
在我之前文章 “Elasticsearch:如何调试集群状态 - 定位错误信息” 中,我有详细介绍如何调试集群状态。在今天的文章中,我将详细介绍如何故障排除和修复索引状态。

Elasticsearch 是一个伟大而强大的系统,特别是创建一个可扩展性极强的分布式数据存储,并自动跟踪、管理和路由索引中的所有数据。
但有时事情会出错,索引会遇到或大或小的麻烦。 这通常最终会导致它们具有红色或黄色的状态。 集群将紧随其后,因为它的状态是所有索引中最差的,例如 如果一个索引为红色,则集群为红色。
如果你的集群和一些索引是红色或黄色的,你会怎么做? 那么,你需要找出原因。 你是怎样做的?
红色或黄色是什么意思?
首先,说一下颜色的含义,因为它们看起来很复杂,但最终很简单:
- 黄色 —— 一个或多个索引缺少(“未分配 - unassigned”)副本分片。 索引仍在工作,可以完全索引、搜索和提供数据,只是没有我们想要的那么快和可靠。
- 丢失的碎片可能真的丢失、损坏或有其他问题; 或者集群可能正处于移动或重建这些丢失的分片的过程中。
- 我们的工作是手动或自动重新创建这些丢失的副本以达到绿色。
- 红色 —— 一个或多个索引缺少主分片并且无法正常工作,即它无法索引、搜索或提供数据。
- 请注意,这是基于每个分片的,因此即使有 50 个分片,也只需要一个分片失效即可将索引和集群变为红色。
- 我们的工作是手动查找或修复这些缺失的主索引,如果可以的话,否则索引就会丢失,必须从快照或原始源数据中重新创建。
查找红色和黄色索引
- 第一步是确定你知道的主要问题,例如死节点、磁盘空间问题等可能产生问题的问题。 这有助于告知我们寻找什么以及我们以后如何修复它。
有时你只需要耐心等待,因为系统通常会通过移动数据来修复自身,例如将副本提升为主要副本,然后重新创建新副本,但这需要时间,从几分钟到更长,具体取决于分片数量和大小, 集群负载、磁盘速度等。
但你不能指望这一点,除非很明显系统正在自我修复。 有时事情真的坏了,这就是为什么了解历史是件好事,因为重启节点肯定会使一些索引变黄,但几分钟后又变绿。
- 第二步是确定哪些索引有问题,有多少索引有问题。 _cat API 可以通过状态告诉我们:
GET /_cat/indices?v&health=red
GET /_cat/indices?v&health=yellow
从中我们可以了解我们有多少问题,这可能与上面讨论的任何最近事件有关。 我们还需要这个列表,以便我们可以更深入地挖掘每个索引。
- 第三步是查看哪些分片有问题以及原因。 这与索引列表有关,但索引列表只会告诉你哪些索引有问题,现在我们需要每个分片的问题列表。
我们为此使用 _cat 接口,理想情况下使用排序和一些额外的列,例如这将列出按状态排序的索引,包括未分配的基本原因 - 查找 UNASSIGNED 状态:
GET /_cat/shards?v&h=n,index,shard,prirep,state,sto,sc,unassigned.reason,unassigned.details&s=sto,index
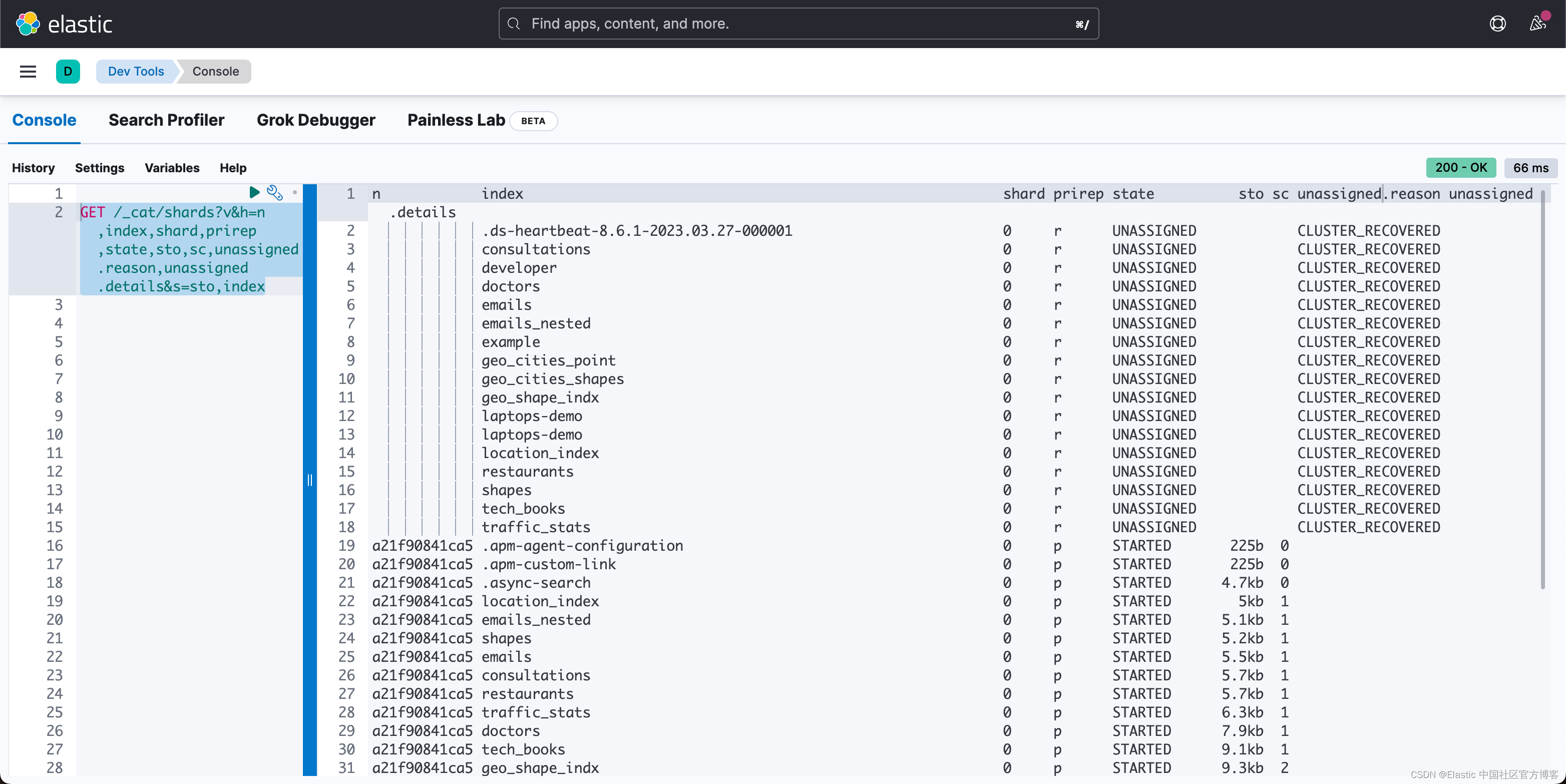
这可能足以了解正在发生的事情,其中有未分配的详细信息列,我们可以从中解决问题。 但有时我们需要更多细节,特别是当我们有节点路由或其他更复杂的问题时。
我们可以询问集群为什么分片没有分配 …
为此,我们可以要求集群解释给定分片的当前分配情况和逻辑。 这有点混乱,因为我们需要上面列表中的两个分片编号(从 0 开始),并且要知道我们是否要查看主分片或副本,同样来自上面的列表。
API 调用是这样的,这里需要设置索引名,分片号,primary true/false:
GET _cluster/allocation/explain
{
"index": ".ds-heartbeat-8.6.1-2023.03.27-000001",
"shard": 0,
"primary": true
}
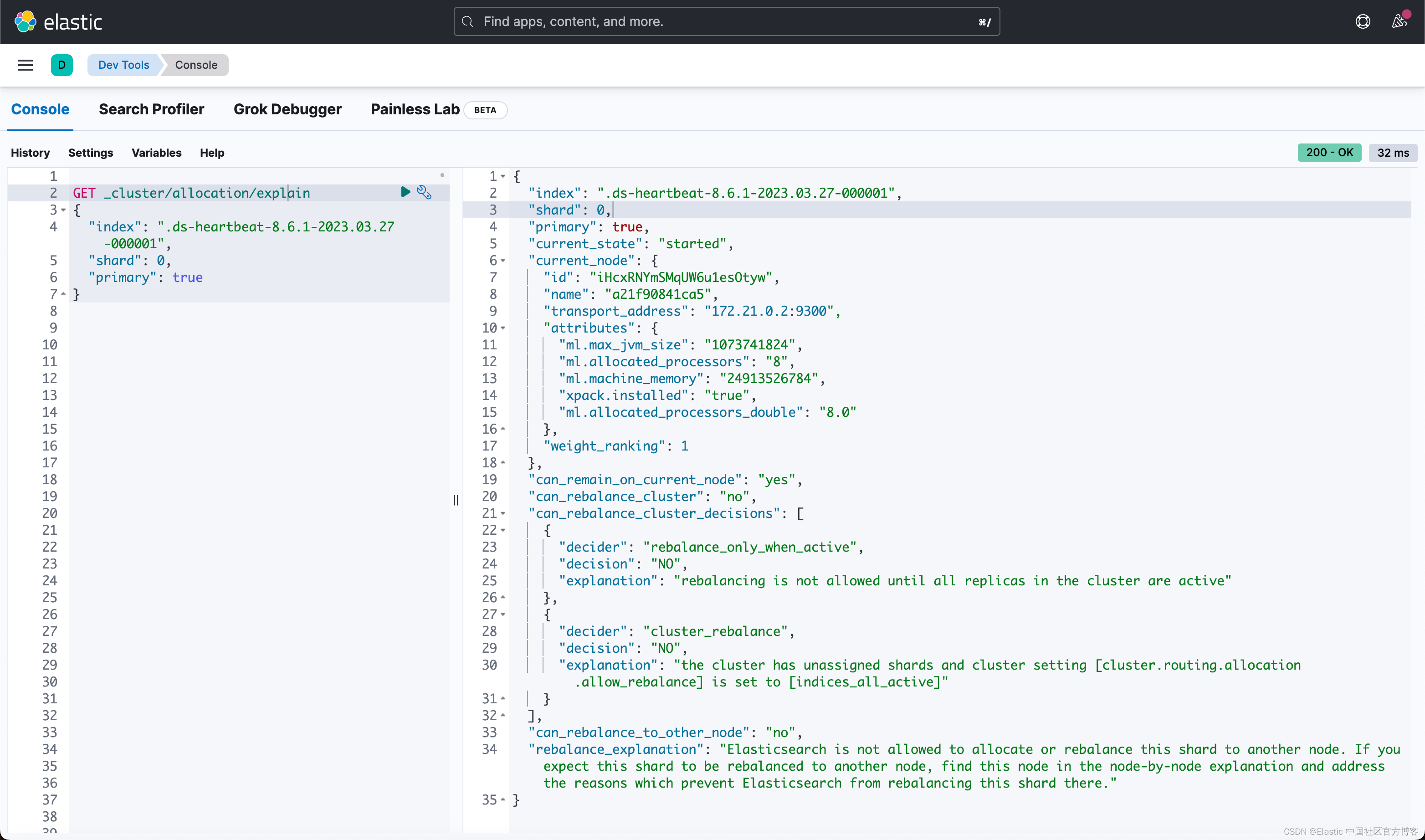
这将使您更详细地了解情况,接下来要做什么取决于您在那里找到的原因。
一些常见问题包括:
- 磁盘空间不足 —— 没有空间可以分配。请详细阅读文章 “Elasticsearch:Low disk watermark”。
- 分片计数限制 —— 每个节点的分片太多,这在创建新索引或删除某些节点并且系统无法为它们找到位置时很常见。
- JVM 或堆限制 —— 一些版本可以在 RAM 不足时限制分配
- 路由或分配规则 —— 常见的 HA(Highly Available)云或大型复杂系统
- 损坏或严重问题 —— 可能会出现更多问题,每个问题都需要特别注意或解决方案,或者在许多情况下,只需删除旧分片并添加新副本或主分片。
修复红色和黄色索引
第四步是修复问题。 修复分为几类:
- 等待并让 Elasticsearch 修复它 —— 对于节点重启等临时情况
- 手动分配分片 —— 有时需要解决问题
- 检查路由/分配规则 —— 许多 HA 或复杂系统使用路由或分配规则来控制放置,随着情况的变化,这可能会创建无法分配的分片。 解释应该清楚这一点。
- 通过将数字设置为 0 来删除所有副本 —— 也许你无法修复副本或手动移动或分配它。 在这种情况下,只要你有一个主节点(索引是黄色的,而不是红色的),你总是可以将副本计数设置为 0,等一下,然后设置回 1 或任何你想要的,使用:“index” :{“number_of_replicas”:0}
我们将在出现状态和解决方案时添加更多详细信息,但这是一个复杂的问题,并且与所有系统一样,修复会根据问题的确切细节和历史记录而有所不同。
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。