
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
逻辑回归、支持向量机等机器学习算法可以对二元数据集进行分类,但是无法处理超过 2 个目标类标签的多类分类任务。对于多类分类或多标签分类任务,我们需要使用某些技巧或者其他机器学习算法来训练数据集。

One-vs-One 和 One-vs-Rest 是两种可以处理多类或多标签分类任务的技术。One-vs-Rest 分类器为目标类标签总数为“c”的数据训练“c”个分类器,每个分类器只适配一个类并将所有其他类分成其他类(变成二分类)。而One-vs-One分类器为每个类训练匹配一个分类器。在预测时进行投票,收到最多投票的类就是输出。Error-correcting output code(ECOC) 与 OvO 和 OvR 分类器有很大不同。在本文中,我们将讨论 ECOC 的内部工作原理以及如何使用它来训练多类分类任务的模型。
如果对One-vs-One 和 One-vs-Rest 不太了解,请先查看本文最后提供的Sklearn文档。
什么是ECOC?
ECOC,即Error Correcting Output Codes,这里暂时翻译成“纠错输出码”。它是一种最常用的MvM技术(many vs. many多对多),可以用来将 Multiclass Classification 问题转化为 Binary Classification 问题。
ECOC的思想是将机器学习问题看做数据通信问题,并采用纠错输出码对各类别进行编码,因此在分类过程中能够纠正某些二分器的错误输出,从而提高分类器的预测精度。
ECOC 将多类目标类标签预处理为二进制代码(0 和 1 的数组)。使用这种策略,目标类标签在二进制代码的欧几里得空间中表示,并使用码表来记录编码的对应关系。
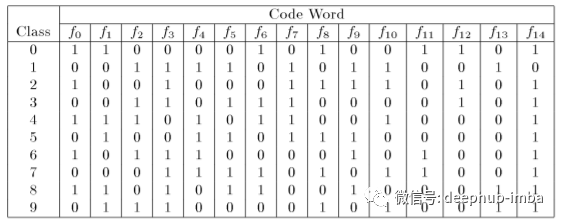
上图显示了 10 类目标标签的 15 位编码。每个目标标签都分配有唯一的 15 位编码。码表矩阵可以记录每个目标类的位编码。
开发人员可以控制位编码的维度。如果位编码的维数大于目标类标签的基数,那么一些分类器的预测可以被其他分类器纠正。在这种情况下,要训练的分类器数量会比 One-vs-Rest 多。
如果我们保持位编码的维度小于目标类标签的基数,那么它训练的分类器比 one-vs-rest 分类器少。理论上,log2(n_classes) 足以明确表示目标类标签。对于 10 类目标标签 log2(10)=4 就可以了。
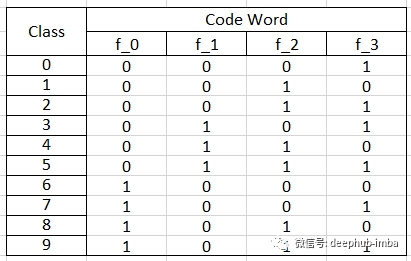
在对目标类标签进行d维编码后,需要匹配数量为' d '个的分类器,每个编码位对应一个二元分类器。在预测时,利用分类器在类空间中投影新点,并选择最接近点的类。
代码实现
Scikit-learn包附带了一个OutputCodeClassifier()函数,它用一行Python代码提供了ECOC分类器的实现。参数code_size可用于确定目标类的位编码。0到1之间的值可以用来压缩模型,或者code_size > 1可以使模型对于错误更加健壮。
code_size是一个超参数,可以进行调优:
0 < code_size < 1:训练一个压缩模型,其中拟合的估计器数量小于One-vs-Rest分类器的情况。
code_size>1:训练一个能够进行错误修正模型,对错误更加健壮。所拟合的估计量比在one vs- rest分类器的情况下要多。
from sklearn.linear_model import LogisticRegression
from sklearn.multiclass import OutputCodeClassifier
model = LogisticRegression(random_state=42)
ecoc = OutputCodeClassifier(model, code_size=5, random_state=42).fit(X_train, y_train)
y_pred = ecoc.predict(X_test)
可以对超参数code_size进行调优,以更改目标类嵌入的维度。我使用OutputCodeClassifier训练了一个20类分类数据集,并用Logistic回归模型作为基本分类器。
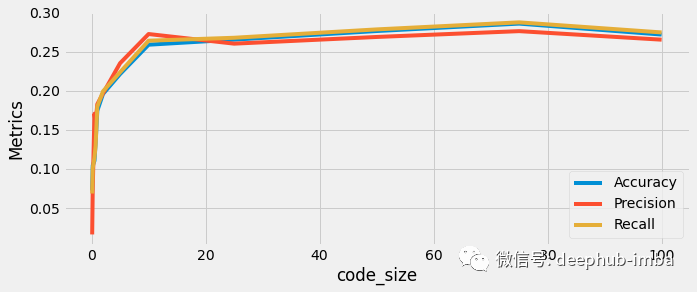
从上面的分布图中,我们可以观察到性能指标的增加,然后趋于平缓。代码大小= 10的值可以看作是一个阈值。对于代码大小= 10,我们得到了25.9%的准确率,27.3%的精度和26.5%的召回率。进一步增加嵌入维数对模型的性能没有影响。
总结
OutputCodeClassifier是一个方便的函数,用于适应实现ECOC算法进行多分类任务。我们可以控制分类器的数量,这是相对于One-vs-One或One-vs-Rest技术的一个额外优势(在这些技术中,分类器的数量依赖于目标类的基数)。
模型的性能取决于基本分类器的数量。理论上,log2(n_classes)足以明确地表示目标类,但它可能不会产生一个健壮的模型,因此我们需要增加它大小以便训练出更健壮的模型。
最后Sklearn文档如下:
https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OutputCodeClassifier.html
https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsOneClassifier.html
https://scikit-learn.org/stable/modules/generated/sklearn.multiclass.OneVsRestClassifier.html
作者:Satyam Kumar
喜欢就关注一下吧:
点个 在看 你最好看!********** **********