
1、HDFS概述
Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪一种,需要看我们具体的实现类,在我们实际工作中,用到的最多的就是 HDFS(分布式文件系统)以及 LocalFileSystem(本地文件系统)了。
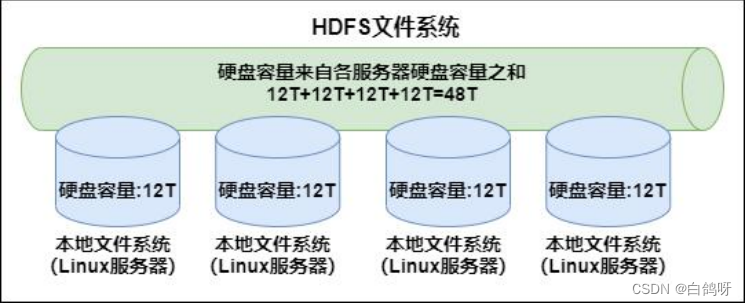
在现代的企业环境中,单机容量往往无法存储大量数据,需要跨机器存储。统一管理分布在集群上的文件系统称为分布式文件系统。
HDFS(Hadoop Distributed File System)是 Hadoop 项目的一个子项目。是Hadoop 的核心组件之一, Hadoop 非常适于存储大型数据 (比如 TB 和 PB),其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件,并且提供统一的访问接口,像是访问一个普通文件系统一样使用分布式文件系统。
2、HDFS架构
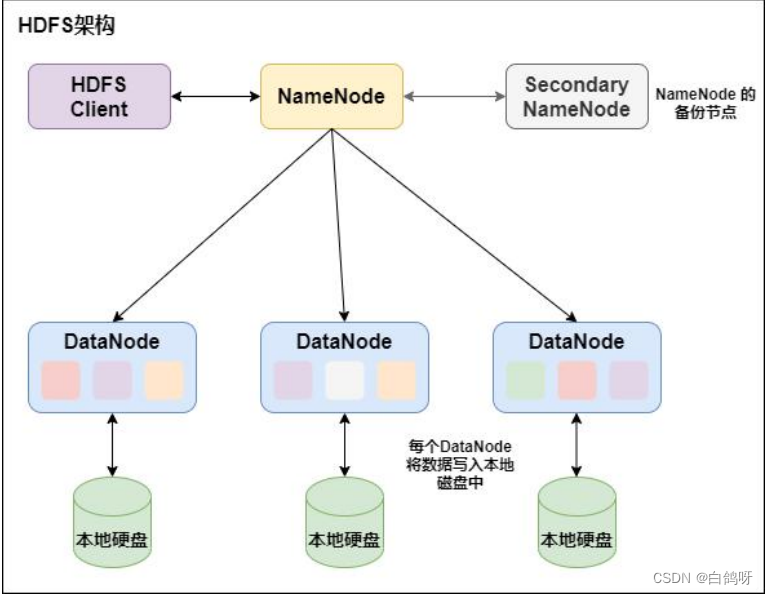 HDFS 是一个主/从(Mater/Slave)体系结构,由三部分组成: NameNode 和DataNode 以及 SecondaryNamenode:
HDFS 是一个主/从(Mater/Slave)体系结构,由三部分组成: NameNode 和DataNode 以及 SecondaryNamenode:
- NameNode 负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
- DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个DataNode 上存储多个副本,默认为 3 个。
- Secondary NameNode 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。最主要作用是辅助 NameNode 管理元数据信息
3、HDFS特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间目录树来定位文件;
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
1、master/slave 架构(主从架构)
HDFS 采用 master/slave 架构。一般一个 HDFS 集群是有一个 Namenode 和一定数目的 Datanode 组成。Namenode 是 HDFS 集群主节点,Datanode 是 HDFS 集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
2、分块存储
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规
定,默认大小在 hadoop2.x 版本中是 128M。
3、名字空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文
件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:
用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都
将被 Namenode 记录下来。
HDFS 会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:
hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
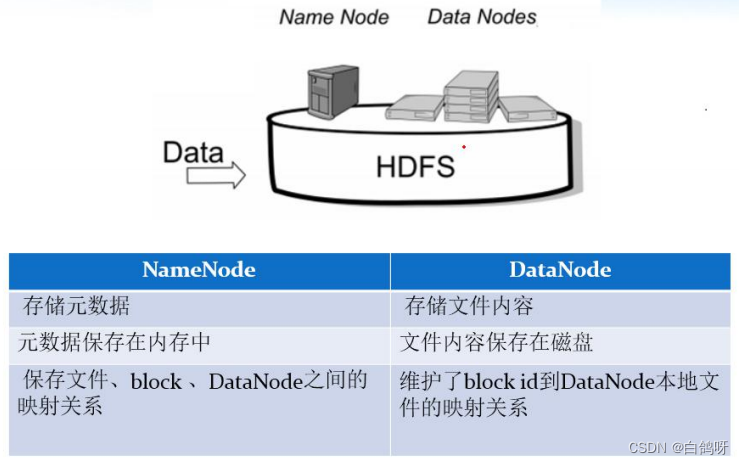
4、NameNode 元数据管理
我们把目录结构及文件分块位置信息叫做元数据。NameNode 负责维护整个 HDFS 文
件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的 id,及
所在的 DataNode 服务器)。
5、DataNode 数据存储
文件的各个 block 的具体存储管理由 DataNode 节点承担。每一个 block 都可以
在多个 DataNode 上。DataNode 需要定时向 NameNode 汇报自己持有的 block 信
息。 存储多个副本(副本数量也可以通过参数设置 dfs.replication,默认是 3)
6、副本机制
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都
是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的
时候指定,也可以在之后改变。
7、一次写入,多次读出
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改。 正因为如
此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因
为修改不方便,延迟大,网络开销大,成本太高。
4、HDFS命令行
如果没有配置 hadoop 的环境变量,则在 hadoop 的安装目录下的 bin 目录中执行
以下命令,如已配置 hadoop 环境变量,则可在任意目录下执行
help
格式: hdfs dfs -help 操作命令
作用: 查看某一个操作命令的参数信息
ls
格式:hdfs dfs -ls URI
作用:类似于 Linux 的 ls 命令,显示文件列表
lsr
格式 : hdfs dfs -lsr URI
作用 : 在整个目录下递归执行 ls, 与 UNIX 中的 ls-R 类似
mkdir
格式 : hdfs dfs -mkdir[-p]<paths>
作用 : 以<paths>中的 URI 作为参数,创建目录。使用-p 参数可以递归创建目录
put
格式 : hdfs dfs -put<localsrc >... <dst>
作用 : 将单个的源文件 src 或者多个源文件 srcs 从本地文件系统拷贝到目标文件系统中(<dst>对应的路径)。也可以从标准输入中读取输入,写入目标文件系统中
hdfs dfs -put /rooot/bigdata.txt /dir1
moveFromLocal
格式: hdfs dfs -moveFromLocal<localsrc><dst>
作用: 和 put 命令类似,但是源文件 localsrc 拷贝之后自身被删除
hdfs dfs -moveFromLocal /root/bigdata.txt /
copyFromLocal
格式: hdfs dfs -copyFromLocal<localsrc>... <dst>
作用: 从本地文件系统中拷贝文件到 hdfs 路径去
appendToFile
格式: hdfs dfs -appendToFile<localsrc>... <dst>
作用: 追加一个或者多个文件到 hdfs 指定文件中.也可以从命令行读取输入.
hdfs dfs -appendToFile a.xml b.xml /big.xml
moveToLocal
在 hadoop 2.6.4 版本测试还未未实现此方法
格式:hadoop dfs -moveToLocal[-crc]<src><dst>
作用:将本地文件剪切到 HDFS
get
格式 hdfs dfs -get[-ignorecrc ][-crc]<src><localdst>
作用:将文件拷贝到本地文件系统。 CRC 校验失败的文件通过-ignorecrc 选项拷贝。 文件和 CRC 校验可以通过-CRC 选项拷贝
hdfs dfs -get /bigdata.txt /export/servers
getmerge
格式: hdfs dfs -getmerge<src><localdst>
作用: 合并下载多个文件,比如 hdfs 的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
copyToLocal
格式: hdfs dfs -copyToLocal<src>... <localdst>
作用: 从 hdfs 拷贝到本地
mv
格式 : hdfs dfs -mv URI <dest>
作用: 将 hdfs 上的文件从原路径移动到目标路径(移动之后文件删除),该命令不能跨文件系统
hdfs dfs -mv /dir1/bigdata.txt /dir2
rm
格式: hdfs dfs -rm[-r] 【-skipTrash】 URI 【URI 。。。】
作用: 删除参数指定的文件,参数可以有多个。 此命令只删除文件和非空目录。
如果指定-skipTrash 选项,那么在回收站可用的情况下,该选项将跳过回收站而直接删除文件;
否则,在回收站可用时,在 HDFS Shell 中执行此命令,会将文件暂时放到回收站中。
hdfs dfs -rm-r /dir1
cp
格式: hdfs dfs -cp URI [URI ...]<dest>
作用: 将文件拷贝到目标路径中。如果<dest> 为目录的话,可以将多个文件拷贝到该目录下。
-f
选项将覆盖目标,如果它已经存在。
-p
选项将保留文件属性(时间戳、所有权、许可、ACL、XAttr)。
hdfs dfs -cp /dir1/a.txt /dir2/bigdata.txt
cat
hdfs dfs -cat URI [uri ...]
作用:将参数所指示的文件内容输出到 stdout
hdfs dfs -cat /bigdata.txt
tail
格式: hdfs dfs -tail path
作用: 显示一个文件的末尾
text
格式:hdfs dfs -text path
作用: 以字符形式打印一个文件的内容
chmod
格式:hdfs dfs -chmod[-R] URI[URI ...]
作用:改变文件权限。如果使用 -R 选项,则对整个目录有效递归执行。使用这一命令的用户必须是文
件的所属用户,或者超级用户。
hdfs dfs -chmod-R777 /bigdata.txt
chown
格式: hdfs dfs -chmod[-R] URI[URI ...]
作用: 改变文件的所属用户和用户组。如果使用 -R 选项,则对整个目录有效递归执行。使用这一命
令的用户必须是文件的所属用户,或者超级用户。
hdfs dfs -chown-R hadoop:hadoop /bigdata.txt
df
格式: hdfs dfs -df-h path
作用: 统计文件系统的可用空间信息
du
格式: hdfs dfs -du-s-h path
作用: 统计文件夹的大小信息
count
格式: hdfs dfs -count path
作用: 统计一个指定目录下的文件节点数量
setrep
格式: hdfs dfs -setrep num filePath
作用: 设置 hdfs 中文件的副本数量
注意: 即使设置的超过了 datanode 的数量,副本的数量也最多只能和 datanode 的数量是一致的
expunge (慎用)
格式: hdfs dfs -expunge
作用: 清空 hdfs 垃圾桶
5、HDFS高级使用命令
1、HDFS 文件限额配置
在多人共用 HDFS 的环境下,配置设置非常重要。特别是在 Hadoop 处理大量资
料的环境,如果没有配额管理,很容易把所有的空间用完造成别人无法存取。
HDFS的配额设定是针对目录而不是针对账号,可以让每个账号仅操作某一个目录,然后对目录设置配置。
HDFS 文件的限额配置允许我们以文件个数,或者文件大小来限制我们在某个目
录下上传的文件数量或者文件内容总量,以便达到我们类似百度网盘网盘等限制
每个用户允许上传的最大的文件的量
hdfs dfs -count-q-h /user/root/dir1 #查看配额信息

数量配额
hdfs dfs -mkdir-p /user/root/dir #创建 hdfs 文件夹
hdfs dfsadmin -setQuota2dir# 给该文件夹下面设置最多上传两个文件,发现只能上传一个文件
hdfs dfsadmin -clrQuota /user/root/dir # 清除文件数量限制
空间大小限额
在设置空间配额时,设置的空间至少是 block_size * 3 大小
hdfs dfsadmin -setSpaceQuota 4k /user/root/dir # 限制空间大小 4KB
hdfs dfs -put /root/a.txt /user/root/dir
生成任意大小文件的命令:
ddif=/dev/zero of=1.txt bs=1M count=2#生成 2M 的文件
清除空间配额限制
hdfs dfsadmin -clrSpaceQuota /user/root/dir
2、HDFS 的安全模式
安全模式是 hadoop 的一种保护机制,用于保证集群中的数据块的安全性。当集群
启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整
性。
假设我们设置的副本数(即参数 dfs.replication)是 3,那么在 datanode 上就
应该有 3 个副本存在,假设只存在 2 个副本,那么比例就是 2/3=0.666。hdfs
默认的副本率 0.999。我们的副本率 0.666 明显小于 0.999,因此系统会自动的
复制副本到其他 dataNode,使得副本率不小于 0.999。如果系统中有 5 个副本,
超过我们设定的 3 个副本,那么系统也会删除多于的 2 个副本。
在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。
在,当整个系统达到安全标准时,HDFS 自动离开安全模式。30s
安全模式操作命令
hdfs dfsadmin -safemode get #查看安全模式状态
hdfs dfsadmin -safemode enter #进入安全模式
hdfs dfsadmin -safemode leave #离开安全模式
6、HDFS 的 block 块和副本机制
HDFS 将所有的文件全部抽象成为 block 块来进行存储,不管文件大小,全部一
视同仁都是以 block 块的统一大小和形式进行存储,方便我们的分布式文件系
统对文件的管理。
所有的文件都是以 block 块的方式存放在 hdfs 文件系统当中,在 Hadoop 1版本当中,文件的 block 块默认大小是 64M,Hadoop 2 版本当中,文件的 block块大小默认是 128M,block 块的大小可以通过 hdfs-site.xml 当中的配置文件进行指定。
<property><name>dfs.block.size</name><value>块大小 以字节为单位</value> //只写数值就可以
</property>
1、抽象为 block 块的好处
1、 一个文件有可能大于集群中任意一个磁盘 10T*3/128 = xxx 块 2T,2T,2T
文件方式存—–>多个 block 块,这些 block 块属于一个文件
2、 使用块抽象而不是文件可以简化存储子系统
3、块非常适合用于数据备份进而提供数据容错能力和可用性
2、块缓存
通常 DataNode 从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在 DataNode 的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个 DataNode 的内存中,当然可以针对每个文件配置 DataNode 的数量。作业调度器通过在缓存块的 DataNode 上运行任务,可以利用块缓存的优势提高读操作的性能。
例如: 连接(join)操作中使用的一个小的查询表就是块缓存的一个很好的候选。 用户或应用通过在缓存池中增加一个 cache directive 来告诉 namenode需要缓存哪些文件及存多久。缓存池(cache pool)是一个拥有管理缓存权限和资源使用的管理性分组。
例如: 一个文件 130M,会被切分成 2 个 block 块,保存在两个 block 块里面,实际占
用磁盘 130M 空间,而不是占用 256M 的磁盘空间
3、hdfs 的文件权限验证
hdfs 的文件权限机制与 linux 系统的文件权限机制类似
r:read w:write x:execute
权限 x 对于文件表示忽略,对于文件夹表示是否有权限访问其内容
如果 linux 系统用户 zhangsan 使用 hadoop 命令创建一个文件,那么这个文件在
HDFS 当中的 owner 就是 zhangsan
HDFS 文件权限的目的,防止好人做错事,而不是阻止坏人做坏事。HDFS 相信你
告诉我你是谁,你就是谁
4、hdfs 的副本因子
为了保证 block 块的安全性,也就是数据的安全性,在 hadoop2 当中,文件默认保存三个副本,我们可以更改副本数以提高数据的安全性
在 hdfs-site.xml 当中修改以下配置属性,即可更改文件的副本数
<property><name>dfs.replication</name><value>3</value></property>
7、HDFS 文件写入过程(非常重要)
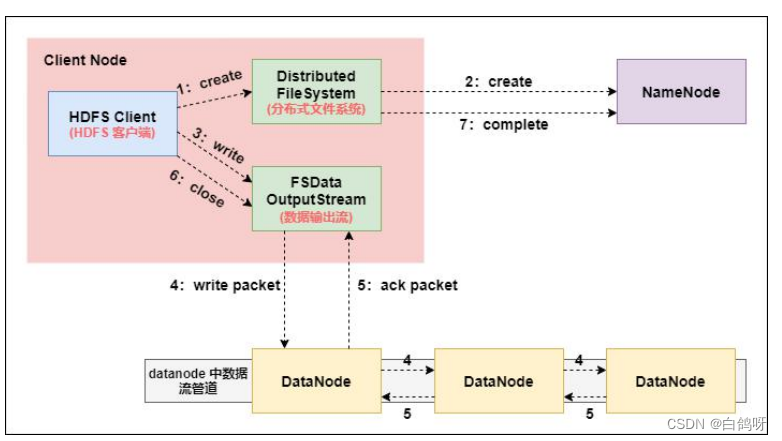 1、Client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯, NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
1、Client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯, NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、Client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3、NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配, 返回可用的 DataNode 的地址如:A, B, C;Hadoop 在设计时考虑到数据的安全与高效, 数据文件默认在 HDFS 上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。
4、Client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC调用,建立 pipeline ),A 收到请求会继续调用 B,然后 B 调用 C,将整个 pipeline 建立完成, 后逐级返回 client;
5、 Client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,B 传给 C。A 每传一个 packet 会放入一个应答队列等待应答;
6、数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在pipeline 反方向上, 逐个发送 ack(命令正确应答),最终由 pipeline中第一个 DataNode 节点 A 将 pipelineack 发送给 Client;
7、当一个 block 传输完成之后,Client 再次请求 NameNode 上传第二个block,重复步骤 2
1、网络拓扑概念
在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述。
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点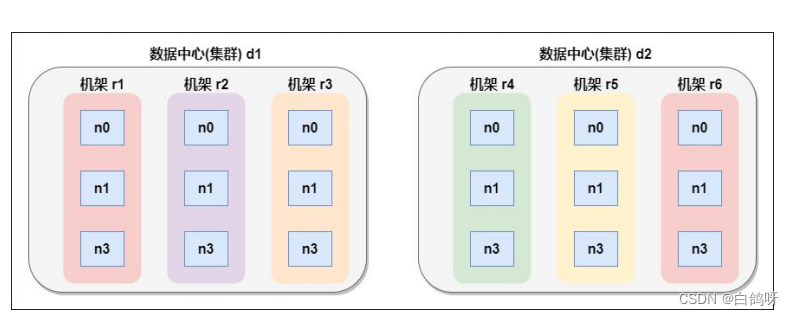
2、机架感知(副本节点选择)
第一个副本在 client 所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点
8、HDFS 文件读取过程(非常重要)

1、Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
2、NameNode会视情况返回文件的部分或者全部block列表,对于每block,NameNode 都会返回含有该 block 副本的 DataNode 地址; 这些返回的DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
3、Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
4、底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
5、当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
6、读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
7、read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回 Client 请求包含块的 DataNode 地址,并不是返回请求块的数据;
8、最终读取来所有的 block 会合并成一个完整的最终文件。
从 HDFS 文件读写过程中,可以看出,HDFS 文件写入时是串行写入的,数据包先发送给节点 A,然后节点 A 发送给 B,B 在给 C;而 HDFS 文件读取是并行的, 客户端Client 直接并行读取 block 所在的节点
9、NameNode 工作机制以及元数据管理(重要)
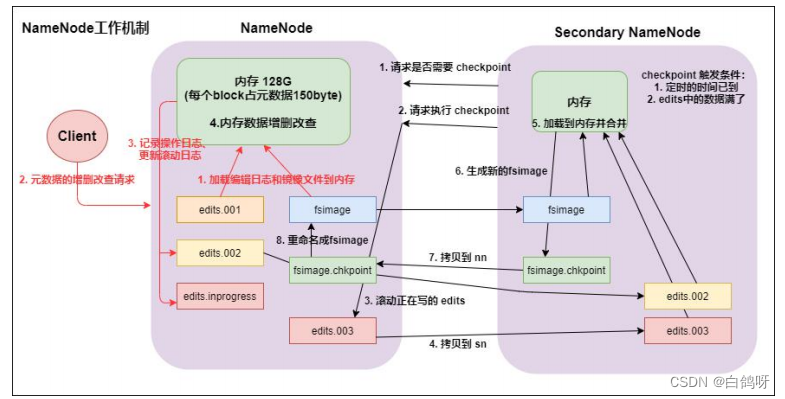
1、namenode 与 datanode 启动
namenode 工作机制
- 第一次启动 namenode 格式化后,创建 fsimage 和 edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- 客户端对元数据进行增删改的请求。
- namenode 记录操作日志,更新滚动日志。
- namenode 在内存中对数据进行增删改查。
secondary namenode
5. secondary namenode 询问 namenode 是否需要 checkpoint。直接带回 namenode
是否检查结果。
6. secondary namenode 请求执行 checkpoint。
7. namenode 滚动正在写的 edits 日志。
8. 将滚动前的编辑日志和镜像文件拷贝到 secondary namenode。
9. secondary namenode 加载编辑日志和镜像文件到内存,并合并。
10. 生成新的镜像文件 fsimage.chkpoint。
11. 拷贝 fsimage.chkpoint 到 namenode。
12. namenode 将 fsimage.chkpoint 重新命名成 fsimage。
2、 FSImage 与 edits 详解
所有的元数据信息都保存在了 FsImage 与 Eidts 文件当中,这两个文件就记录了所有的数据的元数据信息,元数据信息的保存目录配置在了 hdfs-site.xml 当中
<!--fsimage 文件存储的路径--><property><name>dfs.namenode.name.dir</name><value>file:///opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas
</value></property><!-- edits 文件存储的路径 --><property><name>dfs.namenode.edits.dir</name><value>file:///opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits<
/value></property>
edits(内存镜像):客户端对 hdfs 进行写文件时会首先被记录在 edits 文件中。
edits 修改时元数据也会更新。每次 hdfs 更新时 edits 先更新后客户端才会看到最新信息。
fsimage(完整镜像):是 namenode 中关于元数据的镜像,一般称为检查点。
一般开始时对 namenode 的操作都放在 edits 中,为什么不放在 fsimage 中呢?
因为 fsimage 是 namenode 的完整的镜像,内容很大,如果每次都加载到内存的话生成树状拓扑结构,这是非常耗内存和 CPU。
fsimage 内容包含了 namenode 管理下的所有 datanode 中文件及文件 block 及block 所在的 datanode 的元数据信息。随着 edits 内容增大,就需要在一定时间点和 fsimage 合并。
3、FSimage 文件当中的文件信息查看
使用命令 hdfs oiv
cd /opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_0000000000000000112 -p XML -o hello.xml
4、edits 当中的文件信息查看
查看命令 hdfs oev
cd /opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
hdfs oev -i edits_0000000000000000112-0000000000000000113 -o myedit.xml -p XML
5、secondarynameNode 如何辅助管理 FSImage 与 Edits 文件
- secnonaryNN 通知 NameNode 切换 editlog。
- secondaryNN 从 NameNode 中获得 FSImage 和 editlog(通过 http 方式)。
- secondaryNN 将 FSImage 载入内存,然后开始合并 editlog,合并之后成为新的 fsimage。
- secondaryNN 将新的 fsimage 发回给 NameNode。
- NameNode 用新的 fsimage 替换旧的 fsimage。
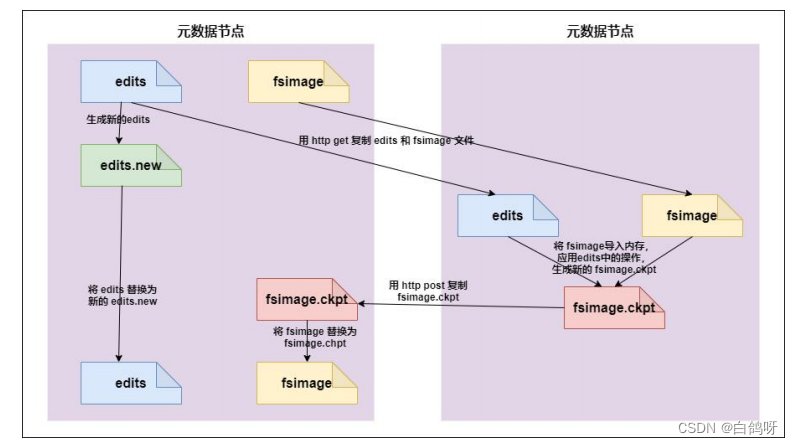 1、完成合并的是 secondarynamenode,会请求 namenode 停止使用 edits,暂时将新写操作放入一个新的文件中(edits.new)。
1、完成合并的是 secondarynamenode,会请求 namenode 停止使用 edits,暂时将新写操作放入一个新的文件中(edits.new)。
2、secondarynamenode 从 namenode 中通过 http get 获得 edits,因为要和 fsimage合并,所以也是通过 http get 的方式把 fsimage 加载到内存,然后逐一执行具体对文件系统的操作,与 fsimage 合并,生成新的 fsimage,然后把 fsimage 发送给 namenode,通过 http post 的方式。namenode 从 secondarynamenode 获得了 fsimage 后会把原有的 fsimage 替换为新的 fsimage,把 edits.new 变成 edits。同时会更新 fsimage。
3、hadoop 进入安全模式时需要管理员使用 dfsadmin 的 save namespace 来创建新的检查点。
4、secondarynamenode 在合并 edits 和 fsimage 时需要消耗的内存和 namenode 差不多,所以一般把 namenode 和 secondarynamenode 放在不同的机器上。
5、fsimage 与 edits 的合并时机取决于两个参数,第一个参数是默认 1 小时 fsimage
与 edits 合并一次。
第一个参数:时间达到一个小时 fsimage 与 edits 就会进行合并
dfs.namenode.checkpoint.period 3600
第二个参数:hdfs 操作达到 1000000 次也会进行合并
dfs.namenode.checkpoint.txns 1000000
第三个参数:每隔多长时间检查一次 hdfs 的操作次数
dfs.namenode.checkpoint.check.period 60
6、namenode 元数据信息多目录配置
为了保证元数据的安全性,我们一般都是先确定好我们的磁盘挂载目录,将元数
据的磁盘做 RAID1
namenode 的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠
性
hdfs-site.xml
<property><name>dfs.namenode.name.dir</name><value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeD
atas</value></property>
7、namenode 故障恢复
在我们的 secondaryNamenode 对 namenode 当中的 fsimage 和 edits 进行合并的时候,每次都会先将 namenode 的 fsimage 与 edits 文件拷贝一份过来,所以fsimage 与 edits 文件在 secondarNamendoe 当中也会保存有一份,如果 namenode的 fsimage 与 edits 文件损坏,那么我们可以将 secondaryNamenode 当中的fsimage 与 edits 拷贝过去给 namenode 继续使用,只不过有可能会丢失一部分数据。
这里涉及到几个配置选项
namenode 保存 fsimage 的配置路径
<!-- namenode 元数据存储路径,实际工作当中一般使用 SSD 固态硬盘,并使用多个固态硬盘隔开,冗
余元数据 --><property><name>dfs.namenode.name.dir</name><value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopData/namenodeDatas</value></property>
namenode 保存 edits 文件的配置路径
<property><name>dfs.namenode.edits.dir</name><value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value></property>
secondaryNamenode 保存 fsimage 文件的配置路径
<property><name>dfs.namenode.checkpoint.dir</name><value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name</value></property>
secondaryNamenode 保存 edits 文件的配置路径
<property><name>dfs.namenode.checkpoint.edits.dir</name><value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits</value></property>
接下来我们来模拟 namenode 的故障恢复功能:
- 杀死 namenode 进程: 使用 jps 查看 namenode 的进程号 , kill -9 直接杀死。
- 删除 namenode 的 fsimage 文件和 edits 文件。 根据上述配置, 找到 namenode 放置fsimage 和 edits 路径. 直接全部 rm -rf 删除。
- 拷贝 secondaryNamenode 的 fsimage 与 edits 文件到 namenode 的 fsimage 与 edits文件夹下面去。 根据上述配置, 找到 secondaryNamenode 的 fsimage 和 edits 路径, 内容 使用cp -r 全部复制到 namenode 对应的目录下即可。
- 重新启动 namenode, 观察数据是否存在。
10、datanode 工作机制以及数据存储
1、datanode 工作机制
- 一个数据块在 datanode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
- DataNode 启动后向 namenode 注册,通过后,周期性(1 小时)的向 namenode上报所有的块信息。(dfs.blockreport.intervalMsec)。
- 心跳是每 3 秒一次,心跳返回结果带有 namenode 给该 datanode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 datanode 的心跳,则认为该节点不可用。
- 集群运行中可以安全加入和退出一些机器。
2、数据完整性
- 当 DataNode 读取 block 的时候,它会计算 checksum。
- 如果计算后的 checksum,与 block 创建时值不一样,说明 block 已经损坏。
- client 读取其他 DataNode 上的 block。
- datanode 在其文件创建后周期验证 checksum。
3、掉线时限参数设置
datanode 进程死亡或者网络故障造成 datanode 无法与 namenode 通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为 10 分钟+30 秒。
如果定义超时时间为 timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 *dfs.heartbeat.interval。
而默认的 dfs.namenode.heartbeat.recheck-interval 大小为 5 分钟,dfs.heartbeat.interval 默认为 3 秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位
为毫秒,dfs.heartbeat.interval 的单位为秒。
<property><name>dfs.namenode.heartbeat.recheck-interval</name><value>300000</value></property><property><name>dfs.heartbeat.interval </name><value>3</value></property>
4、DataNode 的目录结构
和 namenode 不同的是,datanode 的存储目录是初始阶段自动创建的,不
需要额外格式化。
在/opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current 这个目录下查看版本号
cat VERSION
#Thu Mar 14 07:58:46 CST 2019storageID=DS-47bcc6d5-c9b7-4c88-9cc8-6154b8a2bf39
clusterID=CID-dac2e9fa-65d2-4963-a7b5-bb4d0280d3f4
cTime=0datanodeUuid=c44514a0-9ed6-4642-b3a8-5af79f03d7a4
storageType=DATA_NODE
layoutVersion=-56
具体解释:
- storageID:存储 id 号。
- clusterID 集群 id,全局唯一。
- cTime 属性标记了 datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为 0;但是在文件系统升级之后,该值会更新到新的时间戳。
- datanodeUuid:datanode 的唯一识别码。
- storageType:存储类型。
- layoutVersion 是一个负整数。通常只有 HDFS 增加新特性时才会更新这个版本 号。
5、datanode 多目录配置
datanode 也可以配置成多个目录,每个目录存储的数据不一样。即:数据不是副本。具体配置如下: - 只需要在 value 中使用逗号分隔出多个存储目录即可
cd /opt/hadoop-2.6.0-cdh5.14.0/etc/hadoop
<!-- 定义 dataNode 数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录
用,进行分割 --><property><name>dfs.datanode.data.dir</name><value>file:///opt/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDat
as</value></property>
6、新增数据节点DataNode
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存
储数据的需求,需要在原有集群基础上动态添加新的数据节点。
1、环境准备
- 复制一台新的虚拟机出来 将我们纯净的虚拟机复制一台出来,作为我们新的节点
- 修改 mac 地址以及 IP 地址 修改 mac 地址命令 vim /etc/udev/rules.d/70-persistent-net.rules 修改 ip 地址命令 vim /etc/sysconfig/network-scripts/ifcfg-eth0
- 关闭防火墙,关闭 selinux 关闭防火墙 service iptables stop 关闭 selinux vim /etc/selinux/config
- 更改主机名 更改主机名命令,将 node04 主机名更改为 node04.hadoop.com vim /etc/sysconfig/network
- 四台机器更改主机名与 IP 地址映射 四台机器都要添加 hosts 文件 vim /etc/hosts 192.168.52.100 node01.hadoop.com node01 192.168.52.110 node02.hadoop.com node02 192.168.52.120 node03.hadoop.com node03 192.168.52.130 node04.hadoop.com node04
- node04 服务器关机重启 node04 执行以下命令关机重启 reboot -h now 7. node04 安装 jdk node04 统一两个路径 mkdir -p /export/softwares/ mkdir -p /export/servers/ 然后解压 jdk 安装包,配置环境变量
- 解压 hadoop 安装包 在 node04 服务器上面解压 hadoop 安装包到/export/servers , node01 执行以下命令将hadoop 安装包拷贝到 node04 服务器 cd /export/softwares/ scp hadoop-2.6.0-cdh5.14.0-自己编译后的版本.tar.gz node04:$PWDnode04 解压安装包 tar -zxf hadoop-2.6.0-cdh5.14.0-自己编译后的版本.tar.gz -C /export/servers/
- 将 node01 关于 hadoop 的配置文件全部拷贝到 node04 node01 执行以下命令,将 hadoop 的配置文件全部拷贝到 node04 服务器上面 cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/ scp ./* node04:$PWD
2、新增DataNode
- 创建 dfs.hosts 文件 在 node01 也就是 namenode 所在的机器的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop 目录下创建 dfs.hosts 文件 [root@node01 hadoop]# cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop [root@node01 hadoop]# touch dfs.hosts [root@node01 hadoop]# vim dfs.hosts 添加如下主机名称(包含新服役的节点) node01 node02 node03 node04
- node01 编辑 hdfs-site.xml 添加以下配置 在 namenode 的 hdfs-site.xml 配置文件中增加 dfs.hosts 属性 node01 执行以下命令 : cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim hdfs-site.xml
# 添加一下内容<property><name>dfs.hosts</name><value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value></property><!--动态上下线配置: 如果配置文件中有, 就不需要配置--><property><name>dfs.hosts</name><value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/accept_host</value></property><property><name>dfs.hosts.exclude</name><value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/deny_host</value></property> - 刷新 namenode node01 执行以下命令刷新 namenode [root@node01 hadoop]# hdfs dfsadmin -refreshNodes Refresh nodes successful
- 更新 resourceManager 节点 node01 执行以下命令刷新 resourceManager [root@node01 hadoop]# yarn rmadmin -refreshNodes 19/03/16 11:19:47 INFO client.RMProxy: Connecting to ResourceManager at node01/192. 168.52.100:8033
- namenode 的 slaves 文件增加新服务节点主机名称 node01 编辑 slaves 文件,并添加新增节点的主机,更改完后,slaves 文件不需要分发到其他机器上面去node01 执行以下命令编辑 slaves 文件 : cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim slaves 添加一下内容: node01 node02 node03 node04
- 单独启动新增节点 node04 服务器执行以下命令,启动 datanode 和 nodemanager : cd /export/servers/hadoop-2.6.0-cdh5.14.0/ sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start nodemanager
- 使用负载均衡命令,让数据均匀负载所有机器 node01 执行以下命令 : cd /export/servers/hadoop-2.6.0-cdh5.14.0/ sbin/start-balancer.sh
7、去除不需要数据节点DataNode
- 创建 dfs.hosts.exclude 配置文件 在 namenod 所在服务器的 /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop 目录下创建 dfs.hosts.exclude 文件,并添加需要退役的主机名称node01 执行以下命令 : cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop touch dfs.hosts.exclude vim dfs.hosts.exclude添加以下内容: node04.hadoop.com 特别注意:该文件当中一定要写真正的主机名或者 ip 地址都行,不能写 node04
- 编辑 namenode 所在机器的 hdfs-site.xml 编辑 namenode 所在的机器的 hdfs-site.xml 配置文件,添加以下配置 cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoopvim hdfs-site.xml
#添加一下内容:<property><name>dfs.hosts.exclude</name><value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.exclude</value></property> - 刷新 namenode,刷新 resourceManager 在 namenode 所在的机器执行以下命令,刷新 namenode,刷新 resourceManager : hdfs dfsadmin -refreshNodes yarn rmadmin -refreshNodes
- 节点退役完成,停止该节点进程 等待退役节点状态为 decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是 3,服役的节点小于等于 3,是不能退役成功的,需要修改副本数后才能退役。 node04 执行以下命令,停止该节点进程 : cd /export/servers/hadoop-2.6.0-cdh5.14.0 sbin/hadoop-daemon.sh stop datanode sbin/yarn-daemon.sh stop nodemanager
- 从 include 文件中删除退役节点 namenode 所在节点也就是 node01 执行以下命令删除退役节点 : cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim dfs.hosts 删除后的内容: 删除了 node04 node01 node02 node03
- node01 执行一下命令刷新 namenode,刷新 resourceManager hdfs dfsadmin -refreshNodes yarn rmadmin -refreshNodes
- 从 namenode 的 slave 文件中删除退役节点 namenode 所在机器也就是 node01 执行以下命令从 slaves 文件中删除退役节点 : cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim slaves 删除后的内容: 删除了 node04 node01 node02 node03
- 如果数据负载不均衡,执行以下命令进行均衡负载 node01 执行以下命令进行均衡负载 cd /export/servers/hadoop-2.6.0-cdh5.14.0/ sbin/start-balancer.sh
11、 block 块手动拼接成为完整数据
所有的数据都是以一个个的 block 块存储的,只要我们能够将文件的所有 block块全部找出来,拼接到一起,又会成为一个完整的文件,接下来我们就来通过命令将文件进行拼接:
- 上传一个大于 128M 的文件到 hdfs 上面去我们选择一个大于 128M 的文件上传到 hdfs 上面去,只有一个大于 128M 的文件才会有多个 block 块。这里我们选择将我们的 jdk 安装包上传到 hdfs 上面去。node01 执行以下命令上传 jdk 安装包 cd /export/softwares/ hdfs dfs -put jdk-8u141-linux-x64.tar.gz /
- web 浏览器界面查看 jdk 的两个 block 块 id 这里我们看到两个 block 块 id 分别为1073742699 和 1073742700 那么我们就可以通过 blockid 将我们两个 block 块进行手动拼接了。
- 根据我们的配置文件找到 block 块所在的路径 根据我们 hdfs-site.xml 的配置,找到 datanode 所在的路径
<!-- 定义 dataNode 数据存储的节点位置,实际工作中,一般先确定磁盘的挂载目录,然后多个目录用,进行分割 --><property><name>dfs.datanode.data.dir</name><value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value></property>
进入到以下路径 : 此基础路径为 上述配置中 value 的路径
cd /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current/BP-5574
66926-192.168.52.100-1549868683602/current/finalized/subdir0/subdir3
- 执行 block 块的拼接 将不同的各个 block 块按照顺序进行拼接起来,成为一个完整的文件 cat blk_1073742699 >> jdk8u141.tar.gz cat blk_1073742700 >> jdk8u141.tar.gz 移动我们的 jdk 到/export 路径,然后进行解压 mv jdk8u141.tar.gz /export/ cd /export/ tar -zxf jdk8u141.tar.gz 正常解压,没有问题,说明我们的程序按照 block 块存储没有问题
12、HDFS 其他重要功能
1. 多个集群之间的数据拷贝
在我们实际工作当中,极有可能会遇到将测试集群的数据拷贝到生产环境集群,或者将生产环境集群的数据拷贝到测试集群,那么就需要我们在多个集群之间进行数据的远程拷贝,hadoop 自带也有命令可以帮我们实现这个功能
1、本地文件拷贝 scp
cd /export/softwares/
scp -r jdk-8u141-linux-x64.tar.gz root@node02:/export/
2、 集群之间的数据拷贝 distcp
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
bin/hadoop distcp hdfs://node01:8020/jdk-8u141-linux-x64.tar.gz hdfs://cluster2:80
20/
2、hadoop 归档文件 archive
每个文件均按块存储,每个块的元数据存储在 namenode 的内存中,因此 hadoop存储小文件会非常低效。因为大量的小文件会耗尽 namenode 中的大部分内存。
但注意,存储小文件所需要的磁盘容量和存储这些文件原始内容所需要的磁盘空
间相比也不会增多。例如,一个 1MB 的文件以大小为 128MB 的块存储,使用的是
1MB 的磁盘空间,而不是 128MB。
Hadoop 存档文件或 HAR 文件,是一个更高效的文件存档工具,它将文件存入 HDFS
块,在减少 namenode 内存使用的同时,允许对文件进行透明的访问。具体说来,
Hadoop 存档文件可以用作 MapReduce 的输入。
创建归档文件
1、第一步:创建归档文件
注意:归档文件一定要保证 yarn 集群启动
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hadoop archive -archiveName myhar.har -p /user/root /user
2、第二步:查看归档文件内容
hdfs dfs -lsr /user/myhar.har
hdfs dfs -lsr har:///user/myhar.har
3、第三步:解压归档文件
hdfs dfs -mkdir -p /user/har
hdfs dfs -cp har:///user/myhar.har/* /user/har/
3、hdfs 快照 snapShot 管理
快照顾名思义,就是相当于对我们的 hdfs 文件系统做一个备份,我们可以通过快照对我们指定的文件夹设置备份,但是添加快照之后,并不会立即复制所有文件,而是指向同一个文件。当写入发生时,才会产生新文件
1、快照使用基本语法
1、 开启指定目录的快照功能
hdfs dfsadmin -allowSnapshot 路径
2、禁用指定目录的快照功能(默认就是禁用状态)
hdfs dfsadmin -disallowSnapshot 路径
本文档来自公众号:五分钟学大数据
3、给某个路径创建快照 snapshot
hdfs dfs -createSnapshot 路径
4、指定快照名称进行创建快照 snapshot
hdfs dfs -createSanpshot 路径 名称
5、给快照重新命名
hdfs dfs -renameSnapshot 路径 旧名称 新名称
6、列出当前用户所有可快照目录
hdfs lsSnapshottableDir
7、比较两个快照的目录不同之处
hdfs snapshotDiff 路径 1 路径 28、删除快照 snapshot
hdfs dfs -deleteSnapshot<path><snapshotName>
2、快照操作实际案例
1、开启与禁用指定目录的快照
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfsadmin -allowSnapshot /user
Allowing snaphot on /user succeeded
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfsadmin -disallowSnapshot /user
Disallowing snaphot on /user succeeded
2、对指定目录创建快照
注意:创建快照之前,先要允许该目录创建快照
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfsadmin -allowSnapshot /user
Allowing snaphot on /user succeeded
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfs -createSnapshot /user
Created snapshot /user/.snapshot/s20190317-210906.549
通过 web 浏览器访问快照
http://node01:50070/explorer.html#/user/.snapshot/s20190317-210906.5493、指定名称创建快照
[root@node01 hadoop-2.6.0-cdh5.14.0]# hdfs dfs -createSnapshot /user mysnap1
Created snapshot /user/.snapshot/mysnap1
4、重命名快照
hdfs dfs -renameSnapshot /user mysnap1 mysnap2
5、列出当前用户所有可以快照的目录
hdfs lsSnapshottableDir
6、比较两个快照不同之处
hdfs dfs -createSnapshot /user snap1
hdfs dfs -createSnapshot /user snap2
hdfs snapshotDiff snap1 snap2
7、删除快照
hdfs dfs -deleteSnapshot /user snap1
4. hdfs 回收站
任何一个文件系统,基本上都会有垃圾桶机制,也就是删除的文件,不会直接彻底清掉,我们一把都是将文件放置到垃圾桶当中去,过一段时间之后,自动清空垃圾桶当中的文件,这样对于文件的安全删除比较有保证,避免我们一些误操作,导致误删除文件或者数据
1、回收站配置两个参数
默认值 fs.trash.interval=0,0 表示禁用回收站,可以设置删除文件的存活时间。
默认值 fs.trash.checkpoint.interval=0,检查回收站的间隔时间。
要求 fs.trash.checkpoint.interval<=fs.trash.interval。
2、启用回收站
修改所有服务器的 core-site.xml 配置文件
<!-- 开启 hdfs 的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 --><property><name>fs.trash.interval</name><value>10080</value></property>
3、查看回收站
回收站在集群的 /user/root/.Trash/ 这个路径下
4、通过 javaAPI 删除的数据,不会进入回收站,需要调用 moveToTrash()才会进入回收
站
//使用回收站的方式: 删除数据@TestpublicvoiddeleteFile()throwsException{//1. 获取 FileSystem 对象Configuration configuration =newConfiguration();FileSystem fileSystem =FileSystem.get(newURI("hdfs://node01:8020"), confi
guration,"root");//2. 执行删除操作// fileSystem.delete(); 这种操作会直接将数据删除, 不会进入垃圾桶Trash trash =newTrash(fileSystem,configuration);boolean flag = trash.isEnabled();// 是否已经开启了垃圾桶机制System.out.println(flag);
trash.moveToTrash(newPath("/quota"));//3. 释放资源
fileSystem.close();}
5、恢复回收站数据
hdfs dfs -mv trashFileDir hdfsdir
trashFileDir :回收站的文件路径
hdfsdir :将文件移动到 hdfs 的哪个路径下
6、清空回收站
hdfs dfs -expunge
转载自:五分钟大数据
版权归原作者 白鸽呀 所有, 如有侵权,请联系我们删除。