
hbase的使用记录
为什么要用hbase
项目里要记录k-v键值对,且数据量非常庞大达到T级别,传统的关系型数据库扛不住查询压力。hbase对于大数据量的查询支持比较优秀。
hbase准备工作
1、虚拟机安装-linux安装
这个应该没有什么问题,网上有很多破解版的,再下一个centos7镜像进行安装。
2、删除自带的jdk
有些用窗口安装的linux自带了jdk,可以先删掉。因为没有配置环境变量
需先切换到root下,然后执行下面的命令
yum -y remove java*
3、安装jdk
去oracle下载一个jdk8,我是自己有,上传到虚拟机
/root
目录
# 进入存放安装包的 /root/ 目录
cd /root/
# 解压安装包
tar -zxvf jdk-8u202-linux-x64.tar.gz
# 创建安装目录
mkdir /usr/local/java/
# 查看解压出来的文件
ll
# 解压后的文件夹名为:jdk1.8.0_202
# 将加压好的JDK移动到安装目录
mv /root/jdk1.8.0_202/ /usr/local/java/
# 查看安装好的jdk
cd /usr/local/java/jdk1.8.0_202/
ll
配置环境变量
# 打开全局配置文件/etc/profile
vi /etc/profile
# 按 i 键,进入文本输入模式
底部加入下列配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
刷新配置文件
source /etc/profile
检查jdk是否正常
# 查看JDK版本
java -version
4、修改hostname
为什么要修改hostname,可能会导致远程连接不上,就是因为连不上我才回来改了hostname重启的
执行一下命令
hostname 你的hostname
hostname
我这里用的名字简称,你可以随意,但是好像不能有下划线
然后需要修改hosts
vi /etc/hosts
加入
虚拟机ip hostname(你的主机名)
5、安装hadoop
我选的hadoop版本为3.3.4,hadoop、jdk、hbase有版本规定,具体可查看官网
Hadoop 安装包下载链接(清华大学开源软件镜像站,下载快):
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
将安装包上传到虚拟机
/root
目录
# 进入到root目录
cd /root
# 解压
tar -zxvf hadoop-3.3.4.tar.gz
# 创建安装目录
mkdir /usr/local/hadoop
# 将解压后的hadoop挪到创建的安装目录
mv /root/hadoop-3.3.4/ /usr/local/hadoop/
# 进入到安装目录
cd /usr/local/hadoop/hadoop-3.3.4/
# 查看
ll
#进入配置文件目录
cd /usr/local/hadoop/hadoop-3.3.4/etc/hadoop
(1)修改 core-site.xml
vi core-site.xml
在
<configuration></configuration>
键值对中间加入
<property>
<name>fs.defaultFS</name>
<value>hdfs://hostname:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 自定义 hadoop 的工作目录 -->
<value>/usr/local/hadoop/hadoop-3.3.4/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<!-- 禁用Hadoop的本地库 -->
<value>false</value>
</property>
其中
hdfs://hostname:9000
的
hostname
为自定义主机名
(2)修改 hdfs-site.xml
vi hdfs-site.xml
在
<configuration></configuration>
键值对中间加入
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(3)修改 yarn-site.xml
vi yarn-site.xml
在
<configuration></configuration>
键值对中间加入
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hostname</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!-- yarn web 页面 -->
<value>0.0.0.0:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<!-- reducer获取数据的方式 -->
<value>mapreduce_shuffle</value>
</property>
其中
hostname
为自定义主机名
(4)修改mapred-site.xml
vi mapred-site.xml
在
<configuration></configuration>
键值对中间加入
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)修改hadoop-env.sh
vi hadoop-env.sh
在文件末尾添加:
# 将当前用户 root 赋给下面这些变量
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# JDK 安装路径,参考 cat /etc/profile |grep JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
# Hadop 安装路径下的 ./etc/hadoop 路径
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.3.4/etc/hadoop
(6)配置hadoop环境变量
vi /etc/profile
在文件末尾添加:
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
刷新配置文件:
source /etc/profile
(7)配置本机 ssh 免密登录
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
验证本机ssh到本机:
ssh [email protected]
# 不用输密码旧登录好了
(8)格式化 HDFS
hdfs namenode -format
(9)启动 Hadoop
cd /usr/local/hadoop/hadoop-3.3.4/sbin
start-all.sh
6、安装hbase
我选的hadoop版本为2.4.17,hadoop、jdk、hbase有版本规定,具体可查看官网
Hbase 安装包下载链接:
https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz
将安装包上传到虚拟机
/root
目录
# 进入到root目录
cd /root
# 解压
tar -zxvf hbase-2.4.17-bin.tar.gz
# 创建安装目录
mkdir /usr/local/hbase/
# 将解压后的hadoop挪到创建的安装目录
mv /root/hbase-2.4.17/ /usr/local/hbase/
# 进入到安装目录
cd /usr/local/hbase/hbase-2.4.17/
# 查看
ll
cd /usr/local/hbase/hbase-2.4.17/conf
(1)修改hbase-env.sh
vi hbase-env.sh
将以下内容粘在末尾
export JAVA_HOME=/usr/local/java/jdk1.8.0_202
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
注:HBase 自带 zookeeper ,上述配置文件中的 HBASE_MANAGES_ZK=true 默认为 true,代表使用自带的 zookeeper。此处使用默认配置,即使用 HBase 自带的 zookeeper。
(2)修改hbase-site.xml
vi hbase-site.xml
添加以下内容:
<property>
<!-- 伪分布式 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!-- region server 的共享 HDFS 目录,用来持久化 Hbase -->
<name>hbase.rootdir</name>
<value>hdfs://127.0.0.1:9000/hbase</value>
</property>
<property>
<!-- hbase 的 zookeeper 集群的地址列表,用逗号分隔 -->
<name>hbase.zookeeper.quorum</name>
<value>127.0.0.1</value>
</property>
<property>
<!-- zookeeper 快照存放地址 -->
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase/hbase-2.4.14/data/zookeeper</value>
</property>
注:伪分布式那个我自带有,如果有请忽略
(3)修改regionservers
vi regionservers
内容设置为:
hostname
hostname为你的主机名
(3)配置hbase环境变量
vi /etc/profile
在文件末尾添加:
export HBASE_HOME=/usr/local/hbase/hbase-2.4.17
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
刷新配置文件:
source /etc/profile
(4)启动hbase
start-hbase.sh
7、windows环境dll配置和hosts配置
springboot连接的时候报了个错
java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
是因为windows没有配置hadoop环境,但是windows只要下载winutils文件,然后配置环境变量,最后再把hadoop.dll文件放到 C:/windows/system32 下就可以了
下载链接:https://github.com/steveloughran/winutils
点击绿色的Code按钮,再选择Download Zip下载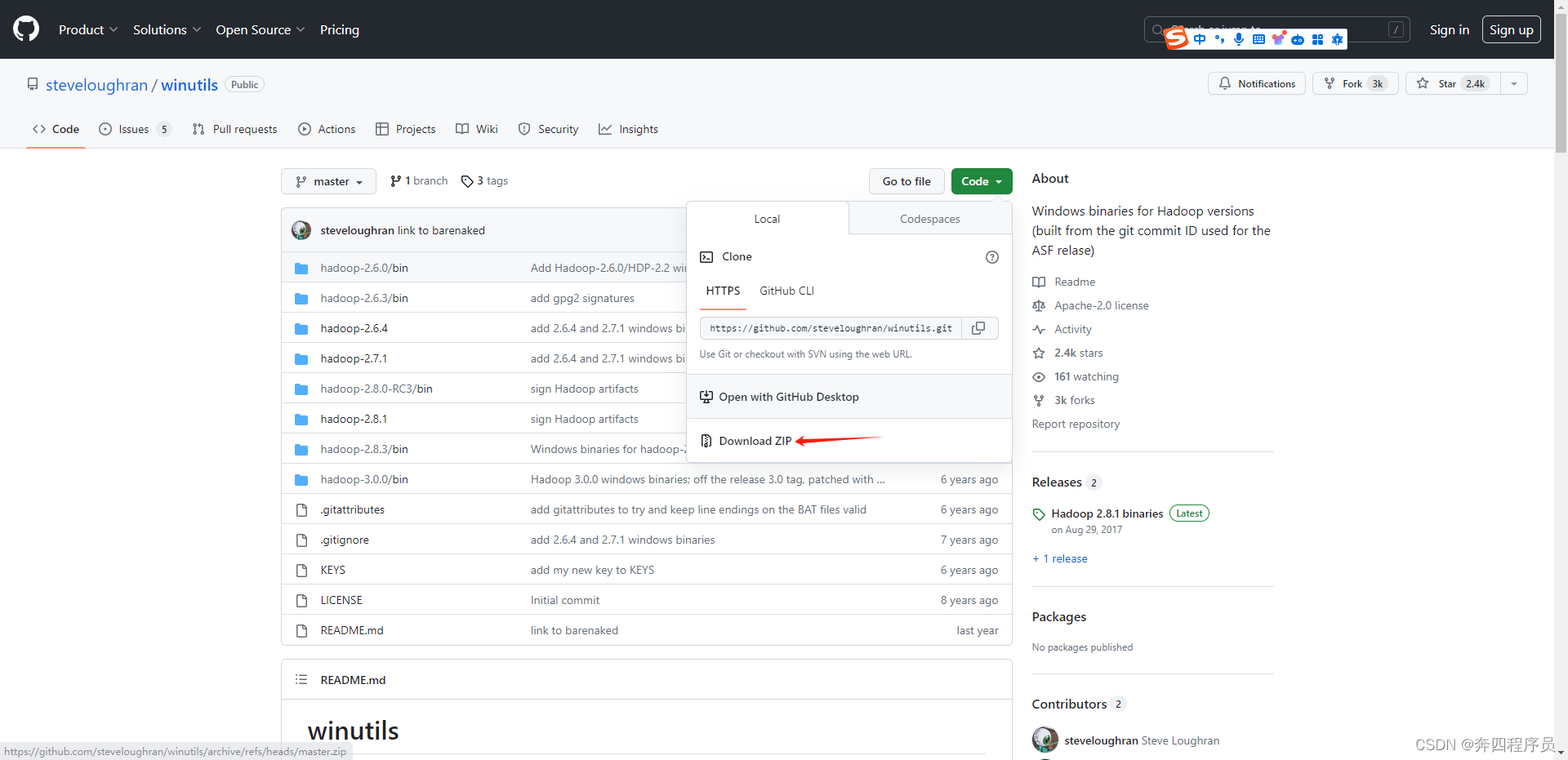
如果没有和你版本一致的文件夹,就选择和你版本最相近的,因为我的Hadoop版本是3.2.2版本,所以我选择的是hadoop-3.0.0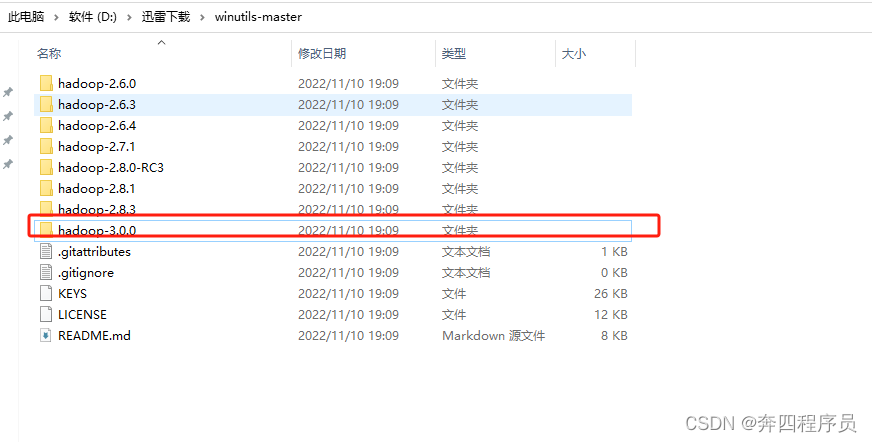
配置系统环境变量:
新增 变量名:HADOOP_HOME 变量值:就是你上面选择的hadoop版本文件夹的位置地址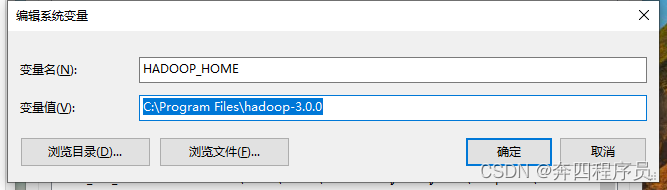 在 变量名:path 中新增 变量值:%HADOOP_HOME%\bin
在 变量名:path 中新增 变量值:%HADOOP_HOME%\bin
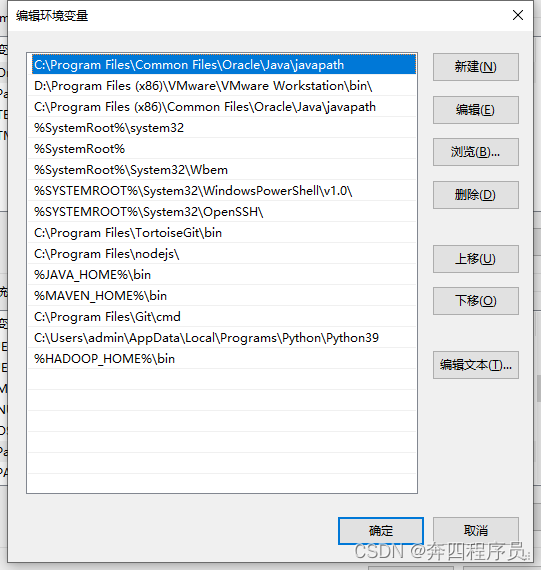
把hadoop.dll放到C:/windows/system32文件夹下
拷贝bin文件夹下的hadoop.dll文件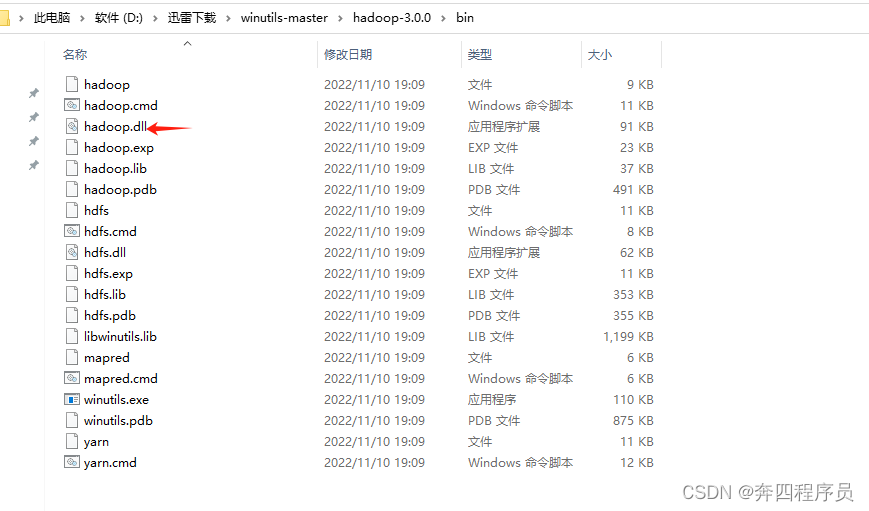
复制进C:/windows/system32文件夹下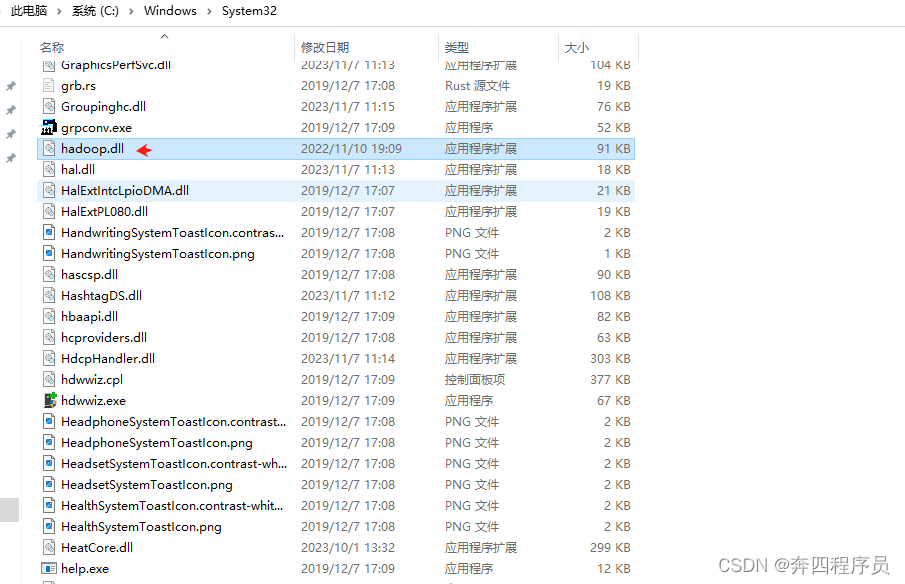
springboot 集成
pom.xml引入
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.4.13</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
ym配置:
hbase:
config:
hbase:
zookeeper:
property:
clientPort: 2181
quorum: 虚拟机ip
配置类:
packagecom.wish.hbase_demo.config;importorg.apache.hadoop.hbase.HBaseConfiguration;importorg.apache.hadoop.hbase.client.Admin;importorg.apache.hadoop.hbase.client.Connection;importorg.apache.hadoop.hbase.client.ConnectionFactory;importorg.springframework.boot.context.properties.ConfigurationProperties;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importjava.io.IOException;importjava.util.HashMap;importjava.util.Map;@Configuration@ConfigurationProperties(prefix ="hbase")publicclassHBaseConfig{privateMap<String,String> config =newHashMap<>();publicMap<String,String>getConfig(){return config;}publicvoidsetConfig(Map<String,String> config){this.config = config;}publicorg.apache.hadoop.conf.Configurationconfiguration(){org.apache.hadoop.conf.Configuration configuration =HBaseConfiguration.create();//此处可自己自定义和改造 拓展用// configuration.set(HBASE_QUORUM, "81.68.xx.xx:2181");// configuration.set(HBASE_ROOTDIR, "/");// configuration.set(HBASE_ZNODE_PARENT, "/hbase");for(Map.Entry<String,String> map : config.entrySet()){
configuration.set(map.getKey(), map.getValue());}return configuration;}@BeanpublicAdminadmin(){Admin admin =null;try{Connection connection =ConnectionFactory.createConnection(configuration());
admin = connection.getAdmin();}catch(IOException e){
e.printStackTrace();}return admin;}}
工具类:
packagecom.wish.hbase_demo;importlombok.extern.slf4j.Slf4j;importorg.apache.hadoop.hbase.*;importorg.apache.hadoop.hbase.client.*;importorg.apache.hadoop.hbase.filter.Filter;importorg.apache.hadoop.hbase.util.Bytes;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.stereotype.Service;importjava.io.IOException;importjava.util.*;@Service@Slf4jpublicclassHBaseUtils{@AutowiredprivateAdmin hbaseAdmin;/**
* 创建命名空间
* @param namespace
*/publicvoidcreateNamespace(String namespace){try{NamespaceDescriptor desc =NamespaceDescriptor.create(namespace).build();
hbaseAdmin.createNamespace(desc);
log.info("namespace {} is create success!", namespace);}catch(IOException e){
log.error("", e);}}/**
* 判断表是否存在
*
* @param tableName 表名
* @return true/false
*/publicbooleanisExists(String tableName){boolean tableExists =false;try{TableName table =TableName.valueOf(tableName);
tableExists = hbaseAdmin.tableExists(table);}catch(IOException e){
e.printStackTrace();}return tableExists;}/**
* 创建表
* @param tableName 表名
* @param columnFamily 列族
* @return true/false
*/publicbooleancreateTable(String tableName,List<String> columnFamily){returncreateTable(tableName, columnFamily,null);}/**
* 预分区创建表
* @param tableName 表名
* @param columnFamily 列族
* @param keys 分区集合
* @return true/false
*/publicbooleancreateTable(String tableName,List<String> columnFamily,List<String> keys){if(!isExists(tableName)){try{TableName table =TableName.valueOf(tableName);HTableDescriptor desc =newHTableDescriptor(table);for(String cf : columnFamily){
desc.addFamily(newHColumnDescriptor(cf));}if(keys ==null){
hbaseAdmin.createTable(desc);}else{byte[][] splitKeys =getSplitKeys(keys);
hbaseAdmin.createTable(desc, splitKeys);}returntrue;}catch(IOException e){
e.printStackTrace();}}else{System.out.println(tableName +"is exists!!!");returnfalse;}returnfalse;}/**
* 删除表
*
* @param tableName 表名
*/publicvoiddropTable(String tableName)throwsIOException{if(isExists(tableName)){TableName table =TableName.valueOf(tableName);
hbaseAdmin.disableTable(table);
hbaseAdmin.deleteTable(table);}}/**
* 插入数据(单条)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param column 列
* @param value 值
* @return true/false
*/publicbooleanputData(String tableName,String rowKey,String columnFamily,String column,String value){returnputData(tableName, rowKey, columnFamily,Arrays.asList(column),Arrays.asList(value));}/**
* 插入数据(批量)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param columns 列
* @param values 值
* @return true/false
*/publicbooleanputData(String tableName,String rowKey,String columnFamily,List<String> columns,List<String> values){try{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Put put =newPut(Bytes.toBytes(rowKey));for(int i=0; i<columns.size(); i++){
put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columns.get(i)),Bytes.toBytes(values.get(i)));}
table.put(put);
table.close();returntrue;}catch(IOException e){
e.printStackTrace();returnfalse;}}/**
* 获取数据(全表数据)
* @param tableName 表名
* @return map
*/publicList<Map<String,String>>getData(String tableName){List<Map<String,String>> list =newArrayList<>();try{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Scan scan =newScan();ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner){HashMap<String,String> map =newHashMap<>();//rowkeyString row =Bytes.toString(result.getRow());
map.put("row", row);for(Cell cell : result.listCells()){//列族String family =Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(), cell.getFamilyLength());//列String qualifier =Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(), cell.getQualifierLength());//值String data =Bytes.toString(cell.getValueArray(),
cell.getValueOffset(), cell.getValueLength());
map.put(family +":"+ qualifier, data);}
list.add(map);}
table.close();}catch(IOException e){
e.printStackTrace();}return list;}/**
* 获取数据(根据传入的filter)
* @param tableName 表名
* @param filter 过滤器
* @return map
*/publicList<Map<String,String>>getData(String tableName,Filter filter){List<Map<String,String>> list =newArrayList<>();try{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Scan scan =newScan();// 添加过滤器
scan.setFilter(filter);ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner){HashMap<String,String> map =newHashMap<>();//rowkeyString row =Bytes.toString(result.getRow());
map.put("row", row);for(Cell cell : result.listCells()){//列族String family =Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(), cell.getFamilyLength());//列String qualifier =Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(), cell.getQualifierLength());//值String data =Bytes.toString(cell.getValueArray(),
cell.getValueOffset(), cell.getValueLength());
map.put(family +":"+ qualifier, data);}
list.add(map);}
table.close();}catch(IOException e){
e.printStackTrace();}return list;}/**
* 获取数据(根据rowkey)
* @param tableName 表名
* @param rowKey rowKey
* @return map
*/publicMap<String,String>getData(String tableName,String rowKey){HashMap<String,String> map =newHashMap<>();try{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Get get =newGet(Bytes.toBytes(rowKey));Result result = table.get(get);if(result !=null&&!result.isEmpty()){for(Cell cell : result.listCells()){//列族String family =Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(), cell.getFamilyLength());//列String qualifier =Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(), cell.getQualifierLength());//值String data =Bytes.toString(cell.getValueArray(),
cell.getValueOffset(), cell.getValueLength());
map.put(family +":"+ qualifier, data);}}
table.close();}catch(IOException e){
e.printStackTrace();}return map;}/**
* 获取数据(根据rowkey,列族,列)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param columnQualifier 列
* @return map
*/publicStringgetData(String tableName,String rowKey,String columnFamily,String columnQualifier){String data ="";try{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Get get =newGet(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnQualifier));Result result = table.get(get);if(result !=null&&!result.isEmpty()){Cell cell = result.listCells().get(0);
data =Bytes.toString(cell.getValueArray(), cell.getValueOffset(),
cell.getValueLength());}
table.close();}catch(IOException e){
e.printStackTrace();}return data;}/**
* 删除数据(根据rowkey)
* @param tableName 表名
* @param rowKey rowKey
*/publicvoiddeleteData(String tableName,String rowKey)throwsIOException{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Delete delete =newDelete(Bytes.toBytes(rowKey));
table.delete(delete);
table.close();}/**
* 删除数据(根据rowkey,列族)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
*/publicvoiddeleteData(String tableName,String rowKey,String columnFamily)throwsIOException{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Delete delete =newDelete(Bytes.toBytes(rowKey));
delete.addFamily(columnFamily.getBytes());
table.delete(delete);
table.close();}/**
* 删除数据(根据rowkey,列族)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param column 列
*/publicvoiddeleteData(String tableName,String rowKey,String columnFamily,String column)throwsIOException{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));Delete delete =newDelete(Bytes.toBytes(rowKey));
delete.addColumn(columnFamily.getBytes(), column.getBytes());
table.delete(delete);
table.close();}/**
* 删除数据(多行)
* @param tableName 表名
* @param rowKeys rowKey集合
*/publicvoiddeleteData(String tableName,List<String> rowKeys)throwsIOException{Table table = hbaseAdmin.getConnection().getTable(TableName.valueOf(tableName));List<Delete> deleteList =newArrayList<>();for(String row : rowKeys){Delete delete =newDelete(Bytes.toBytes(row));
deleteList.add(delete);}
table.delete(deleteList);
table.close();}/**
* 分区【10, 20, 30】 -> ( ,10] (10,20] (20,30] (30, )
* @param keys 分区集合[10, 20, 30]
* @return byte二维数组
*/privatebyte[][]getSplitKeys(List<String> keys){byte[][] splitKeys =newbyte[keys.size()][];TreeSet<byte[]> rows =newTreeSet<>(Bytes.BYTES_COMPARATOR);for(String key : keys){
rows.add(Bytes.toBytes(key));}int i =0;for(byte[] row : rows){
splitKeys[i]= row;
i ++;}return splitKeys;}}
测试控制器:
packagecom.wish.hbase_demo.controller;importcom.wish.hbase_demo.HBaseUtils;importlombok.AllArgsConstructor;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RestController;importjava.io.IOException;importjava.util.Arrays;importjava.util.List;importjava.util.Map;@RestController@AllArgsConstructor@RequestMapping("/hbase/")publicclassFrontController{@AutowiredprivateHBaseUtils hbaseUtils;publicstaticfinalStringNAMESPACE="hbase_ns_test_1";@GetMapping("/test")publicvoidtest()throwsIOException{System.out.println("---开始创建test表---");
hbaseUtils.createTable(NAMESPACE+":"+"test",Arrays.asList("cf"));System.out.println("---判断test表是否存在---");Boolean t = hbaseUtils.isExists(NAMESPACE+":"+"test");System.out.println(t);System.out.println("\n---插入一列数据---");
hbaseUtils.putData(NAMESPACE+":"+"test","row1","cf","a","value1-1");System.out.println("\n---插入多列数据---");
hbaseUtils.putData(NAMESPACE+":"+"test","row2","cf",Arrays.asList("a","b","c"),Arrays.asList("value2-1","value2-2","value2-3"));System.out.println("\n---根据rowkey、列族、列查询数据---");String columnData = hbaseUtils.getData(NAMESPACE+":"+"test","row2","cf","b");System.out.println(columnData);System.out.println("\n---根据rowkey查询数据---");Map<String,String> rowData = hbaseUtils.getData(NAMESPACE+":"+"test","row2");System.out.println(rowData);System.out.println("\n---查询全表数据---");List<Map<String,String>> tableData = hbaseUtils.getData(NAMESPACE+":"+"test");System.out.println(tableData);System.out.println("\n---根据rowkey、列族、列删除数据---");
hbaseUtils.deleteData(NAMESPACE+":"+"test","row2","cf","b");System.out.println("\n---根据rowkey、列族删除数据---");
hbaseUtils.deleteData(NAMESPACE+":"+"test","row2","cf");System.out.println("\n---根据rowkey删除数据---");
hbaseUtils.deleteData(NAMESPACE+":"+"test","row2");System.out.println("\n---根据rowkey批量删除数据---");
hbaseUtils.deleteData(NAMESPACE+":"+"test",Arrays.asList("row1","row2"));System.out.println("\n---删除表---");
hbaseUtils.dropTable(NAMESPACE+":"+"test");}}
如果启动发现问题连接不上zookeeper,记得关闭虚拟机防火墙
注:hbase后台地址:
虚拟机ip:16010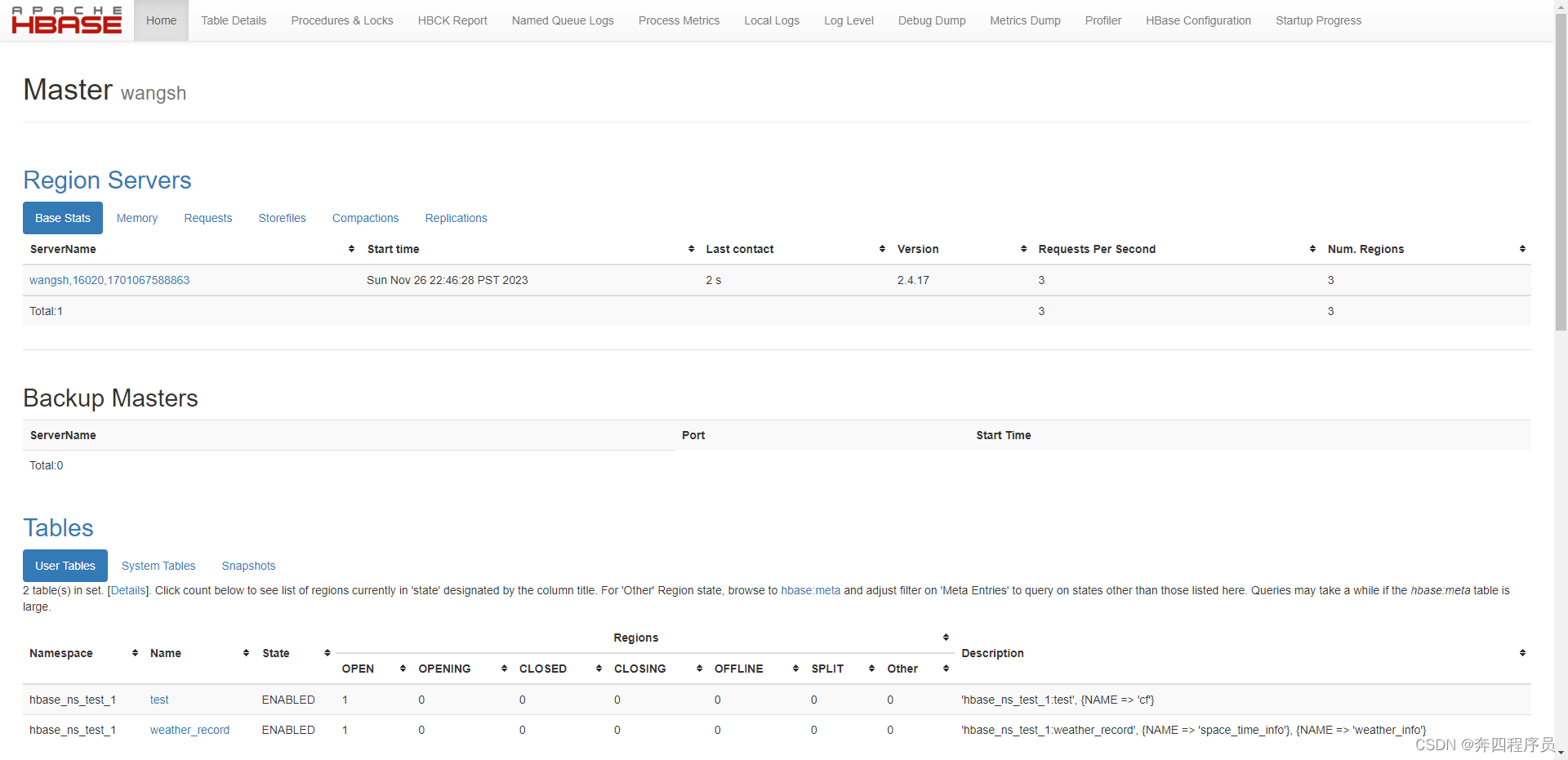
hadoop后台地址:
虚拟机ip:9870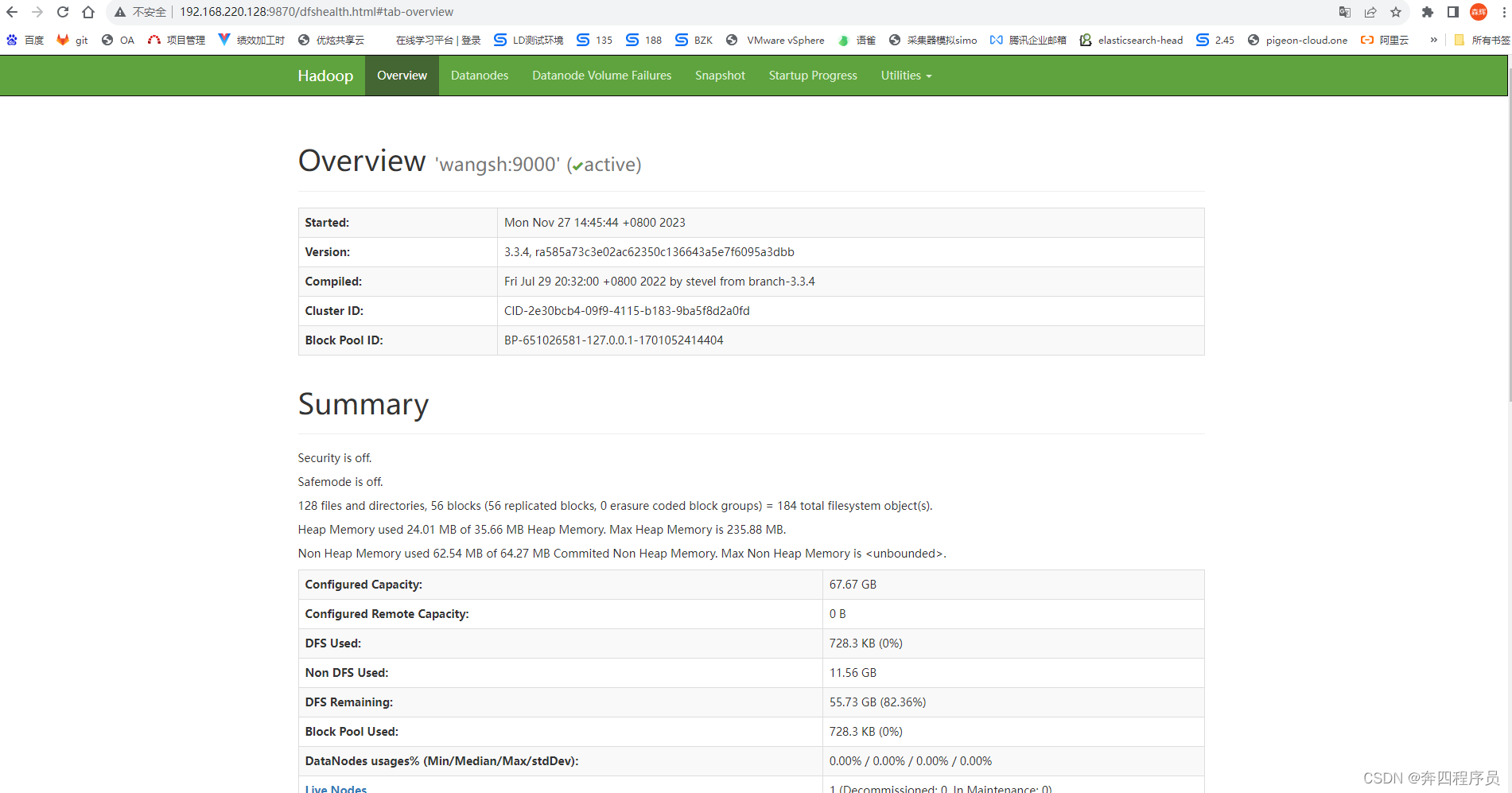
版权归原作者 奔四程序员 所有, 如有侵权,请联系我们删除。