
一、安装VMware Workstation 15.1
安装路径:VMware Workstation 15.1兼容win10 https://www.aliyundrive.com/s/uUNpgqctbi9
提取码: ix71
二、下载Ubuntu镜像
这里推荐直接进入Ubuntu的官网进行下载:Ubuntu20.04
三、安装Ubuntu镜像



6.可以自己改虚拟机的名称,这里建议存储放在除C盘外的其他盘里。然后【下一步】
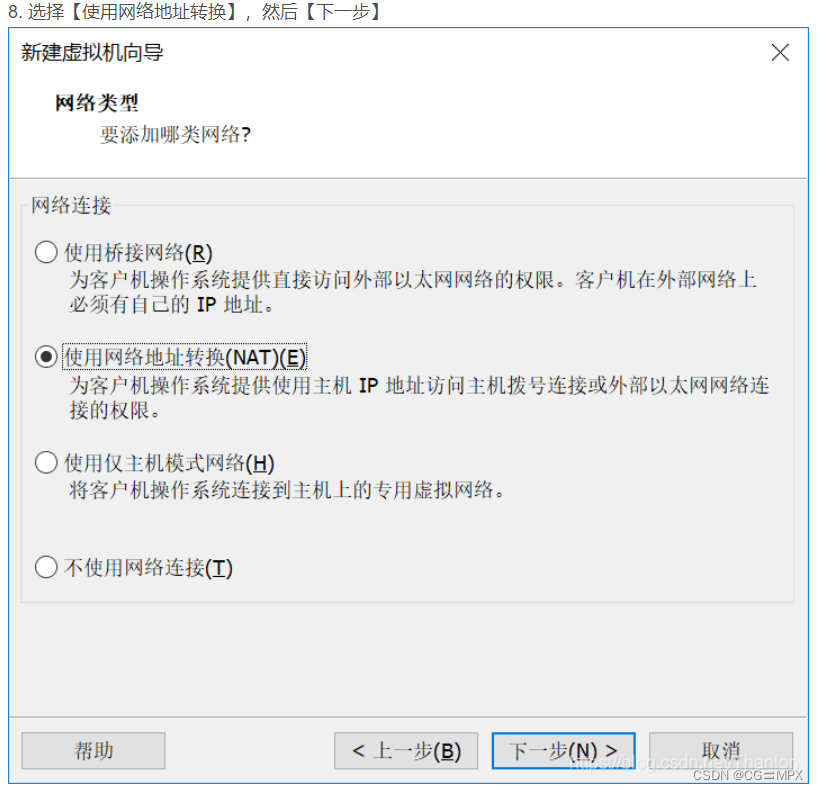
9.默认【下一步】

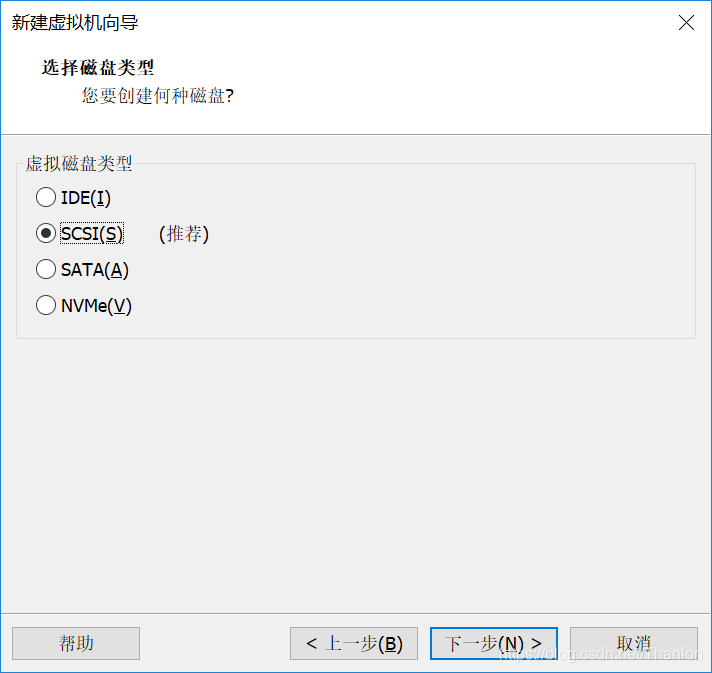


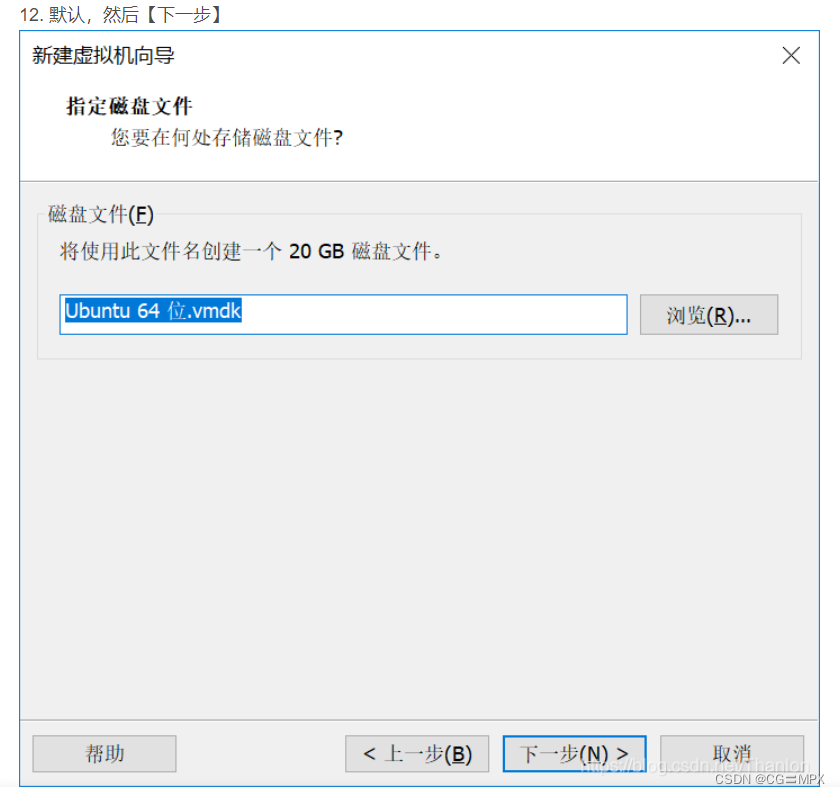
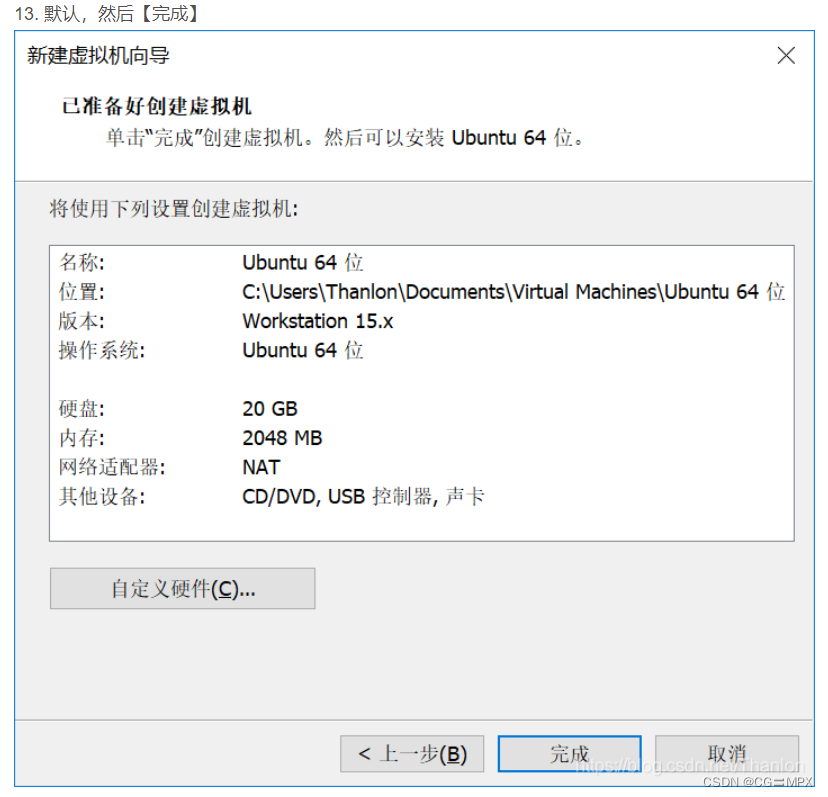
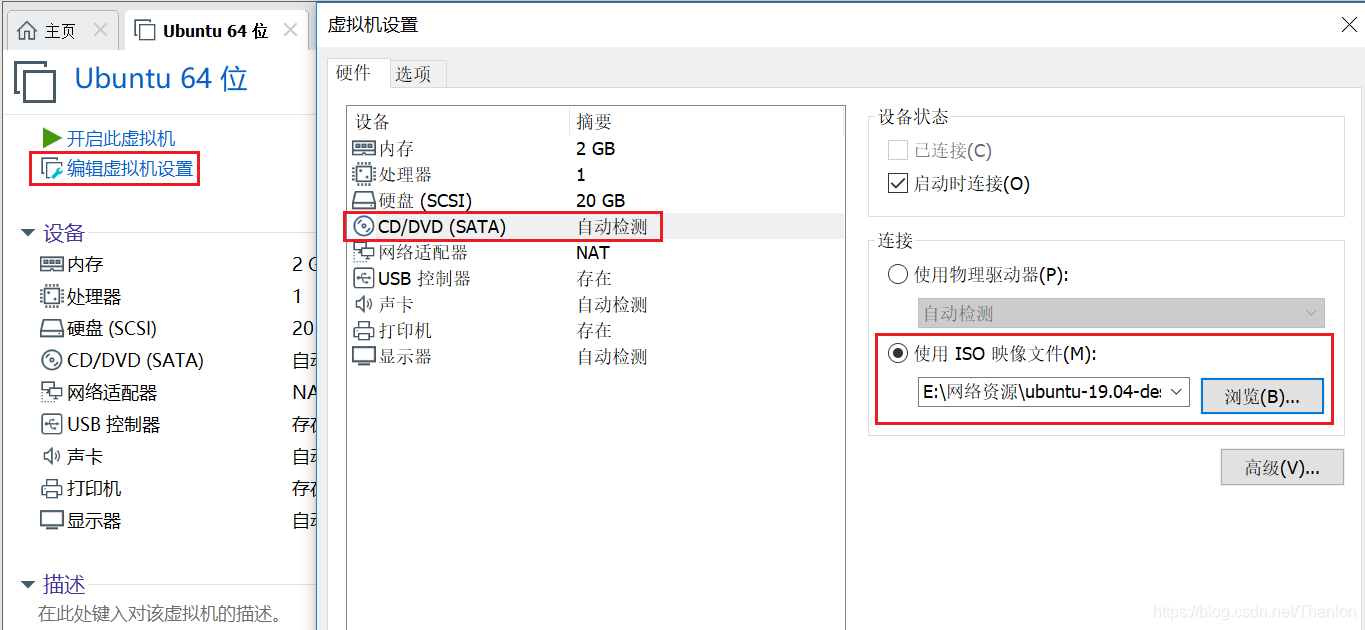
14.选择【编辑虚拟机设置】->【CD/DVD(SATA)】->【使用ISO映像(M)】,然后选择下载好的ubuntu20.04镜像文件。 (图片安装的是Ubuntu19.04镜像,但是操作是一样的。有想要安装Ubuntu19.04的朋友,可以参考这篇文章。)
15.安装Ubuntu
向下滚动找到中文简体

默认键盘设置,点击【继续】

默认选项,点击【继续】
点击【现在安装】
时间选择shanghai,点击【继续】
设置用户名和密码(登录方式可按照自己需求来设置)点击【继续】
上个步骤完成后,就要等待安装,安装过程下载解压的文件较多,会很慢,要保证电脑常亮,不要进入待机状态,不然虚拟机可能会出现卡顿。安装完成后,点击【现在重启】
重启进入后,点击自己的用户,输入密码,【回车】
然后就是一些基础的设置
 打开之后,Ubuntu系统界面不是全屏,可以右击桌面,点击【显示设置】,【显示器】,将分辨率调成如图数值就可以了。
打开之后,Ubuntu系统界面不是全屏,可以右击桌面,点击【显示设置】,【显示器】,将分辨率调成如图数值就可以了。

以上安装过程建议在使用有线网环境下进行,因为本人是按照这个步骤安装的,安装完成后并没有出现IP地址上的问题,虚拟机上的网络是可用的。显示也是有线已连接。
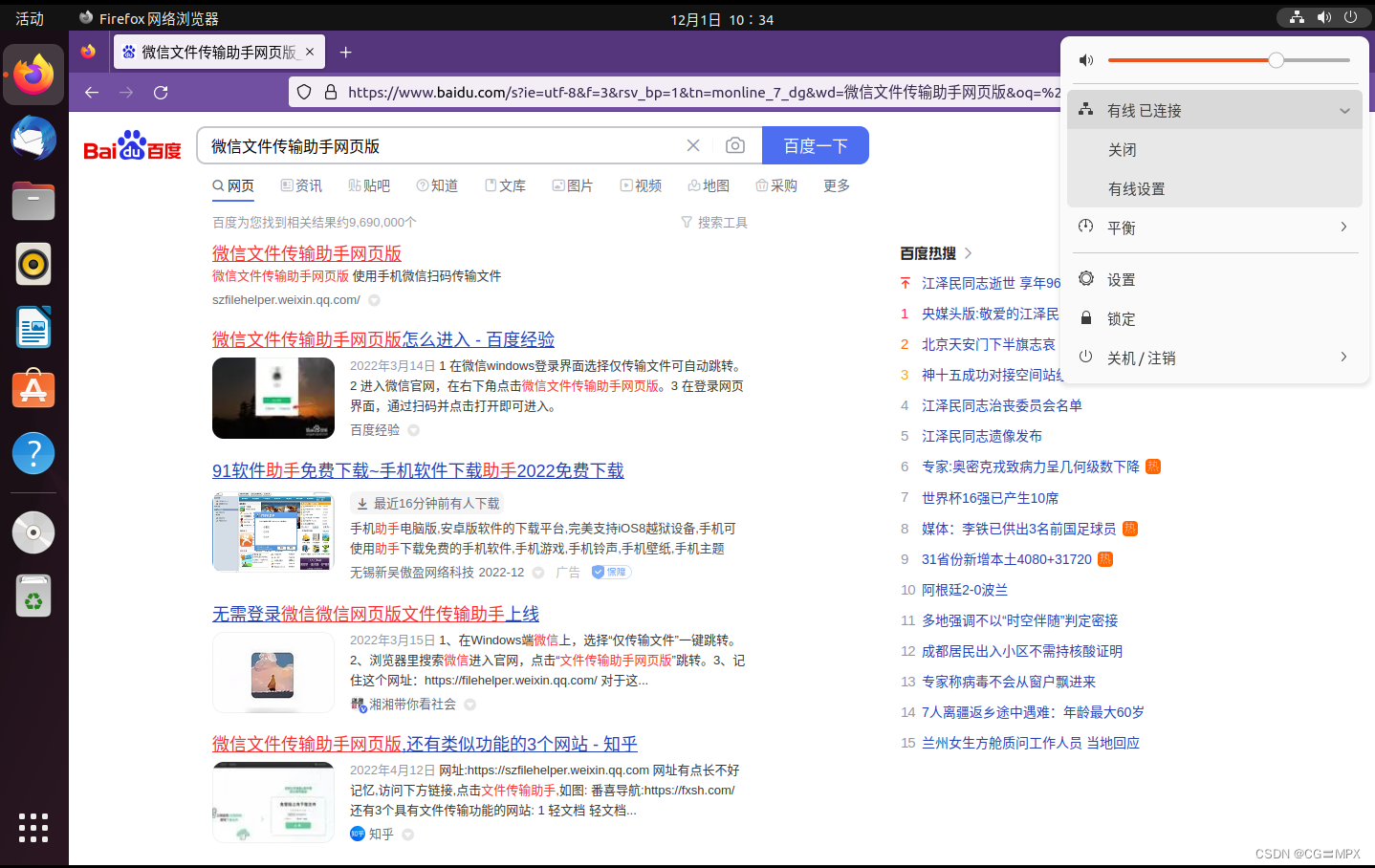
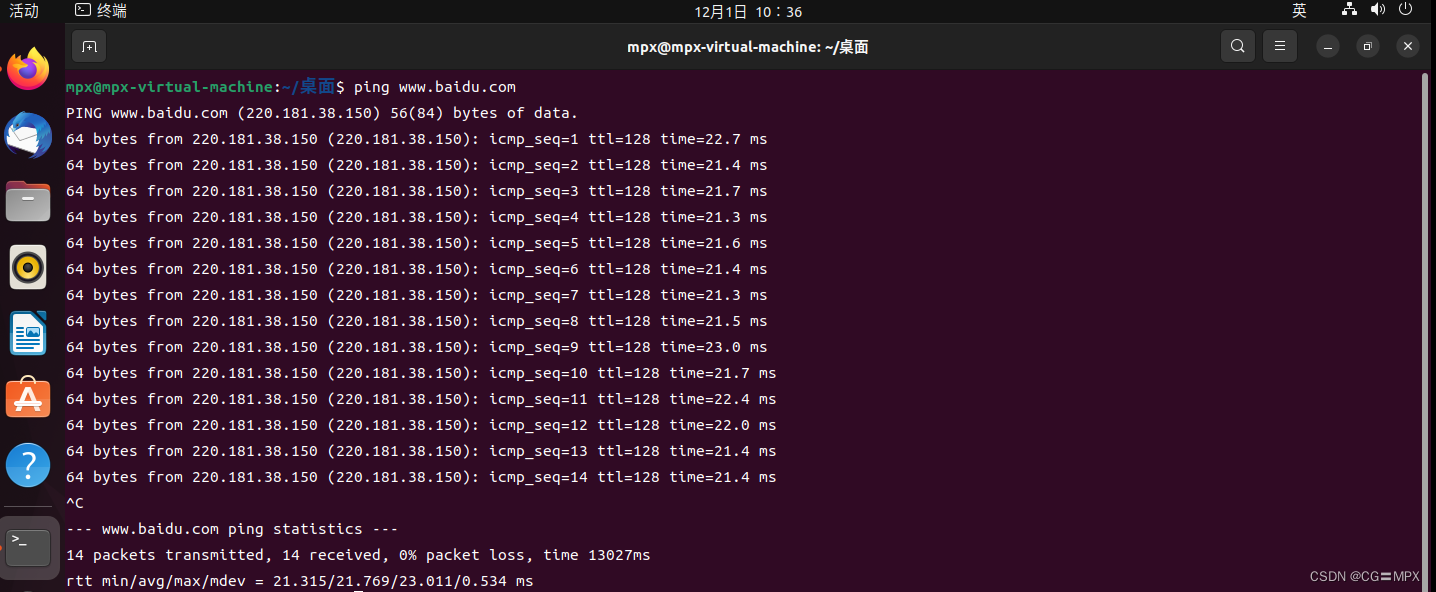
利用终端 ping www.baidu.com,也是可以ping通的。
下载vim数据包
sudo apt-get install vim
更改阿里云镜像源
点击左下角九个点的方块,然后找到并点击【软件和更新】
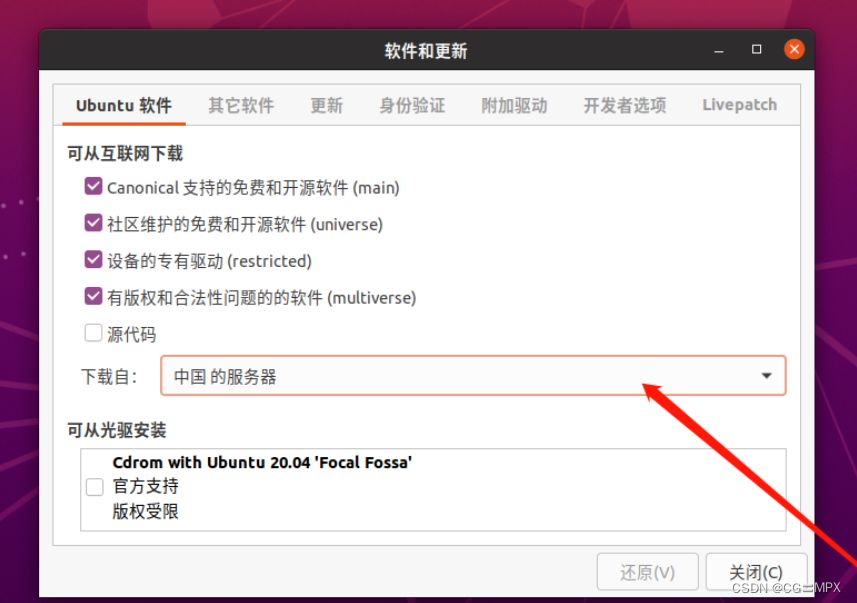


点击【重新载入】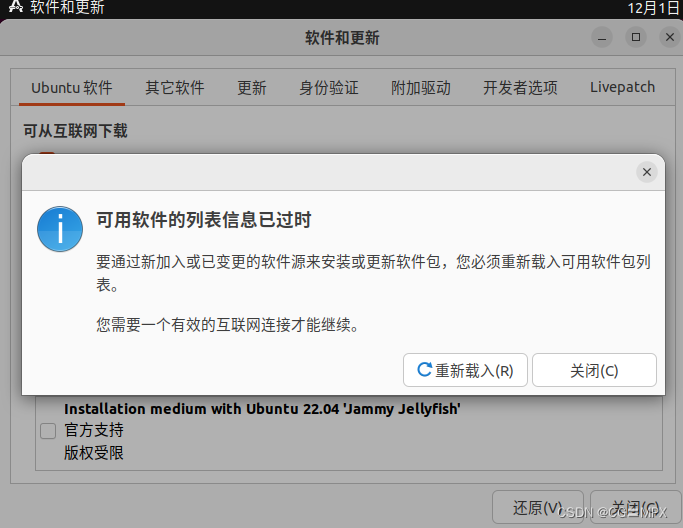
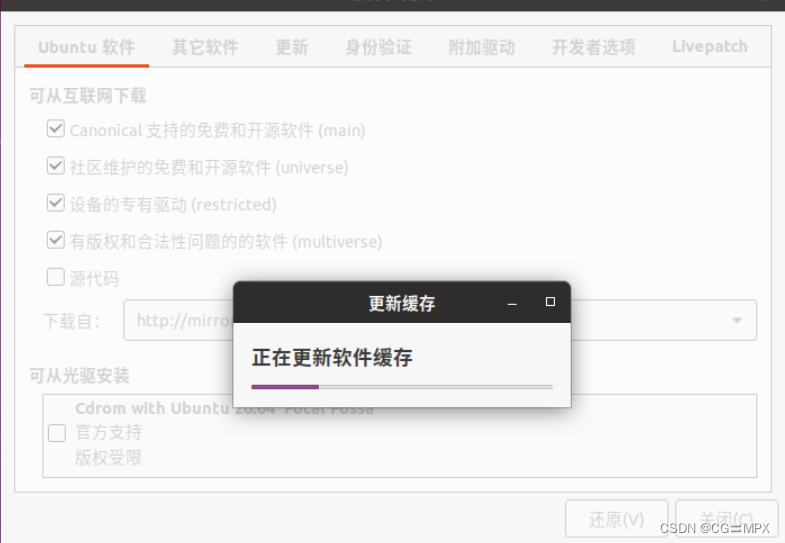
sudo apt-get update
四、配置JAVA环境
打开下载Java JDK的文件夹,右键【在终端打开】,输入命令
tar -zxvf jdk-19_linux-x64_bin.tar.gz
然后将解压后的文件夹移动到 /usr/java 下(需要输入管理员密码),输入命令
sudo mv jdk-19.0.1 /usr/java

显示主目录的隐藏文件 .profile 文件,进行环境配置。
用文本编辑器打开它,然后在末尾添加如下代码,然后点击【保存】。
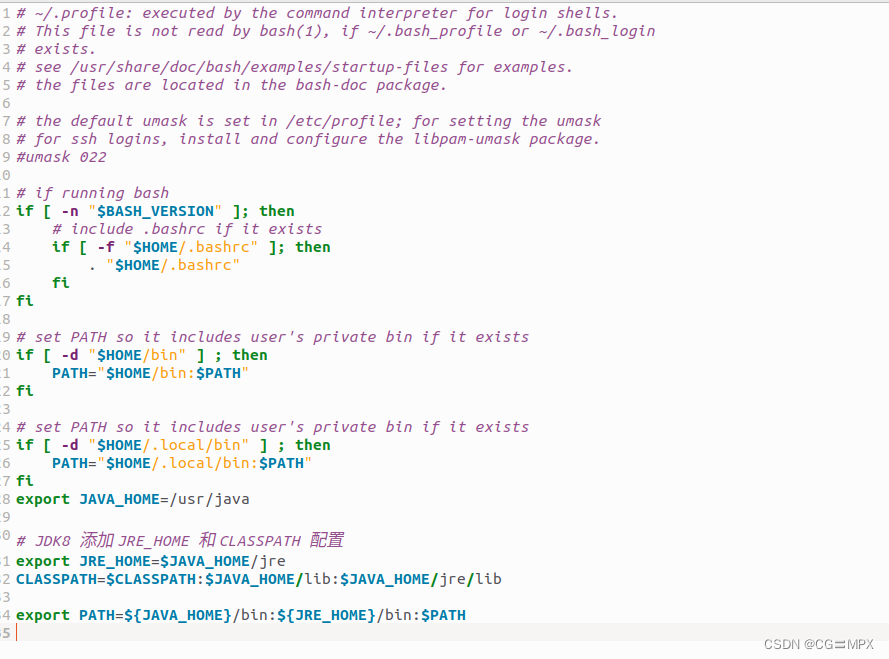
export JAVA_HOME=/usr/java
# JDK8 添加 JRE_HOME 和 CLASSPATH 配置
export JRE_HOME=$JAVA_HOME/jre
CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
 输入命令,运行配置环境。
输入命令,运行配置环境。
source ~/.profile

建立系统软链接
sudo update-alternatives --install /usr/bin/javac javac /usr/java/bin/javac 1
sudo update-alternatives --install /usr/bin/javac java /usr/java/bin/java 1
输入命令查看Java版本
java -version

五、配置安装Hadoop
解压压缩包,然后将解压后的文件夹移动到 /usr/hadoop 下(需要输入管理员密码),输入命令
tar -zxvf hadoop-3.3.2.tar.gz
sudo mv hadoop-3.3.2 /usr/hadoop
配置JDK路径
打开文件管理器,找到 Hadoop 安装目录下的 /etc/hadoop/hadoop-env.sh 并使用文本编辑器打开(默认双击)
注意此处是 hadoop-env.sh 而不是 hadoop-env.cmd
在文件末尾添加以下代码(建议直接复制)并保存退出
export JAVA_HOME=/usr/java
配置Hadoop
在刚刚的目录下找到 core-site.xml 文件,用文本编辑器打开
在 <configuration> 标签中添加下面的配置,保存并退出
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
继续在文件夹中找到 hdfs-site.xml 文件,用文本编辑器打开
在 <configuration> 标签中添加下面的配置,保存并退出
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
以上全部配置完成。
修改虚拟机名称
hostname
hostnamectl set-hostname ‘hadoop01’
hostname
ifconfig
#分别得到三台设备的IP地址
sudo vim /etc/hosts
#将IP地址和用户名编辑在后面
 配置SSH免密登录
配置SSH免密登录
sudo apt-get install openssh-server

ssh localhost #登录主机,要输入yes
exit #退出主机
cd ~/.ssh/ #进入到ssh里面
ssh-keygen -t rsa #按四次回车

用户名改为自己的即可。
#三台机器互相免密登录
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
cat ./id_rsa.pub >> ./authorized_keys #让master 节点可以无密码 SSH 本机,在 master 节点上执行
ssh master #在主结点上实现ssh免密登录
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/ #slave1是结点名称hadoop是自己主机名,发送公钥至从结点
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了
#上述操作需要虚拟机之间互相操作,即主节点要发给从节点,确认后从节点还要发给主节点,少操作一步都会使SSH免密登录不成功。
配置集群环境
配置集群模式时,需要修改“/usr/local/hadoop/etc/hadoop”目录下的配置文件,包括workers、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。【主机名和路径需要自己修改】
vim workers
#命令
#以下是写入文件的内容(按【i】编辑,只能用键盘方向键移动光标,按【Esc】退出编辑,输入【:wq】保存并退出文件)
hadoopWyc
hadoopWyc2
hadoopWyc3
vim core-site.xml
#命令
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoopWyc:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
vim hdfs-site.xml
#命令
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoopWyc2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
vim mapred-site.xml
#命令
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoopWyc:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoopWyc:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
vim yarn-site.xml
#命令
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoopWyc</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
分发文件
此步骤也可以将上个步骤重复操作。
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz hadoop # 先压缩再复制
cd ~
scp hadoop.master.tar.gz hadoopWyc2:/home/
scp hadoop.master.tar.gz hadoopWyc3:/home/
#从节点虚拟机解压缩
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf /home/hadoop.master.tar.gz -C /usr/local
sudo chown -R wyc /usr/local/hadoop
启动Hadoop
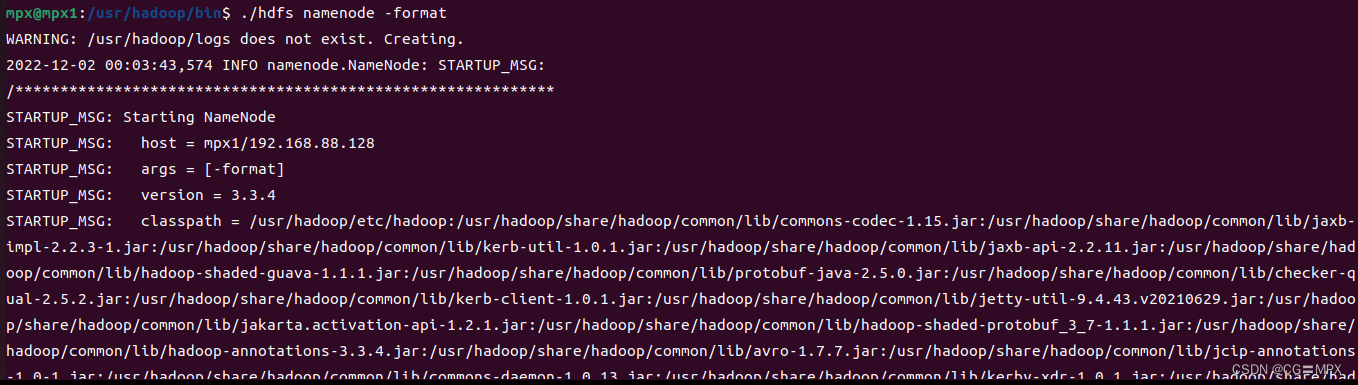
cd /usr/hadoop/bin
#打开任意终端,进入 /hadoop/bin 路径
./hdfs namenode -format
#进行格式化
cd /usr/hadoop/sbin
#进入 /hadoop/sbin 路径
./start-all.sh
#启动 hadoop
jps
#查看进程

cd /usr/local/hadoop
./bin/hadoop version
#查询Hadoop版本
如果出现如下图中的报错,参考此文。
root@hadoopWyc3:/usr/local/hadoop# ./sbin/start-dfs.sh
Starting namenodes on [hadoopWyc]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoopWyc2]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
数据分析
安装配置好Hadoop之后,可以利用Hadoop来进行数据分析。【相关资源点这里】
unzip bdintro-master.zip #解压缩
cd bdintro-master #进入解压文件
unzip hadoop-yangyaru-datanode-dell119.log.zip
hdfs dfs -copyFromLocal hadoop-yangyaru-datanode-dell119.log /
#下载bigdata-0.0.1.jar
#分析日志文件
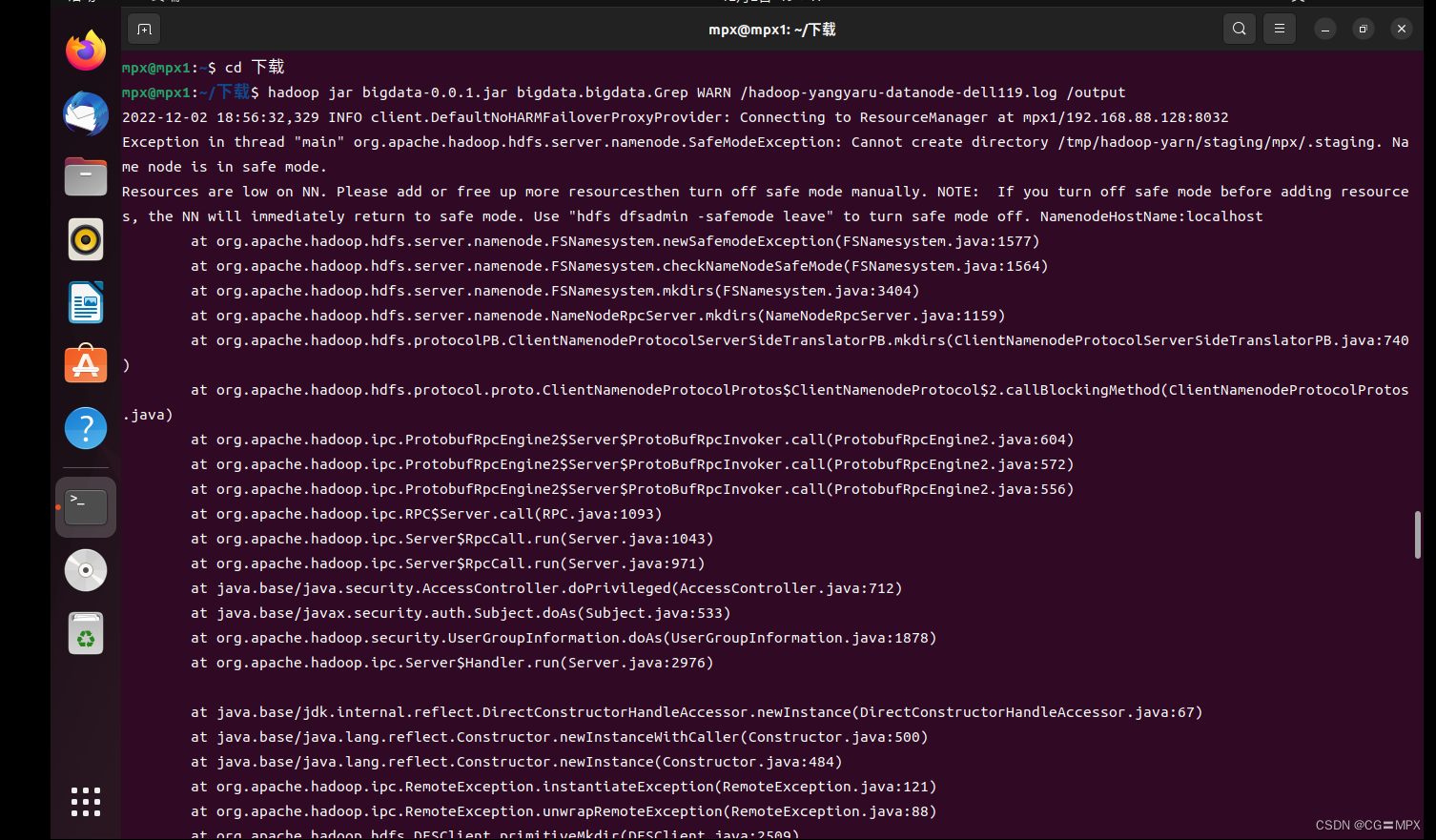
hadoop jar bigdata-0.0.1.jar bigdata.bigdata.Grep WARN /hadoop-yangyaru-datanode-dell119.log /output
#数据分析交通文件
hadoop jar bigdata-0.0.1.jar bigdata.bigdata.TrafficTotal /Traffic_Violations.csv /output/traffic


创作不易,请多支持!
版权归原作者 CG〓MPX 所有, 如有侵权,请联系我们删除。