
一、为何要搭建 Elasticsearch 集群
凡事都要讲究个为什么。在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢?
(1)高可用性
Elasticsearch 作为一个搜索引擎,我们对它的基本要求就是存储海量数据并且可以在非常短的时间内查询到我们想要的信息。所以第一步我们需要保证的就是 Elasticsearch 的高可用性,什么是高可用性呢?它通常是指,通过设计减少系统不能提供服务的时间。假设系统一直能够提供服务,我们说系统的可用性是 100%。如果系统在某个时刻宕掉了,比如某个网站在某个时间挂掉了,那么就可以它临时是不可用的。所以,为了保证 Elasticsearch 的高可用性,我们就应该尽量减少 Elasticsearch 的不可用时间。
那么怎样提高 Elasticsearch 的高可用性呢?这时集群的作用就体现出来了。假如 Elasticsearch 只放在一台服务器上,即单机运行,假如这台主机突然断网了或者被攻击了,那么整个 Elasticsearch 的服务就不可用了。但如果改成 Elasticsearch 集群的话,有一台主机宕机了,还有其他的主机可以支撑,这样就仍然可以保证服务是可用的。
那可能有的小伙伴就会说了,那假如一台主机宕机了,那么不就无法访问这台主机的数据了吗?那假如我要访问的数据正好存在这台主机上,那不就获取不到了吗?难道其他的主机里面也存了一份一模一样的数据?那这岂不是很浪费吗?
为了解答这个问题,这里就引出了 Elasticsearch 的信息存储机制了。首先解答上面的问题,一台主机宕机了,这台主机里面存的数据依然是可以被访问到的,因为在其他的主机上也有备份,但备份的时候也不是整台主机备份,是分片备份的,那这里就又引出了一个概念——分片。
分片,英文叫做 Shard,顾名思义,分片就是对数据切分成了多个部分。我们知道 Elasticsearch 中一个索引(Index)相当于是一个数据库,如存某网站的用户信息,我们就建一个名为 user 的索引。但索引存储的时候并不是整个存一起的,它是被分片存储的,Elasticsearch 默认会把一个索引分成五个分片,当然这个数字是可以自定义的。分片是数据的容器,数据保存在分片内,分片又被分配到集群内的各个节点里。当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里,所以相当于一份数据被分成了多份并保存在不同的主机上。
那这还是没解决问题啊,如果一台主机挂掉了,那么这个分片里面的数据不就无法访问了?别的主机都是存储的其他的分片。其实是可以访问的,因为其他主机存储了这个分片的备份,叫做副本,这里就引出了另外一个概念——副本。
副本,英文叫做 Replica,同样顾名思义,副本就是对原分片的复制,和原分片的内容是一样的,Elasticsearch 默认会生成一份副本,所以相当于是五个原分片和五个分片副本,相当于一份数据存了两份,并分了十个分片,当然副本的数量也是可以自定义的。这时我们只需要将某个分片的副本存在另外一台主机上,这样当某台主机宕机了,我们依然还可以从另外一台主机的副本中找到对应的数据。所以从外部来看,数据结果是没有任何区别的。
一般来说,Elasticsearch 会尽量把一个索引的不同分片存储在不同的主机上,分片的副本也尽可能存在不同的主机上,这样可以提高容错率,从而提高高可用性。
但这时假如你只有一台主机,那不就没办法了吗?分片和副本其实是没意义的,一台主机挂掉了,就全挂掉了。
(2)健康状态
针对一个索引,Elasticsearch 中其实有专门的衡量索引健康状况的标志,分为三个等级:
green,绿色。这代表所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果更多的分片消失,你就会丢数据了。所以可把 yellow 想象成一个需要及时调查的警告。
red,红色。至少一个主分片以及它的全部副本都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
如果你只有一台主机的话,其实索引的健康状况也是 yellow,因为一台主机,集群没有其他的主机可以防止副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的。
(3)存储空间
另外,既然是群集,那么存储空间肯定也是联合起来的,假如一台主机的存储空间是固定的,那么集群它相对于单个主机也有更多的存储空间,可存储的数据量也更大。
所以综上所述,我们需要一个集群!
二、详细了解 Elasticsearch 集群
接下来我们再来了解下集群的结构是怎样的。
首先我们应该清楚多台主机构成了一个集群,每台主机称作一个节点(Node)。
如图就是一个三节点的集群:
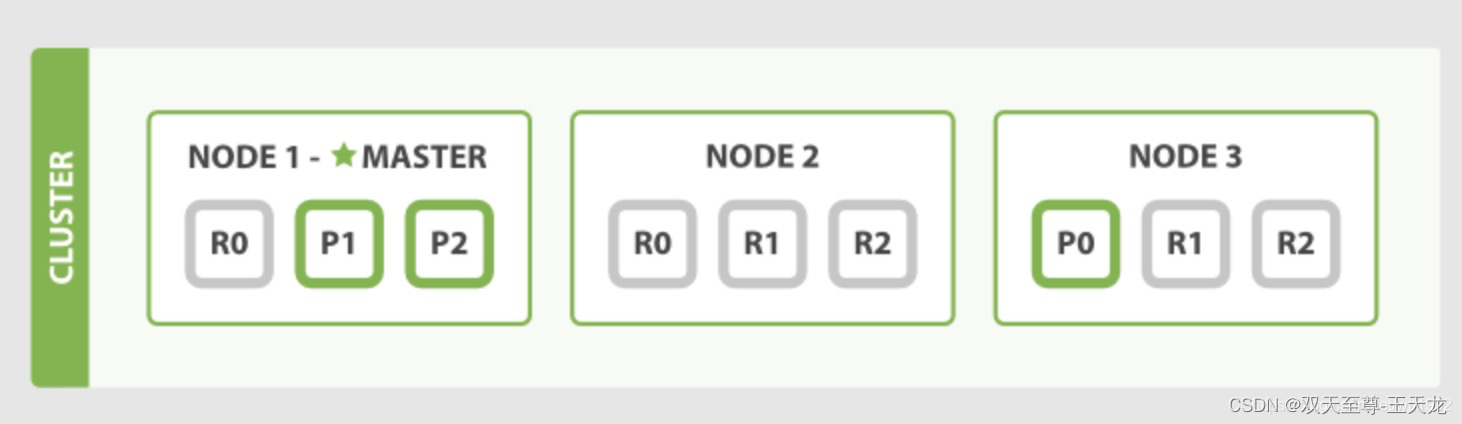

在图中,每个 Node 都有三个分片,其中 P 开头的代表 Primary 分片,即主分片,R 开头的代表 Replica 分片,即副本分片。所以图中主分片 1、2,副本分片 0 储存在 1 号节点,副本分片 0、1、2 储存在 2 号节点,主分片 0 和副本分片 1、2 储存在 3 号节点,一共是 3 个主分片和 6 个副本分片。同时我们还注意到 1 号节点还有个 MASTER 的标识,这代表它是一个主节点,它相比其他的节点更加特殊,它有权限控制整个集群,比如资源的分配、节点的修改等等。
这里就引出了一个概念就是节点的类型,我们可以将节点分为这么四个类型:
主节点:即 Master 节点。主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。默认情况下任何一个集群中的节点都有可能被选为主节点。索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
数据节点:即 Data 节点。数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对 CPU、内存、IO 要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
负载均衡节点:也称作 Client 节点,也称作客户端节点。当一个节点既不配置为主节点,也不配置为数据节点时,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。独立的客户端节点在一个比较大的集群中是非常有用的,他协调主节点和数据节点,客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
预处理节点:也称作 Ingest 节点,在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
以上就是节点几种类型,一个节点其实可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,但如果一个节点既不是主节点也不是数据节点,那么它就是负载均衡节点。具体的类型可以通过具体的配置文件来设置。
三、怎样搭建 Elasticsearch 8.6.1 集群
1、准备环境
采用三台CentOS7.6部署Elasticsearch集群,部署Elasticsearch集群就不得不提索引分片,以下是索引分片的简单介绍。
系统
节点名称
IP地址
centos stream 9
node1
192.168.56.201
centos stream 9
node2
192.168.56.202
centos stream 9
node3
192.168.56.203
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
下载Elasticsearch:
https://www.elastic.co/cn/downloads/past-releases#elasticsearch
在node1、node2、node3上都要执行一下操作:
增加/etc/hosts的ip解析:
vim /etc/hosts
192.168.56.201 node1
192.168.56.202 node2
192.168.56.203 node3
解压 elasticsearch-8.6.1-linux-x86_64.tar.gz
tar -zxvf elasticsearch-8.6.1-linux-x86_64.tar.gz
mv elasticsearch-8.6.1 es-cluster
配置环境变量:
vim /etc/profile.d/ES_ENV.sh
#!/bin/bash
export JAVA_HOME=/data/soft/jdk1.8.0_201
export ES_HOME=/data/soft/es-cluster
export PATH=$PATH:$JAVA_HOME/bin:$ES_HOME/bin
source /etc/profile
创建es用户:
useradd es
passwd es
为es-cluster目录进行用户授权:
chown -R es:es es-cluster/
JVM配置
由于Elasticsearch是Java开发的,所以可以通过/data/soft/es-cluster/config/jvm.options配置文件来设定JVM的相关设定。如果没有特殊需求按默认即可。
不过其中还是有两项最重要的-Xmx1g与-Xms1gJVM的最大最小内存。如果太小会导致Elasticsearch刚刚启动就立刻停止。太大会拖慢系统本身。

修改vim /etc/security/limits.conf:
#在文件末尾增加如下内容#每个进程可以打开的进程数的限制
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
vim /etc/sysctl.conf:
vm.max_map_count=655360
sysctl -p
vim /data/soft/es-cluster/config/elasticsearch.yml:
单机模式的节点配置如下:
# 集群名称
cluster.name: es-cluster
# 节点名称,仅仅是描述名称,用于在日志中区分
node.name: node1
# 当前节点的IP地址
network.host: node1
node.roles: [master, data]# 对外提供服务的端口,9300为集群服务的端口
http.port: 9200
#数据存放的位置
path.data: /data/soft/es-cluster/es-datas
#日志存放的位置
path.logs: /data/soft/es-cluster/es-logs
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x之后新增的配置,初始化一个新的集群时需要配置来选举master
cluster.initial_master_nodes: ["node1"]
集群下的node1的配置如下:
# 集群名称
cluster.name: es-cluster
# 节点名称,仅仅是描述名称,用于在日志中区分
node.name: node1
# 当前节点的IP地址
network.host: node1
node.roles: [master, data]# 对外提供服务的端口,9300为集群服务的端口
http.port: 9200
#数据存放的位置
path.data: /data/soft/es-cluster/es-datas
#日志存放的位置
path.logs: /data/soft/es-cluster/es-logs
# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x之后新增的配置,初始化一个新的集群时需要配置来选举master
cluster.initial_master_nodes: ["node1"]
discovery.seed_hosts: ["node1:9300","node2:9300","node3:9300"]
gateway.recover_after_data_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.compress: true#集群内同时启动的数据任务个数,默认是2个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#初始化数据恢复时,兵法恢复线程的个数,默认4个
cluster.routing.allocation.node_initial_primaries_recoveries: 16
2、配置账号密码登录
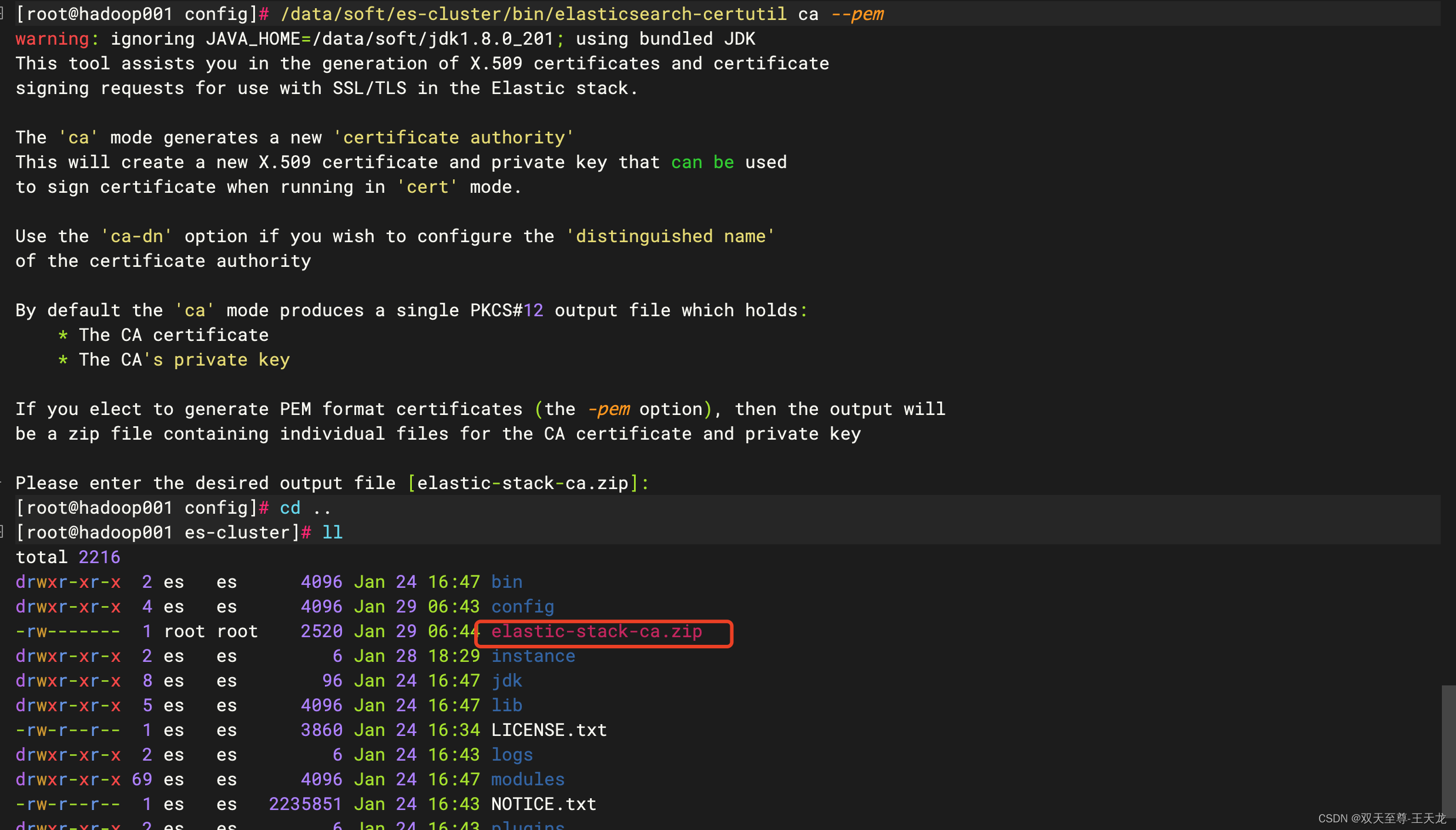
第一步:生成ES的秘钥
1、进入es的安装目录下的bin目录,输入下面代码,执行后会在bin目录下生成根密钥:elastic-stack-ca.zip
/data/soft/es-cluster/bin/elasticsearch-certutil ca --pem
生成的文件路径:/data/soft/es-cluster/elastic-stack-ca.zip
2、在bin目录输入下面代码,解压根秘钥,会生成一个ca文件夹,包含ca.key和ca.cert
unzip elastic-stack-ca.zip

3、然后在bin目录,输入下面代码,执行后会生成节点密钥:certificate-bundle.zip
/data/soft/es-cluster/bin/elasticsearch-certutil cert --ca-cert ca/ca.crt --ca-key ca/ca.key --pem
生成的文件路径:/data/soft/es-cluster/certificate-bundle.zip

4、在bin目录输入下面代码,解压节点密钥,解压后会生成 一个instance文件夹,包含instance.key和instance.crt
unzip certificate-bundle.zip
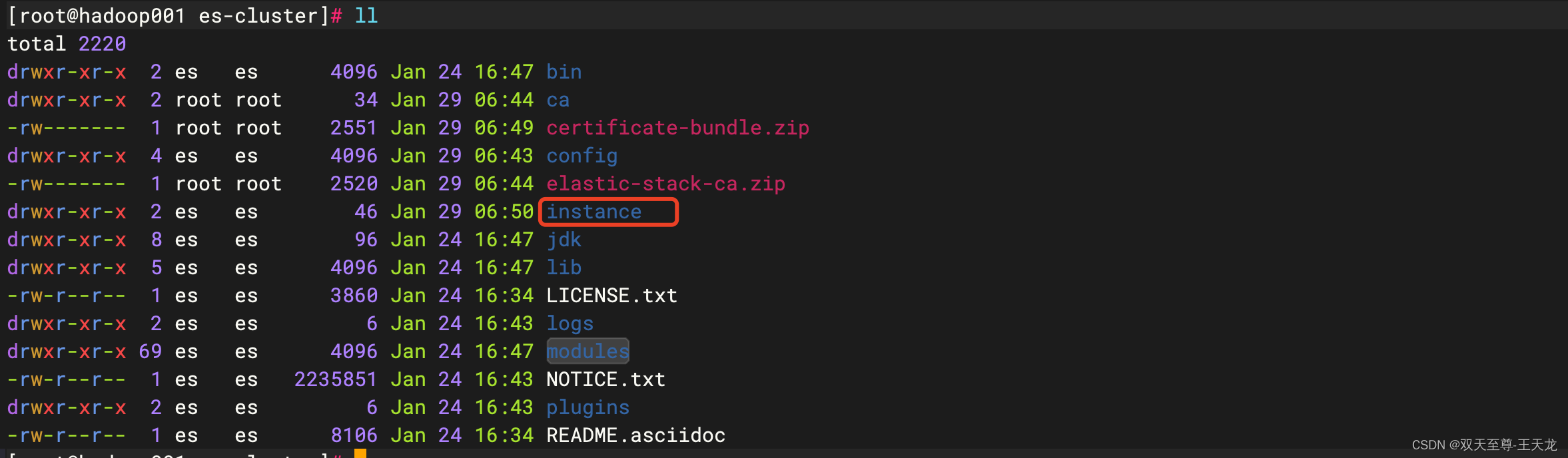
5、进入es的安装目录下的config,就是有elasticsearch.yml的目录,输入下面代码生成x-pack文件夹
cd /data/soft/es-cluster/config
mkdir x-pack
cp -r ../ca ./x-pack/
cp -r ../instance ./x-pack/

6、新增elasticsearch.yml里的配置
# 配置账号密码
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.key: x-pack/instance/instance.key
xpack.security.transport.ssl.certificate: x-pack/instance/instance.crt
xpack.security.transport.ssl.certificate_authorities: x-pack/ca/ca.crt
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
7、启动elasticsearch
chown -R es:es es-cluster/
su es
elasticsearch

后台启动的命令:
nohup elasticsearch &
8、交互式添加密码
/data/soft/es-cluster/bin/elasticsearch-setup-passwords interactive
输入代码后稍等一会会一行一行的出现提示语,让你修改各种密码,然后按照提示修改即可
[root@hadoop001 es-cluster]# /data/soft/es-cluster/bin/elasticsearch-setup-passwords interactive
warning: ignoring JAVA_HOME=/data/soft/jdk1.8.0_201; using bundled JDK
******************************************************************************
Note: The 'elasticsearch-setup-passwords' tool has been deprecated. This command will be removed in a future release.
******************************************************************************
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana_system]:
Reenter password for [kibana_system]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
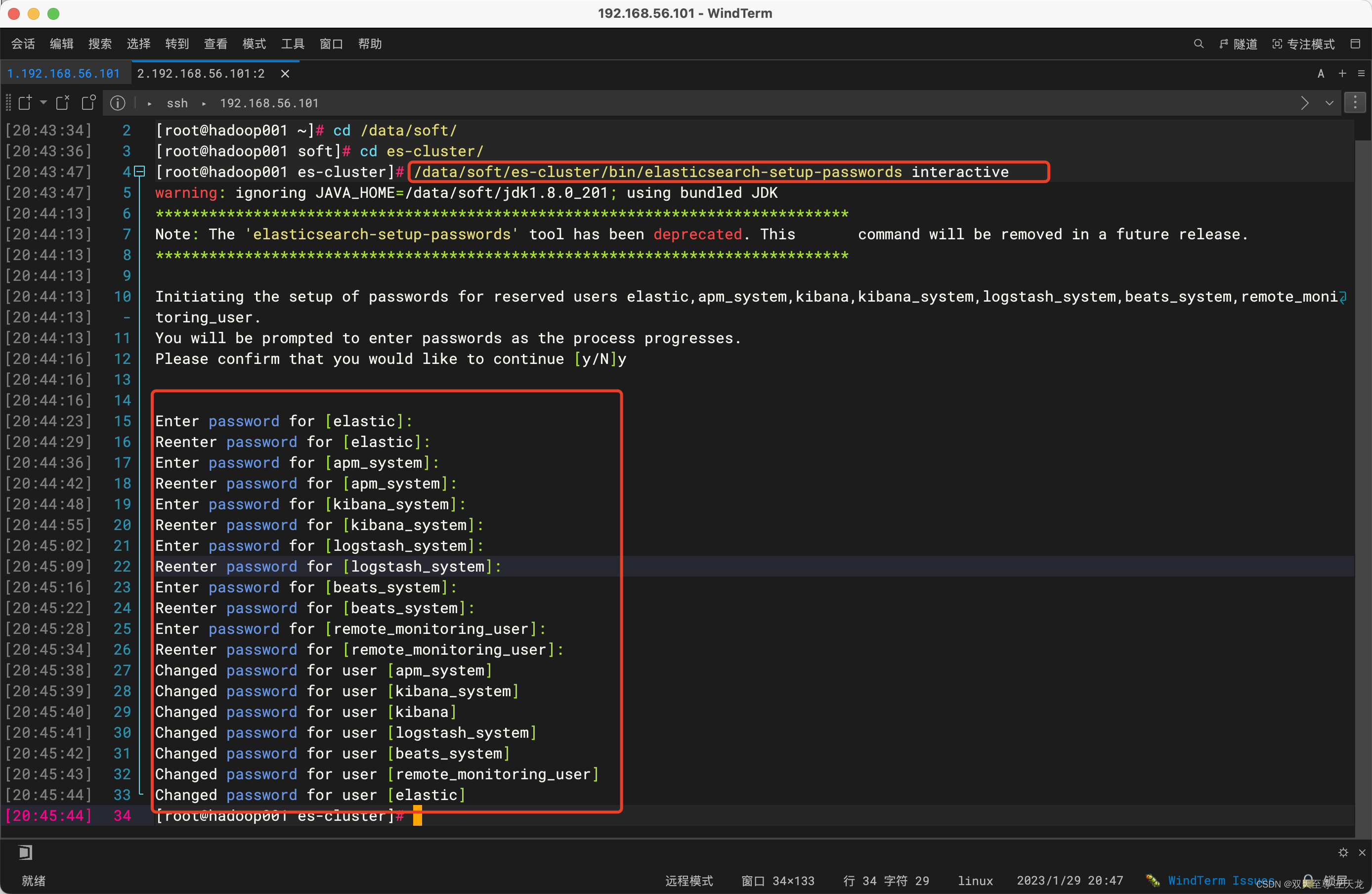
现在就大功告成了!!
用户名为: elastic
以下是集群的操作:
node1、node2、node3的 elasticsearch.yml:
需要修改的部分:
节点名称,仅仅是描述名称,用于在日志中区分
node.name: node1
当前节点的IP地址
network.host: node1
node2:
节点名称,仅仅是描述名称,用于在日志中区分
node.name: node2
当前节点的IP地址
network.host: node2
node3:
节点名称,仅仅是描述名称,用于在日志中区分
node.name: node3
当前节点的IP地址
network.host: node3
启动:
su es
/data/soft/es-cluster/bin/elasticsearch -d

然后在node2、node3上依次启动:
在node1上:
scp /etc/security/limits.conf node2:/etc/security/
scp /etc/security/limits.conf node3:/etc/security/
scp /etc/security/limits.d/20-nproc.conf node2:/etc/security/limits.d/
scp /etc/security/limits.d/20-nproc.conf node3:/etc/security/limits.d/
scp /etc/sysctl.conf node2:/etc/sysctl.conf
scp /etc/sysctl.conf node3:/etc/sysctl.conf
#在node2、node3上执行
sysctl -p

启动之前要修改es-cluster/config/elasticsearch.yml的内容!!!
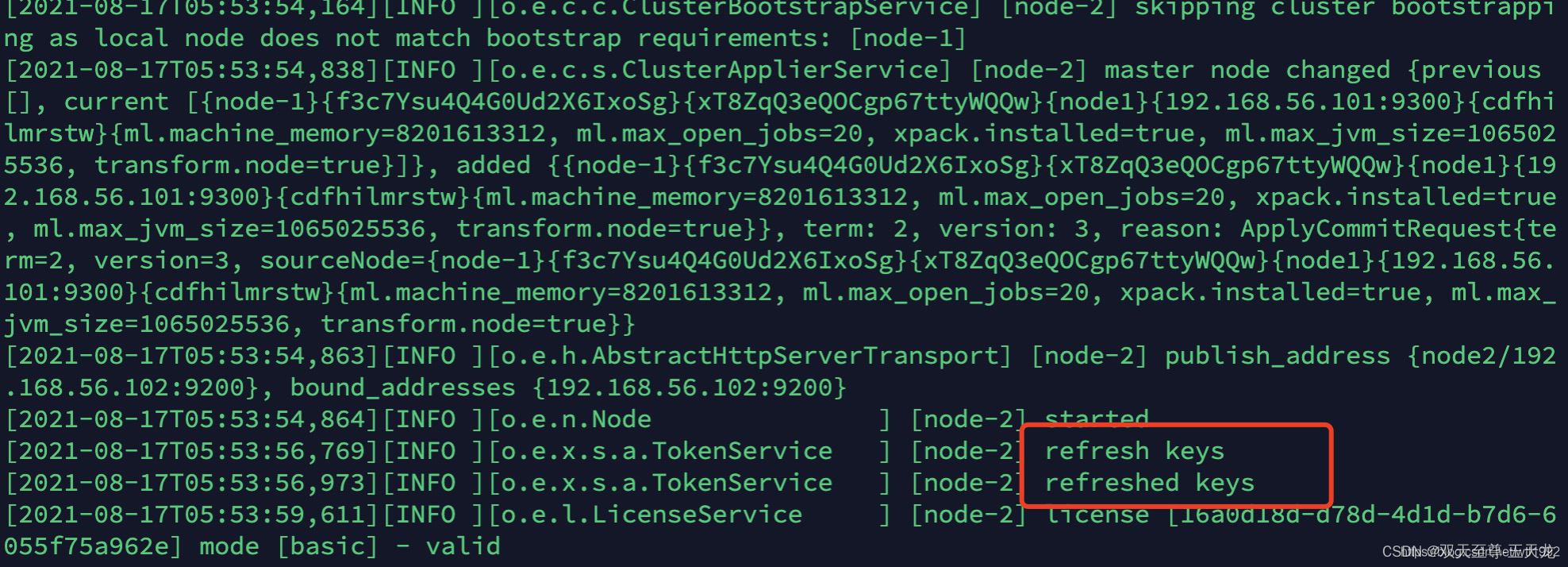
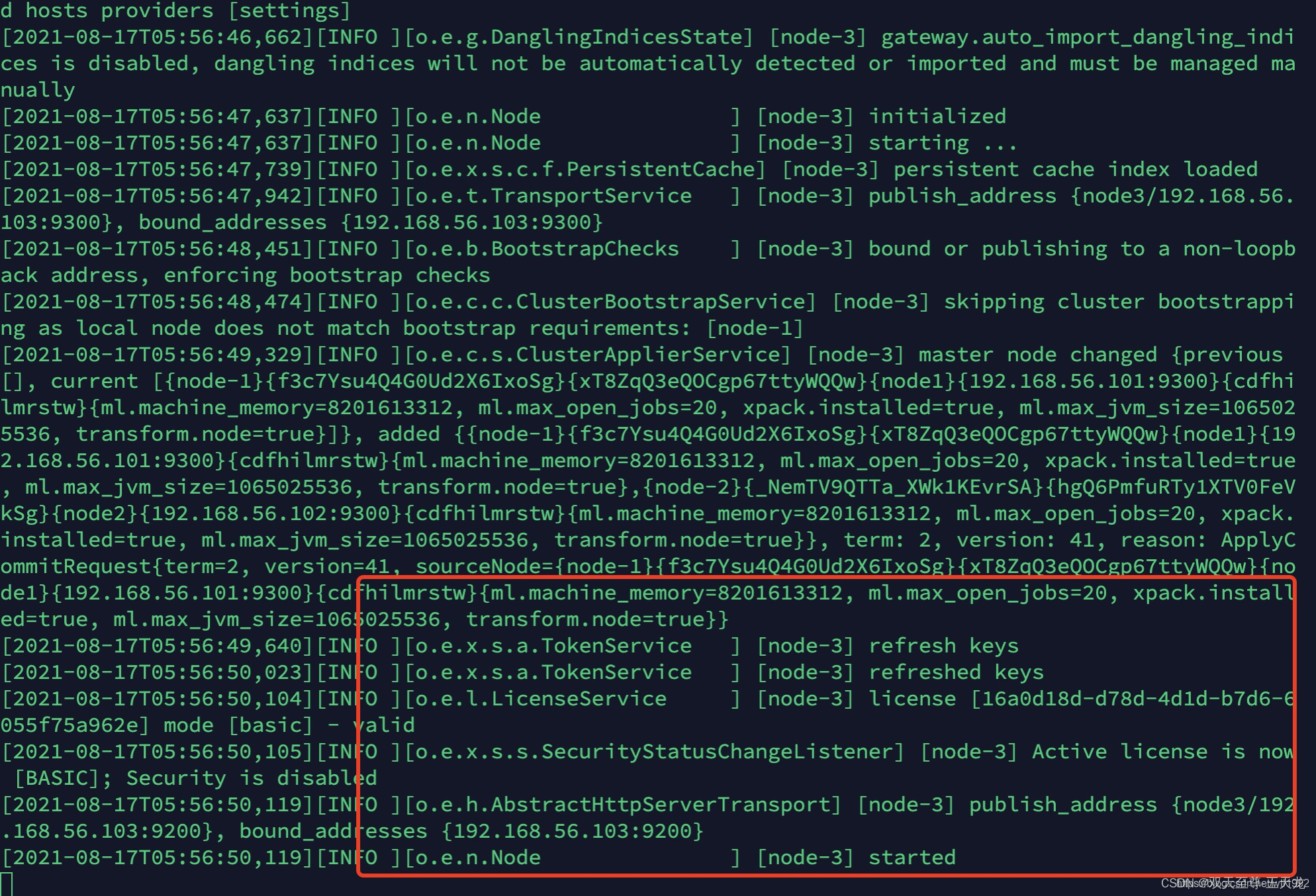
验证集群是否成功:
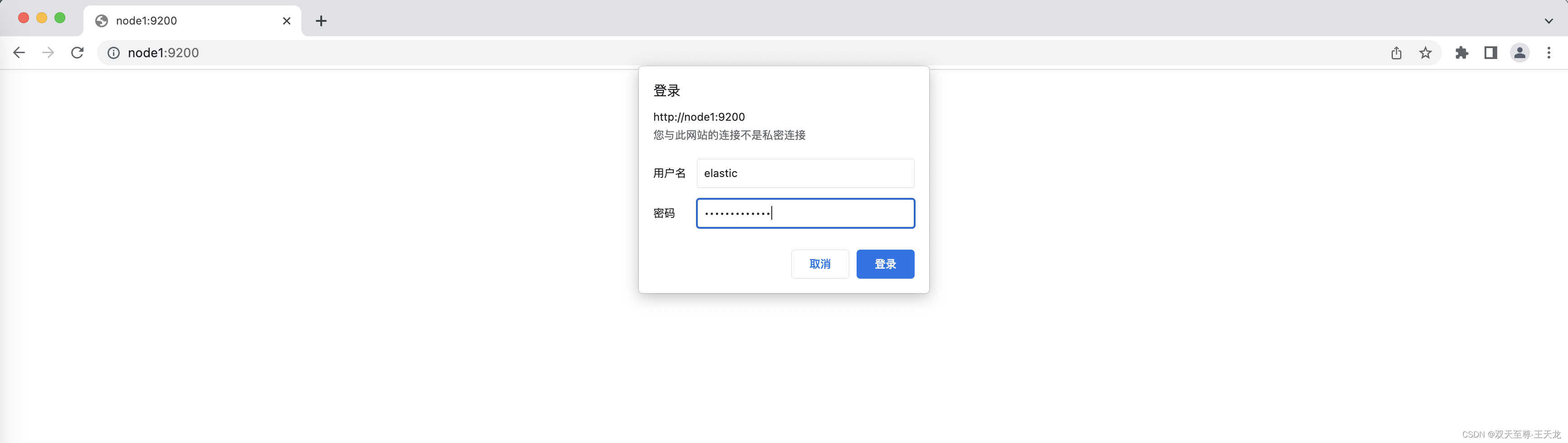

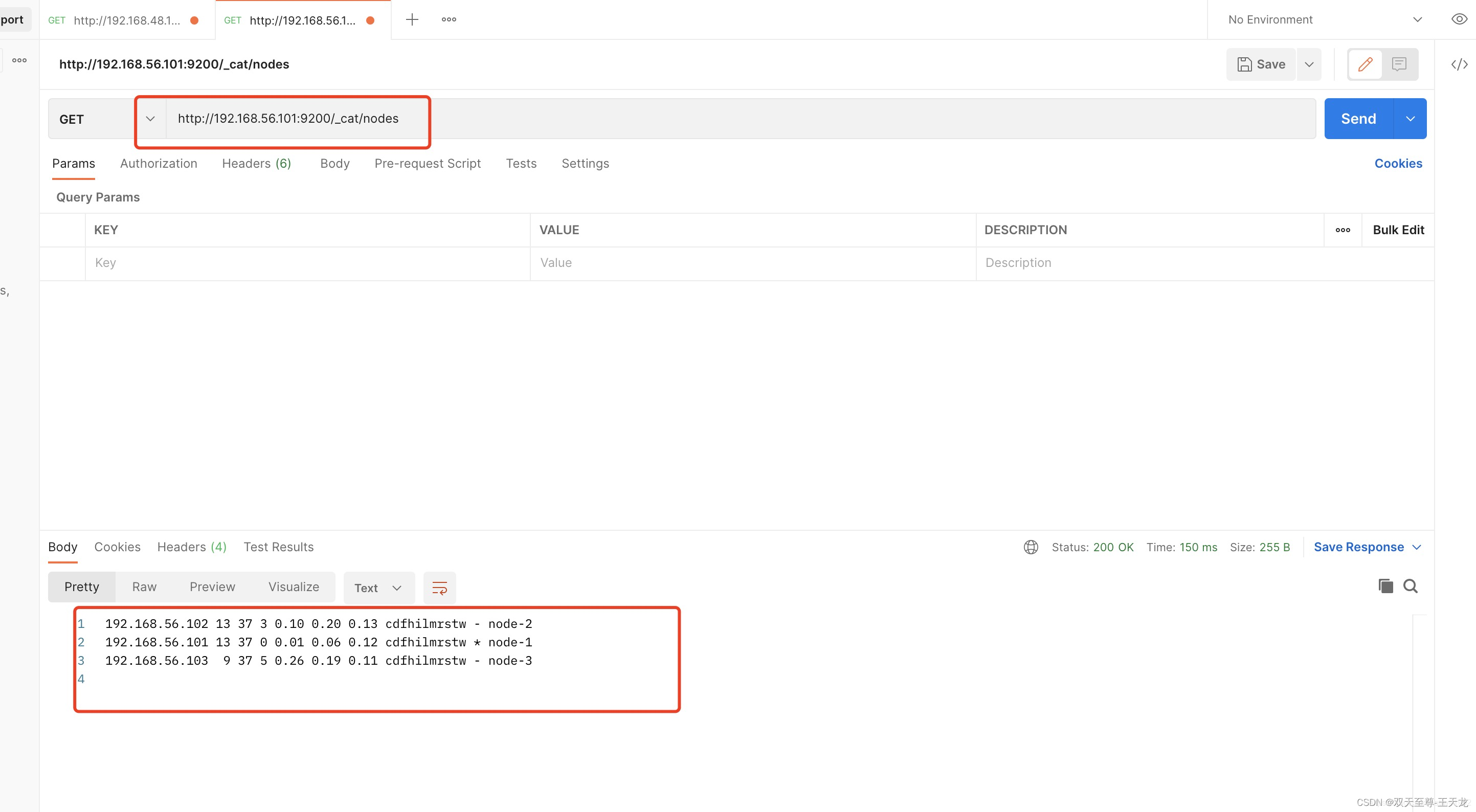
Head插件的安装:
使用chrome的插件进行使用!!!

版权归原作者 双天至尊-王天龙 所有, 如有侵权,请联系我们删除。