
文章目录
前言
上文末尾讲到了Eureka对于下线服务的感知不是很敏锐,会把已经下线的服务加载到可用的服务列表里。当轮询到该服务实例来处理请求就会出现“调用请求已经发送出去,但是接口却TimeOut、404、500…错误”,本文会使用多种服务下线方式并结合JMeter压测来具体分析
1. Eureka-Server的设计
Eureka中设计了三级缓存:一级缓存(registry注册表)——二级缓存(readWriteCacheMap读写缓存)——三级缓存(readOnlyCacheMap只读缓存)。作为经典的AP模型,读写分离,牺牲了一致性保证了高可用。(以后会分析源码)
2. Eureka+Ribbon感知下线服务机制
当客户端的服务实例正常下线,会发送心跳向Eureka服务端中的一级缓存更新信息(30S)——一级缓存会向二级缓存同步信息(立刻)——二级缓存向三级缓存同步信息(30S)——客户端从三级缓存中同步信息(30S)——Ribbon会向客户端同步缓存,更新服务列表upList(30S),可见如果是在极端情况下,感知到一个服务下线是需要120S的。(注意这并不是串行化执行,30S均为默认时间)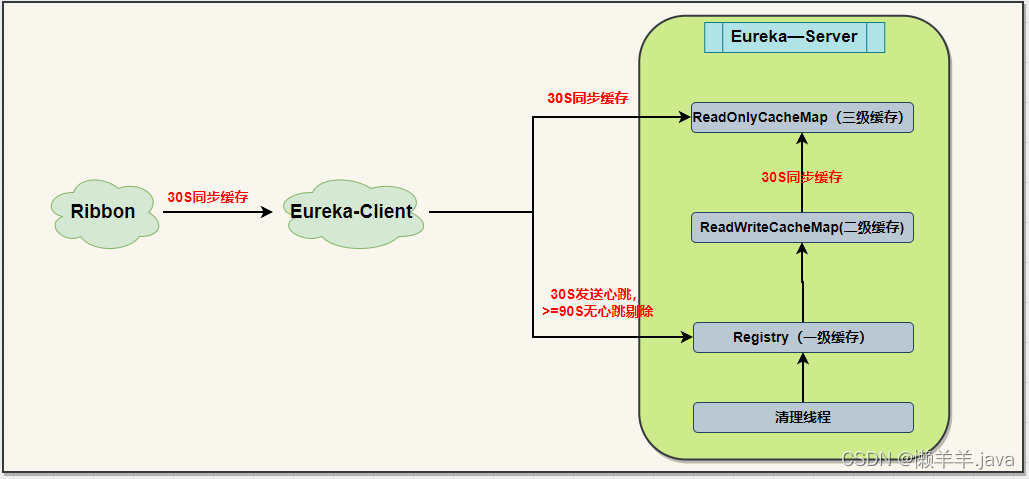
下面基于这个流程,采用多种下线的方式结合JMeter压测报告来研究Eureka服务下线感知情况
3.服务调用接口压测模型
采用Jmeter(100个线程—3S内请求)对服务下线后的服务调用接口进行压测,来观察接口执行情况,以及结合日志来体现Ribbon的负载均衡情况:

通过观察线程组执行完后响应的异常率,来判断已经下线的服务是否没有被Eureka、Ribbon及时更新(也就是服务的感知情况),从而使调用方调用到了不可用的服务。
服务被调用方现有8081、8083、8084三个端口的实例,本次实验统一下线其中两个服务实例,并且Ribbon负载均衡的策略都为默认
4.Eureka几种服务下线的方式
4.1强制下线
直接关闭进程,类似于在服务器上通过kill-9的方式。通过下面的案例可以看到,当我强制下线了服务下的两个服务实例之后,此时立即进行服务间的远程调用(由于Eureka的缓存机制,已经下线的服务还会在缓存的服务列表中没来得及更新,但是列表里已经被下线的实例已经无法再处理请求),调用方会报出connect refused的错误,就像这样:
在控制台中,调用方直接无法建立连接,请求已经到达目标服务,但目标服务主动拒绝了连接。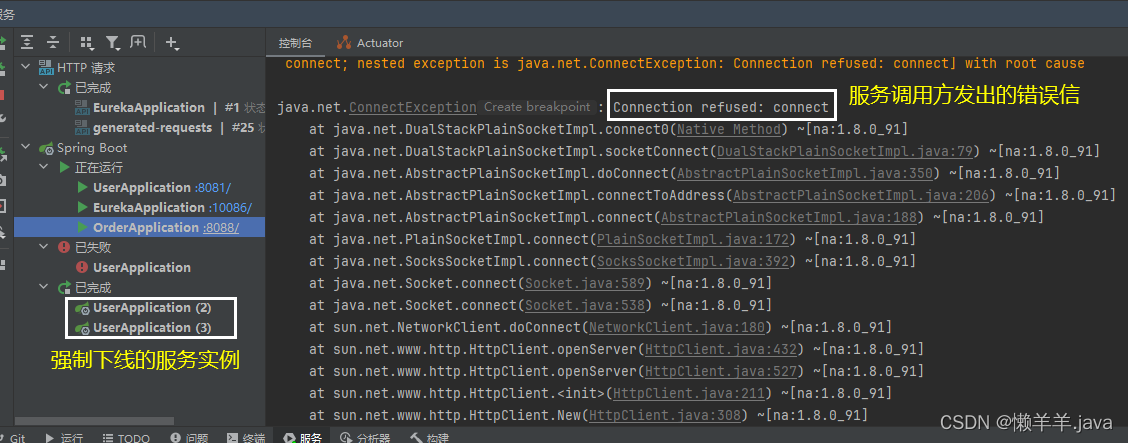
在postman中发起调用的接口则是直接报出了500错误,显示服务端存在内部问题: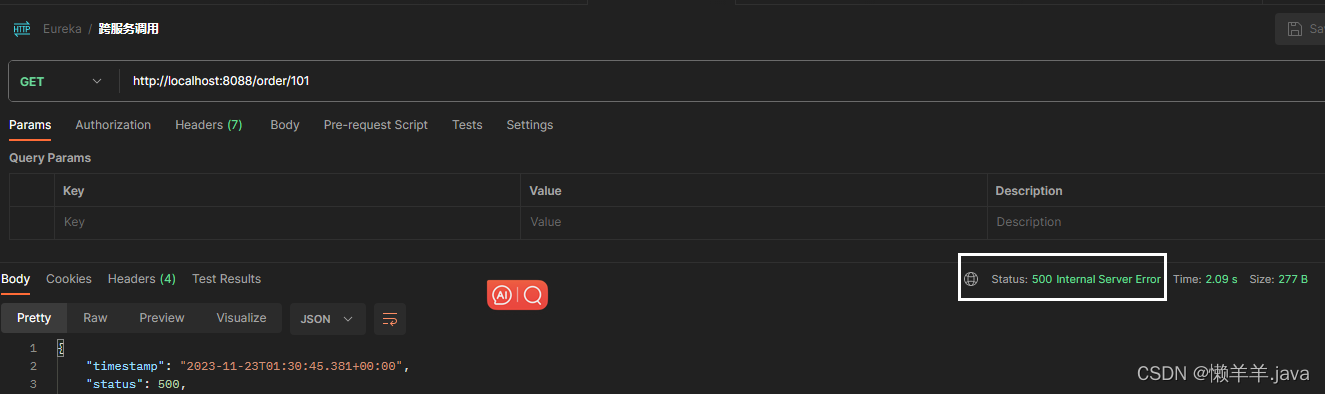
PS:这样下线会存在很多风险,比如进程中还有请求在处理,不建议使用
压测
15S,使用Jmeter压测模型进行压测,发现异常率高达51%
30S,使用Jmeter压测模型进行压测,发现异常率为0%
4.2 发送delete()请求
向Eureka服务端发送http请求,来删除注册表的服务信息,也就是一级缓存中的数据
@GetMapping("/service-down")publicStringshutDown(@RequestParamList<Integer> portParams,@RequestParamString vipAddress){List<Integer> successList =newArrayList<>();//获取到服务名下的所有服务实例List<InstanceInfo> instances = eurekaClient.getInstancesByVipAddress(vipAddress,false);//map<端口-实例id>
instances.forEach(temp ->{String instanceId = temp.getInstanceId();String appName = temp.getAppName();int port = temp.getPort();//"http://eureka-server-url/eureka/apps/" + appName + "/" + instanceId;
sourceMap.put(port, appName +"/"+instanceId);});//创建请求体OkHttpClient client =newOkHttpClient();if(ObjectUtils.isEmpty(portParams)){return"端口为空";//todo 完善自定义异常}
portParams.forEach(temp->{//处理服务信息String serviceInfo = sourceMap.get(temp);//创建请求去删除服务Request request =newRequest.Builder().url("http://"+eurekaServer+"/eureka/apps/"+ serviceInfo).delete().build();
log.debug(request.url().toString());try{Response response = client.newCall(request).execute();if(response.code()==200){
log.debug(serviceInfo+"服务下线成功");
successList.add(temp);}else{
log.debug(serviceInfo+"服务下线失败");}}catch(IOException e){
log.error(e.toString());}});return"goodbye service"+successList;}
使用这种方法,就是越过了client向一级缓存发送心跳的步骤,直接清除了一级缓存相当节省了极端情况的30S。其实这也是不可取的,因为此时我只是相当于告诉了eureka-Serve,该服务下线了,但是服务进程在没有被关闭的条件下还是会发送心跳向eureka-server的一级缓存同步信息的。
就会导致这样一种情况发生: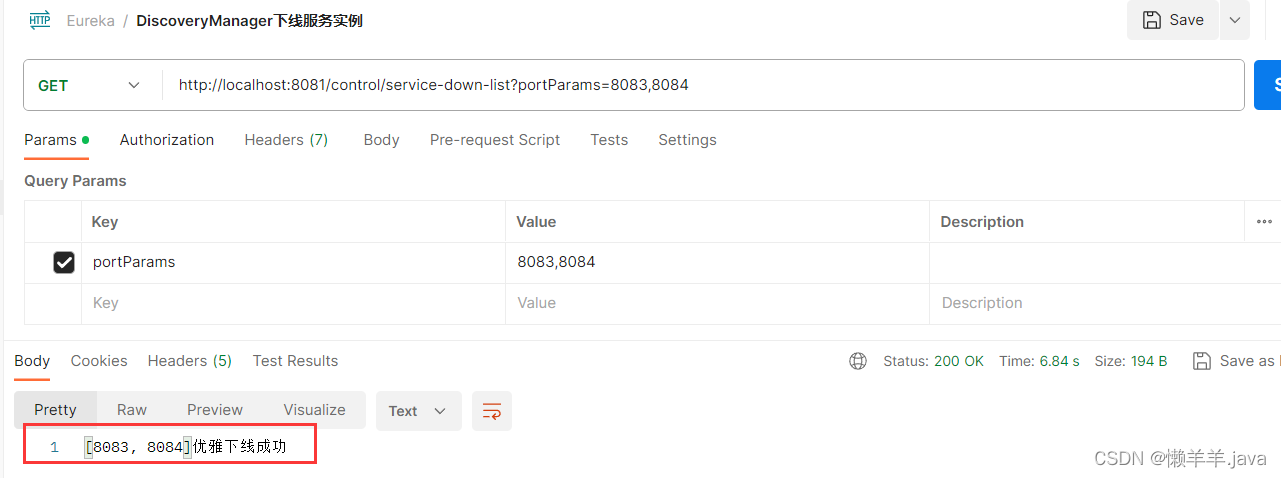

时间过了大约十几秒之后,下线的服务又被注册了回来:
在刚执行完下线服务的接口之后,立即进行远程调用,就出现了异常情况,接口响应时长太长太长: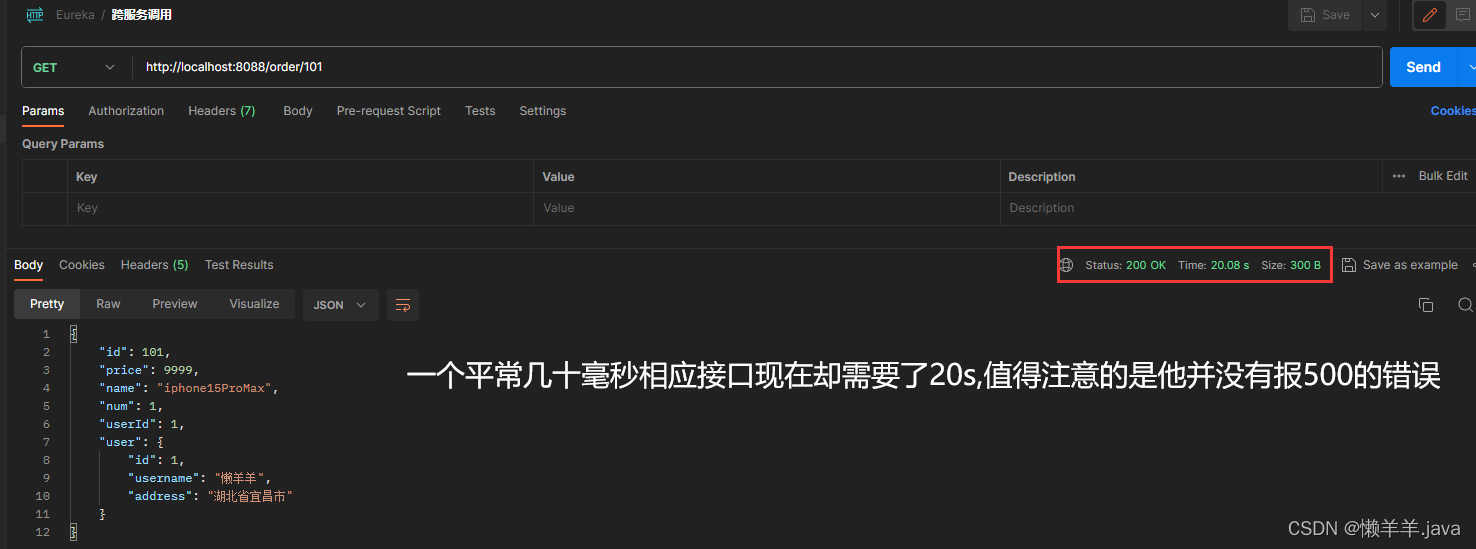
我的理解:由于调用了下线服务的接口,Eureka-Server中的一级缓存信息被清除了,但是三级缓存以及Ribbon中的缓存并没有被清除(也就是更新)。恰巧负载均衡轮询到了已下线但未更新的服务实例,负载均衡使得调用方成功发送了请求,也就是给了调用方一个假象。值得注意的是,直到此时客户端的服务在物理层面上是没有下线的,他还在向Eureka-server的一级缓存发送心跳并同步到三级缓存来保证服务可用。而这段时间(续约服务)就是接口响应时间过长的原因所在。
压测
15S,使用Jmeter压测模型进行压测,发现接口异常率为0%
30S,使用Jmeter压测模型进行压测,发现接口异常率为0%
为什么这样的方式在上述的两个时间节点都不会出现问题,这是因为15S,30S后下线的服务已经续约上了,跨服务调用的接口请求还是被负载均衡到了三个服务实例上。
可以想象:当Eureka-Server中的二级缓存去同步一级缓存时,下线的服务已经通过心跳续约到了一级缓存(注册表)中,下线的服务已经重新注册,三级缓存同步二级缓存时,服务都是在线的状态,不存在什么调用到下线的服务。
4.3 调用DiscoveryManager
客户端主动下线,调用DiscoveryManager的API来下线服务(不会关闭进程)。可以通过接口来发送http请求的方式:
@GetMapping(value ="/service-down")publicvoidoffLine(){DiscoveryManager.getInstance().shutdownComponent();}
为了方便下线指定端口,我是这样写的(发请求通过接口调接口):
/**
* DiscoveryManager下线服务
* @param portParams 下线端口列表
*/@GetMapping(value ="/service-down-list")publicStringoffLine(@RequestParamList<Integer> portParams){List<Integer> successList =newArrayList<>();//得到服务信息List<InstanceInfo> instances = eurekaClient.getInstancesByVipAddress(appName,false);List<Integer> servicePorts = instances.stream().map(InstanceInfo::getPort).collect(Collectors.toList());//去服务列表里挨个下线OkHttpClient client =newOkHttpClient();
portParams.forEach(temp ->{if(servicePorts.contains(temp)){Request request =newRequest.Builder().url("http://"+ ipAddress +":"+ temp +"/control/service-down").build();try{Response response = client.newCall(request).execute();if(response.code()==200){
log.debug(temp +"服务下线成功");
successList.add(temp);}else{
log.debug(temp +"服务下线失败");}}catch(IOException e){
log.error(e.toString());}}});return successList +"优雅下线成功";}
这样下线之后,客户端服务不会向eureka-server发送心跳,并且在一级缓存中的服务信息也会被立即清除。
理想状态:如果我们通过这样的方式,来下线服务,并且更新Ribbon同步缓存的时间,二级缓存同步三级缓存的时间,客户端同步三级缓存的时间,这样轮询到下线服务的概率是不是会大大减小?(当然更新这个时间应该只是针对原生的Eureka,对于SpringCloudEureka是不适用的)
压测
15S,异常率为0%,但是一级缓存中不存在的服务信息还是会被调用
30S,一级缓存中不存在的服务信息还是会被调用。
虽然上述两个时间节点的异常率都为0%,但是会负载均衡到刚刚通过api调用后已经下线的服务实例上: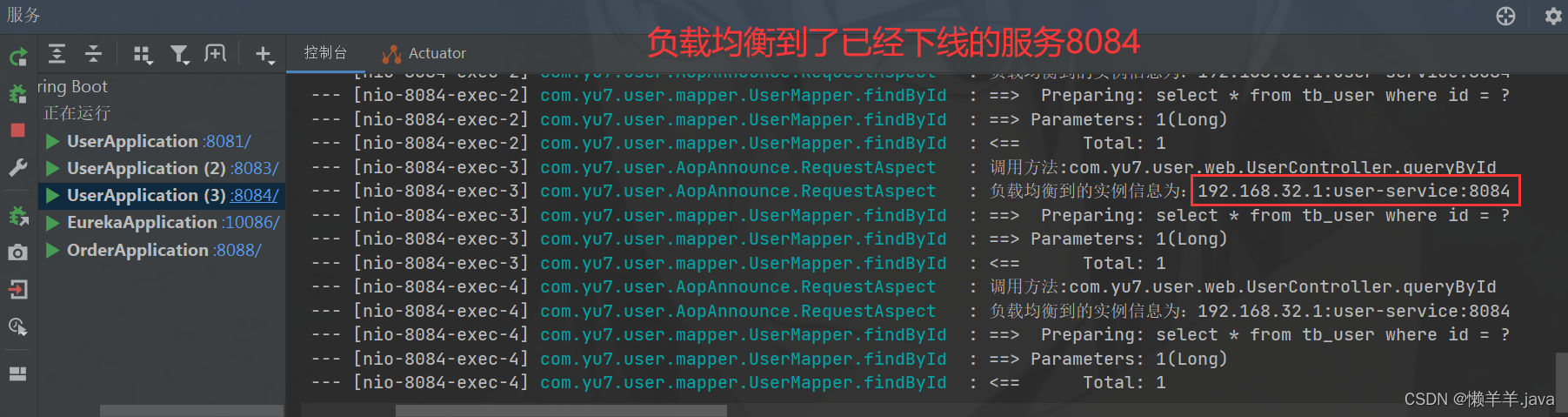
只有在40-50S的时间段才会不调用下线的服务,这段时间主要是在进行Eureka本地缓存的同步(二级同步三级,客户端同步三级,Ribbon同步客户端)
4. 三方工具Actuator
使用第三方工具,actuator来关闭服务,网上发现听说这种方式会让服务把当前请求处理完在关闭,并且会立即停止接受请求(关闭进程),实现起来比较简单只需要引入actuator依赖并且发送指定端口的post请求即可,就像这样:
/**
* actuator下线服务列表
* @param portParams 端口集合
* @return 优雅
*/@GetMapping(value ="/service-down-ports")publicStringdownServiceByPorts(@RequestParamList<Integer> portParams){if(ObjectUtils.isEmpty(portParams)){return"端口为空";}//成功下线列表List<Integer> successList =newArrayList<>();OkHttpClient client =newOkHttpClient();
portParams.forEach(temp ->{Request request =newRequest.Builder().url("http://"+ ipAddress +":"+ temp +"/actuator/shutdown").post(RequestBody.create(null,newbyte[0])).build();try{Response response = client.newCall(request).execute();if(response.code()==200){
log.debug(temp +"服务下线成功");
successList.add(temp);}else{
log.debug(temp +"服务下线失败");}}catch(IOException e){
log.error(e.toString());}});return successList +"优雅下线成功";}
服务会被下线,并且Eureka里一级缓存的数据立即会被清除,搭配起更改缓存同步的时间应该也是一个不错的选择(这也是针对原生的Eureka)
15S,异常率高达50%
30S,异常率为0%
看下来,后两种方案可以直接清理一级缓存,并且服务不会续约。但是由于三级缓存不是实时更新的,所以还是会有调用下线服务导致接口报错的风险。
总结
接口报错的前提是发生了服务调用,发生服务调用的前提是负载均衡,负载均衡的前提是拉取同步信息到Ribbon缓存,而问题就出在这里,即Ribbon加载到了已经下线的服务。想到去清理Ribbon缓存(强制更新)这样做可以减少刷新服务的时间但不能根本解决问题,因为他是从客户端同步的缓存,而客户端又是从三级缓存同步的缓存,所以归根结底在于三级缓存同步二级缓存也就相当于是一级缓存(这个过程时间非常短)。但是springcloudeureka是不能强制更新三级缓存的
好像只能通过缩短感应时间来降低错误发生的概率,不能完全避免错误
对于SpringCloudEureka而言,上面的方式还有很多优化的手段来缩短感知时间,我们下次再来talk about~
版权归原作者 懒羊羊.java 所有, 如有侵权,请联系我们删除。