
1、顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能,顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写。
2、零拷贝
Kafka高吞吐量的原因其中有个重要技术就是Zero-Copy(零拷贝)系统调用机制
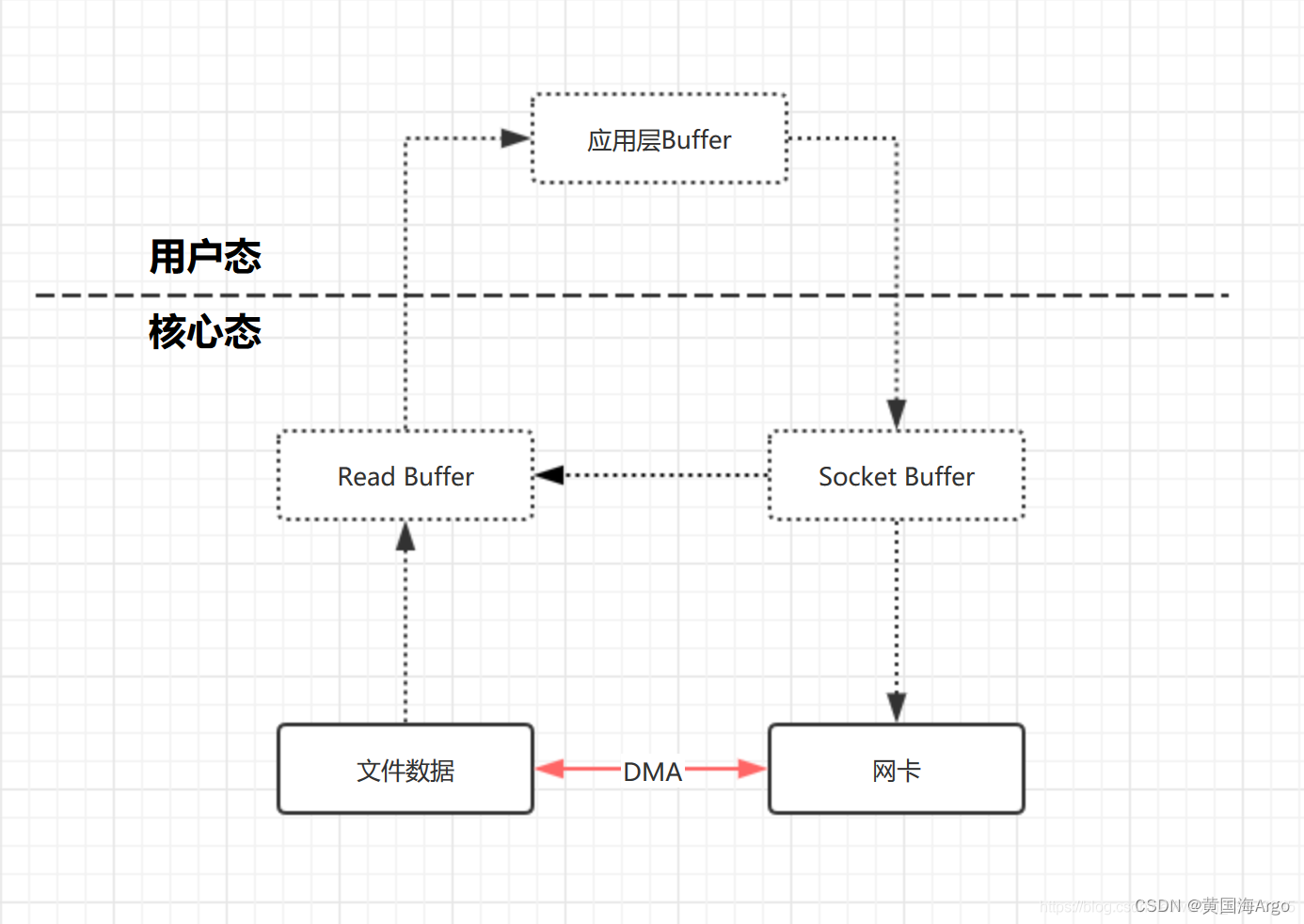
传统的文件拷贝

由于应用程序无法直接读取内核空间的数据,如果要读取这些数据,那么必须把数据从读取缓冲区拷贝到应用程序缓冲区
用户态把数据拷贝到核心态Socket Buffer,然后发送到网卡
DMA(Direct Memory Access)
Kafka引入DMA(Direct Memory Access)直接内存访问,一种可以让某些硬件子系统可以直接访问系统主内存,而不用依赖CPU调度,传统的内存访问都需要经过CPU的调度来完成的。
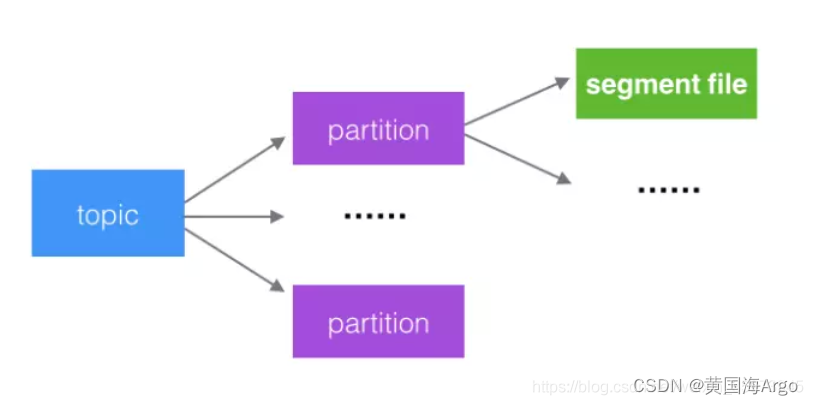
4、分区
kafka中的topic中的内容可以被分为多个partition,每个partition又分为多段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力。
5、批量发送
kafka允许进行批量发送消息,producer发送消息的时候,可以将消息缓存在本地,等到固定条件再发送到kafka
消息条数满足固定条数
一段时间发送一次数据压缩
kafka还支持对消息集合进行压缩,producer可以通过GZIP或Snappy格式对消息集合进行压缩,压缩的好处就是减少传输的数据量,减轻对网络传输的压力。
6、Kafka优化JVM GC
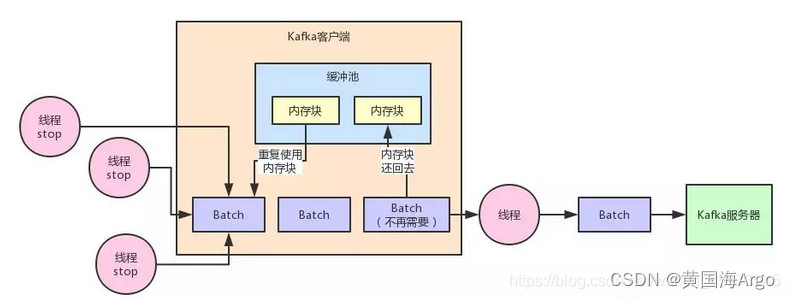
内存缓冲机制把多条消息组成一个Batch,一次网络请求就是一个Batch或者多个Batch,避免了一条消息一次网络请求,从而提升了吞吐量,但是由此带来一个问题,Batch数据发送完过后,Batch所占用JVM内存如何处理?
JVM GC在回收内存垃圾的时候,会有一个“stop the world”的过程,也就是垃圾回收线程运行的时候,会导致其他工作线程短暂的停顿,如何尽可能避免JVM频繁的GC?
为了避免内存缓冲机制造成频繁的GC,Kafka客户端内部实现了缓冲池机制。
简单来讲,就是每个Batch底层都对应一块内存空间,这个内存空间就是专门用来存放写入进去的消息,当每一个Batch被发送到了kafka服务器买这Batch的数据不再需要了,就意味着这个Batch的内存空间不再使用了,此时这个Batch底层的内存空间不要交给JVM去垃圾回收,而是把这块内存空间放入一个缓冲池里,这个缓冲池里放了很多内存空间,下一个Batch可以直接从这个缓冲池获取一块内存空间,以此类推,循环往复。
版权归原作者 慢一点,细一点 所有, 如有侵权,请联系我们删除。