

**个人简介: **
📦个人主页:赵四司机
🏆学习方向:JAVA后端开发
⏰往期文章:SpringBoot项目整合微信支付
🔔博主推荐网站:牛客网 刷题|面试|找工作神器
📣种一棵树最好的时间是十年前,其次是现在!
💖喜欢的话麻烦点点关注喔,你们的支持是我的最大动力。
前言:
无论在哪个项目,使用延迟队列都需要很明确你使用它的意义以及消息执行的顺序,并且你还需要考虑如何确保数据能够正确被处理而不会丢失,在进行梳理过程中我就发现了一个漏洞会造成数据丢失,所以在这里我单独写一篇文章来说明一下这个漏洞及优化策略,假如你有更好的优化策略欢迎私信博主。
如果你想要一个可以系统学习的网站,那么我推荐的是牛客网,个人感觉用着还是不错的,页面很整洁,而且内容也很全面,语法练习,算法题练习,面试知识汇总等等都有,论坛也很活跃,传送门链接:牛客刷题神器
一:回顾梳理
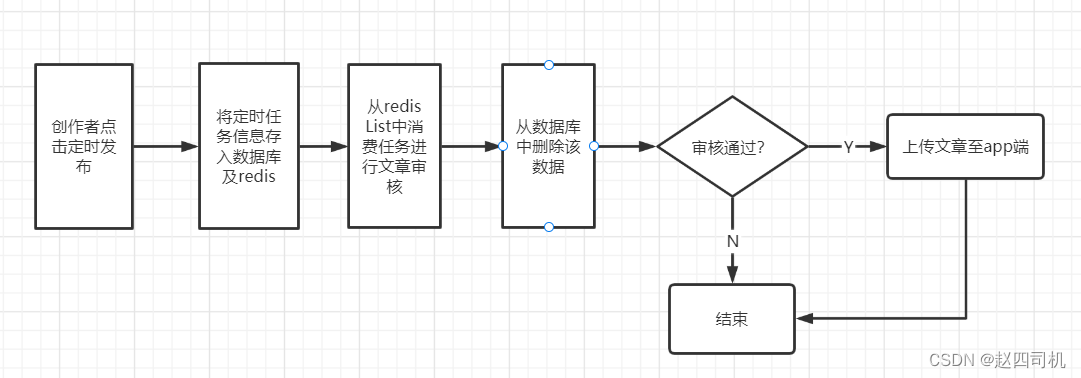
1.流程图
完成前面的操作之后,使用延迟队列定时提交文章功能就算完成了。在测试过程中我发现一个问题,虽然数据做了持久化处理,但是当每次消费任务之后数据库中该条数据也会随之被清理掉,这时候还会存在数据丢失的风险。为什么这么说呢,我们的定时发布是按照下面的流程图进行的:
2.代码
对应的代码如下:
@Autowired
private WmNewsAutoScanServiceImpl wmNewsAutoScanService;
/**
* 消费延迟队列数据
*/
@Scheduled(fixedRate = 1000)
@Override
@SneakyThrows
public void scanNewsByTask() {
ResponseResult responseResult = scheduleClient.poll(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType(), TaskTypeEnum.NEWS_SCAN_TIME.getPriority());
if(responseResult.getCode().equals(200) && responseResult.getData() != null){
log.info("文章审核---消费任务执行---begin---");
String json_str = JSON.toJSONString(responseResult.getData());
Task task = JSON.parseObject(json_str, Task.class);
byte[] parameters = task.getParameters();
WmNews wmNews = ProtostuffUtil.deserialize(parameters, WmNews.class);
System.out.println(wmNews.getId()+"-----------");
wmNewsAutoScanService.autoScanWmNews(wmNews.getId());
log.info("文章审核---消费任务执行---end---");
}
}
/**
* 删除任务,更新日志
* @param taskId
* @param status
* @return
*/
private Task UpdateDb(long taskId, int status) {
Task task = null;
try {
//1.删除任务
log.info("删除数据库中的任务...");
taskInfoMapper.deleteById(taskId);
//2.更新日志
log.info("更新任务日志...");
TaskinfoLogs taskinfoLogs = taskInfoLogsMapper.selectById(taskId);
taskinfoLogs.setStatus(status);
taskInfoLogsMapper.updateById(taskinfoLogs);
//3.设置返回值
task = new Task();
BeanUtils.copyProperties(taskinfoLogs,task);
task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime());
} catch (BeansException e) {
throw new RuntimeException(e);
}
return task;
}
/**
* 消费任务
* @param type 任务类型
* @param priority 任务优先级
* @return Task
*/
@Override
public Task poll(int type, int priority) {
Task task = null;
try {
String key = type + "_" + priority;
String task_json = cacheService.lRightPop(ScheduleConstants.TOPIC + key);
if(StringUtils.isNotBlank(task_json)) {
task = JSON.parseObject(task_json,Task.class);
//更新数据库
UpdateDb(task.getTaskId(),ScheduleConstants.EXECUTED);
}
} catch (Exception e) {
e.printStackTrace();
log.error("poll task exception");
}
return task;
}
可以看到在redis中获取数据之后便将数据从数据库中删除,这时候假如后面的审核流程出现问题或者保存文章时候移动端微服务出现故障导致文章不能保存,而这时候数据库中及redis中的数据都删除了,这就造成了数据的丢失。
二:第一次优化
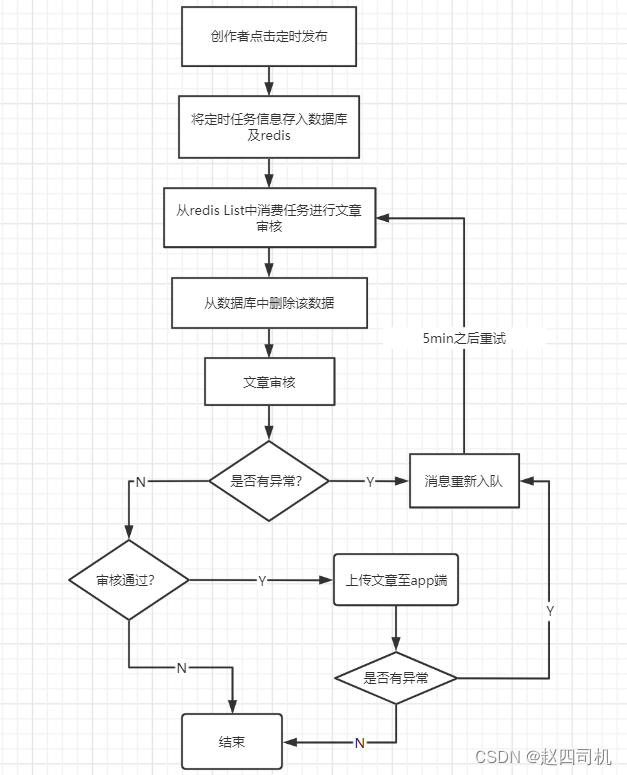
1.优化策略
首先我想到的优化策略是当检测到文章审核或者文章保存值移动端有异常时候就将已经出队列的数据重新放回队列并且在5分钟之后再进行消费直到消费成功,流程图见下图:
2.代码实现
WmAutoScanServiceImpl
package com.my.wemedia.service.impl;
@Slf4j
@Service
@Transactional
public class WmAutoScanServiceImpl implements WmAutoScanService {
@Autowired
private WmNewsService wmNewsService;
@Autowired
private TextDetection textDetection;
@Autowired
private ImageDetection imageDetection;
/**
* 自动审核文章文本及图片
* @param id
*/
@Override
@Async
public void AutoScanTextAndImage(Integer id) throws Exception {
log.info("开始进行文章审核...");
// Thread.sleep(300); //休眠300毫秒,以保证能够获取到数据库中的数据
WmNews wmNews = wmNewsService.getById(id);
if(wmNews == null) {
throw new RuntimeException("WmAutoScanServiceImpl-文章信息不存在");
}
if(wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())) {
//中间步骤省略
//4,审核成功
//4.1保存文章
log.info("检测到文章无违规内容");
ResponseResult responseResult = saveAppArticle(wmNews);
if(!responseResult.getCode().equals(200)) {
throw new RuntimeException("AutoScanTextAndImage--检测失败");
}
}
}
/**
* 保存App端文章数据
* @param wmNews
* @return
*/
@Override
public ResponseResult saveAppArticle(WmNews wmNews) {
//中间步骤省略
//7.保存App端文章
log.info("异步调用保存文章至App端");
ResponseResult responseResult = null;
try {
responseResult = iArticleClient.saveArticle(articleDto);
} catch (Exception e) {
responseResult = new ResponseResult(AppHttpCodeEnum.SERVER_ERROR.getCode(),"保存文章至App失败");
}
return responseResult;
}
}
WmNewsTaskServiceImpl
@Autowired
private WmAutoScanService wmAutoScanService;
@Autowired
private CacheService cacheService;
/**
* 消费任务
*/
@Override
@Scheduled(fixedRate = 2000) //每两秒执行一次
public void scanNewsByTask() {
ResponseResult responseResult = scheduleClient.poll(TaskTypeEnum.NEWS_SCAN_TIME.getTaskType(), TaskTypeEnum.NEWS_SCAN_TIME.getPriority());
if(responseResult.getCode().equals(200) && responseResult.getData() != null) {
log.info("文章审核---消费任务执行---begin");
String json_str = JSON.toJSONString(responseResult.getData());
Task task = JSON.parseObject(json_str,Task.class);
byte[] parameters = task.getParameters();
//反序列化
WmNews wmNews = ProtostuffUtil.deserialize(parameters, WmNews.class);
try {
wmAutoScanService.AutoScanTextAndImage(wmNews.getId());
} catch (Exception e) {
log.warn("审核失败,将于5分钟之后再次尝试");
//文章未能成功审核,将数据加入ZSet,5分钟之后再重新尝试
//1.构造key
String key = task.getTaskType() + "_" + task.getPriority();
//2.获取5分钟之后的时间
Calendar calendar = Calendar.getInstance();
calendar.add(Calendar.MINUTE,5);
long nextScheduleTime = calendar.getTimeInMillis();
//3.将数据重新加入
cacheService.zAdd(ScheduleConstants.FUTURE + key,JSON.toJSONString(task),nextScheduleTime);
e.printStackTrace();
}
log.info("文章审核---消费任务执行---end");
}
3.遇到的问题
这时候虽然做了优化,但是在实际运行时候 WmNewsTaskServiceImpl中的try-catch并没有发挥作用,我没有开启移动端微服务,在审核时候也抛出了异常,但是这时候WmNewsTaskServiceImpl中并没有catch到这个异常。这是为什么呢,通过断点发现在执行到AutoScanTextAndImage方法时候,程序便直接跳出了catch块,这时候便想到前面我们还没有引入延迟队列时候用的是异步方法来调用文本图片审核方法来进行审核,而且当时还出现了在数据库中获取不到数据的问题,现在想起这就是因为采用了异步调用才引起的。在这里也一样,由于在AutoScanTextAndImage方法前面添加了@Async注解,表明这是一个异步方法,这时候我们在 WmNewsTaskServiceImpl中调用该方法时候是异步执行的,这当然就捕获不到抛出的异常,因需要将该方法的@Async注解去掉,改成同步调用。
三:第二次优化
1.问题引入
问题一:
解决完上面的问题,看着似乎问题得到了解决,消息没有正确被消费时候会被重新投递回去直到被正确消费,但是这时候还应该注意到另外一个问题。虽然消息消费失败之后被重新投递了,但是这时候数据库中的数据已经被删除掉了,假如redis服务器出现了问题,这时候就算你采用了重回队列策略数据还是永久丢失了,因为你的持久化处理在这时候已经失效了。这时候可以考虑失败之后将数据再存回数据库中,这样再次做了持久化处理,但是这样显然会造成不必要的IO操作。
问题二:
前面的做法是将审核的方法由异步改成了同步,这时候由于调用的是第三方的审核接口,有时候难免会因为网络等原因造成审核时间很长,这时候假如采用同步策略,就会造成长时间阻塞,影响用户体验,同时也会浪费大量资源。
2.解决策略
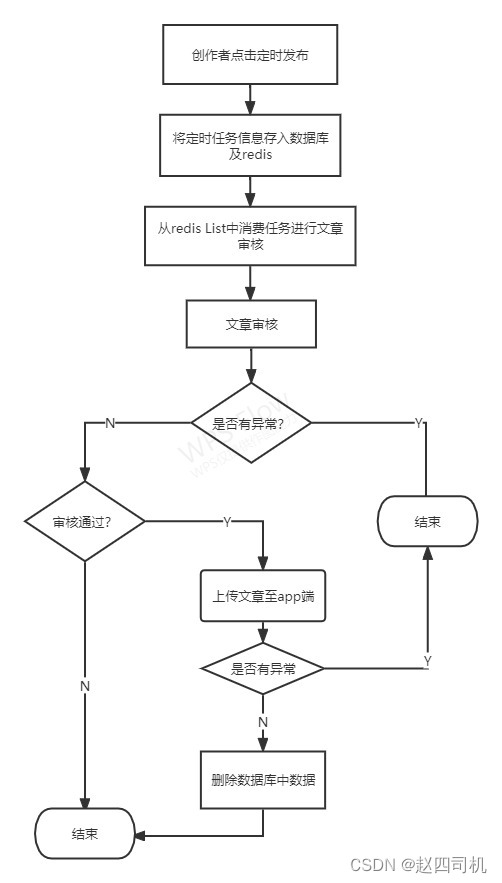
- 针对问题一,我认为在一开始对队列消息进行消费时候就不应该立马删除数据库中的数据,而是等到最后确保消息被正确处理之后再删除数据库中相应的数据。
- 针对问题二,我认为不应该将审核方法由异步改成同步,但是这时候就会出现前面提到的问题----catch不到异常,这时候似乎又回到了起点。试想,我们使用这个异常捕获的目的是什么?我们的目的就是为了出现异常时候将消息重新入队防止数据丢失,这时候我们不妨换一种策略,前面提到了我们在确保消息被正确消费之后再删除数据库中的数据,这不就已经解决了问题了吗?我们会定时同步数据库中的数据到redis,这时候就算消息在redis中丢失了也没关系,只要数据库中的数据还在就行。
流程图见下图:
3.代码实现
①在tbug-headlines-feign-api模块的IScheduleClient接口中添加如下内容:
/**
* 删除数据库中的任务,更新日志
* @param taskId
*/
@DeleteMapping("/api/v1/task/delete/{taskId}/{status}")
void updateDb(@PathVariable("taskId") Long taskId, @PathVariable("status") Integer status);
②在package com.my.schedule.feign中更新该接口的实现类
/**
* 删除数据库中任务,更新日志
* @param taskId
*/
@Override
@DeleteMapping("/api/v1/task/delete/{taskId}/{status}")
public void updateDb(@PathVariable("taskId")Long taskId, @PathVariable("status") Integer status) {
taskService.UpdateDb(taskId,status);
}
③在TaskService中增加UpdateDb(long taskId, int status)方法,将实现类中该方法权限设置为public
TaskService
/**
* 删除数据库任务并更新日志
* @param taskId
* @param status
* @return
*/
Task UpdateDb(long taskId, int status);
Impl
/**
* 删除任务,更新日志
* @param taskId
* @param status
* @return
*/
public Task UpdateDb(long taskId, int status) {
Task task = null;
try {
//1.删除任务
log.info("删除数据库中的任务...");
taskInfoMapper.deleteById(taskId);
//2.更新日志
log.info("更新任务日志...");
TaskinfoLogs taskinfoLogs = taskInfoLogsMapper.selectById(taskId);
taskinfoLogs.setStatus(status);
taskInfoLogsMapper.updateById(taskinfoLogs);
//3.设置返回值
task = new Task();
BeanUtils.copyProperties(taskinfoLogs,task);
task.setExecuteTime(taskinfoLogs.getExecuteTime().getTime());
} catch (BeansException e) {
throw new RuntimeException(e);
}
return task;
}
④修改taskServiceImpl中的poll方法
/**
* 消费任务
* @param type 任务类型
* @param priority 任务优先级
* @return Task
*/
@Override
public Task poll(int type, int priority) {
Task task = null;
try {
String key = type + "_" + priority;
String task_json = cacheService.lRightPop(ScheduleConstants.TOPIC + key);
if(StringUtils.isNotBlank(task_json)) {
task = JSON.parseObject(task_json,Task.class);
//更新数据库 (抛弃该策略)
// UpdateDb(task.getTaskId(),ScheduleConstants.EXECUTED);
//接口幂等性
TaskinfoLogs taskinfoLogs = taskInfoLogsMapper.selectById(task.getTaskId());
//获取任务状态
if(taskinfoLogs != null) {
Integer status = taskinfoLogs.getStatus();
if(ScheduleConstants.EXECUTED == status) {
return null;
}
}
}
} catch (Exception e) {
e.printStackTrace();
log.error("poll task exception");
}
return task;
}
这里主要修改了两点:
- 抛弃原来直接调用方法删除数据库中的任务的策略
- 增加接口幂等性,假如该任务已经被成功执行但是并没有在数据库中删除该任务,那么第二次执行该任务时候假如判断到该任务已经执行过则直接返回null不做处理。
⑤修改自动审核方法
@Autowired
private IScheduleClient scheduleClient;
/**
* 自动审核文章文本及图片
* @param id
*/
@Override
@Async
public void AutoScanTextAndImage(Integer id,Long taskId) throws Exception {
log.info("开始进行文章审核...");
// Thread.sleep(300); //休眠300毫秒,以保证能够获取到数据库中的数据
WmNews wmNews = wmNewsService.getById(id);
if(wmNews == null) {
throw new RuntimeException("WmAutoScanServiceImpl-文章信息不存在");
}
if(wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())) {
//1.提取文章文本及图片
Map<String,Object> map = getTextAndImages(wmNews);
//2.检测文本
//2.1提取文本
String content = ((StringBuilder) map.get("content")).toString();
//2.2自管理敏感词过滤
boolean SHandleResult = handleSensitiveScan(content,wmNews);
if(!SHandleResult) return;
//2.3调用腾讯云进行文本检测
Boolean THandleResult = handleTextScan(content, wmNews);
if(!THandleResult) return;
//3.检测图片
//3.1提取图片
List<String> imageUrl = (List<String>) map.get("images");
//3.2调用腾讯云对图片进行检测
Boolean IHandleResult = handleImageScan(imageUrl, wmNews);
if(!IHandleResult) return;
//4,审核成功
//4.1保存文章
log.info("检测到文章无违规内容");
ResponseResult responseResult = saveAppArticle(wmNews);
if(!responseResult.getCode().equals(200)) {
throw new RuntimeException("AutoScanTextAndImage--检测失败");
}
//4.2回填article_id
wmNews.setArticleId((Long) responseResult.getData());
wmNews.setStatus(WmNews.Status.PUBLISHED.getCode());
wmNews.setReason("审核成功");
wmNewsService.updateById(wmNews);
//删除数据库中的任务并更新日志
scheduleClient.updateDb(taskId, ScheduleConstants.EXECUTED);
}
}
至此关于延迟任务的数据优化部分就完成了,后续有什么问题会再进行优化。
下篇预告:App端文章搜索
友情链接: 牛客网 刷题|面试|找工作神器
本文转载自: https://blog.csdn.net/weixin_45750572/article/details/126453285
版权归原作者 赵四司机 所有, 如有侵权,请联系我们删除。
版权归原作者 赵四司机 所有, 如有侵权,请联系我们删除。