
Flink SQL和Table API实现消费kafka写入mysql
1、构建****table环境
// 创建flink流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// table环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
2、构建source kafka
方式一:API
// Kafka连接器
Kafka kafka = new Kafka()
.version("0.10") // 指定Kafka的版本,可选参数包含"0.8", "0.9", "0.10", "0.11", 和 "universal","universal"为通用版本
.property("zookeeper.connect", "172.18.194.90:2181,172.18.194.91:2181,172.18.194.92:2181") // 指定Kafka集群关联的zookeeper集群的地址
.property("bootstrap.servers", "172.18.194.90:9092,172.18.194.91:9092,172.18.194.92:9092") // 指定Kafka broker的地址
.property("group.id", "testGroup") // 指定Kafka消费者的group id
.topic("test_huyj"); // 指定消费的topic的名字
// 指定数据结构
Schema schema = new Schema()
.field("opt","string")
.field("username", "string")
.field("password", "string");
tableEnv
.connect(kafka)//定义表的数据来源,和外部系统建立连接
.withFormat(new Json().failOnMissingField(false)) //定义数据格式化方法
.withSchema(schema) //定义表结构
.createTemporaryTable("user_table"); //创建临时表
Table user_table = tableEnv.from("user_table");//读临时表
user_table.printSchema();//打印表结构
DataStream<User> dataStream = tableEnv.toAppendStream(user_table, User.class);//转成流
dataStream.print();
方式二:Flink SQL
tableEnv.sqlUpdate( "CREATE TABLE user_table (\n" +
" opt string,\n" +
" username string,\n" +
" password string\n" +
") WITH (\n" +
" 'connector.type' = 'kafka', \n" + //-- 使用 kafka connector
" 'connector.version' = '0.10', \n" +//-- kafka 版本,universal 支持 0.11 以上的版本 -- 写universal报错,改成0.10
" 'connector.topic' = 'test_huyj', \n" +//-- kafka topic
" 'connector.startup-mode' = 'earliest-offset',\n" +
" 'connector.properties.0.key' = 'zookeeper.connect', \n" +//-- 连接信息
" 'connector.properties.0.value' = '172.18.194.90:2181,172.18.194.91:2181,172.18.194.92:2181', \n" +
" 'connector.properties.1.key' = 'bootstrap.servers',\n" +
" 'connector.properties.1.value' = '172.18.194.90:9092,172.18.194.91:9092,172.18.194.92:9092', \n" +
" 'update-mode' = 'append',\n" +
" 'format.type' = 'json', \n" +//-- 数据源格式为 json
" 'format.derive-schema' = 'true' \n" +//-- 从 DDL schema 确定 json 解析规则
")\n");
**3、构建sink mysql **
//构建sink方式1:直接执行flink sql构建sink mysql
tableEnv.sqlUpdate("CREATE TABLE mysqlOutput(\n"+
"opt string,\n" +
"username string,\n" +
"password string\n" +
") WITH (\n" +
"'connector.type'='jdbc',\n" +
"'connector.url'='jdbc:mysql://172.18.194.91:13306/huyj?useUnicode=true&characterEncoding=utf-8',\n" +
"'connector.table'='tb_user',\n" +
"'connector.driver'='com.mysql.jdbc.Driver',\n" +
"'connector.username'='root',\n" +
"'connector.password'='root'" +
")");
4、写入将source表写入sink表
方式一:API
user_table.insertInto("mysqlOutput");
方式二:Flink SQL
tableEnv.sqlUpdate("INSERT INTO mysqlOutput\n" +
"SELECT opt,username,password\n" +
"FROM user_table");
5、手动执行
env.execute("kafka2mysql");
6、测试
(1)连接kafka生产者
cd /realtime/kafkacluster/kafka_2.11-1.1.1/bin
sh kafka-console-producer.sh --broker-list 172.18.194.90:9092,172.18.194.91:9092,172.18.194.92:9092 --topic test_huyj
(2)造数据
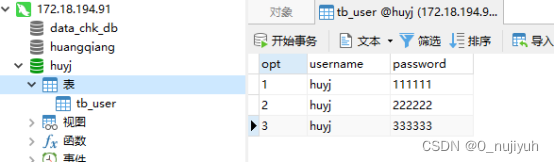
{"opt":"1","username":"huyj","password":"111111"}
{"opt":"2","username":"huyj","password":"222222"}
{"opt":"3","username":"huyj","password":"333333"}
(3)mysql查看入库情况
本文转载自: https://blog.csdn.net/weixin_45207751/article/details/131260716
版权归原作者 0_nujiyuh 所有, 如有侵权,请联系我们删除。
版权归原作者 0_nujiyuh 所有, 如有侵权,请联系我们删除。