
背景:
根据甲方要求,需要对大数据平台指定表(hive、impala表)的历史数据[2021-01-01至2023-03-29]指定字段进行批量更新,然后把表同步到Oracle。先更新大数据平台上的表,再把更新完成的表同步到Oracle。hive有8张表更新,其中4张大表【分区表】(数据量分别为:1038738976、260958144、25860509、2867005),另外4张小表(几万、二十几万的样子)。4张小表使用kettle直接全量同步到Oracle,另外4张大表数据量很大,使用kettle同步的话,时间也会很久而且不一定能成功,所以我决定在Oracle上直接更新。查看Oracle更新(牵涉7张表,其中4张表数据量少,几万二十几万的样子;3张数据量大),3张生产环境表(表1:136327470;表2:32311563;表3:2757935)高达亿级的数据量,需要更新的数据也有上亿、千万、百万,还需要连表查询。
开始使用update 语句直接更新的时候发现,50分钟都未能更新完成,使用了merge 后,速度有很大提升。
第一种情况:全删全插
1、备份数据
先备份表数据,以免删错数据:
create table 表名_bak_日期 as select * from 表名;
2、删除数据
三种方法:删除表(记录和结构)的语句delete、truncate、drop
drop命令
drop table 表名;
例如:删除学生表(student)
drop table student;注意:用drop删除表数据,不但会删除表中的数据,连结构也会被删除!!!
truncate命令
truncate table 表名;
例如:删除学生表(student)
truncate table student;注意:
1、用truncate删除表数据,只是删除表中的数据,表结构不会被删除!
2、删除整个表的数据时,过程是系统一次性删除数据,效率比较高
3、truncate删除释放空间
delete命令
delete from 表名;
例如:删除学生表(student)
delete from student;注意:
1、用delete删除表数据,只是删除表中的数据,表结构不会被删除!
2、虽然也是删除整个表的数据,但是过程是系统一行一行的删,效率比truncate低
3、delete删除是不释放空间的
Truncate总结
- truncate table在功能上与不带where子句的delete语句相同:二者均删除表中的全部行。
- 但truncate比delete速度快,且使用的系统和事务日志资源少。
- delete语句每次删除一行,并在事务日志中为所删除的每行记录一项。所以可以对delete操作进行rollback。
1、truncate在各种表上无论是大的还是小的都非常快。如果有rollback命令delte将被撤销,而truncate则不会被撤销。
2、truncate是一个DDL语言,向其他所有的DDL语言一样,他将被隐式提交,不能对truncate使用rollback命令。
3、truncate将重新设置高水平线和所有的索引。在对整个表和索引进行完全浏览时,经过truncate操作后的表比delete操作后的表要快得多。
4、truncate不能触发任何delete触发器。
5、当表被清空后表和表的索引将重新设置成初始大小,而delete则不能。
6、不能清空父表
3、插入数据
insert into 表名A select * from 表名B;
第二种情况:不删除数据直接更新表
方法一:update
update 表1 b set b.PROJECTBELONG = (select distinct a.PROJECTBELONG from 表2 a
where b.ROOT_ITEM_CODE = a.DESC1
)
where b.ROOT_ITEM_CODE in (select distinct a.DESC1 from 表2 a
);
上面的表1数据量275万条左右、表2数据量5万左右,说起来也不是特别大,但是这个语句执行起来特别的慢,我等了1个小时都没执行完,后来取消掉了更新。
建议:建索引稍微快一点。但我觉得不如merge into高效。
方法二:merge into
merge into 表1 t
using (select DESC1,PROJECTBELONG from 表2) s
on (t.ROOT_ITEM_CODE = s.DESC1
--如果表数据量大,可以按照某个特定字段更新,我这里是按月更新
AND t.DATE_MONTH = '2022-04'
)
when matched then
update set t.PROJECTBELONG = s.PROJECTBELONG;
4百万的数据更新用时:1m31s
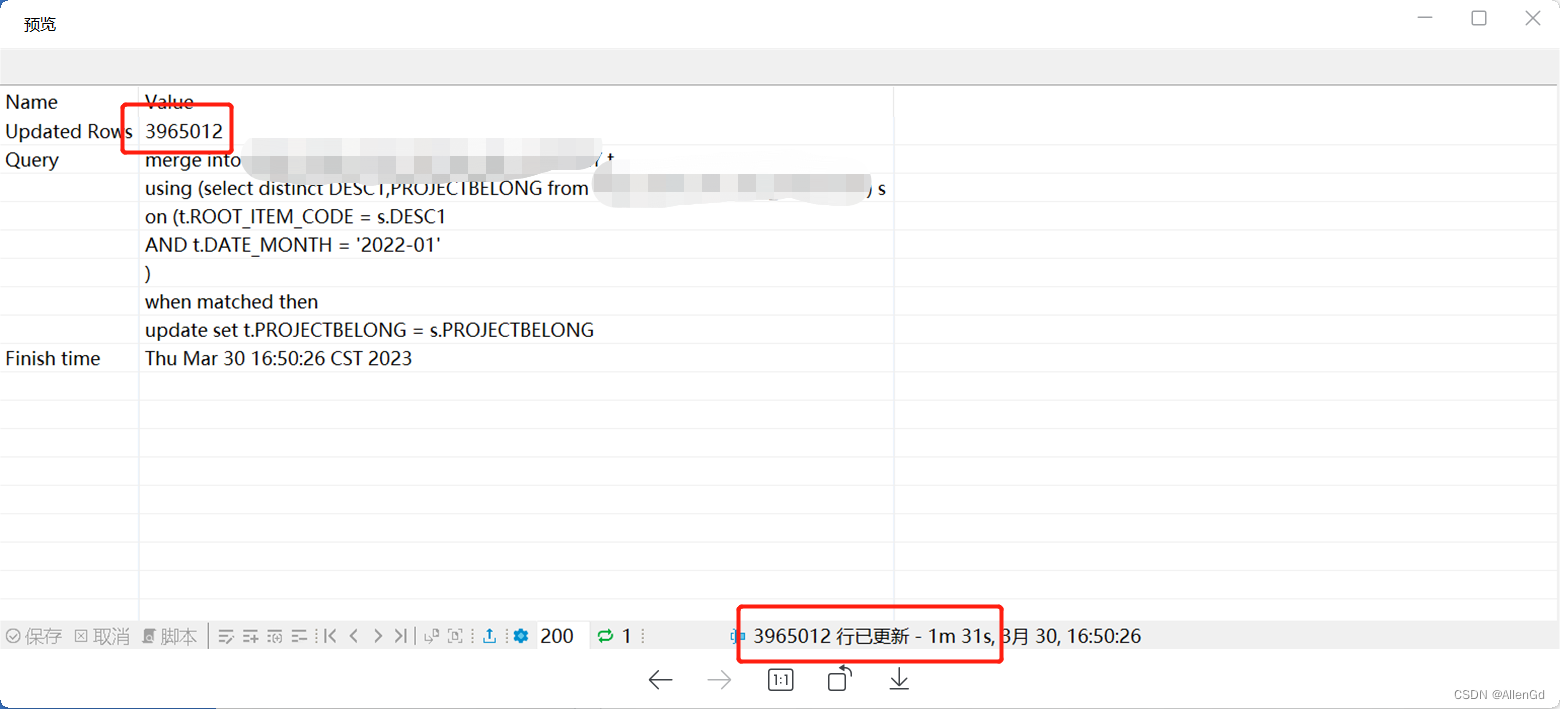
补充:when matched then 还支持insert ,可以通过此sql 实现“存在即更新,不存在则插入”批量操作,可以大大减少数据库链接操作。
版权归原作者 AllenGd 所有, 如有侵权,请联系我们删除。