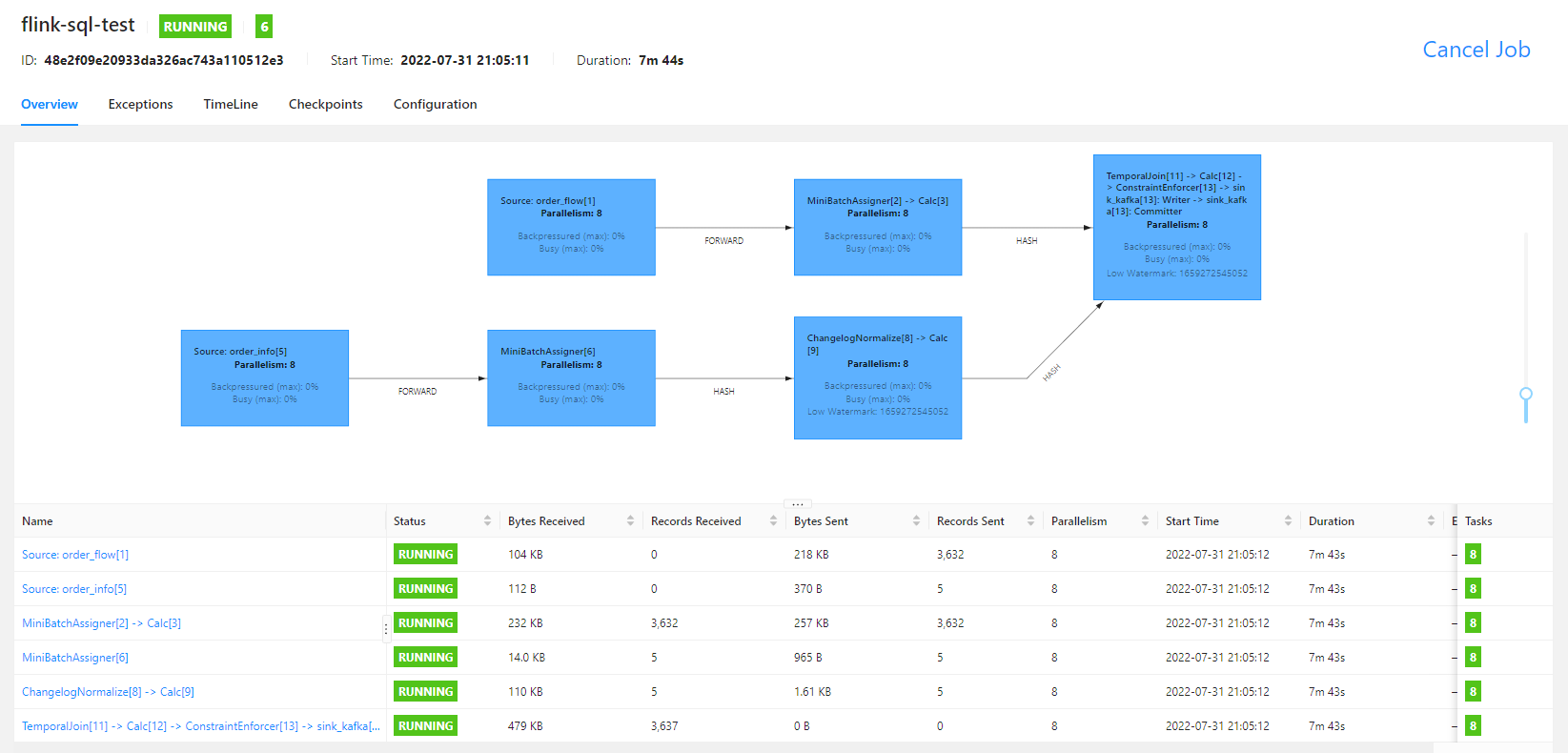
查看结果写入的 kafka
for_sink
主题的数据为
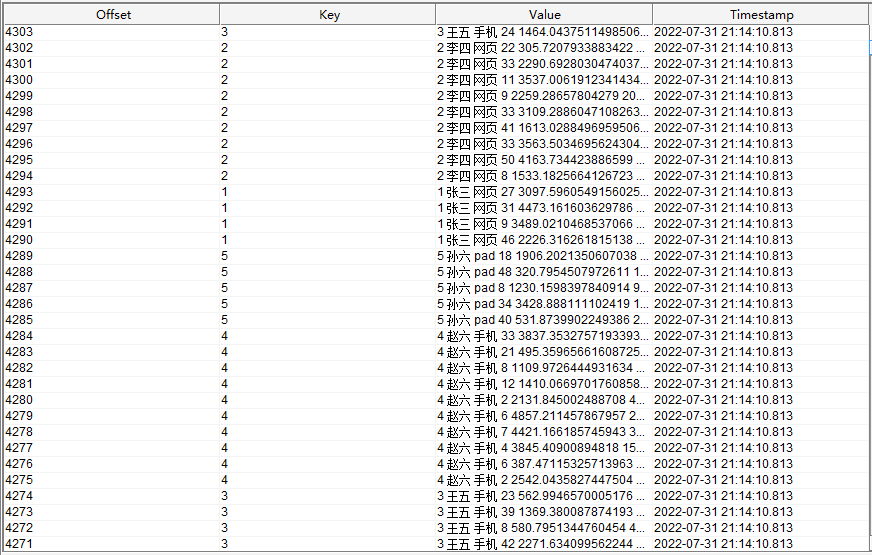
此时新增数据到 kafka 维表主题
order_info
中,新增的数据如下

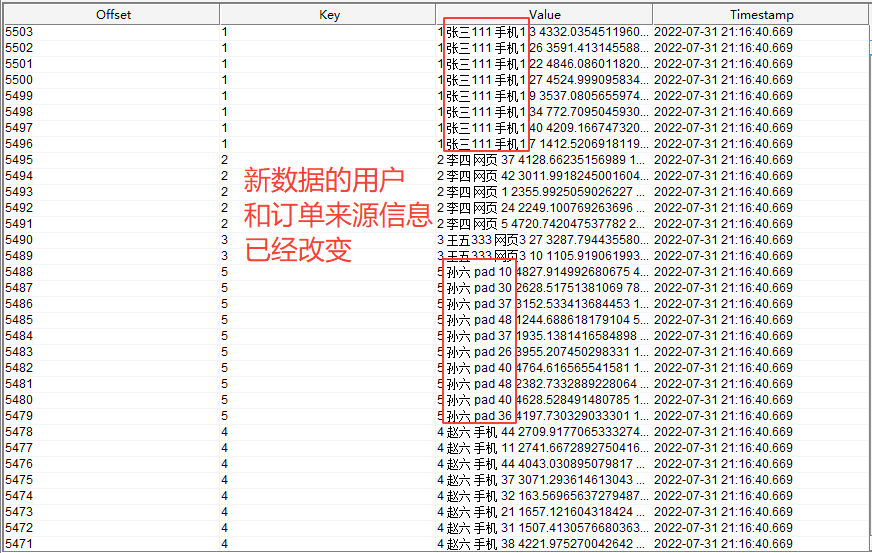
再查看结果写入的 kafka
for_sink
主题的数据为
注意
经过测试发现,当将 upsert kafka 作为 source 时,主题中的数据必须有 key,否则会抛出无法反序列化数据的错误,具体如下
[INFO] [2022-07-31 21:18:22][org.apache.flink.runtime.executiongraph.ExecutionGraph]Source: order_info[5] (2/8) (f8b093cf4f7159f9511058eb4b100b2e) switched from RUNNING to FAILED on bbc9c6a6-0a76-4efe-a7ea-0c00a19ab400 @ 127.0.0.1 (dataPort=-1).
java.io.IOException: Failed to deserialize consumer record due to
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:56) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:33) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.base.source.reader.SourceReaderBase.pollNext(SourceReaderBase.java:143) ~[flink-connector-base-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.api.operators.SourceOperator.emitNext(SourceOperator.java:385) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.io.StreamTaskSourceInput.emitNext(StreamTaskSourceInput.java:68) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:65) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:519) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:203) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:804) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:753) ~[flink-streaming-java-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.runWithSystemExitMonitoring(Task.java:948) ~[flink-runtime-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.restoreAndInvoke(Task.java:927) ~[flink-runtime-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:741) ~[flink-runtime-1.15.1.jar:1.15.1]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:563) ~[flink-runtime-1.15.1.jar:1.15.1]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_311]
Caused by: java.io.IOException: Failed to deserialize consumer record ConsumerRecord(topic = order_info, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1659273502239, serialized key size = 0, serialized value size = 18, headers = RecordHeaders(headers = [], isReadOnly = false), key = [B@2add8ff2, value = [B@2a633689).
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:57) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
... 14 more
Caused by: java.io.IOException: Failed to deserialize CSV row ''.
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:162) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:47) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82) ~[flink-core-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:119) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:54) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
... 14 more
Caused by: org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException: No content to map due to end-of-input
at [Source: UNKNOWN; line: -1, column: -1]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException.from(MismatchedInputException.java:59) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.DeserializationContext.reportInputMismatch(DeserializationContext.java:1601) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader._initForReading(ObjectReader.java:358) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader._bindAndClose(ObjectReader.java:2023) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectReader.readValue(ObjectReader.java:1528) ~[flink-shaded-jackson-2.12.4-15.0.jar:2.12.4-15.0]
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:155) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.formats.csv.CsvRowDataDeserializationSchema.deserialize(CsvRowDataDeserializationSchema.java:47) ~[flink-csv-1.15.1.jar:1.15.1]
at org.apache.flink.api.common.serialization.DeserializationSchema.deserialize(DeserializationSchema.java:82) ~[flink-core-1.15.1.jar:1.15.1]
at org.apache.flink.streaming.connectors.kafka.table.DynamicKafkaDeserializationSchema.deserialize(DynamicKafkaDeserializationSchema.java:119) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.deserializer.KafkaDeserializationSchemaWrapper.deserialize(KafkaDeserializationSchemaWrapper.java:54) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
at org.apache.flink.connector.kafka.source.reader.KafkaRecordEmitter.emitRecord(KafkaRecordEmitter.java:53) ~[flink-connector-kafka-1.15.1.jar:1.15.1]
... 14 more
一些特殊语法
列转行
也就是将数组展开,一行变多行,使用到
cross join unnest()
语句。
读取 hive 表数据,然后写入 hive 表。
source,
source_table
表信息如下
CREATETABLE`test.source_table`(`col1` string,`col2` array<string>COMMENT'数组类型的字段')ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/source_table'
TBLPROPERTIES ('transient_lastDdlTime'='1659261419');
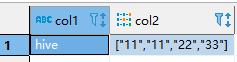
source_table
表数据如下
sink_table
表信息如下
CREATETABLE`test.sink_table`(`col1` string,`col2` string)ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://hadoopCluster/user/hive/warehouse/test.db/sink_table'
TBLPROPERTIES ('transient_lastDdlTime'='1659261915');
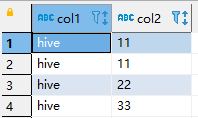
sink_table
表数据如下
下面将使用两种方言演示如何将数组中的数据展开
使用flink方言
set'table.local-time-zone'='GMT+08:00';-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。-- 创建catalogcreate catalog hive with('type'='hive','hadoop-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources','hive-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources');use catalog hive;insert overwrite test.sink_table
select col1, a.col
from test.source_table
crossjoin unnest(col2)as a (col);
使用hive方言
set'table.local-time-zone'='GMT+08:00';-- 在需要读取hive或者是写入hive表时,必须创建hive catalog。-- 创建catalogcreate catalog hive with('type'='hive','hadoop-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources','hive-conf-dir'='D:\IDEAWorkspace\work\baishan\log\data-max\src\main\resources');use catalog hive;load module hive;set'table.sql-dialect'='hive';insert overwrite table test.sink_table
select col1, a.col
from test.source_table
lateral view explode(col2) a as col
;
写在最后
若大家有优秀的使用案例的话,也可留言,以丰富更多的案例。
版权归原作者 第一片心意 所有, 如有侵权,请联系我们删除。