
参数传递
对于ETL参数传递是一个很重要的环节,因为参数的传递会涉及到业务数据是如何抽取,例如需要抽取昨天的数据装载到目标表中,kettle开发中的参数可分为全局参数和局部参数,不同的参数类型采用不同参数传递方式。 全局参数一般只在临时调试中使用,以为全局参数存储在kettle用户的kettle.properties文件中,运行依赖于kettle.properties文件,一般使用在所有开发流程都需要设置同样的参数时使用,也就是公共的参数,例如数据库的账密信息。
局部参数在kettle流程的开发中使用较多,主要的传递方式分为
- 变量 variable (设置变量/获取变量)
- 命名参数 parameter
- 位置参数 argument
全局参数
定义全局变量的两种方式:
- spoon界面中的编辑->编辑kettle.properties文件进行全局变量的定义。
在spoon界面中定义全局参数可以立即使用。全局参数是定义在kettle.properties文件中的参数,如果编写完成中的ktr文件中使用到了全局参数,但更换了ktr的运行环境,则ktr脚本无法获取到参数。
- 通过直接修改当前用户的.kettle文件夹中的kettle.properties文件来定义全局变量,在kettle.properties文件中以键值对的方式定义。
通过修改配置文件的方式定义参数kettle.properties文件修改之后需要重启kettle后才能生效
全局参数定义是通过。定义方式是采用键=值对方式来定,如:start_date=20130101
我们首先可以看一下这个文件中都有哪些内容
cat .kettle/kettle.properties
因为这里我们还没有配置任何全局变量,所以这个文件是空的,但是这里给出了我们一些例子
# This file was generated by Pentaho Data Integration version 5.4-SNAPSHOT.
#
# Here are a few examples of variables to set:
#
# PRODUCTION_SERVER = hercules
# TEST_SERVER = zeus
# DEVELOPMENT_SERVER = thor
#
# Note: lines like these with a # in front of it are comments
#
全局参数—配置数据库连接
下面我们看一个全局参数的案例,就是配置数据库链接,因为数据库链接用到的参数可能很多任务都会用到
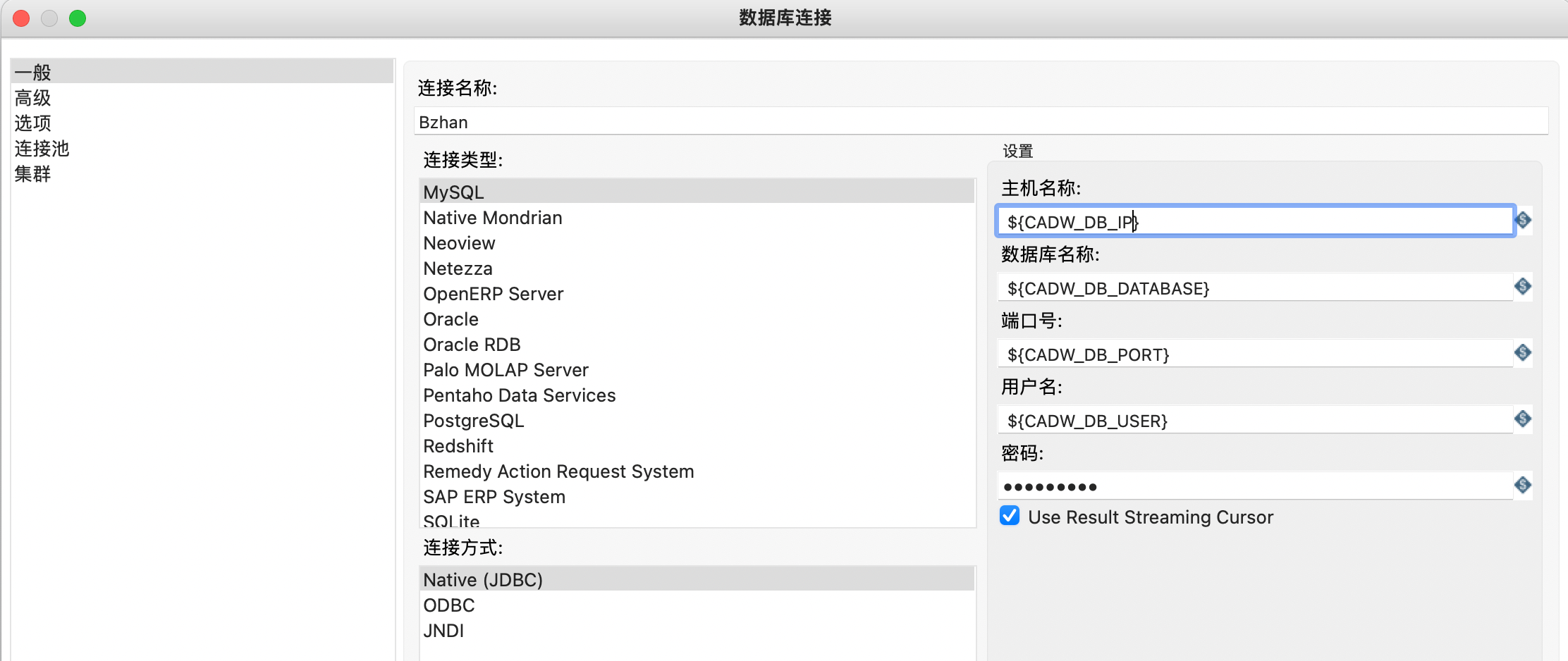
我们可以像下面这样配置,这里我们直接修改文件 ,只不过修改之后要重启服务
CADW_DB_NAME=CADW业务库
CADW_DB_IP=IP地址
CADW_DB_DATABASE=数据库名称
CADW_DB_PORT=端口
CADW_DB_USER=用户名
CADW_DB_PASSWORD=密码
重启后我们可以通过编辑入库去查看我们的配置,当然也可以在这里编辑
数据如下

这下我们就可以通过下面的方式配置数据库连接了
局部变量
局部变量也有两种设置方式
- 在ktr转换中设置变量
在转换中通过设置变量组件实现变量的设置,变量在当前转换中设置,不能在当前转换中使用,必须在下一转换中使用,在下一转换中通过获取变量组件实现上一转换中变量的获取使用。
总结:变量设置组建设置变量,变量获取组建获取变量
- 在job作业中设置变量
在job作业中也可以设置变量,在作业中通过设置变量设置完成后,在下一转换中可以使用获取变量组件获取或直接在使用时通过${变量名}使用。
总结:使用获取变量组件获取后直接使用 或者直接在需要使用时使用${变量名}
注:在SQL中使用变量时需要把“是否替换变量”勾选上,否则无法使变量生效。
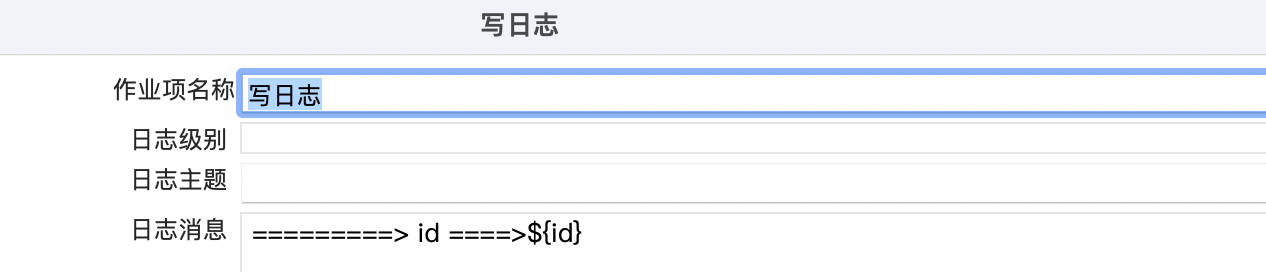
设置变量
就是我们在作业中通过引入设置变量组件进行设置,设置完成后在后面的组件中直接使用,我们的作业大致就是这样的
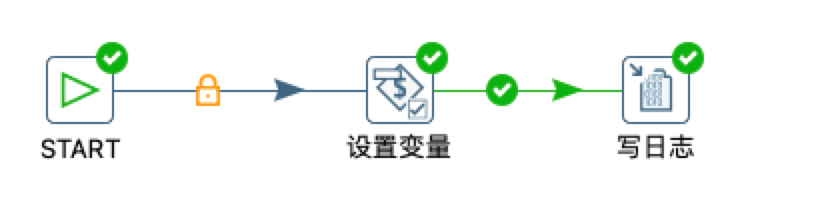
通过设置变量组件设置变量
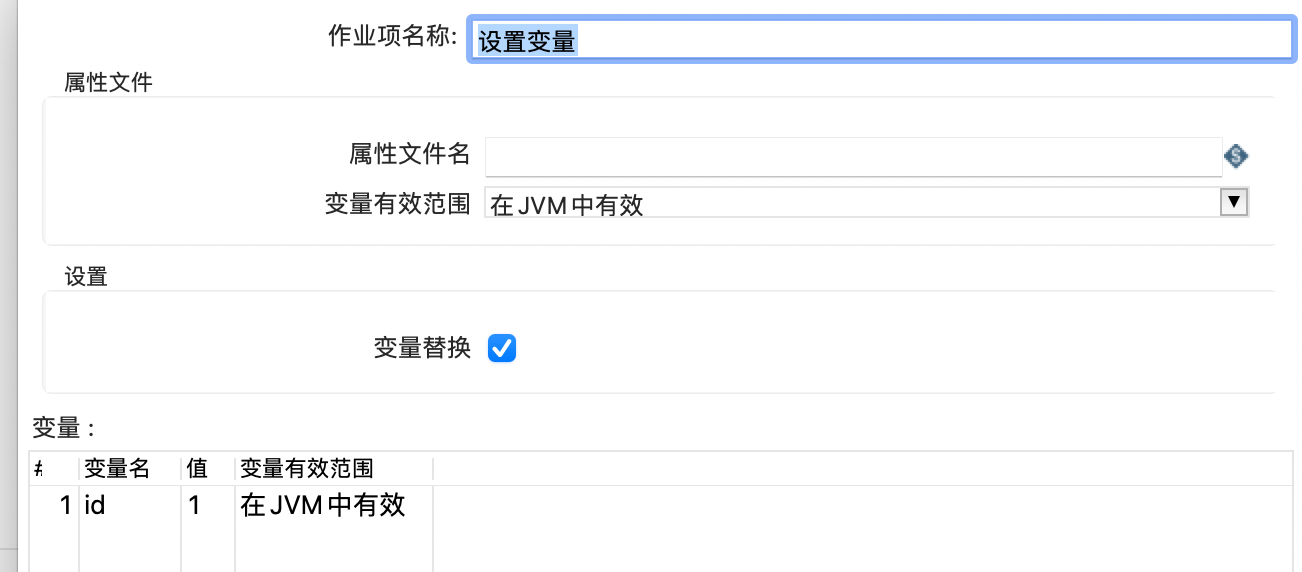
在日志组件中获取变量,并输出
下面我们就看一下能不能获取到这个变量即可,通过日志我们可以明显看到获取到了
2023/03/22 09:54:53 - Spoon - 正在开始任务...
2023/03/22 09:54:53 - 直接设置变量 - 开始执行任务
2023/03/22 09:54:53 - 直接设置变量 - 开始项[设置变量]
2023/03/22 09:54:53 - 直接设置变量 - 开始项[写日志]
2023/03/22 09:54:53 - - =========> id ====>1
2023/03/22 09:54:53 - 直接设置变量 - 完成作业项[写日志] (结果=[true])
2023/03/22 09:54:53 - 直接设置变量 - 完成作业项[设置变量] (结果=[true])
2023/03/22 09:54:53 - 直接设置变量 - 任务执行完毕
2023/03/22 09:54:53 - Spoon - 任务已经结束.
转换设置变量
虽然我们上面设置变量组件来设置,然后在需要的地方获取变量再去使用,但是这样非常不灵活,因为这个变量是写死的,我们在ETL 任务中经常遇到的一个场景是获取相关的日期
我们可以通过“获取系统信息”组件获取昨天日期,再通过字段选择转换成yyyy-mm-dd格式或者是从特定的表里面获取参数,最后设置成变量,然后获取变量完成业务逻辑。
下面我们开始定义一个转换
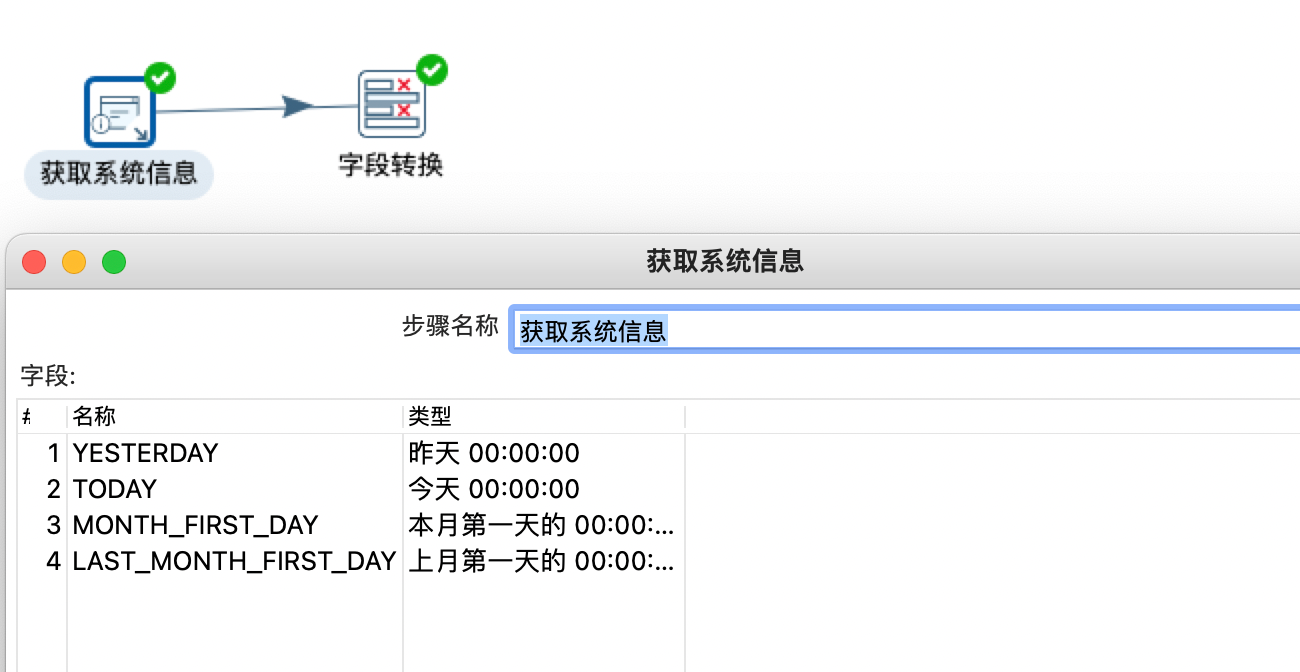
接下来我们把获取到的时间信息转换成
yyyy-mm-dd
格式的数据
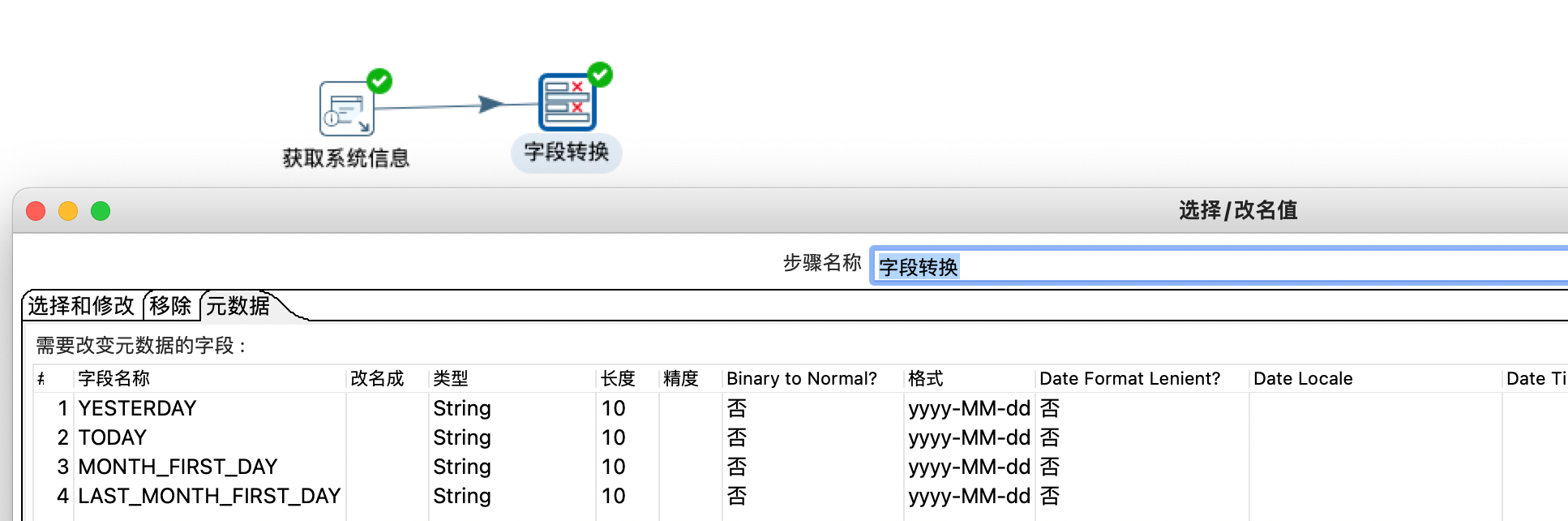
然后我们将相关的数据是这成变量即可
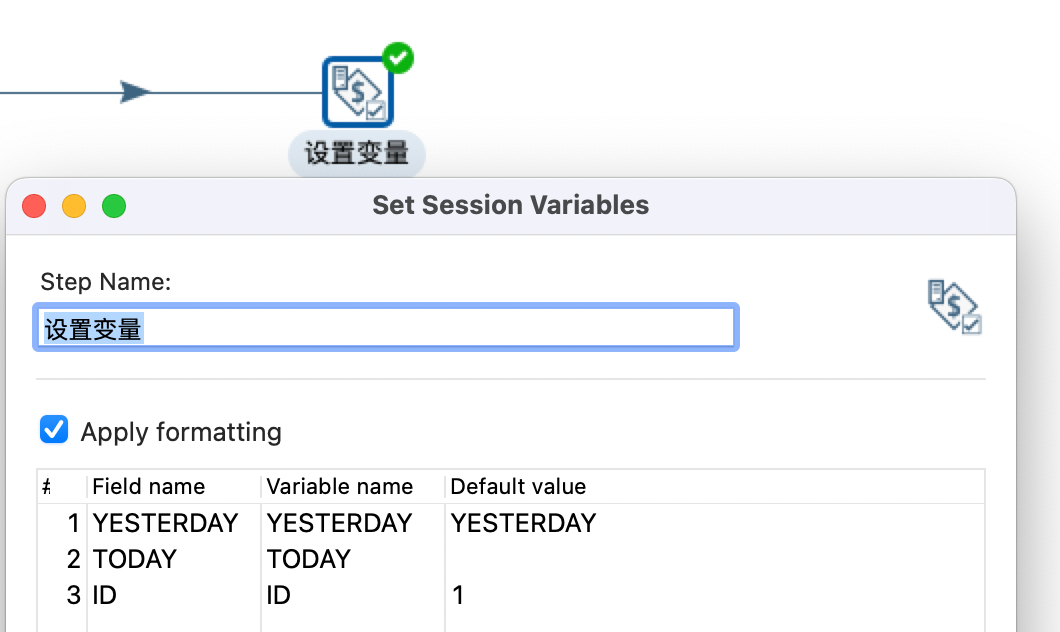
运行任务我们可以看到这些变量的值已经被设置好了
2023/03/22 16:20:03 - 设置变量.0 - Set session variable [YESTERDAY] = [2023/03/21 00:00:00.000]
2023/03/22 16:20:03 - 设置变量.0 - Set session variable [TODAY] = [2023/03/22 00:00:00.000]
2023/03/22 16:20:03 - 设置变量.0 - Unable to find field [ID] in input row. Using default value [1]
2023/03/22 16:20:03 - 设置变量.0 - Set session variable [ID] = [1]
命名参数
其实命名参数的含义非常简单,就是命了名字的参数,因为这是相对位置参数而言的,位置参数就是获取参数的时候根据位置而言的,例如Java 程序启动时候的传参—argument
命名参数的使用方式很简单,首先我们在日志组件中获取变量进行输出
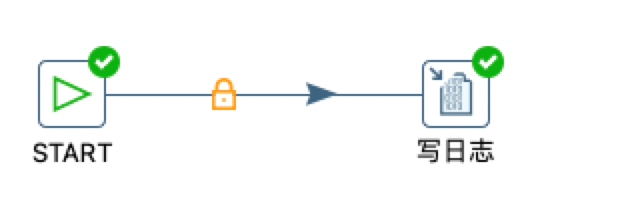
然后在作业的空白处双击,进入作业属性界面,然后我们点击命名参数进行设置,这里我们提供了一个默认值

结下来我们运行作业,可以看到已经获取这个参数值了
2023/03/22 14:04:39 - Spoon - 正在开始任务...
2023/03/22 14:04:39 - 命名参数 - 开始执行任务
2023/03/22 14:04:39 - 命名参数 - 开始项[写日志]
2023/03/22 14:04:39 - - =====startDate=====>2023-02-28==
2023/03/22 14:04:39 - 命名参数 - 完成作业项[写日志] (结果=[true])
2023/03/22 14:04:39 - 命名参数 - 任务执行完毕
2023/03/22 14:04:39 - Spoon - 任务已经结束.
其实我们在执行作业的页面上,也能看到这个信息
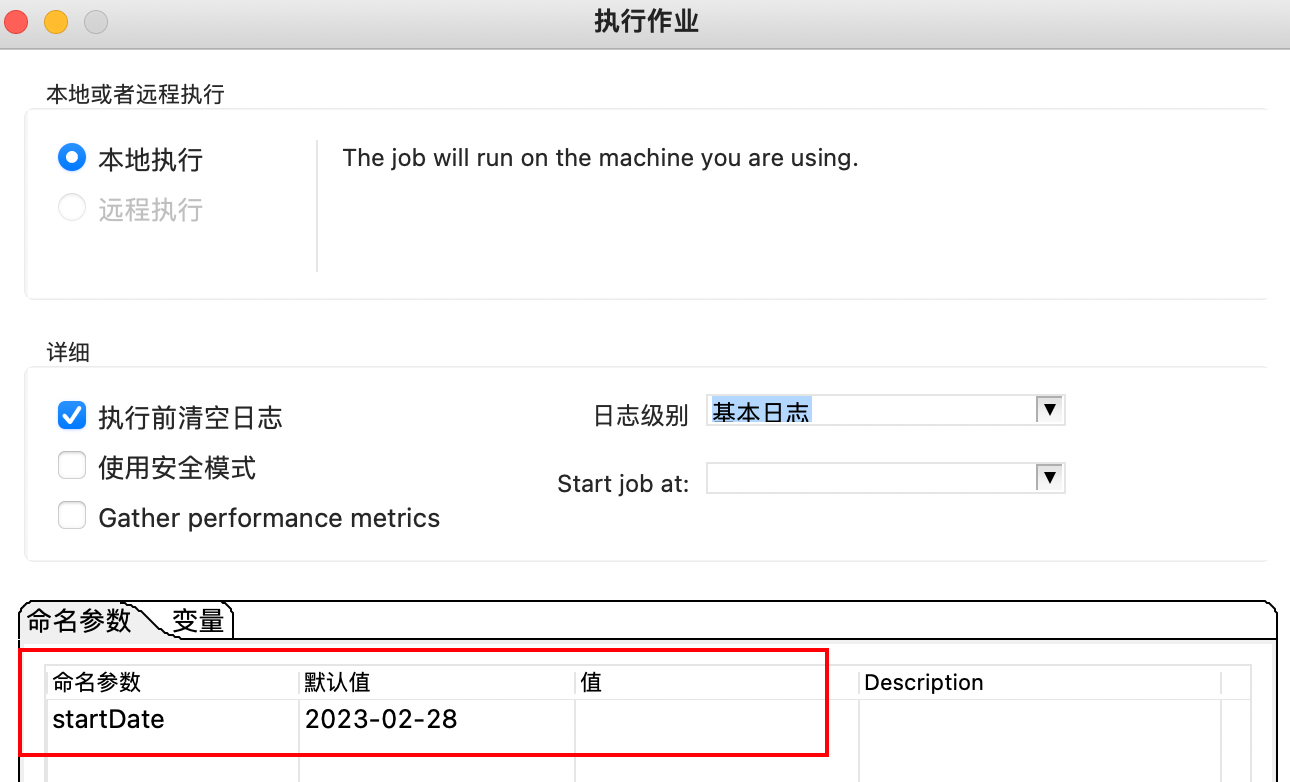
但是到这里我们还是没看到这命名参数的方便之处,因为参数值还是固定的,其实我们可以通过下面的方式将这个参数传递进去
./kitchen.sh -rep=DatabaseRepository -user=admin -pass=admin -job=命名参数 -dir=/ -param:startDate=2023-03-01
日志如下
2023/03/22 14:13:39 - 命名参数 - 开始执行任务
2023/03/22 14:13:39 - 命名参数 - 开始项[写日志]
2023/03/22 14:13:39 - - =====startDate=====>2023-03-01==
2023/03/22 14:13:39 - 命名参数 - 完成作业项[写日志] (结果=[true])
2023/03/22 14:13:39 - 命名参数 - 任务执行完毕
所以命名参数就是首先给变量起一个名字,可以在程序中使用,具体的参数值可以在程序运行的时候传递进去
位置参数
其实做过程序开发的小伙伴其实应该很清楚,我们传递程序的参数一般都是位置参数,什么意思呢?就是我们在程序里获取传递给我们的参数的时候是根据位置来的,例如Java 里面就是一个数组,那我们就知道第一个参数是什么意思,第二个参数表是什么意思。
位置参数只能在转换中获取,所以这里引入了获取信息的组件
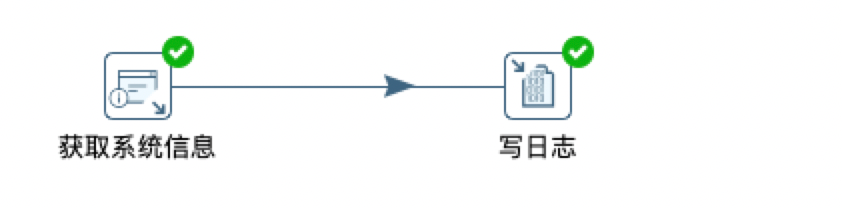
我们在这里里面就是定义了一个变量 startDate ,然后它的类型是
命令行参数1
,其实这里更加准确的描述是它的值是
命令行参数1
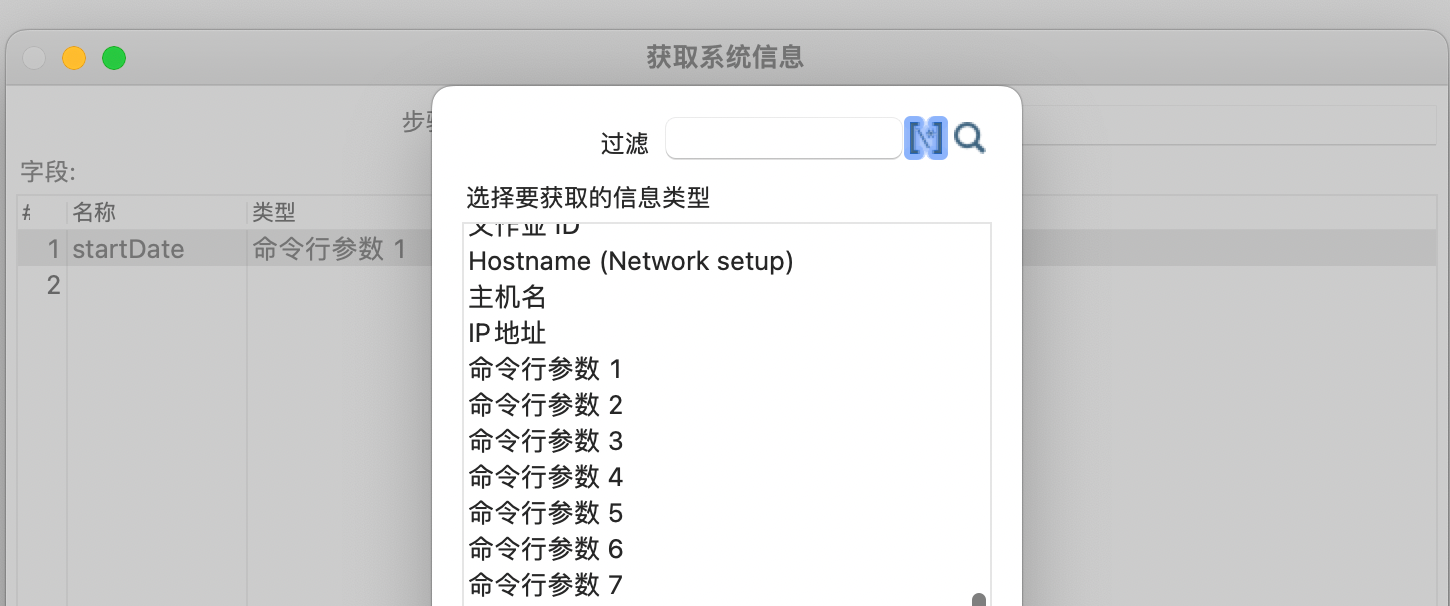
然后我们在日志组件中输出这个值,只不过我们在运行的时候,需要传入这个值
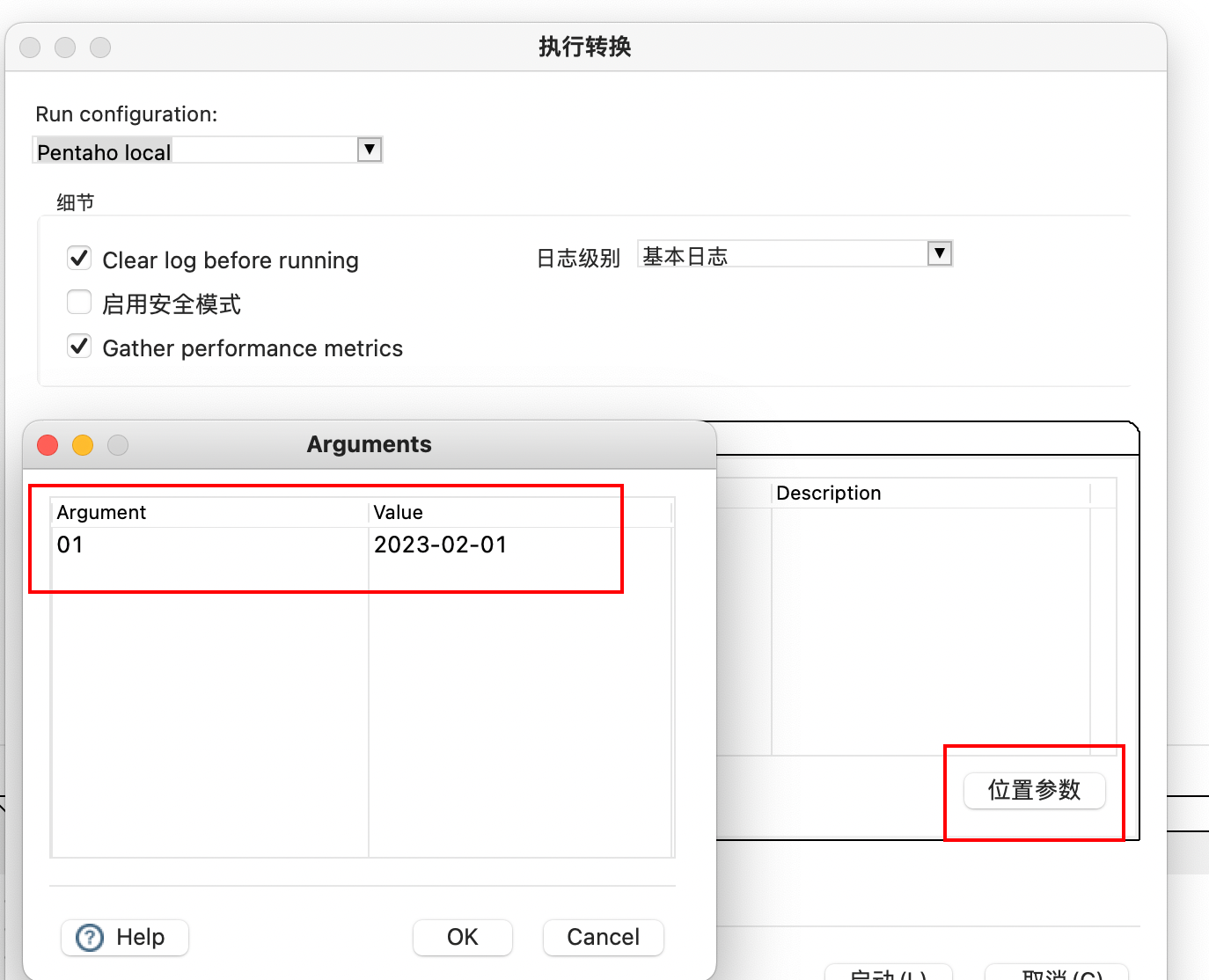
我们可以看到已经获取到这个值了
2023/03/22 14:53:09 - 获取位置参数 - 为了转换解除补丁开始 [获取位置参数]
2023/03/22 14:53:09 - 获取系统信息.0 - 完成处理 (I=0, O=0, R=1, W=1, U=0, E=0)
2023/03/22 14:53:09 - 写日志.0 -
2023/03/22 14:53:09 - 写日志.0 - ------------> 行号 1------------------------------
2023/03/22 14:53:09 - 写日志.0 - startDate = 2023-02-01
2023/03/22 14:53:09 - 写日志.0 -
2023/03/22 14:53:09 - 写日志.0 - ====================
2023/03/22 14:53:09 - 写日志.0 - 完成处理 (I=0, O=0, R=1, W=1, U=0, E=0)
2023/03/22 14:53:09 - Spoon - 转换完成!!
当然我们也可以在运行的时候去传递这个参数
./pan.sh -rep=DatabaseRepository -user=admin -pass=admin -trans=获取位置参数 -dir=/ 2023-03-21
日志如下
2023/03/22 15:03:29 - Pan - 开始运行.
2023/03/22 15:03:29 - RepositoriesMeta - Reading repositories XML file: /Users/kingcall/.kettle/repositories.xml
三月 22, 2023 3:03:31 下午 org.apache.cxf.endpoint.ServerImpl initDestination
信息: Setting the server's publish address to be /marketplace
2023/03/22 15:03:31 - 获取位置参数 - 为了转换解除补丁开始 [获取位置参数]
三月 22, 2023 3:03:31 下午 org.apache.cxf.endpoint.ServerImpl initDestination
信息: Setting the server's publish address to be /lineage
2023/03/22 15:03:31 - 获取系统信息.0 - 完成处理 (I=0, O=0, R=1, W=1, U=0, E=0)
2023/03/22 15:03:31 - 写日志.0 -
2023/03/22 15:03:31 - 写日志.0 - ------------> 行号 1------------------------------
2023/03/22 15:03:31 - 写日志.0 - startDate = 2023-03-21
2023/03/22 15:03:31 - 写日志.0 -
2023/03/22 15:03:31 - 写日志.0 - ====================
2023/03/22 15:03:31 - 写日志.0 - 完成处理 (I=0, O=0, R=1, W=1, U=0, E=0)
2023/03/22 15:03:31 - Pan - 完成!
2023/03/22 15:03:31 - Pan - 开始=2023/03/22 15:03:29.300, 停止=2023/03/22 15:03:31.404
2023/03/22 15:03:31 - Pan - 2 秒后处理结束.
2023/03/22 15:03:31 - 获取位置参数 -
2023/03/22 15:03:31 - 获取位置参数 - 进程 获取系统信息.0 成功结束, 处理了 1 行. ( 0 行/秒)
2023/03/22 15:03:31 - 获取位置参数 - 进程 写日志.0 成功结束, 处理了 1 行. ( 0 行/秒)
内置变量
变量描述Internal.Kettle.Version这是kettle的版本号,比如4.0.0Internal.Kettle.Build.Version这是kettle源代码的SVN的修订号Internal.Kettle.Build.Date这是kettle的build日期Internal.Job.Filename.Directory如果使用文件方式运行作业(.kjb),这个变量就是作业文件所在的目录。里用这个变量用户可以指定其它文件Internal.Job.Filename.Name如果使用文件方式运行作业(.kjb),这个变量就是作业文件名Internal.Job.Name当前正在执行的作业的名字Internal.Transformation.Repository.Directory如果使用资源库方式执行转换,这个变量是转换所在资源库目录的路径Internal.Step.Partition.ID如果一个步骤是以分区方式运行的,每个分区都有一个步骤拷贝。这个变量就是步骤拷贝所属的分区IDInternal.Step.Partition.Number如果一个步骤是以分区方式运行的,每个分区都有一个步骤拷贝器。这个变量就是步骤拷贝所属的分区编号,分区编号从0到分区个数减1Internal.Slave.Transformation.Number如果转换在子服务器上以集群方式运行,这个变量就是子服务器的名字Internal.Cluster.Size如果转换在子服务器上以集群方式运行,这个变量就是集群中子服务器的个数Internal.Step.Unique.Number这个变量是指定步骤的步骤拷贝的唯一编号。这个变量同样适用于分区和集群环境。取值从0到步骤拷贝个数减1Internal.Cluster.Master若转换以集群方式运行,如果是运行在主服务器上,这个值是Y,如果是运行在子服务器上,这个值是NInternal.Step.Unique.Count唯一的步骤拷贝个数。也适用于集群或分区的情况Internal.Step.Name正在执行的步骤的名字Internal.Step.CopyNr本地转换的步骤拷贝号(不考虑集群的情况)
总结
下面我们总结了一下位置参数、命名参数、变量的优缺点,然后文章中介绍了变量的使用的两种方式
通过设置变量组件设置然后获取使用
通过转换获取设置变量然后获取使用
位置参数(argument)命名参数(parameter)变量(variable)说明根据参数的位置来设置和读取参数值,用于在KJB外部传入,并在KJB内部使用根据参数的名字来设置和读取参数值,用于在KJB外部传入,并在KJB内部使用由用户自定义,在KJB内部随时随地的定义、赋值和使用关键点1、参数值只能由外部传入(arg1 arg2 arg3)2、通过位置来取值;3、只能在转换中(transform)获取到参数值;4、最多支持10个参数5、功能:太弱(不建议使用)1、参数值只能由外部传入(-param:Key=Value),Key必须固定,值可以在KJB内部重新赋值; 2、可以在作业属性中指定默认值,如果外部不传入,就取默认值; 3、可在作业、转换中任意使用; 4、不能动态新增; 5、通过${Key}使用; 6、强大程度:一般1、变量必须在KJB内部定义,在内部赋值,在内部使用(Key=Value); 2、虽然变量只能在内部定义、赋值和使用,但是因为Key和Value都可以是变量,所以可以从外部(文件、数据库等)读取变量名、变量值,实现动态的变量声明、赋值,功能非常强大; 3、可在作业、转换任意使用; 4、可以动态声明、赋值、使用; 5、通过${Key}使用; 6、最灵活强大,推荐使用如何定义?一边定义,一边赋值。见下面的“如何赋值”双击作业(或转换)的空白处,在弹出的“parameters”标签页,可以设置参数的名字1、在作业中,通过General->Set Variables控件定义;2、在转换中,通过Job->Set Variables控件定义;3、在作业中,通过“JS脚本”控件设置,如parent_job.setVariable(“VAR1”, “abc123”);如何赋值?1、在设计界面(spoon.bat)点击执行按钮时,可以在弹出的“Run Options”设置,每次运行都要重新设置; 2、在命令行界面(kitchen.bat)执行.kjb文件时,直接指定。如:sh kitchen.sh -file=/kettle/test.kjb 20150101 abc 123,这里按顺序指定了3个参数,以空格隔开; 3、父作业里面执行一个子作业时,可以在“Job”控件的Arguments标签里指定,可以使用变量1、在设计界面(spoon.bat)点击执行按钮时,可以在弹出的“Run Options”设置,每次运行都要重新设置; 2、在命令行kitchen.bat执行.kjb文件时,直接指定。如:sh kitchen.sh -file=/kettle/test.kjb -param:P1=20150101 -param:P2=abc -param:P3=123,这里指定了三个命名参数P1、P2、P3的参数值,顺序不限 3、父作业里面执行一个子作业时,可以在“Job”控件的Parameters标签里指定,可以使用变量,可以使用数据流批量赋值并循环1、在作业中,通过General->Set Variables控件赋值; 2、在转换中,通过Job->Set Variables控件赋值,前面必须带有一个Input控件(强大的关键点在这里,Input控件有多少,我们就可以有多少种方法去动态设置变量),且Input控件生成的记录数必须是1条(也可以是0,此时变量未能赋值); 3、在作业中,通过“JS脚本”控件设置,如parent_job.setVariable(“VAR1”, “abc123”); 4、父作业里面执行一个子作业时,子作业可以自由使用父作业定义的变量,包括重新赋值,不用刻意传递如何读取?新建一个转换,选择“Input”下的“get System Info”控件,type选择“command line argument1、2、3…”,即可读取对应位置的参数值。1、在所有控件中,末尾带有菱形号的输入框都可以使用,通过 号的输入框都可以使用,通过 号的输入框都可以使用,通过{KEY_NAME}使用。可以嵌套使用,比如 P 1 的内容是 A B C {P1}的内容是ABC P1的内容是ABC{P2}123,那么${P2}的值也会被替代成真实值 2、通过作业里面的JavaScript脚本控件读取,如:parent_job.getVariable(“VAR1”);1、在所有控件中,末尾带有菱形 号的输入框都可以使用,通过 号的输入框都可以使用,通过 号的输入框都可以使用,通过{KEY_NAME}使用。可以嵌套使用,比如 P 1 的内容是 A B C {P1}的内容是ABC P1的内容是ABC{P2}123,那么${P2}的值也会被替代成真实值; 2、通过作业里面的JavaScript脚本控件读取,如:parent_job.getVariable(“VAR1”);
版权归原作者 不二人生 所有, 如有侵权,请联系我们删除。