
Spark SQL explain 方法有 simple、extended、codegen、cost、formatted 参数,具体如下
目录
一、基本语法
从 3.0 开始,explain 方法有一个新的 mode 参数,指定执行计划展示格式
- 只展示物理执行计划,默认 mode 是 simple - spark.sql(sqlstr).explain()
- 展示物理执行计划和逻辑执行计划 - spark.sql(sqlstr).explain(mode=“extended”)
- 展示要 Codegen 生成的可执行 Java 代码 - spark.sql(sqlstr).explain(mode=“codegen”)
- 展示优化后的逻辑执行计划以及相关的统计 - spark.sql(sqlstr).explain(mode=“cost”)
- 格式化输出更易读的物理执行计划,展示每个节点的详细信息 - spark.sql(sqlstr).explain(mode=“formatted”)
二、执行计划处理流程
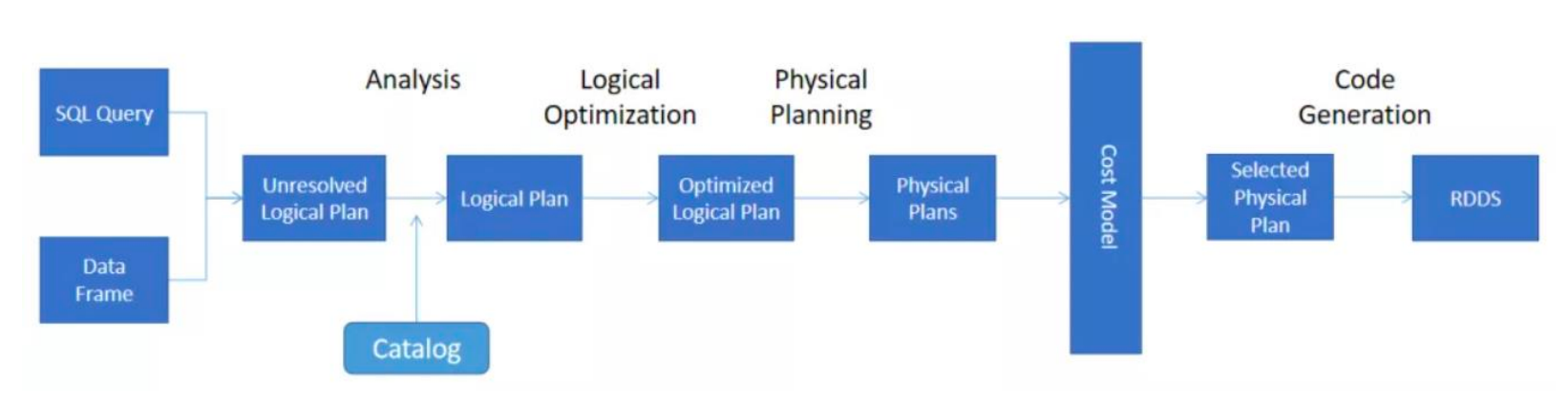
- 流程 - 开始执行的 SQL 或者 DateFrame 操作会生成一个 Unresolved Logical Plan,也就是未决断逻辑计划,从语法的角度去进行校验,校验关键字等是否准确- 然后通过 Catalog 进行分析校验,校验表名列名是否存在,生成一个 Logical Plan 逻辑计划,当前阶段可以直接拿来跑- 但是同一个结果可以有不同的操作方式和执行顺序,会自动生成一个 Logical Optimization 逻辑优化操作,生成一个 Optimized Logical Plan 优化后的逻辑计划- 然后再转换成 Physical Plan 物理计划,通过 Cost Model ,也就是 CBO 代价选择去选择一个代价小的物理计划- 最后生成可执行 Java 代码转换成 RDD
优化后可以分为 5个 步骤
select
sc.courseid,
sc.coursename,
sum(sellmoney) as totalsell
from sale_course sc join course_shopping_cart csc
on sc.courseid=csc.courseid and sc.dt=csc.dt and sc.dn=csc.dn
group by sc.courseid,sc.coursename
# Unresolved 逻辑执行计划
== Parsed Logical Plan ==
'Aggregate ['sc.courseid, 'sc.coursename], ['sc.courseid, 'sc.coursename, 'sum('sellmoney) AS totalsell#38]
+- 'Join Inner, ((('sc.courseid = 'csc.courseid) AND ('sc.dt = 'csc.dt)) AND ('sc.dn = 'csc.dn))
:- 'SubqueryAlias sc
: +- 'UnresolvedRelation [sale_course], [], false
+- 'SubqueryAlias csc
+- 'UnresolvedRelation [course_shopping_cart], [], false
# Resolved 逻辑执行计划
== Analyzed Logical Plan ==
courseid: bigint, coursename: string, totalsell: double
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#38]
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24))
:- SubqueryAlias sc
: +- SubqueryAlias spark_catalog.spark_optimize.sale_course
: +- Relation spark_optimize.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet
+- SubqueryAlias csc
+- SubqueryAlias spark_catalog.spark_optimize.course_shopping_cart
+- Relation spark_optimize.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet
# 优化后的逻辑执行计划
== Optimized Logical Plan ==
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#38]
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24))
:- Project [courseid#3L, coursename#5, dt#15, dn#16]
: +- Filter ((isnotnull(courseid#3L) AND isnotnull(dt#15)) AND isnotnull(dn#16))
: +- Relation spark_optimize.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet
+- Project [courseid#17L, sellmoney#22, dt#23, dn#24]
+- Filter ((isnotnull(courseid#17L) AND isnotnull(dt#23)) AND isnotnull(dn#24))
+- Relation spark_optimize.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet
# 物理执行计划
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
# HashAggregate 表示数据聚合,一般是成对出现,第一个执行节点本地的数据进行局部聚合,另一个是将各个分区的数据进一步进行聚合计算
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, totalsell#38])
# Exchange 就是 shuffle,在集群上移动数据,很多时候 HashAggregate 会以 Exchange 分隔开
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [id=#127]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, sum#44])
# Project 是 SQL 中的投影操作,选择列
+- Project [courseid#3L, coursename#5, sellmoney#22]
# BroadcastHashJoin 广播方式进行 HashJoin
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [id=#122]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_optimize.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shop..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
三、具体案例
测试 SQL
select
sc.courseid,
sc.coursename,sum(sellmoney)as totalsell
from sale_course sc join course_shopping_cart csc
on sc.courseid=csc.courseid and sc.dt=csc.dt and sc.dn=csc.dn
groupby sc.courseid,sc.coursename
- 只展示物理执行计划,默认 mode 是 simple - spark.sql(sqlstr).explain() / spark.sql(sqlstr).explain(“simple”)
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [id=#43]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))])
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [id=#38]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_optimize.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shop..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
- 展示物理执行计划和逻辑执行计划 - spark.sql(sqlstr).explain(mode=“extended”)
== Parsed Logical Plan ==
'Aggregate ['sc.courseid, 'sc.coursename], ['sc.courseid, 'sc.coursename, 'sum('sellmoney) AS totalsell#0]
+- 'Join Inner, ((('sc.courseid = 'csc.courseid) AND ('sc.dt = 'csc.dt)) AND ('sc.dn = 'csc.dn))
:- 'SubqueryAlias sc
: +- 'UnresolvedRelation [sale_course], [], false
+- 'SubqueryAlias csc
+- 'UnresolvedRelation [course_shopping_cart], [], false
== Analyzed Logical Plan ==
courseid: bigint, coursename: string, totalsell: double
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#0]
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24))
:- SubqueryAlias sc
: +- SubqueryAlias spark_catalog.spark_optimize.sale_course
: +- Relation spark_optimize.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet
+- SubqueryAlias csc
+- SubqueryAlias spark_catalog.spark_optimize.course_shopping_cart
+- Relation spark_optimize.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet
== Optimized Logical Plan ==
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#0]
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24))
:- Project [courseid#3L, coursename#5, dt#15, dn#16]
: +- Filter ((isnotnull(courseid#3L) AND isnotnull(dt#15)) AND isnotnull(dn#16))
: +- Relation spark_optimize.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet
+- Project [courseid#17L, sellmoney#22, dt#23, dn#24]
+- Filter ((isnotnull(courseid#17L) AND isnotnull(dt#23)) AND isnotnull(dn#24))
+- Relation spark_optimize.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, totalsell#0])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [id=#43]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, sum#30])
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [id=#38]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_optimize.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shop..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
- 展示要 Codegen 生成的可执行 Java 代码 - spark.sql(sqlstr).explain(mode=“codegen”)
Found 3 WholeStageCodegen subtrees.
== Subtree 1 / 3 (maxMethodCodeSize:409; maxConstantPoolSize:139(0.21% used); numInnerClasses:0) ==
*(1) Project [courseid#3L, coursename#5, dt#15, dn#16]
+- *(1) Filter isnotnull(courseid#3L)
+- *(1) ColumnarToRow
+- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course/dt=20190..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage1(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=1
/* 006 */ final class GeneratedIteratorForCodegenStage1 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private int columnartorow_batchIdx_0;
/* 010 */ private org.apache.spark.sql.execution.vectorized.OnHeapColumnVector[] columnartorow_mutableStateArray_2 = new org.apache.spark.sql.execution.vectorized.OnHeapColumnVector[4];
/* 011 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] columnartorow_mutableStateArray_3 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[3];
/* 012 */ private org.apache.spark.sql.vectorized.ColumnarBatch[] columnartorow_mutableStateArray_1 = new org.apache.spark.sql.vectorized.ColumnarBatch[1];
/* 013 */ private scala.collection.Iterator[] columnartorow_mutableStateArray_0 = new scala.collection.Iterator[1];
/* 014 */
/* 015 */ public GeneratedIteratorForCodegenStage1(Object[] references) {
/* 016 */ this.references = references;
/* 017 */ }
/* 018 */
/* 019 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 020 */ partitionIndex = index;
/* 021 */ this.inputs = inputs;
/* 022 */ columnartorow_mutableStateArray_0[0] = inputs[0];
/* 023 */
/* 024 */ columnartorow_mutableStateArray_3[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96);
/* 025 */ columnartorow_mutableStateArray_3[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96);
/* 026 */ columnartorow_mutableStateArray_3[2] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96);
/* 027 */
/* 028 */ }
/* 029 */
/* 030 */ private void columnartorow_nextBatch_0() throws java.io.IOException {
/* 031 */ if (columnartorow_mutableStateArray_0[0].hasNext()) {
/* 032 */ columnartorow_mutableStateArray_1[0] = (org.apache.spark.sql.vectorized.ColumnarBatch)columnartorow_mutableStateArray_0[0].next();
/* 033 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* numInputBatches */).add(1);
/* 034 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[0] /* numOutputRows */).add(columnartorow_mutableStateArray_1[0].numRows());
/* 035 */ columnartorow_batchIdx_0 = 0;
/* 036 */ columnartorow_mutableStateArray_2[0] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(0);
/* 037 */ columnartorow_mutableStateArray_2[1] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(1);
/* 038 */ columnartorow_mutableStateArray_2[2] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(2);
/* 039 */ columnartorow_mutableStateArray_2[3] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(3);
/* 040 */
/* 041 */ }
/* 042 */ }
/* 043 */
/* 044 */ protected void processNext() throws java.io.IOException {
/* 045 */ if (columnartorow_mutableStateArray_1[0] == null) {
/* 046 */ columnartorow_nextBatch_0();
/* 047 */ }
/* 048 */ while ( columnartorow_mutableStateArray_1[0] != null) {
/* 049 */ int columnartorow_numRows_0 = columnartorow_mutableStateArray_1[0].numRows();
/* 050 */ int columnartorow_localEnd_0 = columnartorow_numRows_0 - columnartorow_batchIdx_0;
/* 051 */ for (int columnartorow_localIdx_0 = 0; columnartorow_localIdx_0 < columnartorow_localEnd_0; columnartorow_localIdx_0++) {
/* 052 */ int columnartorow_rowIdx_0 = columnartorow_batchIdx_0 + columnartorow_localIdx_0;
/* 053 */ do {
/* 054 */ boolean columnartorow_isNull_0 = columnartorow_mutableStateArray_2[0].isNullAt(columnartorow_rowIdx_0);
/* 055 */ long columnartorow_value_0 = columnartorow_isNull_0 ? -1L : (columnartorow_mutableStateArray_2[0].getLong(columnartorow_rowIdx_0));
/* 056 */
/* 057 */ boolean filter_value_2 = !columnartorow_isNull_0;
/* 058 */ if (!filter_value_2) continue;
/* 059 */
/* 060 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[2] /* numOutputRows */).add(1);
/* 061 */
/* 062 */ boolean columnartorow_isNull_1 = columnartorow_mutableStateArray_2[1].isNullAt(columnartorow_rowIdx_0);
/* 063 */ UTF8String columnartorow_value_1 = columnartorow_isNull_1 ? null : (columnartorow_mutableStateArray_2[1].getUTF8String(columnartorow_rowIdx_0));
/* 064 */ boolean columnartorow_isNull_2 = columnartorow_mutableStateArray_2[2].isNullAt(columnartorow_rowIdx_0);
/* 065 */ UTF8String columnartorow_value_2 = columnartorow_isNull_2 ? null : (columnartorow_mutableStateArray_2[2].getUTF8String(columnartorow_rowIdx_0));
/* 066 */ boolean columnartorow_isNull_3 = columnartorow_mutableStateArray_2[3].isNullAt(columnartorow_rowIdx_0);
/* 067 */ UTF8String columnartorow_value_3 = columnartorow_isNull_3 ? null : (columnartorow_mutableStateArray_2[3].getUTF8String(columnartorow_rowIdx_0));
/* 068 */ columnartorow_mutableStateArray_3[2].reset();
/* 069 */
/* 070 */ columnartorow_mutableStateArray_3[2].zeroOutNullBytes();
/* 071 */
/* 072 */ if (false) {
/* 073 */ columnartorow_mutableStateArray_3[2].setNullAt(0);
/* 074 */ } else {
/* 075 */ columnartorow_mutableStateArray_3[2].write(0, columnartorow_value_0);
/* 076 */ }
/* 077 */
/* 078 */ if (columnartorow_isNull_1) {
/* 079 */ columnartorow_mutableStateArray_3[2].setNullAt(1);
/* 080 */ } else {
/* 081 */ columnartorow_mutableStateArray_3[2].write(1, columnartorow_value_1);
/* 082 */ }
/* 083 */
/* 084 */ if (columnartorow_isNull_2) {
/* 085 */ columnartorow_mutableStateArray_3[2].setNullAt(2);
/* 086 */ } else {
/* 087 */ columnartorow_mutableStateArray_3[2].write(2, columnartorow_value_2);
/* 088 */ }
/* 089 */
/* 090 */ if (columnartorow_isNull_3) {
/* 091 */ columnartorow_mutableStateArray_3[2].setNullAt(3);
/* 092 */ } else {
/* 093 */ columnartorow_mutableStateArray_3[2].write(3, columnartorow_value_3);
/* 094 */ }
/* 095 */ append((columnartorow_mutableStateArray_3[2].getRow()));
/* 096 */
/* 097 */ } while(false);
/* 098 */ if (shouldStop()) { columnartorow_batchIdx_0 = columnartorow_rowIdx_0 + 1; return; }
/* 099 */ }
/* 100 */ columnartorow_batchIdx_0 = columnartorow_numRows_0;
/* 101 */ columnartorow_mutableStateArray_1[0] = null;
/* 102 */ columnartorow_nextBatch_0();
/* 103 */ }
/* 104 */ }
/* 105 */
/* 106 */ }
== Subtree 2 / 3 (maxMethodCodeSize:541; maxConstantPoolSize:351(0.54% used); numInnerClasses:1) ==
*(2) HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, sum#30])
+- *(2) Project [courseid#3L, coursename#5, sellmoney#22]
+- *(2) BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, true], input[2, string, true], input[3, string, true])), [id=#57]
: +- *(1) Project [courseid#3L, coursename#5, dt#15, dn#16]
: +- *(1) Filter isnotnull(courseid#3L)
: +- *(1) ColumnarToRow
: +- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course/dt=20190..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- *(2) Project [courseid#17L, sellmoney#22, dt#23, dn#24]
+- *(2) Filter isnotnull(courseid#17L)
+- *(2) ColumnarToRow
+- FileScan parquet spark_optimize.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shopping_cart..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage2(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=2
/* 006 */ final class GeneratedIteratorForCodegenStage2 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean agg_initAgg_0;
/* 010 */ private boolean agg_bufIsNull_0;
/* 011 */ private double agg_bufValue_0;
/* 012 */ private agg_FastHashMap_0 agg_fastHashMap_0;
/* 013 */ private org.apache.spark.unsafe.KVIterator<UnsafeRow, UnsafeRow> agg_fastHashMapIter_0;
/* 014 */ private org.apache.spark.unsafe.KVIterator agg_mapIter_0;
/* 015 */ private org.apache.spark.sql.execution.UnsafeFixedWidthAggregationMap agg_hashMap_0;
/* 016 */ private org.apache.spark.sql.execution.UnsafeKVExternalSorter agg_sorter_0;
/* 017 */ private int columnartorow_batchIdx_0;
/* 018 */ private org.apache.spark.sql.execution.joins.UnsafeHashedRelation bhj_relation_0;
/* 019 */ private boolean agg_agg_isNull_8_0;
/* 020 */ private boolean agg_agg_isNull_10_0;
/* 021 */ private org.apache.spark.sql.execution.vectorized.OnHeapColumnVector[] columnartorow_mutableStateArray_2 = new org.apache.spark.sql.execution.vectorized.OnHeapColumnVector[4];
/* 022 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] columnartorow_mutableStateArray_3 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[9];
/* 023 */ private org.apache.spark.sql.vectorized.ColumnarBatch[] columnartorow_mutableStateArray_1 = new org.apache.spark.sql.vectorized.ColumnarBatch[1];
/* 024 */ private scala.collection.Iterator[] columnartorow_mutableStateArray_0 = new scala.collection.Iterator[1];
/* 025 */
/* 026 */ public GeneratedIteratorForCodegenStage2(Object[] references) {
/* 027 */ this.references = references;
/* 028 */ }
/* 029 */
/* 030 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 031 */ partitionIndex = index;
/* 032 */ this.inputs = inputs;
/* 033 */ wholestagecodegen_init_0_0();
/* 034 */ wholestagecodegen_init_0_1();
/* 035 */
/* 036 */ }
/* 037 */
/* 038 */ public class agg_FastHashMap_0 {
/* 039 */ private org.apache.spark.sql.catalyst.expressions.RowBasedKeyValueBatch batch;
/* 040 */ private int[] buckets;
/* 041 */ private int capacity = 1 << 16;
/* 042 */ private double loadFactor = 0.5;
/* 043 */ private int numBuckets = (int) (capacity / loadFactor);
/* 044 */ private int maxSteps = 2;
/* 045 */ private int numRows = 0;
/* 046 */ private Object emptyVBase;
/* 047 */ private long emptyVOff;
/* 048 */ private int emptyVLen;
/* 049 */ private boolean isBatchFull = false;
/* 050 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter agg_rowWriter;
/* 051 */
/* 052 */ public agg_FastHashMap_0(
/* 053 */ org.apache.spark.memory.TaskMemoryManager taskMemoryManager,
/* 054 */ InternalRow emptyAggregationBuffer) {
/* 055 */ batch = org.apache.spark.sql.catalyst.expressions.RowBasedKeyValueBatch
/* 056 */ .allocate(((org.apache.spark.sql.types.StructType) references[1] /* keySchemaTerm */), ((org.apache.spark.sql.types.StructType) references[2] /* valueSchemaTerm */), taskMemoryManager, capacity);
/* 057 */
/* 058 */ final UnsafeProjection valueProjection = UnsafeProjection.create(((org.apache.spark.sql.types.StructType) references[2] /* valueSchemaTerm */));
/* 059 */ final byte[] emptyBuffer = valueProjection.apply(emptyAggregationBuffer).getBytes();
/* 060 */
/* 061 */ emptyVBase = emptyBuffer;
/* 062 */ emptyVOff = Platform.BYTE_ARRAY_OFFSET;
/* 063 */ emptyVLen = emptyBuffer.length;
/* 064 */
/* 065 */ agg_rowWriter = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(
/* 066 */ 2, 32);
/* 067 */
/* 068 */ buckets = new int[numBuckets];
/* 069 */ java.util.Arrays.fill(buckets, -1);
/* 070 */ }
/* 071 */
/* 072 */ public org.apache.spark.sql.catalyst.expressions.UnsafeRow findOrInsert(long agg_key_0, UTF8String agg_key_1) {
/* 073 */ long h = hash(agg_key_0, agg_key_1);
/* 074 */ int step = 0;
/* 075 */ int idx = (int) h & (numBuckets - 1);
/* 076 */ while (step < maxSteps) {
/* 077 */ // Return bucket index if it's either an empty slot or already contains the key
/* 078 */ if (buckets[idx] == -1) {
/* 079 */ if (numRows < capacity && !isBatchFull) {
/* 080 */ agg_rowWriter.reset();
/* 081 */ agg_rowWriter.zeroOutNullBytes();
/* 082 */ agg_rowWriter.write(0, agg_key_0);
/* 083 */ agg_rowWriter.write(1, agg_key_1);
/* 084 */ org.apache.spark.sql.catalyst.expressions.UnsafeRow agg_result
/* 085 */ = agg_rowWriter.getRow();
/* 086 */ Object kbase = agg_result.getBaseObject();
/* 087 */ long koff = agg_result.getBaseOffset();
/* 088 */ int klen = agg_result.getSizeInBytes();
/* 089 */
/* 090 */ UnsafeRow vRow
/* 091 */ = batch.appendRow(kbase, koff, klen, emptyVBase, emptyVOff, emptyVLen);
/* 092 */ if (vRow == null) {
/* 093 */ isBatchFull = true;
/* 094 */ } else {
/* 095 */ buckets[idx] = numRows++;
/* 096 */ }
/* 097 */ return vRow;
/* 098 */ } else {
/* 099 */ // No more space
/* 100 */ return null;
/* 101 */ }
/* 102 */ } else if (equals(idx, agg_key_0, agg_key_1)) {
/* 103 */ return batch.getValueRow(buckets[idx]);
/* 104 */ }
/* 105 */ idx = (idx + 1) & (numBuckets - 1);
/* 106 */ step++;
/* 107 */ }
/* 108 */ // Didn't find it
/* 109 */ return null;
/* 110 */ }
/* 111 */
/* 112 */ private boolean equals(int idx, long agg_key_0, UTF8String agg_key_1) {
/* 113 */ UnsafeRow row = batch.getKeyRow(buckets[idx]);
/* 114 */ return (row.getLong(0) == agg_key_0) && (row.getUTF8String(1).equals(agg_key_1));
/* 115 */ }
/* 116 */
/* 117 */ private long hash(long agg_key_0, UTF8String agg_key_1) {
/* 118 */ long agg_hash_0 = 0;
/* 119 */
/* 120 */ long agg_result_0 = agg_key_0;
/* 121 */ agg_hash_0 = (agg_hash_0 ^ (0x9e3779b9)) + agg_result_0 + (agg_hash_0 << 6) + (agg_hash_0 >>> 2);
/* 122 */
/* 123 */ int agg_result_1 = 0;
/* 124 */ byte[] agg_bytes_0 = agg_key_1.getBytes();
/* 125 */ for (int i = 0; i < agg_bytes_0.length; i++) {
/* 126 */ int agg_hash_1 = agg_bytes_0[i];
/* 127 */ agg_result_1 = (agg_result_1 ^ (0x9e3779b9)) + agg_hash_1 + (agg_result_1 << 6) + (agg_result_1 >>> 2);
/* 128 */ }
/* 129 */
/* 130 */ agg_hash_0 = (agg_hash_0 ^ (0x9e3779b9)) + agg_result_1 + (agg_hash_0 << 6) + (agg_hash_0 >>> 2);
/* 131 */
/* 132 */ return agg_hash_0;
/* 133 */ }
/* 134 */
/* 135 */ public org.apache.spark.unsafe.KVIterator<UnsafeRow, UnsafeRow> rowIterator() {
/* 136 */ return batch.rowIterator();
/* 137 */ }
/* 138 */
/* 139 */ public void close() {
/* 140 */ batch.close();
/* 141 */ }
/* 142 */
/* 143 */ }
/* 144 */
/* 145 */ private void agg_doAggregate_sum_0(boolean agg_exprIsNull_2_0, org.apache.spark.sql.catalyst.InternalRow agg_unsafeRowAggBuffer_0, org.apache.spark.unsafe.types.UTF8String agg_expr_2_0) throws java.io.IOException {
/* 146 */ agg_agg_isNull_8_0 = true;
/* 147 */ double agg_value_9 = -1.0;
/* 148 */ do {
/* 149 */ boolean agg_isNull_9 = true;
/* 150 */ double agg_value_10 = -1.0;
/* 151 */ agg_agg_isNull_10_0 = true;
/* 152 */ double agg_value_11 = -1.0;
/* 153 */ do {
/* 154 */ boolean agg_isNull_11 = agg_unsafeRowAggBuffer_0.isNullAt(0);
/* 155 */ double agg_value_12 = agg_isNull_11 ?
/* 156 */ -1.0 : (agg_unsafeRowAggBuffer_0.getDouble(0));
/* 157 */ if (!agg_isNull_11) {
/* 158 */ agg_agg_isNull_10_0 = false;
/* 159 */ agg_value_11 = agg_value_12;
/* 160 */ continue;
/* 161 */ }
/* 162 */
/* 163 */ if (!false) {
/* 164 */ agg_agg_isNull_10_0 = false;
/* 165 */ agg_value_11 = 0.0D;
/* 166 */ continue;
/* 167 */ }
/* 168 */
/* 169 */ } while (false);
/* 170 */ boolean agg_isNull_13 = agg_exprIsNull_2_0;
/* 171 */ double agg_value_14 = -1.0;
/* 172 */ if (!agg_exprIsNull_2_0) {
/* 173 */ final String agg_doubleStr_0 = agg_expr_2_0.toString();
/* 174 */ try {
/* 175 */ agg_value_14 = Double.valueOf(agg_doubleStr_0);
/* 176 */ } catch (java.lang.NumberFormatException e) {
/* 177 */ final Double d = (Double) Cast.processFloatingPointSpecialLiterals(agg_doubleStr_0, false);
/* 178 */ if (d == null) {
/* 179 */ agg_isNull_13 = true;
/* 180 */ } else {
/* 181 */ agg_value_14 = d.doubleValue();
/* 182 */ }
/* 183 */ }
/* 184 */ }
/* 185 */ if (!agg_isNull_13) {
/* 186 */ agg_isNull_9 = false; // resultCode could change nullability.
/* 187 */
/* 188 */ agg_value_10 = agg_value_11 + agg_value_14;
/* 189 */
/* 190 */ }
/* 191 */ if (!agg_isNull_9) {
/* 192 */ agg_agg_isNull_8_0 = false;
/* 193 */ agg_value_9 = agg_value_10;
/* 194 */ continue;
/* 195 */ }
/* 196 */
/* 197 */ boolean agg_isNull_15 = agg_unsafeRowAggBuffer_0.isNullAt(0);
/* 198 */ double agg_value_16 = agg_isNull_15 ?
/* 199 */ -1.0 : (agg_unsafeRowAggBuffer_0.getDouble(0));
/* 200 */ if (!agg_isNull_15) {
/* 201 */ agg_agg_isNull_8_0 = false;
/* 202 */ agg_value_9 = agg_value_16;
/* 203 */ continue;
/* 204 */ }
/* 205 */
/* 206 */ } while (false);
/* 207 */
/* 208 */ if (!agg_agg_isNull_8_0) {
/* 209 */ agg_unsafeRowAggBuffer_0.setDouble(0, agg_value_9);
/* 210 */ } else {
/* 211 */ agg_unsafeRowAggBuffer_0.setNullAt(0);
/* 212 */ }
/* 213 */ }
/* 214 */
/* 215 */ private void agg_doAggregateWithKeysOutput_0(UnsafeRow agg_keyTerm_0, UnsafeRow agg_bufferTerm_0)
/* 216 */ throws java.io.IOException {
/* 217 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[11] /* numOutputRows */).add(1);
/* 218 */
/* 219 */ boolean agg_isNull_16 = agg_keyTerm_0.isNullAt(0);
/* 220 */ long agg_value_17 = agg_isNull_16 ?
/* 221 */ -1L : (agg_keyTerm_0.getLong(0));
/* 222 */ boolean agg_isNull_17 = agg_keyTerm_0.isNullAt(1);
/* 223 */ UTF8String agg_value_18 = agg_isNull_17 ?
/* 224 */ null : (agg_keyTerm_0.getUTF8String(1));
/* 225 */ boolean agg_isNull_18 = agg_bufferTerm_0.isNullAt(0);
/* 226 */ double agg_value_19 = agg_isNull_18 ?
/* 227 */ -1.0 : (agg_bufferTerm_0.getDouble(0));
/* 228 */
/* 229 */ columnartorow_mutableStateArray_3[8].reset();
/* 230 */
/* 231 */ columnartorow_mutableStateArray_3[8].zeroOutNullBytes();
/* 232 */
/* 233 */ if (agg_isNull_16) {
/* 234 */ columnartorow_mutableStateArray_3[8].setNullAt(0);
/* 235 */ } else {
/* 236 */ columnartorow_mutableStateArray_3[8].write(0, agg_value_17);
/* 237 */ }
/* 238 */
/* 239 */ if (agg_isNull_17) {
/* 240 */ columnartorow_mutableStateArray_3[8].setNullAt(1);
/* 241 */ } else {
/* 242 */ columnartorow_mutableStateArray_3[8].write(1, agg_value_18);
/* 243 */ }
/* 244 */
/* 245 */ if (agg_isNull_18) {
/* 246 */ columnartorow_mutableStateArray_3[8].setNullAt(2);
/* 247 */ } else {
/* 248 */ columnartorow_mutableStateArray_3[8].write(2, agg_value_19);
/* 249 */ }
/* 250 */ append((columnartorow_mutableStateArray_3[8].getRow()));
/* 251 */
/* 252 */ }
/* 253 */
/* 254 */ private void wholestagecodegen_init_0_1() {
/* 255 */ columnartorow_mutableStateArray_3[7] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(2, 32);
/* 256 */ columnartorow_mutableStateArray_3[8] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(3, 32);
/* 257 */
/* 258 */ }
/* 259 */
/* 260 */ private void columnartorow_nextBatch_0() throws java.io.IOException {
/* 261 */ if (columnartorow_mutableStateArray_0[0].hasNext()) {
/* 262 */ columnartorow_mutableStateArray_1[0] = (org.apache.spark.sql.vectorized.ColumnarBatch)columnartorow_mutableStateArray_0[0].next();
/* 263 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[7] /* numInputBatches */).add(1);
/* 264 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[6] /* numOutputRows */).add(columnartorow_mutableStateArray_1[0].numRows());
/* 265 */ columnartorow_batchIdx_0 = 0;
/* 266 */ columnartorow_mutableStateArray_2[0] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(0);
/* 267 */ columnartorow_mutableStateArray_2[1] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(1);
/* 268 */ columnartorow_mutableStateArray_2[2] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(2);
/* 269 */ columnartorow_mutableStateArray_2[3] = (org.apache.spark.sql.execution.vectorized.OnHeapColumnVector) columnartorow_mutableStateArray_1[0].column(3);
/* 270 */
/* 271 */ }
/* 272 */ }
/* 273 */
/* 274 */ private void agg_doConsume_0(long agg_expr_0_0, boolean agg_exprIsNull_0_0, UTF8String agg_expr_1_0, boolean agg_exprIsNull_1_0, UTF8String agg_expr_2_0, boolean agg_exprIsNull_2_0) throws java.io.IOException {
/* 275 */ UnsafeRow agg_unsafeRowAggBuffer_0 = null;
/* 276 */ UnsafeRow agg_fastAggBuffer_0 = null;
/* 277 */
/* 278 */ if (true) {
/* 279 */ if (!agg_exprIsNull_0_0 && !agg_exprIsNull_1_0) {
/* 280 */ agg_fastAggBuffer_0 = agg_fastHashMap_0.findOrInsert(
/* 281 */ agg_expr_0_0, agg_expr_1_0);
/* 282 */ }
/* 283 */ }
/* 284 */ // Cannot find the key in fast hash map, try regular hash map.
/* 285 */ if (agg_fastAggBuffer_0 == null) {
/* 286 */ // generate grouping key
/* 287 */ columnartorow_mutableStateArray_3[7].reset();
/* 288 */
/* 289 */ columnartorow_mutableStateArray_3[7].zeroOutNullBytes();
/* 290 */
/* 291 */ if (agg_exprIsNull_0_0) {
/* 292 */ columnartorow_mutableStateArray_3[7].setNullAt(0);
/* 293 */ } else {
/* 294 */ columnartorow_mutableStateArray_3[7].write(0, agg_expr_0_0);
/* 295 */ }
/* 296 */
/* 297 */ if (agg_exprIsNull_1_0) {
/* 298 */ columnartorow_mutableStateArray_3[7].setNullAt(1);
/* 299 */ } else {
/* 300 */ columnartorow_mutableStateArray_3[7].write(1, agg_expr_1_0);
/* 301 */ }
/* 302 */ int agg_unsafeRowKeyHash_0 = (columnartorow_mutableStateArray_3[7].getRow()).hashCode();
/* 303 */ if (true) {
/* 304 */ // try to get the buffer from hash map
/* 305 */ agg_unsafeRowAggBuffer_0 =
/* 306 */ agg_hashMap_0.getAggregationBufferFromUnsafeRow((columnartorow_mutableStateArray_3[7].getRow()), agg_unsafeRowKeyHash_0);
/* 307 */ }
/* 308 */ // Can't allocate buffer from the hash map. Spill the map and fallback to sort-based
/* 309 */ // aggregation after processing all input rows.
/* 310 */ if (agg_unsafeRowAggBuffer_0 == null) {
/* 311 */ if (agg_sorter_0 == null) {
/* 312 */ agg_sorter_0 = agg_hashMap_0.destructAndCreateExternalSorter();
/* 313 */ } else {
/* 314 */ agg_sorter_0.merge(agg_hashMap_0.destructAndCreateExternalSorter());
/* 315 */ }
/* 316 */
/* 317 */ // the hash map had be spilled, it should have enough memory now,
/* 318 */ // try to allocate buffer again.
/* 319 */ agg_unsafeRowAggBuffer_0 = agg_hashMap_0.getAggregationBufferFromUnsafeRow(
/* 320 */ (columnartorow_mutableStateArray_3[7].getRow()), agg_unsafeRowKeyHash_0);
/* 321 */ if (agg_unsafeRowAggBuffer_0 == null) {
/* 322 */ // failed to allocate the first page
/* 323 */ throw new org.apache.spark.memory.SparkOutOfMemoryError("No enough memory for aggregation");
/* 324 */ }
/* 325 */ }
/* 326 */
/* 327 */ }
/* 328 */
/* 329 */ // Updates the proper row buffer
/* 330 */ if (agg_fastAggBuffer_0 != null) {
/* 331 */ agg_unsafeRowAggBuffer_0 = agg_fastAggBuffer_0;
/* 332 */ }
/* 333 */
/* 334 */ // common sub-expressions
/* 335 */
/* 336 */ // evaluate aggregate functions and update aggregation buffers
/* 337 */ agg_doAggregate_sum_0(agg_exprIsNull_2_0, agg_unsafeRowAggBuffer_0, agg_expr_2_0);
/* 338 */
/* 339 */ }
/* 340 */
/* 341 */ private void agg_doAggregateWithKeys_0() throws java.io.IOException {
/* 342 */ if (columnartorow_mutableStateArray_1[0] == null) {
/* 343 */ columnartorow_nextBatch_0();
/* 344 */ }
/* 345 */ while ( columnartorow_mutableStateArray_1[0] != null) {
/* 346 */ int columnartorow_numRows_0 = columnartorow_mutableStateArray_1[0].numRows();
/* 347 */ int columnartorow_localEnd_0 = columnartorow_numRows_0 - columnartorow_batchIdx_0;
/* 348 */ for (int columnartorow_localIdx_0 = 0; columnartorow_localIdx_0 < columnartorow_localEnd_0; columnartorow_localIdx_0++) {
/* 349 */ int columnartorow_rowIdx_0 = columnartorow_batchIdx_0 + columnartorow_localIdx_0;
/* 350 */ do {
/* 351 */ boolean columnartorow_isNull_0 = columnartorow_mutableStateArray_2[0].isNullAt(columnartorow_rowIdx_0);
/* 352 */ long columnartorow_value_0 = columnartorow_isNull_0 ? -1L : (columnartorow_mutableStateArray_2[0].getLong(columnartorow_rowIdx_0));
/* 353 */
/* 354 */ boolean filter_value_2 = !columnartorow_isNull_0;
/* 355 */ if (!filter_value_2) continue;
/* 356 */
/* 357 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[8] /* numOutputRows */).add(1);
/* 358 */
/* 359 */ boolean columnartorow_isNull_2 = columnartorow_mutableStateArray_2[2].isNullAt(columnartorow_rowIdx_0);
/* 360 */ UTF8String columnartorow_value_2 = columnartorow_isNull_2 ? null : (columnartorow_mutableStateArray_2[2].getUTF8String(columnartorow_rowIdx_0));
/* 361 */ boolean columnartorow_isNull_3 = columnartorow_mutableStateArray_2[3].isNullAt(columnartorow_rowIdx_0);
/* 362 */ UTF8String columnartorow_value_3 = columnartorow_isNull_3 ? null : (columnartorow_mutableStateArray_2[3].getUTF8String(columnartorow_rowIdx_0));
/* 363 */
/* 364 */ // generate join key for stream side
/* 365 */ columnartorow_mutableStateArray_3[3].reset();
/* 366 */
/* 367 */ columnartorow_mutableStateArray_3[3].zeroOutNullBytes();
/* 368 */
/* 369 */ if (false) {
/* 370 */ columnartorow_mutableStateArray_3[3].setNullAt(0);
/* 371 */ } else {
/* 372 */ columnartorow_mutableStateArray_3[3].write(0, columnartorow_value_0);
/* 373 */ }
/* 374 */
/* 375 */ if (columnartorow_isNull_2) {
/* 376 */ columnartorow_mutableStateArray_3[3].setNullAt(1);
/* 377 */ } else {
/* 378 */ columnartorow_mutableStateArray_3[3].write(1, columnartorow_value_2);
/* 379 */ }
/* 380 */
/* 381 */ if (columnartorow_isNull_3) {
/* 382 */ columnartorow_mutableStateArray_3[3].setNullAt(2);
/* 383 */ } else {
/* 384 */ columnartorow_mutableStateArray_3[3].write(2, columnartorow_value_3);
/* 385 */ }
/* 386 */ // find matches from HashedRelation
/* 387 */ UnsafeRow bhj_matched_0 = (columnartorow_mutableStateArray_3[3].getRow()).anyNull() ? null: (UnsafeRow)bhj_relation_0.getValue((columnartorow_mutableStateArray_3[3].getRow()));
/* 388 */ if (bhj_matched_0 != null) {
/* 389 */ {
/* 390 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[10] /* numOutputRows */).add(1);
/* 391 */
/* 392 */ boolean bhj_isNull_3 = bhj_matched_0.isNullAt(0);
/* 393 */ long bhj_value_3 = bhj_isNull_3 ?
/* 394 */ -1L : (bhj_matched_0.getLong(0));
/* 395 */ boolean bhj_isNull_4 = bhj_matched_0.isNullAt(1);
/* 396 */ UTF8String bhj_value_4 = bhj_isNull_4 ?
/* 397 */ null : (bhj_matched_0.getUTF8String(1));
/* 398 */ boolean columnartorow_isNull_1 = columnartorow_mutableStateArray_2[1].isNullAt(columnartorow_rowIdx_0);
/* 399 */ UTF8String columnartorow_value_1 = columnartorow_isNull_1 ? null : (columnartorow_mutableStateArray_2[1].getUTF8String(columnartorow_rowIdx_0));
/* 400 */
/* 401 */ agg_doConsume_0(bhj_value_3, bhj_isNull_3, bhj_value_4, bhj_isNull_4, columnartorow_value_1, columnartorow_isNull_1);
/* 402 */
/* 403 */ }
/* 404 */ }
/* 405 */
/* 406 */ } while(false);
/* 407 */ // shouldStop check is eliminated
/* 408 */ }
/* 409 */ columnartorow_batchIdx_0 = columnartorow_numRows_0;
/* 410 */ columnartorow_mutableStateArray_1[0] = null;
/* 411 */ columnartorow_nextBatch_0();
/* 412 */ }
/* 413 */
/* 414 */ agg_fastHashMapIter_0 = agg_fastHashMap_0.rowIterator();
/* 415 */ agg_mapIter_0 = ((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).finishAggregate(agg_hashMap_0, agg_sorter_0, ((org.apache.spark.sql.execution.metric.SQLMetric) references[3] /* peakMemory */), ((org.apache.spark.sql.execution.metric.SQLMetric) references[4] /* spillSize */), ((org.apache.spark.sql.execution.metric.SQLMetric) references[5] /* avgHashProbe */));
/* 416 */
/* 417 */ }
/* 418 */
/* 419 */ protected void processNext() throws java.io.IOException {
/* 420 */ if (!agg_initAgg_0) {
/* 421 */ agg_initAgg_0 = true;
/* 422 */ agg_fastHashMap_0 = new agg_FastHashMap_0(((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).getTaskMemoryManager(), ((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).getEmptyAggregationBuffer());
/* 423 */ agg_hashMap_0 = ((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).createHashMap();
/* 424 */ long wholestagecodegen_beforeAgg_0 = System.nanoTime();
/* 425 */ agg_doAggregateWithKeys_0();
/* 426 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[12] /* aggTime */).add((System.nanoTime() - wholestagecodegen_beforeAgg_0) / 1000000);
/* 427 */ }
/* 428 */ // output the result
/* 429 */
/* 430 */ while (agg_fastHashMapIter_0.next()) {
/* 431 */ UnsafeRow agg_aggKey_0 = (UnsafeRow) agg_fastHashMapIter_0.getKey();
/* 432 */ UnsafeRow agg_aggBuffer_0 = (UnsafeRow) agg_fastHashMapIter_0.getValue();
/* 433 */ agg_doAggregateWithKeysOutput_0(agg_aggKey_0, agg_aggBuffer_0);
/* 434 */
/* 435 */ if (shouldStop()) return;
/* 436 */ }
/* 437 */ agg_fastHashMap_0.close();
/* 438 */
/* 439 */ while ( agg_mapIter_0.next()) {
/* 440 */ UnsafeRow agg_aggKey_0 = (UnsafeRow) agg_mapIter_0.getKey();
/* 441 */ UnsafeRow agg_aggBuffer_0 = (UnsafeRow) agg_mapIter_0.getValue();
/* 442 */ agg_doAggregateWithKeysOutput_0(agg_aggKey_0, agg_aggBuffer_0);
/* 443 */ if (shouldStop()) return;
/* 444 */ }
/* 445 */ agg_mapIter_0.close();
/* 446 */ if (agg_sorter_0 == null) {
/* 447 */ agg_hashMap_0.free();
/* 448 */ }
/* 449 */ }
/* 450 */
/* 451 */ private void wholestagecodegen_init_0_0() {
/* 452 */ columnartorow_mutableStateArray_0[0] = inputs[0];
/* 453 */ columnartorow_mutableStateArray_3[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96);
/* 454 */ columnartorow_mutableStateArray_3[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96);
/* 455 */ columnartorow_mutableStateArray_3[2] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(4, 96);
/* 456 */
/* 457 */ bhj_relation_0 = ((org.apache.spark.sql.execution.joins.UnsafeHashedRelation) ((org.apache.spark.broadcast.TorrentBroadcast) references[9] /* broadcast */).value()).asReadOnlyCopy();
/* 458 */ incPeakExecutionMemory(bhj_relation_0.estimatedSize());
/* 459 */
/* 460 */ columnartorow_mutableStateArray_3[3] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(3, 64);
/* 461 */ columnartorow_mutableStateArray_3[4] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(8, 192);
/* 462 */ columnartorow_mutableStateArray_3[5] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(3, 64);
/* 463 */ columnartorow_mutableStateArray_3[6] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(3, 64);
/* 464 */
/* 465 */ }
/* 466 */
/* 467 */ }
== Subtree 3 / 3 (maxMethodCodeSize:206; maxConstantPoolSize:232(0.35% used); numInnerClasses:0) ==
*(3) HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, totalsell#0])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), true, [id=#67]
+- *(2) HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, sum#30])
+- *(2) Project [courseid#3L, coursename#5, sellmoney#22]
+- *(2) BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, true], input[2, string, true], input[3, string, true])), [id=#57]
: +- *(1) Project [courseid#3L, coursename#5, dt#15, dn#16]
: +- *(1) Filter isnotnull(courseid#3L)
: +- *(1) ColumnarToRow
: +- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course/dt=20190..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- *(2) Project [courseid#17L, sellmoney#22, dt#23, dn#24]
+- *(2) Filter isnotnull(courseid#17L)
+- *(2) ColumnarToRow
+- FileScan parquet spark_optimize.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shopping_cart..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
Generated code:
/* 001 */ public Object generate(Object[] references) {
/* 002 */ return new GeneratedIteratorForCodegenStage3(references);
/* 003 */ }
/* 004 */
/* 005 */ // codegenStageId=3
/* 006 */ final class GeneratedIteratorForCodegenStage3 extends org.apache.spark.sql.execution.BufferedRowIterator {
/* 007 */ private Object[] references;
/* 008 */ private scala.collection.Iterator[] inputs;
/* 009 */ private boolean agg_initAgg_0;
/* 010 */ private org.apache.spark.unsafe.KVIterator agg_mapIter_0;
/* 011 */ private org.apache.spark.sql.execution.UnsafeFixedWidthAggregationMap agg_hashMap_0;
/* 012 */ private org.apache.spark.sql.execution.UnsafeKVExternalSorter agg_sorter_0;
/* 013 */ private scala.collection.Iterator inputadapter_input_0;
/* 014 */ private boolean agg_agg_isNull_4_0;
/* 015 */ private boolean agg_agg_isNull_6_0;
/* 016 */ private org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[] agg_mutableStateArray_0 = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter[2];
/* 017 */
/* 018 */ public GeneratedIteratorForCodegenStage3(Object[] references) {
/* 019 */ this.references = references;
/* 020 */ }
/* 021 */
/* 022 */ public void init(int index, scala.collection.Iterator[] inputs) {
/* 023 */ partitionIndex = index;
/* 024 */ this.inputs = inputs;
/* 025 */
/* 026 */ inputadapter_input_0 = inputs[0];
/* 027 */ agg_mutableStateArray_0[0] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(2, 32);
/* 028 */ agg_mutableStateArray_0[1] = new org.apache.spark.sql.catalyst.expressions.codegen.UnsafeRowWriter(3, 32);
/* 029 */
/* 030 */ }
/* 031 */
/* 032 */ private void agg_doAggregate_sum_0(boolean agg_exprIsNull_2_0, org.apache.spark.sql.catalyst.InternalRow agg_unsafeRowAggBuffer_0, double agg_expr_2_0) throws java.io.IOException {
/* 033 */ agg_agg_isNull_4_0 = true;
/* 034 */ double agg_value_4 = -1.0;
/* 035 */ do {
/* 036 */ boolean agg_isNull_5 = true;
/* 037 */ double agg_value_5 = -1.0;
/* 038 */ agg_agg_isNull_6_0 = true;
/* 039 */ double agg_value_6 = -1.0;
/* 040 */ do {
/* 041 */ boolean agg_isNull_7 = agg_unsafeRowAggBuffer_0.isNullAt(0);
/* 042 */ double agg_value_7 = agg_isNull_7 ?
/* 043 */ -1.0 : (agg_unsafeRowAggBuffer_0.getDouble(0));
/* 044 */ if (!agg_isNull_7) {
/* 045 */ agg_agg_isNull_6_0 = false;
/* 046 */ agg_value_6 = agg_value_7;
/* 047 */ continue;
/* 048 */ }
/* 049 */
/* 050 */ if (!false) {
/* 051 */ agg_agg_isNull_6_0 = false;
/* 052 */ agg_value_6 = 0.0D;
/* 053 */ continue;
/* 054 */ }
/* 055 */
/* 056 */ } while (false);
/* 057 */
/* 058 */ if (!agg_exprIsNull_2_0) {
/* 059 */ agg_isNull_5 = false; // resultCode could change nullability.
/* 060 */
/* 061 */ agg_value_5 = agg_value_6 + agg_expr_2_0;
/* 062 */
/* 063 */ }
/* 064 */ if (!agg_isNull_5) {
/* 065 */ agg_agg_isNull_4_0 = false;
/* 066 */ agg_value_4 = agg_value_5;
/* 067 */ continue;
/* 068 */ }
/* 069 */
/* 070 */ boolean agg_isNull_10 = agg_unsafeRowAggBuffer_0.isNullAt(0);
/* 071 */ double agg_value_10 = agg_isNull_10 ?
/* 072 */ -1.0 : (agg_unsafeRowAggBuffer_0.getDouble(0));
/* 073 */ if (!agg_isNull_10) {
/* 074 */ agg_agg_isNull_4_0 = false;
/* 075 */ agg_value_4 = agg_value_10;
/* 076 */ continue;
/* 077 */ }
/* 078 */
/* 079 */ } while (false);
/* 080 */
/* 081 */ if (!agg_agg_isNull_4_0) {
/* 082 */ agg_unsafeRowAggBuffer_0.setDouble(0, agg_value_4);
/* 083 */ } else {
/* 084 */ agg_unsafeRowAggBuffer_0.setNullAt(0);
/* 085 */ }
/* 086 */ }
/* 087 */
/* 088 */ private void agg_doAggregateWithKeysOutput_0(UnsafeRow agg_keyTerm_0, UnsafeRow agg_bufferTerm_0)
/* 089 */ throws java.io.IOException {
/* 090 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[4] /* numOutputRows */).add(1);
/* 091 */
/* 092 */ boolean agg_isNull_11 = agg_keyTerm_0.isNullAt(0);
/* 093 */ long agg_value_11 = agg_isNull_11 ?
/* 094 */ -1L : (agg_keyTerm_0.getLong(0));
/* 095 */ boolean agg_isNull_12 = agg_keyTerm_0.isNullAt(1);
/* 096 */ UTF8String agg_value_12 = agg_isNull_12 ?
/* 097 */ null : (agg_keyTerm_0.getUTF8String(1));
/* 098 */ boolean agg_isNull_13 = agg_bufferTerm_0.isNullAt(0);
/* 099 */ double agg_value_13 = agg_isNull_13 ?
/* 100 */ -1.0 : (agg_bufferTerm_0.getDouble(0));
/* 101 */
/* 102 */ agg_mutableStateArray_0[1].reset();
/* 103 */
/* 104 */ agg_mutableStateArray_0[1].zeroOutNullBytes();
/* 105 */
/* 106 */ if (agg_isNull_11) {
/* 107 */ agg_mutableStateArray_0[1].setNullAt(0);
/* 108 */ } else {
/* 109 */ agg_mutableStateArray_0[1].write(0, agg_value_11);
/* 110 */ }
/* 111 */
/* 112 */ if (agg_isNull_12) {
/* 113 */ agg_mutableStateArray_0[1].setNullAt(1);
/* 114 */ } else {
/* 115 */ agg_mutableStateArray_0[1].write(1, agg_value_12);
/* 116 */ }
/* 117 */
/* 118 */ if (agg_isNull_13) {
/* 119 */ agg_mutableStateArray_0[1].setNullAt(2);
/* 120 */ } else {
/* 121 */ agg_mutableStateArray_0[1].write(2, agg_value_13);
/* 122 */ }
/* 123 */ append((agg_mutableStateArray_0[1].getRow()));
/* 124 */
/* 125 */ }
/* 126 */
/* 127 */ private void agg_doConsume_0(InternalRow inputadapter_row_0, long agg_expr_0_0, boolean agg_exprIsNull_0_0, UTF8String agg_expr_1_0, boolean agg_exprIsNull_1_0, double agg_expr_2_0, boolean agg_exprIsNull_2_0) throws java.io.IOException {
/* 128 */ UnsafeRow agg_unsafeRowAggBuffer_0 = null;
/* 129 */
/* 130 */ // generate grouping key
/* 131 */ agg_mutableStateArray_0[0].reset();
/* 132 */
/* 133 */ agg_mutableStateArray_0[0].zeroOutNullBytes();
/* 134 */
/* 135 */ if (agg_exprIsNull_0_0) {
/* 136 */ agg_mutableStateArray_0[0].setNullAt(0);
/* 137 */ } else {
/* 138 */ agg_mutableStateArray_0[0].write(0, agg_expr_0_0);
/* 139 */ }
/* 140 */
/* 141 */ if (agg_exprIsNull_1_0) {
/* 142 */ agg_mutableStateArray_0[0].setNullAt(1);
/* 143 */ } else {
/* 144 */ agg_mutableStateArray_0[0].write(1, agg_expr_1_0);
/* 145 */ }
/* 146 */ int agg_unsafeRowKeyHash_0 = (agg_mutableStateArray_0[0].getRow()).hashCode();
/* 147 */ if (true) {
/* 148 */ // try to get the buffer from hash map
/* 149 */ agg_unsafeRowAggBuffer_0 =
/* 150 */ agg_hashMap_0.getAggregationBufferFromUnsafeRow((agg_mutableStateArray_0[0].getRow()), agg_unsafeRowKeyHash_0);
/* 151 */ }
/* 152 */ // Can't allocate buffer from the hash map. Spill the map and fallback to sort-based
/* 153 */ // aggregation after processing all input rows.
/* 154 */ if (agg_unsafeRowAggBuffer_0 == null) {
/* 155 */ if (agg_sorter_0 == null) {
/* 156 */ agg_sorter_0 = agg_hashMap_0.destructAndCreateExternalSorter();
/* 157 */ } else {
/* 158 */ agg_sorter_0.merge(agg_hashMap_0.destructAndCreateExternalSorter());
/* 159 */ }
/* 160 */
/* 161 */ // the hash map had be spilled, it should have enough memory now,
/* 162 */ // try to allocate buffer again.
/* 163 */ agg_unsafeRowAggBuffer_0 = agg_hashMap_0.getAggregationBufferFromUnsafeRow(
/* 164 */ (agg_mutableStateArray_0[0].getRow()), agg_unsafeRowKeyHash_0);
/* 165 */ if (agg_unsafeRowAggBuffer_0 == null) {
/* 166 */ // failed to allocate the first page
/* 167 */ throw new org.apache.spark.memory.SparkOutOfMemoryError("No enough memory for aggregation");
/* 168 */ }
/* 169 */ }
/* 170 */
/* 171 */ // common sub-expressions
/* 172 */
/* 173 */ // evaluate aggregate functions and update aggregation buffers
/* 174 */ agg_doAggregate_sum_0(agg_exprIsNull_2_0, agg_unsafeRowAggBuffer_0, agg_expr_2_0);
/* 175 */
/* 176 */ }
/* 177 */
/* 178 */ private void agg_doAggregateWithKeys_0() throws java.io.IOException {
/* 179 */ while ( inputadapter_input_0.hasNext()) {
/* 180 */ InternalRow inputadapter_row_0 = (InternalRow) inputadapter_input_0.next();
/* 181 */
/* 182 */ boolean inputadapter_isNull_0 = inputadapter_row_0.isNullAt(0);
/* 183 */ long inputadapter_value_0 = inputadapter_isNull_0 ?
/* 184 */ -1L : (inputadapter_row_0.getLong(0));
/* 185 */ boolean inputadapter_isNull_1 = inputadapter_row_0.isNullAt(1);
/* 186 */ UTF8String inputadapter_value_1 = inputadapter_isNull_1 ?
/* 187 */ null : (inputadapter_row_0.getUTF8String(1));
/* 188 */ boolean inputadapter_isNull_2 = inputadapter_row_0.isNullAt(2);
/* 189 */ double inputadapter_value_2 = inputadapter_isNull_2 ?
/* 190 */ -1.0 : (inputadapter_row_0.getDouble(2));
/* 191 */
/* 192 */ agg_doConsume_0(inputadapter_row_0, inputadapter_value_0, inputadapter_isNull_0, inputadapter_value_1, inputadapter_isNull_1, inputadapter_value_2, inputadapter_isNull_2);
/* 193 */ // shouldStop check is eliminated
/* 194 */ }
/* 195 */
/* 196 */ agg_mapIter_0 = ((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).finishAggregate(agg_hashMap_0, agg_sorter_0, ((org.apache.spark.sql.execution.metric.SQLMetric) references[1] /* peakMemory */), ((org.apache.spark.sql.execution.metric.SQLMetric) references[2] /* spillSize */), ((org.apache.spark.sql.execution.metric.SQLMetric) references[3] /* avgHashProbe */));
/* 197 */ }
/* 198 */
/* 199 */ protected void processNext() throws java.io.IOException {
/* 200 */ if (!agg_initAgg_0) {
/* 201 */ agg_initAgg_0 = true;
/* 202 */
/* 203 */ agg_hashMap_0 = ((org.apache.spark.sql.execution.aggregate.HashAggregateExec) references[0] /* plan */).createHashMap();
/* 204 */ long wholestagecodegen_beforeAgg_0 = System.nanoTime();
/* 205 */ agg_doAggregateWithKeys_0();
/* 206 */ ((org.apache.spark.sql.execution.metric.SQLMetric) references[5] /* aggTime */).add((System.nanoTime() - wholestagecodegen_beforeAgg_0) / 1000000);
/* 207 */ }
/* 208 */ // output the result
/* 209 */
/* 210 */ while ( agg_mapIter_0.next()) {
/* 211 */ UnsafeRow agg_aggKey_0 = (UnsafeRow) agg_mapIter_0.getKey();
/* 212 */ UnsafeRow agg_aggBuffer_0 = (UnsafeRow) agg_mapIter_0.getValue();
/* 213 */ agg_doAggregateWithKeysOutput_0(agg_aggKey_0, agg_aggBuffer_0);
/* 214 */ if (shouldStop()) return;
/* 215 */ }
/* 216 */ agg_mapIter_0.close();
/* 217 */ if (agg_sorter_0 == null) {
/* 218 */ agg_hashMap_0.free();
/* 219 */ }
/* 220 */ }
/* 221 */
/* 222 */ }
- 展示优化后的逻辑执行计划以及相关的统计 - spark.sql(sqlstr).explain(mode=“cost”)
Aggregate [courseid#3L, coursename#5], [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double)) AS totalsell#0], Statistics(sizeInBytes=1288.1 GiB)
+- Project [courseid#3L, coursename#5, sellmoney#22], Statistics(sizeInBytes=1639.4 GiB)
+- Join Inner, (((courseid#3L = courseid#17L) AND (dt#15 = dt#23)) AND (dn#16 = dn#24)), Statistics(sizeInBytes=4.1 TiB)
:- Project [courseid#3L, coursename#5, dt#15, dn#16], Statistics(sizeInBytes=40.9 KiB)
: +- Filter ((isnotnull(courseid#3L) AND isnotnull(dt#15)) AND isnotnull(dn#16)), Statistics(sizeInBytes=137.9 KiB)
: +- Relation spark_optimize.sale_course[chapterid#1L,chaptername#2,courseid#3L,coursemanager#4,coursename#5,edusubjectid#6L,edusubjectname#7,majorid#8L,majorname#9,money#10,pointlistid#11L,status#12,teacherid#13L,teachername#14,dt#15,dn#16] parquet, Statistics(sizeInBytes=137.9 KiB)
+- Project [courseid#17L, sellmoney#22, dt#23, dn#24], Statistics(sizeInBytes=103.0 MiB)
+- Filter ((isnotnull(courseid#17L) AND isnotnull(dt#23)) AND isnotnull(dn#24)), Statistics(sizeInBytes=211.4 MiB)
+- Relation spark_optimize.course_shopping_cart[courseid#17L,coursename#18,createtime#19,discount#20,orderid#21,sellmoney#22,dt#23,dn#24] parquet, Statistics(sizeInBytes=211.4 MiB)
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, totalsell#0])
+- Exchange hashpartitioning(courseid#3L, coursename#5, 200), ENSURE_REQUIREMENTS, [id=#43]
+- HashAggregate(keys=[courseid#3L, coursename#5], functions=[partial_sum(cast(sellmoney#22 as double))], output=[courseid#3L, coursename#5, sum#30])
+- Project [courseid#3L, coursename#5, sellmoney#22]
+- BroadcastHashJoin [courseid#3L, dt#15, dn#16], [courseid#17L, dt#23, dn#24], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false], input[2, string, true], input[3, string, true]),false), [id=#38]
: +- Filter isnotnull(courseid#3L)
: +- FileScan parquet spark_optimize.sale_course[courseid#3L,coursename#5,dt#15,dn#16] Batched: true, DataFilters: [isnotnull(courseid#3L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course..., PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,coursename:string>
+- Filter isnotnull(courseid#17L)
+- FileScan parquet spark_optimize.course_shopping_cart[courseid#17L,sellmoney#22,dt#23,dn#24] Batched: true, DataFilters: [isnotnull(courseid#17L)], Format: Parquet, Location: InMemoryFileIndex(1 paths)[hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shop..., PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)], PushedFilters: [IsNotNull(courseid)], ReadSchema: struct<courseid:bigint,sellmoney:string>
- 格式化输出更易读的物理执行计划,展示每个节点的详细信息 - spark.sql(sqlstr).explain(mode=“formatted”)
== Physical Plan ==
* HashAggregate (14)
+- Exchange (13)
+- * HashAggregate (12)
+- * Project (11)
+- * BroadcastHashJoin Inner BuildLeft (10)
:- BroadcastExchange (5)
: +- * Project (4)
: +- * Filter (3)
: +- * ColumnarToRow (2)
: +- Scan parquet spark_optimize.sale_course (1)
+- * Project (9)
+- * Filter (8)
+- * ColumnarToRow (7)
+- Scan parquet spark_optimize.course_shopping_cart (6)
(1) Scan parquet spark_optimize.sale_course
Output [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Batched: true
Location: InMemoryFileIndex [hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/sale_course/dt=20190722/dn=webA]
PartitionFilters: [isnotnull(dt#15), isnotnull(dn#16)]
PushedFilters: [IsNotNull(courseid)]
ReadSchema: struct<courseid:bigint,coursename:string>
(2) ColumnarToRow [codegen id : 1]
Input [4]: [courseid#3L, coursename#5, dt#15, dn#16]
(3) Filter [codegen id : 1]
Input [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Condition : isnotnull(courseid#3L)
(4) Project [codegen id : 1]
Output [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Input [4]: [courseid#3L, coursename#5, dt#15, dn#16]
(5) BroadcastExchange
Input [4]: [courseid#3L, coursename#5, dt#15, dn#16]
Arguments: HashedRelationBroadcastMode(List(input[0, bigint, true], input[2, string, true], input[3, string, true])), [id=#57]
(6) Scan parquet spark_optimize.course_shopping_cart
Output [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
Batched: true
Location: InMemoryFileIndex [hdfs://hybrid01:9000/user/hive/warehouse/spark_optimize.db/course_shopping_cart/dt=20190722/dn=webA]
PartitionFilters: [isnotnull(dt#23), isnotnull(dn#24)]
PushedFilters: [IsNotNull(courseid)]
ReadSchema: struct<courseid:bigint,sellmoney:string>
(7) ColumnarToRow
Input [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
(8) Filter
Input [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
Condition : isnotnull(courseid#17L)
(9) Project
Output [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
Input [4]: [courseid#17L, sellmoney#22, dt#23, dn#24]
(10) BroadcastHashJoin [codegen id : 2]
Left keys [3]: [courseid#3L, dt#15, dn#16]
Right keys [3]: [courseid#17L, dt#23, dn#24]
Join condition: None
(11) Project [codegen id : 2]
Output [3]: [courseid#3L, coursename#5, sellmoney#22]
Input [8]: [courseid#3L, coursename#5, dt#15, dn#16, courseid#17L, sellmoney#22, dt#23, dn#24]
(12) HashAggregate [codegen id : 2]
Input [3]: [courseid#3L, coursename#5, sellmoney#22]
Keys [2]: [courseid#3L, coursename#5]
Functions [1]: [partial_sum(cast(sellmoney#22 as double))]
Aggregate Attributes [1]: [sum#29]
Results [3]: [courseid#3L, coursename#5, sum#30]
(13) Exchange
Input [3]: [courseid#3L, coursename#5, sum#30]
Arguments: hashpartitioning(courseid#3L, coursename#5, 200), true, [id=#67]
(14) HashAggregate [codegen id : 3]
Input [3]: [courseid#3L, coursename#5, sum#30]
Keys [2]: [courseid#3L, coursename#5]
Functions [1]: [sum(cast(sellmoney#22 as double))]
Aggregate Attributes [1]: [sum(cast(sellmoney#22 as double))#25]
Results [3]: [courseid#3L, coursename#5, sum(cast(sellmoney#22 as double))#25 AS totalsell#0]
本文转载自: https://blog.csdn.net/baidu_40468340/article/details/129218300
版权归原作者 AcWare 学习笔记 所有, 如有侵权,请联系我们删除。
版权归原作者 AcWare 学习笔记 所有, 如有侵权,请联系我们删除。