

前言
Selenium 是一个用于Web应用程序测试的工具。
Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。
这个工具的主要功能包括:
浏览器兼容性测试:测试应用程序看是否能够很好的工作在不同浏览器和操作系统之上;
系统功能测试:创建回归测试检验软件功能和用户需求;
支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
通过本篇,你将学会使用 selenium 动态加载HTML的技巧,包括:操作输入框,键盘,下拉条,页面跳转,标签内容读取...。
正文
Selenium 是浏览器自动测试框架,模拟浏览器,驱动浏览器执行特定的动作,并可获取浏览器当前呈现的页面的源代码,可见即可爬。正是利用了这一特点,Python 可以实现对动态页面的渲染,做到可见即可爬。
一、chromedriver 驱动安装
Selenium 相当于机器人,可以模拟人在浏览器中的行为,并自动处理浏览器中的行为,如:单击、翻页、输入数据、回车和删除cookie操作。 而 Chromedriver 是 Chrome 浏览器的驱动程序,可以移动浏览器。
1. 驱动程序介绍
驱动器因浏览器而异,案例以 Chrome 浏览器为例,以下是各种浏览器及其相应的驱动程序:
浏览器驱动地址Chromehttp://chromedriver.storage.googleapis.com/index.htmlEdgehttps://developer.Microsoft.com/en-us/Microsoft-edge/tools/web驱动程序/Firefoxhttps://github.com/Mozilla/gecko driver/releasesSafarihttps://WebKit.org/blog/6900/web驱动程序- support-in-safari-10
2. 驱动程序安装
**注意:**Chromedriver 要下载与本地 Chrome 浏览器相对应的版本。
** ****建议:**直接使用 Chromedriver 驱动的绝对路径,这样做能规避很多坑,听我的没错。
from selenium import webdriver
# 指定chromedriver的绝对路径
driver_path = r'C:\Users\Administrator\Desktop\chromedriver.exe'
# 初始化driver
drive = webdriver.Chrome(executable_path=driver_path)
# 请求页面,打开网页
drive.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(drive.page_source)
# 关闭网页
drive.close()
Chromedriver 主要负责爬取动态页面的前面部分 -- 打开HTML页面,后面页面的渲染和操作,就是 Selenium 的工作内容了。
二、Selenium 插件安装
在【Terminal】控制台**"pip install selenium****"**命令导入,或者在导航栏下【Pycharm - Settings - Python Interpreter 】自动导入插件,以后者为例:
三、Selenium 常用方法
1. 获取节点信息
据说旧版本是使用【find_element_by_xx】方法获取节点,新版本已经不可用了,我目前使用的 Selenium 为【4.4.3】版本:
- 获取单个节点信息(多个则匹配第一个):find_element(By.xx, 'xx')
- 获取多个节点信息(加S):find_elements(By.xx, 'xx')
常用方法
描述
By.ID根据id值获取对应的节点By.NAME根据name值获取对应的单个或多个节点By.TAG_NAME根据节点名获取节点By.CLASS_NAME根据class值获取节点By.LINK_TEXT根据链接文本获取对应的节点By.PARTIAL_LINK_TEXT根据部分链接文本获取对应的节点By.CSS_SELECTOR根据CSS选择器获取节点,对应的value字符串字符串CSS位置By.XPATH根据By.XPATH获取节点,对应的value字符串节点位置
- 案例:
from selenium import webdriver # 浏览器驱动
from selenium.webdriver.common.by import By # 节点定位
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
# 通过id属性获取节点
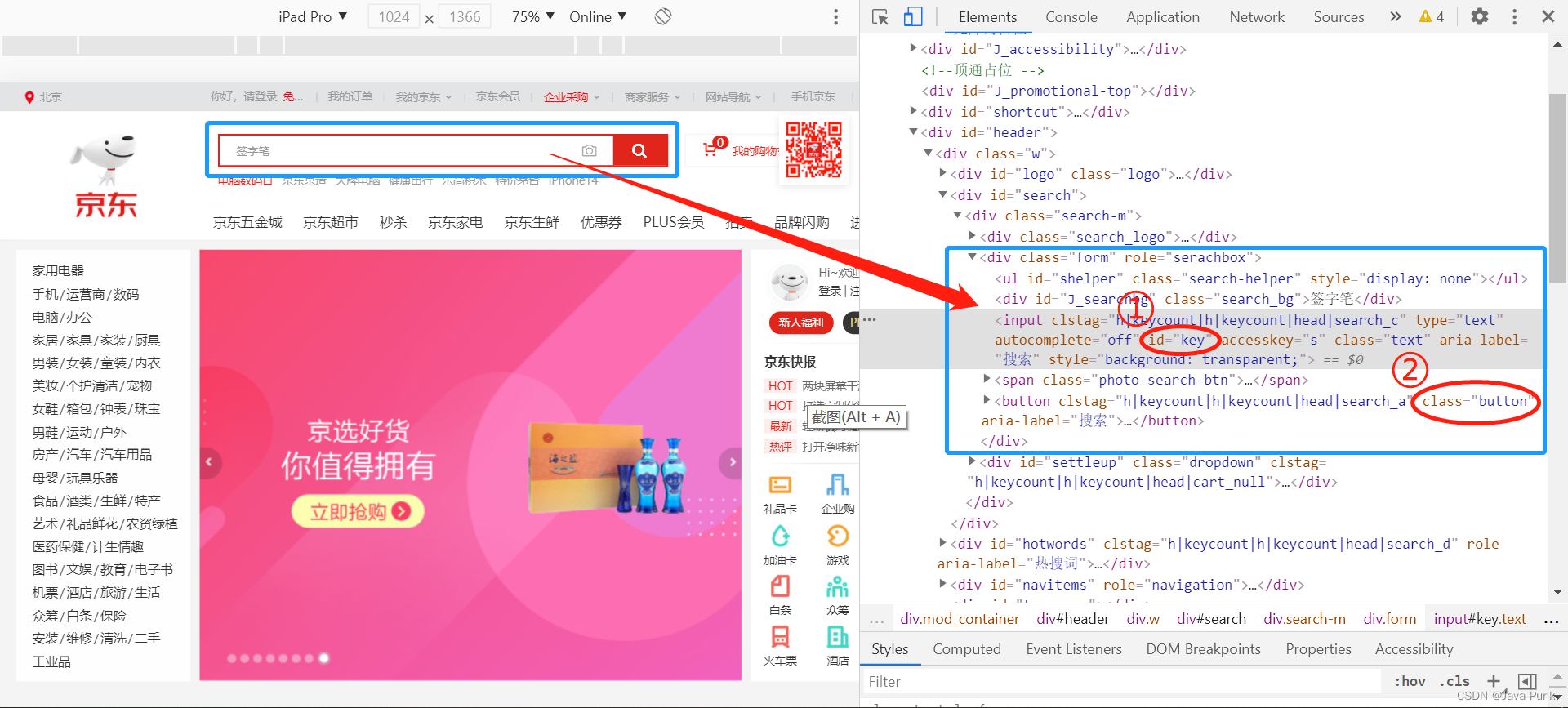
driver.find_element(By.ID, 'key').send_keys("华为mate50")
# 通过class属性获取节点,并触发点击事件
driver.find_element(By.CLASS_NAME, 'button').click()
time.sleep(5)
driver.close()
- HTML说明:输入框和按钮的属性分别是【id="key"】和【class="button"】
2. 获取元素属性
常用方法
描述
get_attribute(xx)获取当前节点xx属性id获取当前节点idlocation获取当前节点位置tag_name获取当前节点名称size获取当前节点大小text获取当前节点文本
- 案例:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
el_div = driver.find_element(By.ID, 'key')
print(el_div)
print(el_div.get_attribute("class")) # class属性
print(el_div.id) # id
print(el_div.location) # 位置
print(el_div.tag_name) # 标签名
print(el_div.size) # 大小
print(el_div.text) # 文本
3. 页面交互:搜索框输入,上下滚动下拉条,页面前进和后退
常用方法描述send_keys(var str)标签栏输入 str,需要先获取标签位置
send_keys(Keys.PAGE_UP)
翻页键上(Page Up),需要先获取标签位置
send_keys(Keys.PAGE_DOWN)
翻页键下(Page Down),需要先获取标签位置
execute_script('window.scrollTo(0,document.body.scrollHeight)')向下滚动到底部execute_script('window.scrollTo(0,0)')向上滚动到顶部execute_script('window.scrollTo(0,int n)')
向下滚动 n px 位置
script = "arguments[0].scrollIntoView();";
driver.execute_script(script, driver.find_element(By.xx, 'xx'))向下滚动到目标元素位置,如:ID = xx
- 案例:
import time # 时间控制
from selenium import webdriver # 浏览器驱动
from selenium.webdriver import Keys # 键盘驱动
from selenium.webdriver.common.by import By # 节点定位
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
# 根据id属性获取【输入框】
_input = driver.find_element(By.ID, 'key')
# 标签内输入搜索内容
_input.send_keys('华为mate50')
# 标签内操作向上,向下翻页
_input.send_keys(Keys.PAGE_DOWN)
_input.send_keys(Keys.PAGE_UP)
# 根据class属性获取【搜索】按钮,触发点击事件
driver.find_element(By.CLASS_NAME, 'button').click()
# 向下滚动到底部
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
# 向上滚动到顶部
driver.execute_script('window.scrollTo(0,0)')
# 向下滚动1000位置
driver.execute_script('window.scrollTo(0,1000)')
time.sleep(2)
# 向下滚动目标元素位置
script = "arguments[0].scrollIntoView();";
driver.execute_script(script, driver.find_element(By.ID, 'J_bottomPage'))
time.sleep(2)
driver.get('https://www.baidu.com/')
driver.back()
time.sleep(2)
driver.forword()
time.sleep(2)
driver.close()
- 输入+点击的代码可以简化一下:
driver.find_element(By.ID, 'key').send_keys("华为mate50")
4. 页面等待:显式,隐式
当进入一个新的网页时,有时网页的加载并没有那没快,当网速很慢时尤其明显,特别是针对商品列表,图片类的信息,这时候是爬不到完整数据的,所以,我们需要等待页面加载完成。
** 等待的方式有3种:**
- 强制等待:必须等这么久,没有任何前提条件,和页面有没有渲染无关;
- 隐性等待:设置一个时间,在设置的时间内,如果页面加载完成了就进行下一步;如果没有加载完成,则会报超时异常;
- 显式等待:设置一个等待时间,一个间隔时间,每隔一段时间执行下util中的方法,直到等待时间结束。
** 注意:**虽然 time.sleep(n) 简单,但是有时设置的睡眠时间过长,干等很浪费效率的,所以一般只用在想要暂停代码查看页面效果的地方,就像案例中一样。
使用方法描述强制time.sleep(int n)强制等待 n 秒,不关注页面渲染情况隐式driver.implicitly_wait(int n)等待 n 秒,如果页面加载出来就继续,否则报异常显式wait = WebDriverWait(driver, int n, int m)
wait.until(EC.presence_of_element_located((By.By.xx, 'xx')))
等待 n 秒,每隔 m 秒 加载一下 until 方法,如果 until 方法内的属性加载出来则继续,否则循环,直到 n 秒结束继续执行。
注:xx代表标签属性
- 案例:
import time # 时间控制
from selenium import webdriver # 浏览器驱动
from selenium.webdriver.common.by import By # 节点定位
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
# 根据id属性获取【搜索框】位置,输入搜索内容
driver.find_element(By.ID, 'key').send_keys("华为mate50")
# 根据class属性获取【搜索】按钮位置,触发点击事件
driver.implicitly_wait(5)
driver.find_element(By.CLASS_NAME, 'button').click()
wait = WebDriverWait(driver, 10, 0.2)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "p-img")))
# 向下滚动到底部
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(3)
# 向上滚动到顶部
driver.execute_script('window.scrollTo(0,0)')
time.sleep(3)
driver.close()
5. 键盘事件
代码
含义
Keys.BACK_SPACE
回退键(BackSpace)
Keys.TAB
制表键(Tab)
Keys.ENTER
回车键(Enter)
Keys.SHIFT
大小写转换键(Shift)
Keys.CONTROL
Control键(Ctrl)
Keys.ALT
ALT键(Alt)
Keys.ESCAPE
返回键(Esc)
Keys.SPACE
空格键(Space)
Keys.PAGE_UP
翻页键上(Page Up)
Keys.PAGE_DOWN
翻页键下(Page Down)
Keys.END
行尾键(End)
Keys.HOME
行首键(Home)
Keys.LEFT
方向键左(Left)
Keys.UP
方向键上(Up)
Keys.RIGHT
方向键右(Right)
Keys.DOWN
方向键下(Down)
Keys.INSERT
插入键(Insert)
DELETE
删除键(Delete)
NUMPAD0 ~ NUMPAD9
数字键1-9
F1 ~ F12
F1 - F12键
(Keys.CONTROL, ‘a’)
组合键Control+a,全选
(Keys.CONTROL, ‘c’)
组合键Control+c,复制
(Keys.CONTROL, ‘x’)
组合键Control+x,剪切
(Keys.CONTROL, ‘v’)
组合键Control+v,粘贴
**6. **selenium转BeautifulSoup
根据小编的开发经验,selenium 很擅长模拟和测试,它的特性是BeautifulSoup不具备的,但是对于取值操作,简单的还好,复杂点的比如循环<li>标签这种操作,我还是觉得BeautifulSoup更方便。
在爬虫的世界里,大量有价值的数据都是循环展现的,比如:某排行榜,某商品列表等...所以,selenium+BeautifulSoup的操作必不可少。
- 核心代码
from selenium import webdriver # 浏览器驱动
from bs4 import BeautifulSoup # 解析html
driver = webdriver.Chrome()
driver.get('https://www.jd.com/')
# 获取完整渲染的网页源代码
pageSource = driver.page_source
soup = BeautifulSoup(pageSource,'html.parser')
# ...
四、注意事项
4.1 no such element: Unable to locate element
在某些场景下使用 selenium 的 driver.find_element(By.CLASS_NAME,'xxxx') 定位web元素的时候,会提示找不到定位元素的异常,比如:我们案例中要定位的包含 class="button cw-icon" 属性的按钮。
- 异常原文
selenium.common.exceptions.NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":".button cw-icon"}
原因分析
经过认真检查,发现从web上获取的元素的class_name并没有错,问题的原因只能是多个属性间的空格“ ”不能被 find_element() 识别造成的。解决办法
针对前端代码一个标签内使用多个属性值的情况,我们只需要把class_name里面的空格间隔符替换成英文的“.”就可以了。
# 注释掉的为原方法,未注释的是修改以后的方法
# driver.find_element(By.CLASS_NAME,'button cw-icon').click()
driver.find_element(By.CLASS_NAME,'button.cw-icon').click()
4.2 其他 ...
版权归原作者 Java Punk 所有, 如有侵权,请联系我们删除。