
一、SparkSQL 概述
1.1 ** SparkSQL是什么**
Spark SQL是Spark用于结构化数据处理的Spark模块。
1.2 Hive and SparkSQL
我们之前学习过hive,hive是一个基于hadoop的SQL引擎工具,目的是为了简化mapreduce的开发。由于mapreduce开发效率不高,且学习较为困难,为了提高mapreduce的开发效率,出现了hive,用SQL的方式来简化mapreduce:hive提供了一个框架**,将SQL转换成mapreduce来执行**。执行的效率不会因此提升,但开发效率会大大提高。
同样的,sparkCore的代码能不能转换成SQL语句呢?sparkSQL的前身是Shark,是一个将spark和hive结合的框架,利用hive SQL简化的思想,将RDD进行简化。Shark的出现,是SQL-on-Hadoop的性能比Hive有了10-100倍的提高。
随着spark的发展,shark的发展受制于hive,在此基础上发展出sparkSQL和hive on spark,SparkSQL 作为 Spark 生态的一员继续发展,而不再受限于 Hive,只是兼容 Hive。
sparkSQL可以用于简化RDD的开发,提高开发效率,且执行效率飞铲快。所以实际工作中,基本上采用的都是sparkSQL。sparkSQL为了简化RDD的开发,提高开发效率,提供了2个编程抽象,类似于spark Core的RDD。
DataSet
DataFrame
1.3 SparkSQL特点
1.3.1 易整合
无缝的整合了SQL查询和Spark编程
1.3.2 统一的数据访问
使用相同的方式连接不同的数据源
1.3.3 兼容Hive
在已有的仓库上直接运行SQL或者HiveQL
1.3.4 标准数据连接
通过JDBC或者ODBC来连接
1.4 DataFrame是什么
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,RDD只关心数据,如传入一数组(1,2,3,4),RDD不关心数组的意思。而DataFrame关心数据结构,如主键。
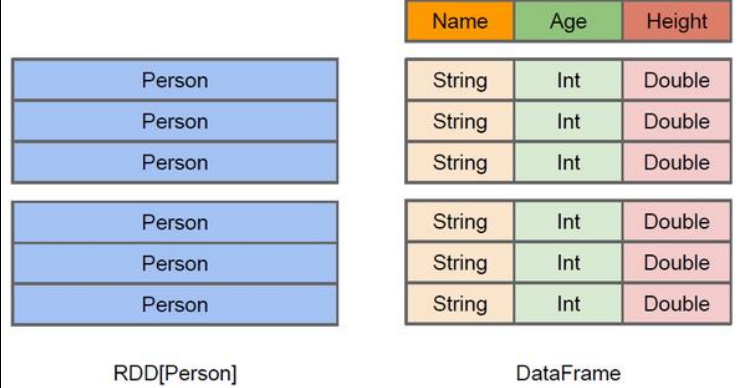
** RDD**:
虽然以Person为参数类型,但Spark框架本身不了解Person类的内部结构。DataFrame:
提供了详细的结构信息,使得SparkSQL可以清楚的知道该数据集中包含哪些列,每列的名称和类型各是什么。
DataFrame为数据提供了Schema视图,可以把它当作数据库中的一张表来对待。
1.5 DataSet是什么
DataSet是分布式数据集合,是DataFrame的一个扩展。提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点
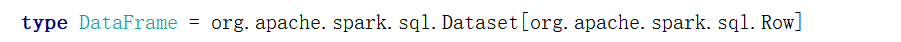
DataFrame是一个特定泛型的DataSet。
二、SparkSQL核心编程
2.1 新的起点
SparkCore中,如果想要执行应用程序,首先需要构建上下文环境对象SparkContext。SparkSQL可以理解为是对SparkCore的封装。不仅是在模型上进行了封装,上下文环境对象也进行了封装。
在老的版本中,SparkSQL提供了两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。**Spark Session 内部封装了 SparkContext**,所以计算实际上是由 sparkContext 完成的。当我们使用 spark-shell 的时候, spark 框架会自动的创建一个名称叫做 spark 的SparkSession 对 象, 就像我们以前可以自动获取到一个 sc 来表示 SparkContext 对象一样。
2.2 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。
2.2.1 创建DataFrame
Spark支持创建文件的数据源格式:spark.read.
**csv format jdbc json load option options orc **
**parquet ****schema table text textFile **


object DataFrameTest {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("detaSetDemo").getOrCreate()
val dataFrame = spark.read.json("in/user.json")
dataFrame.printSchema()
dataFrame.show()
spark.stop()
}
}
注意:
如果从内存中获取数据,spark 可以知道数据类型具体是什么。 如果是数字,默认作 为 Int 处理;但是从文件中读取的数字,不能确定是什么类型,所以用 bigint 接收,可以和 Long 类型转换,但是和 Int 不能进行转换。
结果展示:

2.2.2 SQL语法
1)读取JSON文件创建DataFrame
val dataFrame = spark.read.json("in/user.json")
2)对DataFrame创建一个临时表
dataFrame.createTempView("user")
// 或
dataFrame.createOrReplaceTempView("user")
3)通过SQL语句实现查询全表
val frame = spark.sql("select * from user")
4)结果展示
frame.show()

注意:
普通临时表是 Session 范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
2.2.3 DSL语法
DataFrame提供一个特定领域语言(domain-specific kanguage, DSL)去管理结构化的数据。可以在Sacla, Java, Python和 R 中使用DSL,使用DSL语法风格不必去创建临时试图了。
1)创建一个DataFrame
val df = spark.read.json("in/user.json")
2)查看DataFrame的Schema信息
df.printSchema()
3)只查看列数据的6种方式
注意:涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名
// 输出的6种方式
import spark.implicits._
userDF.select('name,'age).show()
userDF.select("name","age").show()
userDF.select($"name",$"age").show()
userDF.select(userDF("name"),userDF("age")).show()
userDF.select(col("name"),col("age")).show()
userDF.select(column("name"),column("age")).show()
val idColumn = df("id")
4)查看“age”大于“22”的数据
条件过滤可以使用filter,也可以使用where,where的底层调用的也是filter方法。
df.select(userDF("name"),userDF("age"),(userDF("age")+1).as("ageinc"))
.where($"name"=!="zhangsan").show() // where底层也是filter
// .filter($"ageinc">22).show()
5)按照“age”分区,查看数据条数
val countDF = df.groupBy("age").count()
countDF.printSchema()
6)增加列****withColumn
val frame = countDF.withColumn("number",$"count".cast(StringType))
7)修改列名withColumnRenamed
val frame2 = countDF.withColumnRenamed("count","number")
2.2.4 RDD转换为DataFrame
在 IDEA 中开发程序时,如果需要 RDD 与 DF 或者 DS 之间互相操作,那么需要引入**import spark.implicits._**
这里的 spark 不是 Scala 中的包名,而是创建的 sparkSession 对象的变量名称,所以必 须先创建 SparkSession 对象再导入。这里的 spark 对象不能使用 var 声明,因为 Scala 只支持 val 修饰的对象的引入。
rdd =>DataFrame: rdd.toDF
DataFrame => rdd: df.rdd

2.3 DataSet
DataSet是具有**强类型**的数据集合,需要提供对于的类型信息。
2.3.1 创建DataSet
object DataSetDemo {
// 1)使用样例类来创建DataSet
case class Point(label:String,x:Double,y:Double)
case class Category(id:Long,name:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("dataSet").getOrCreate()
val sc = spark.sparkContext
// 重点记忆
import spark.implicits._
// 2)使用基本类型的序列创建DataSet
val points: Seq[Point] = Seq(Point("nj", 23.43, 57.12), Point("bj", 18.21, 199.43), Point("sh", 16.11, 18.3))
val pointDS = points.toDS()
val categories: Seq[Category] = Seq(Category(1, "nj"), Category(2, "bj"))
val categoryDS = categories.toDS()
categoryDS.printSchema()
categoryDS.show()
}
注意:
在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet。
2.3.2 RDD转换为DataSet
SparkSQL能够自动将包含case类的RDD转换成DataSet,case类定义了table的结构,case类属性通过反射编程了表的列名。case类可以包含如Seq或者Array等复杂的结构。
case class User(name: String, age: Int)
sc.makeRDD(Seq(("zhangsan",18), ("zhaosi",20))).toDS
2.3.3 DataSet转换为RDD
DataSet也是对RDD的封装,所以可以直接获得内部的RDD。
case class User(name: String, age: Int)
val res1 = sc.makeRDD(Seq(("zhangsan",18), ("zhaosi",20))).toDS
val rdd = res1.rdd
2.3.4 DataFrame和DataSet转换
DataFrame => DataSet:as[样例类]
DataSet => DataFrame:toDF
case class User(name: String, age: Int)
val userDF = sc.makeRDD(Seq(("zhangsan",18), ("zhaosi",20))).toDF("name", "age")
val userDS = userDF.as[User]
2.4 RDD、DataFrame、DataSet 三者的关系
2.4.1 相互转化

// RDD <=> DataFrame
val rdd = spark.sparkContext.makeRDD(List(1,"zhangsan",30),(2,"lisi",40))
val df: DataFrame = rdd.toDF("id","name","age")
val rowRDD:RDD[Row] = df.rdd
// DataFrame <=> DataFrame
val ds:Dataset[User] = df.as[User]
val df1:DataFrame = ds.toDF()
// RDD <=> DataSet
rdd.map {
case (id, name, age) =>{
User(id, name, age)
}
}
val userRDD:RAA[User] = ds1.rdd
2.4.2 三者的共性
都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
都有惰性机制,在创建、转换时,不会立即执行。只有在遇到行动算子时,才会开始运行
有很多共同的函数
DataFrame 和 DataSet 许多操作都需要导入包:import spark.implicits._
都会根据Spark的内存情况自动缓存运算,即使数据量很大,也不用担心内存溢出
都有partition的概念
DataFrame 和 DataSet 都可以使用匹配模式获取各个字段的值和类型
2.4.3 三者的区别
** 1)RDD**
- RDD一般和spark mllib同时使用
- RDD不支持sparkSQL操作
** 2)DataFrame**
- RDD和DataFrame不同,DataFrame每一行的类型固定为Row,每一列的值无法直接访问,只有通过解析才能获取各个字段的值
- DataFrame 和 DataSet 一般捕鱼spark mllib 同时使用
- DataFrame 和 DataSet 都支持SparkSQL操作,如select,groupby等。同事也能注册临时表/视窗,进行sql语句操作。
- DataFrame 和 DataSet支持一些方便的保存方式,比如保存成csv,可以带上表头
** 3)DataSet**
- DataFrame 和 DataSet拥有完全相同的成员函数,区别只是每一行的数据类型不同。DataFrame其实就是DataSet的一个特例
- DataFrame 也可以叫 DataSet[Row],每一行的类型是Row
三、SparkSQL连接Hive
object SparkHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("sparkHive")
.master("local[*]")
.config("hive.metastore.uris", "thrift://192.168.153.139:9083")
.enableHiveSupport()
.getOrCreate()
spark.sql("show databases").show()
val ecd = spark.table("shopping.ext_customer_details")
ecd.printSchema()
ecd.show()
println("============")
// 每个国家分别有多少员工
import spark.implicits._
import org.apache.spark.sql.functions._
val usernumdf = ecd
// 这里输出之后会自带表头。这是由于我们在hive中设置了删除表头'skip.header.line.count'='1'
// 所以需要过滤表头文件。
.where($"customer_id"=!="customer_id")
// .filter($"customer_id"=!="customer_id")
.groupBy("country")
.agg(count("customer_id").as("usernum"))
usernumdf.printSchema()
usernumdf.show(3)
usernumdf.write.mode("append").saveAsTable("shopping.usernum")
spark.close()
}
}
版权归原作者 five小点心 所有, 如有侵权,请联系我们删除。