
一, MySQl 8.0 窗口函数
窗口函数适用场景:
对分组统计结果中的每一条记录进行计算的场景下, 使用窗口函数更好, 注意, 是每一条!! 因为MySQL的普通聚合函数的结果(如 group by)是
每一组只有一条记录!!!
可以跟Hive的对比着看: 点我, 特么的花了一晚上整理, 没想到跟Hive 的基本一致, 还不因为好久没复习博客了, 淦
注意:
mysql 因为没有array数据结构, 无法像Hive一样 行列进行转换;
1.1 窗口函数分类
- MySQL从8.0版本开始支持窗口函数。窗口函数的作用类似于
在查询中对数据进行分组,不同的是,分组操作会把分组的结果聚合成一条记录,而窗口函数是将分组的结果置于每一条数据记录中。 - 窗口函数可以分为
静态窗口函数和动态窗口函数- 静态窗口函数的窗口大小是固定的, 不会因为记录的不同而不同;- 动态窗口函数的窗口大小会随着记录的不同而变化;
窗口函数总体上可以分为序号函数, 分布函数, 前后函数, 首尾函数和其他函数;

1.2 语法结构
- 窗口函数的语法结构: - 函数 OVER ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC]) - 或者是 函数 OVER 窗口名 … WInDOW 窗口名 AS ([PARTITION BY 字段名 ORDER BY 字段名 ASC|DESC])
OVER 关键字指定窗口的范围;
- 如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所有满足WHERE条件的记录进行计算。
- 如果OVER关键字后面的括号不为空,则可以使用如下语法设置窗口。
PARTITION BY 子句: 指定窗口函数按照哪些字段进行分组,
分组后, 窗口函数可以在每个分组中分别执行;
ORDER BY 子句: 指定窗口函数按照哪些字段进行排序, 执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号;
FRAME 子句: 为分区中的某个子集定义规则, 可以用来作为滑动窗口使用;
1.3 窗口函数🌰
准备表和数据:
- 创建表:
CREATETABLE goods(
id INTPRIMARYKEYAUTO_INCREMENT,
category_id INT,
category VARCHAR(15),
NAME VARCHAR(30),
price DECIMAL(10,2),
stock INT,
upper_time DATETIME);
- 插入数据:
INSERTINTO goods(category_id,category,NAME,price,stock,upper_time)VALUES(1,'女装/女士精品','T恤',39.90,1000,'2020-11-10 00:00:00'),(1,'女装/女士精品','连衣裙',79.90,2500,'2020-11-10 00:00:00'),(1,'女装/女士精品','卫衣',89.90,1500,'2020-11-10 00:00:00'),(1,'女装/女士精品','牛仔裤',89.90,3500,'2020-11-10 00:00:00'),(1,'女装/女士精品','百褶裙',29.90,500,'2020-11-10 00:00:00'),(1,'女装/女士精品','呢绒外套',399.90,1200,'2020-11-10 00:00:00'),(2,'户外运动','自行车',399.90,1000,'2020-11-10 00:00:00'),(2,'户外运动','山地自行车',1399.90,2500,'2020-11-10 00:00:00'),(2,'户外运动','登山杖',59.90,1500,'2020-11-10 00:00:00'),(2,'户外运动','骑行装备',399.90,3500,'2020-11-10 00:00:00'),(2,'户外运动','运动外套',799.90,500,'2020-11-10 00:00:00'),(2,'户外运动','滑板',499.90,1200,'2020-11-10 00:00:00');
下面针对goods表中的数据来验证每个窗口函数的功能。
1. 序号函数
序号函数是按照一定的分组规则
对每一组的数据排序并创建一个序号列
1.1
row_number()
- 单纯的对
数据编号每一组
函数功能row_number() 对数据中的序号进行顺序显示
[案例]
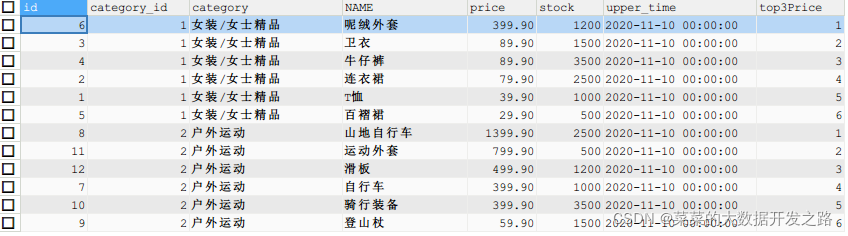
1.1 查询 goods 数据表中每个商品分类下价格降序排列的各个商品信息。
SELECT*,
ROW_NUMBER()OVER(PARTITIONBY category ORDERBY price DESC)AS row_num
FROM goods;
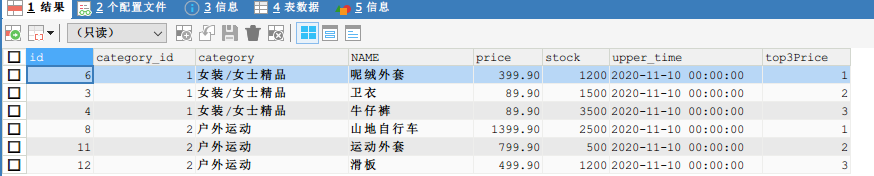
1.2 查询 goods 数据表中每个商品分类下价格最高的3种商品信息。
SELECT*FROM(SELECT*,
ROW_NUMBER()OVER(PARTITIONBY category ORDERBY price DESC)AS top3Price
FROM goods
)AS t
WHERE
top3Price <=3
在名称为“女装/女士精品”的商品类别中,有两款商品的价格为89.90元,分别是卫衣和牛仔裤。两款商品的序号都应该为2,而不是一个为2,另一个为3。此时,可以使用RANK()函数和DENSE_RANK()函数解决;
1.2
rank()
- 排序每一组的某一字段, 同等级同序号前后不连续
函数功能rank()**对序号进行并列排序, 指定字段数值相同(同一等级),则会产生相同序号记录,且产生序号间隙,**如, 1,1,3,4 而不会是 1,2,3,4(row_number的结果), 也不是 1,1,2,3,4 (dense_rank的结果)rank函数没有参数,但需要指定按照那个字段进行排名,所以使用rank函数必须用order by参数,order by的排序字段就是排名字段
1.3
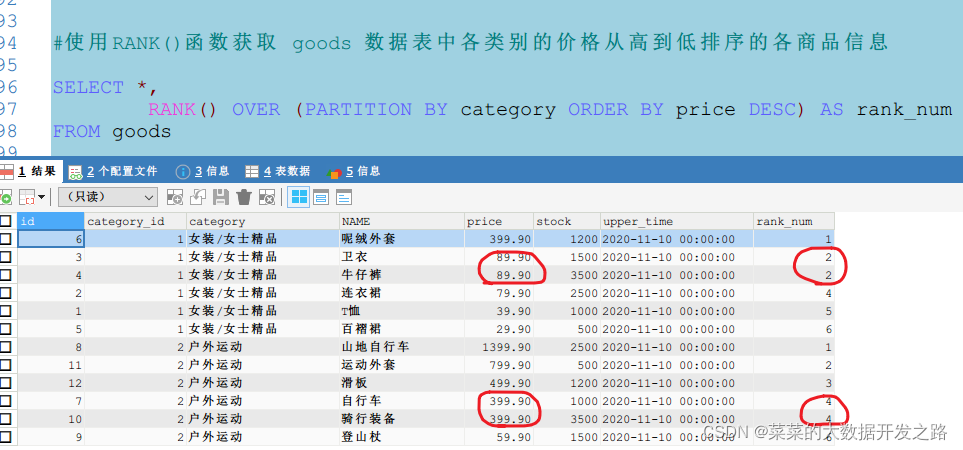
1.4 使用RANK()函数获取 goods 数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
// 常规思路SELECT*FROM goods
WHERE category ='女装/女士精品'ORDERBY price DESCLIMIT4#窗口函数rank: 并列SELECT*,
RANK()OVER(PARTITIONBY category ORDERBY price DESC)AS top4Price
FROM
goods
WHERE
category ='女装/女士精品'LIMIT4;

1.3
dense_rank()
- 排序每一组的某一字段, 同等级同序号前后也连续
函数功能dense_rank()对序号进行并列排序, 指定字段数值相同(同一等级),则会产生相同序号记录,且产生序号间隙,1.5
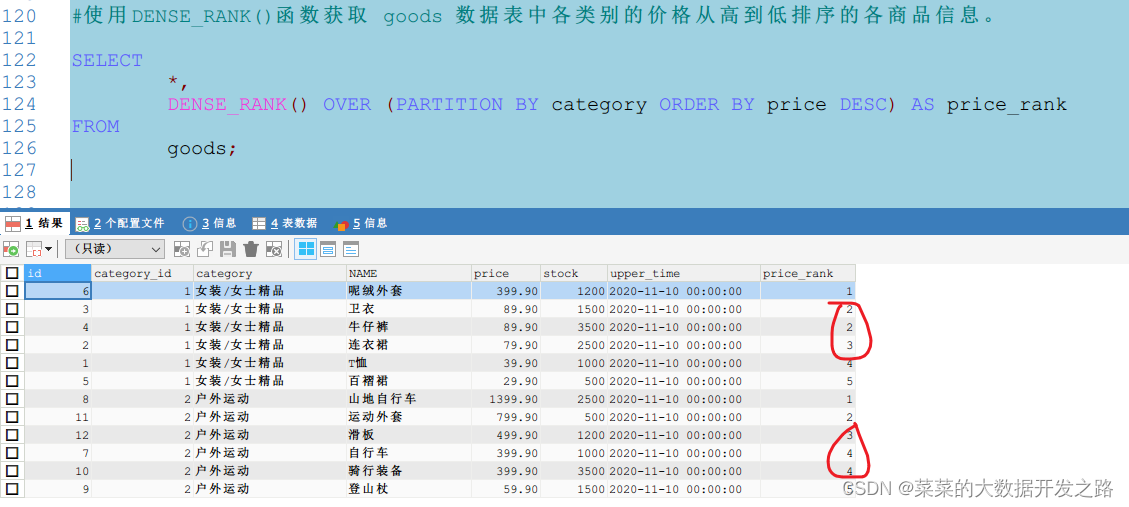
1.6
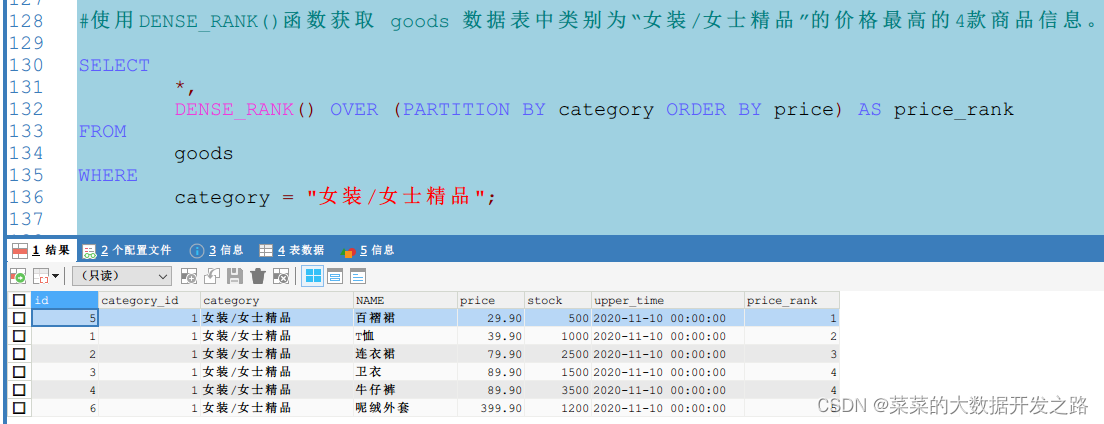
可以看到,使用DENSE_RANK()函数得出的行号为1、2、2、3,相同价格的商品序号相同,且后面的商品序号是连续的
2. 分布函数
2.1
percent_rank()
- 等级值百分比, (rank - 1)/ (rows - 1)
函数功能percent_rank()计算分区或结果集中行的百分位数排名每行按照公式
进行计算。其中,(rank-1)/ (rows-1)
为RANK()函数产生的rank
,序号
为rows当前窗口(当前组)的总行数
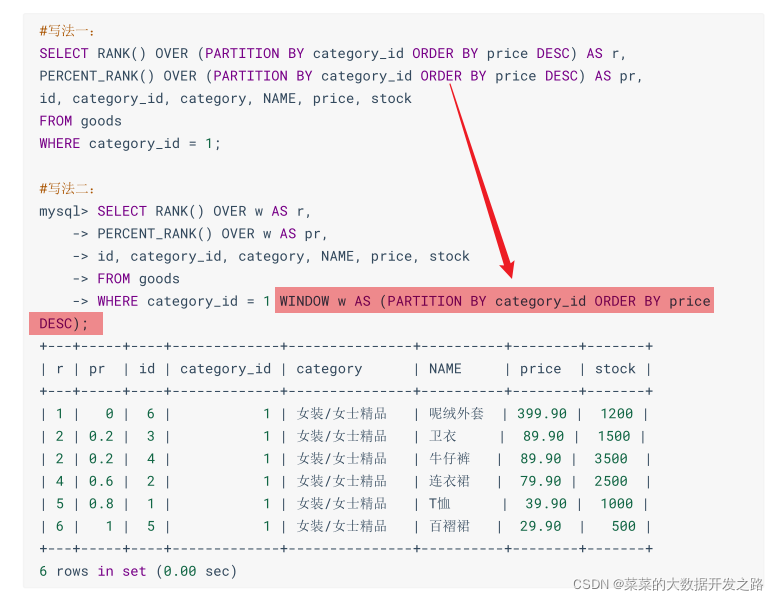
2.2
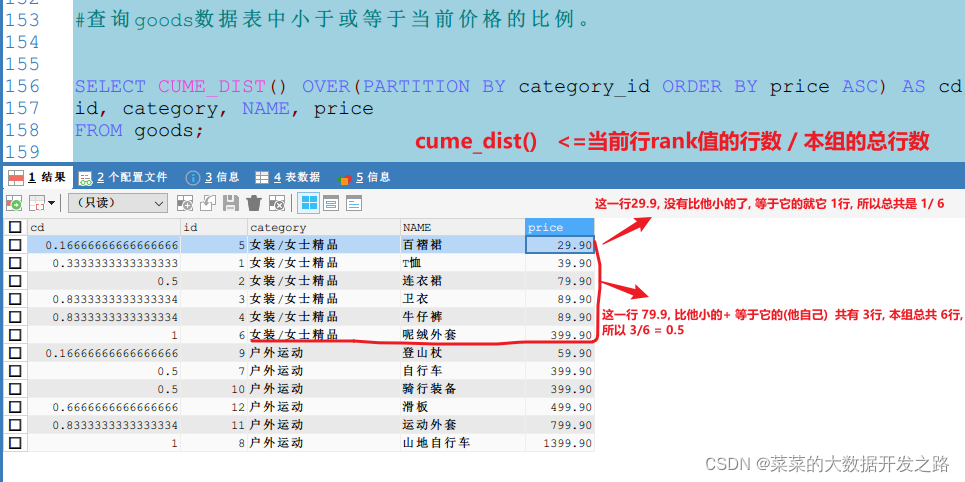
cume_dist()
- 累积分布值,
/<=当前rank值的行数分组内总行数
函数功能cume_dist()分组内
<=当前rank值的行数
/
分组内总行数
3. 前后函数
3.1
LAG(expr, n)
- 返回当前行的前n行(本组内)的expr值
函数功能LAG(expr, n)返回当前行的前n行(本组)的expr值lag允许你在每一个分组内, 从当前行向前看n行数据n(也叫offset)是从当前行偏移的行数,以获取值。offset必须是一个非负整数。如果offset为零,则LAG()函数计算当前行的值。如果省略 offset,则LAG()函数默认使用n=1, 向前看一个数据。
3.2
LEAD(expr, n)
函数功能LEAD(expr, n)返回当前行的后n行(本组)的expr值
4. 首位函数
4.1
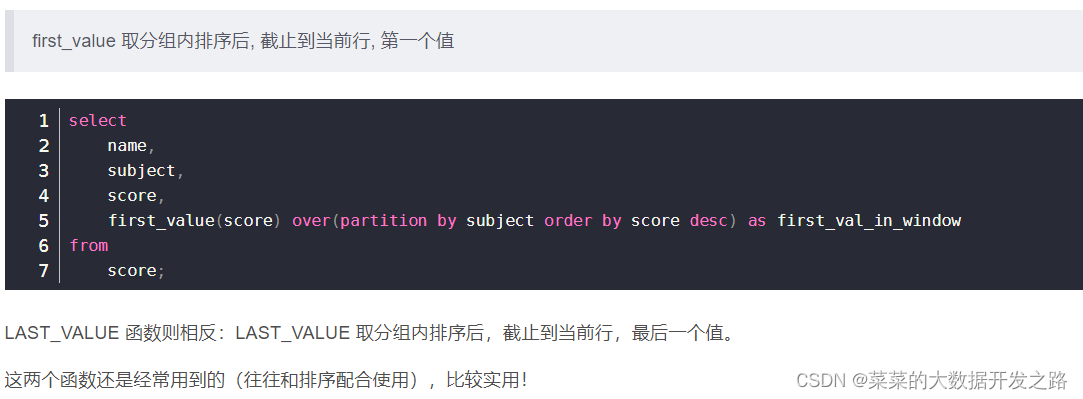
first_value(expr)
,
last_value(expr)
5. 其他函数
5.1
nth_value(expr, n)

5.2
ntile(n)

本文转载自: https://blog.csdn.net/nmsLLCSDN/article/details/123287490
版权归原作者 菜菜的大数据开发之路 所有, 如有侵权,请联系我们删除。
版权归原作者 菜菜的大数据开发之路 所有, 如有侵权,请联系我们删除。